What are women talking about? (Text mining of beauty blogs)
In the hands of our team from CleverDATA was a unique material - about 100 thousand pages of English-language blogs devoted to the beauty sphere. This body came to us thanks to the desire of one cosmetic corporation to find out the laws by which the blogosphere “works”. The company wanted to more effectively interact with the beauty bloggers - get more advertising effect, giving their products in the good hands of loyal authors.

A source
Most companies attach their products to blogging reviews based on the intuition and professionalism of marketers. In fact, brands are moving blindly, because personal acquaintances with bloggers, friendships and agreements without statistical data and analytical calculations sometimes turn out to be very unreliable.
I have to say, we found out the following:
')
I think that our most interesting discoveries, which this article is devoted to, will be useful to anyone who somehow comes into contact with the promotion of products on the web. For example, whether the popularity of a blog depends on the activity of the blogger and how the audience responds to the general mood of the post. And besides this, I would like to tell about the possibilities of Text mining using the example of the analysis of the blogosphere .
Working on the project, we developed a number of approaches and techniques, which in our case showed good results, but it is ineffective to apply them on any other package without calibration. Therefore, I did not give the code, but in detail I tell about the case itself, the methods used and the main conclusions.
So let's go!
It is no secret that textual information is one of the main types of information in modern society; therefore, text analysis can not only reveal implicit patterns, but also be useful in a commercial application.
We did not have to collect data - the array was collected earlier, as a result of crawling beauty blogs. True, for our tasks it turned out to be very raw and demanded preprocessing. In addition, the texts were naturally not marked up, so it was not possible to use machine learning tools with the teacher.

A source
An array of beauty blogs consisted of about 100 thousand pages, or rather 98,496. We first were delighted: 100 thousand pages is a good corpus for the upcoming study. But it turned out that it was very noisy, and after cleaning only 59.6% remained suitable for analysis.
40.4% of the data were blank pages and error pages, pages not in English (23,461), photo and video materials without text (2,315), articles from the techcrunch.com resource not related to the beauty industry (obviously, this is a resource on which the crawler collecting material was tested, and its contribution in the general corpus was noticeable - 3,402 pages).
Of course, getting at the disposal of almost 60 thousand pages, suitable for analysis, is also not bad. It turned out that about 2 thousand unique blogs correspond to this text volume, that is, minus cloned and similar materials, this volume of text was created by two thousand unique authors.

A source
Beauty and health blogs are mostly women's topics. If the exact gender composition of the entire English-language blogosphere is questionable, then everything is unambiguous in blogs about cosmetics and a healthy lifestyle: here most of the authors and readers are women. What are these women blogging talking about? This is the main question that we had to solve in order to understand how to most effectively promote the beauty industry products in the blogosphere. To answer this key question, we first try to explore how women say in blogs.
The bloggers' author style, of course, varies. But according to the size of posts, their authors can be combined into two groups: miniaturists bloggers with posts up to 100 words (20% of all authors), and bloggers who prefer full-weight texts of 200-500 words (~ 80%).
