New compiler "buns" - safer, faster, more perfect

As stated in all of our favorite movie: "Fly, hurry, buy a painting." The latter, of course, has nothing to do with it, but the time has come to “fly” on a new Beta version of the compiler. Today I will talk about what's new in the Intel Parallel Studio XE 2018 Beta package, and in particular, in its compiler component. And there really is a lot of things added, because standards do not stand still - C ++ 14, C ++ 17, Fortran 2008, 2015, OpenMP 4.5 and 5.0 , and the compiler must not only support them, but also generate perfect, productive and safe code. In addition, the new AVX512 instruction sets , which allow "skimming" off the latest Skylake and KNL processors , are increasingly entering the arsenal of modern compilers. But the most delicious is the new keys, which allow you to get even more performance without straining. So let's go!
I must say that you can download the Beta version here:
Intel Parallel Studio XE 2018 Pre-Beta survey
Everything I’ll talk about is included in this version of compilers and Update 1 , which will be available very soon. What then will be in the final product is a difficult question, but, “wangooe,” almost everything. What do we have in the new version 18.0 Beta ?
')
Code Security
Microsoft is trying hard to resist hackers and come up with more and more new technologies. To begin with, they made in their C ++ compiler the default maximum level of stack protection through the / GS: strong option, which allows you to deal with buffer overflow. This is done at the expense of performance, but safety is paramount. Since Intel for Windows is trying to be fully compatible with the Microsoft compiler, starting from the new version we also include / GS: strong by default. You can limit its effect and slightly improve performance using / GS: partial .
In addition, the development of a new technology CET (Control-Flow Enforcement Technology) is underway, which allows you to fight against attacks using the method of reciprocation-oriented programming ( ROP and JOP attacks). One of the ideas of protection is that another protected shadow stack appears in which the return address will be written / duplicated. When we reach the return from the function, the correctness of the address returned by the procedure and the address that we put in the shadow stack is checked. In addition, a new instruction ENDBRANCH is added in order to designate areas in the program to which indirect transitions can be made via call / jmp .
The state machine is implemented, and as soon as the processor processes one of the call / jmp instructions, it goes from the IDLE state to WAIT_FOR_ENDBRANCH . Actually, in this state, the next instruction to execute must be ENDBRANCH . Much more details are written in the above article, and Intel compilers for C / C ++ and Fortran have added support for CET through the -cf-protection option. By default, it is not enabled and, of course, can affect performance when used.
Who is ready to test the new protection? An important note is that in order for CET to work properly, OS and RTL support is required, but it is not there yet.
Performance
Now let's talk about new compiler options that will make your applications even faster and more productive.
There is a compiler optimization called function splitting . In order to understand why it is needed, it is worth remembering about embedding the code and the fact that one of the effects is to increase its size. Therefore, inlining does not make sense for large sizes of the function itself, which we want to build into the place of the call. In these cases, splitting the function and partial inlining will help us to prevent an excessive increase in the size of the code, while retaining its advantages. As a result, our function will be divided into two parts, one of which ( hot ) will be built in, and the other ( cold ) will not.
In fact, this optimization has been present for a long time in Intel 32-bit compilers for Windows, using Profile-Guided Optimization ( PGO ). Here, by the way, is an interesting post about this optimization in gcc . The idea is simple - compile our application, do the instrumentation, then run it and collect data on how it was executed (profile), and, already taking into account this data from runtime, reassemble the code again, applying the knowledge gained for more powerful optimization.
Now it is clear why it was possible to use function splitting with PGO , because we know well for each function, what part of it was running and what needs to be inline.
Now we already allow developers to control this optimization by “handles” by adding the key -ffnsplit [= n] (Linux) or -Qfnsplit [= n] (Windows), which tells the compiler to split the function with the probability of execution of blocks equal to n or less. It does not matter if PGO is enabled or not, but we need to specify this parameter n . If you do not specify it, then this optimization will be performed only if there is dynamic information from the PGO . The values of n can be from 0 to 100 , but the most interesting for us are in the first half. For example, with PGO and a 32-bit compiler on Windows, a value of 5 was used , meaning that if the probability of execution is less than 5% , then this block will not be inline.
If we started talking about PGO , then you should definitely say that here, in the new version of the Studio, there have been pleasant changes. Previously, this optimization worked only with tools, but now it is possible to work using sampling from the VTune profiler. The implementation of such a feature was prompted by the impossibility of using traditional PGO on real time and embedded systems, where there are restrictions on the size of data and code, and the instrumentation could significantly increase it. In addition, on such systems it is impossible to perform I / O operations. VTune hardware self-allocation from VTune can significantly reduce the overhead of executing an application, without increasing memory usage. This method gives statistical data (they are exact with the instrumentation), but at the same time it is applicable on systems where the traditional PGO “slips”.
The scheme of work with the new PGO mode can be represented as a diagram:
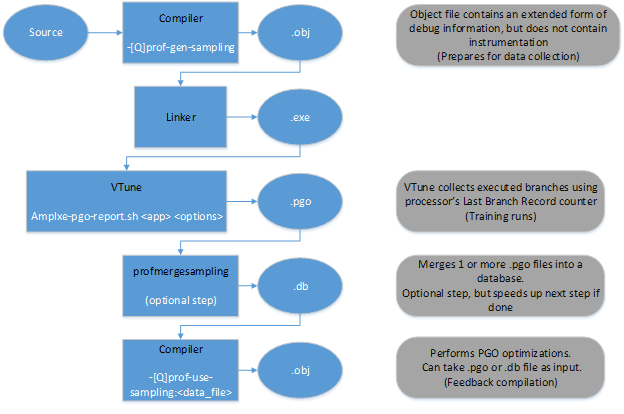
As before, we need to compile our code for the subsequent collection of statistical data. Only now this is done using the option -prof-gen-sampling (Linux) or / Qprof-gen-samplig (Windows).
At the output, we will get binaries with extended debug information (which will increase the size by the allowable 5-10% ), but without instrumentation. And then we need a special script from VTune to run the application and generate a profile. After that (if you don’t need to merge several profiles), simply rebuild our code with the received data with the -prof-use-sampling (Linux) or / Qprof-use-sampling (Windows) key. To work with these options, we need VTune, so we need to install not only the compiler, but also the profiler. The Beta package has both.
Now let's talk about working with mathematical functions from the SVML (Short Vector Math Library) library, which provides vector analogs of scalar mathematical functions.
Just a few changes touched SVML with the release of the new version. In order to remove the overhead during dynamic dispatch, now at the compilation stage a direct call to the necessary function will be generated using the specified values of the -x key. Prior to this, we ran to check what our processor, and called the desired version of the function. And although overhead is not great for ordinary functions, with intensive work with mathematical functions (for example, an exponent), it can be weighty 10% . This will be especially popular when calculating in the financial segment of applications.
However, if we need to return the "old" behavior of the compiler, then the -fimf-force-dynamic-target (Linux) or / Qimf-force-dynamic-target (Windows) option will help us.
From the same financial area came another change. When working with mathematics, not only performance is important, but also reproducibility of results. I already wrote about the great options to take care of this -fp-model (Linux) and / fp (Windows). So, by defining a floating-point model as precise ( -fp-model-precise (Linux) or / fp: precise (Windows)), we were deprived of the satisfaction of using vector mathematical functions from SVML , which, of course, had a negative effect on performance but very positive on reproducible results. Now the developers made sure that the performance does not affect the stability of the numerical results. Using the key -fimf-use-svml (Linux) or / Qimf-use-svml (Windows) you can tell the compiler to use scalar functions from SVML instead of their calls from the standard LIBM library. And since they made sure that the scalar and vector versions of SVML gave the same results, now when using a precise model, you can use vector mathematical functions.
When working with different buffers, a large number of functions are used, such as memcpy , memset , etc. If they have calls, the compiler uses its own internal logic and can go various ways: call the appropriate library function, generate a rep instruction, or expand the operation into a loop, provided that it knows the size at compile time. It so happened that he did not always correctly guess the right approach, so now there is an option -mstringop-strategy (Linux) or / Qstringop-strategy (Windows), with which you can tell the compiler what to do with such functions working with buffers / strings ( strings , hence the name of the key). You can specify libcall , rep, or const_size_loop , respectively, as an argument to the option. For example, when compiling with the -Os key (we care about the size of our binaries), the option -mstringop-strategy = rep will be used implicitly.
For more productive code on systems supporting AVX-512 , the option -opt-assume-safe-padding (Linux) or / Qopt-assume-safe-padding (Windows) has appeared.
It allows the compiler to assume that it can safely access 64 bytes after each array or variable allocated by the application. Previously, this option was available for KNC , but now it can also be used for the latest architectures with support for AVX-512 . In certain cases, such a “liberty” will allow the compiler to generate unmasked download operations instead of masked, for example, when using G2S (gather to shuffle) optimization. But it is important to align data by 64 bytes.
Conclusion
These are perhaps the most important of the new "magic" options that appeared in the latest version of the compiler. But besides all this, support was added for almost the entire OpenMP 4.5 standard (there are not only user defined reductions ), as well as part of the new generation of OpenMP 5.0 (for example, reductions in task 'ah).
Standards C ++ 11 and C ++ 14 are fully supported since version 17.0 , but full support for Fortran 2008 has appeared only now. Yes, and the last standard C ++ 17 will be supported much more, and considering this, it has not yet been finally adopted.
The bottom line is that we have the next version of the compiler, which gives us even more opportunities to optimize our code and get better code performance and security, while still having wide support for the latest standards. Ida test?
Source: https://habr.com/ru/post/329938/
All Articles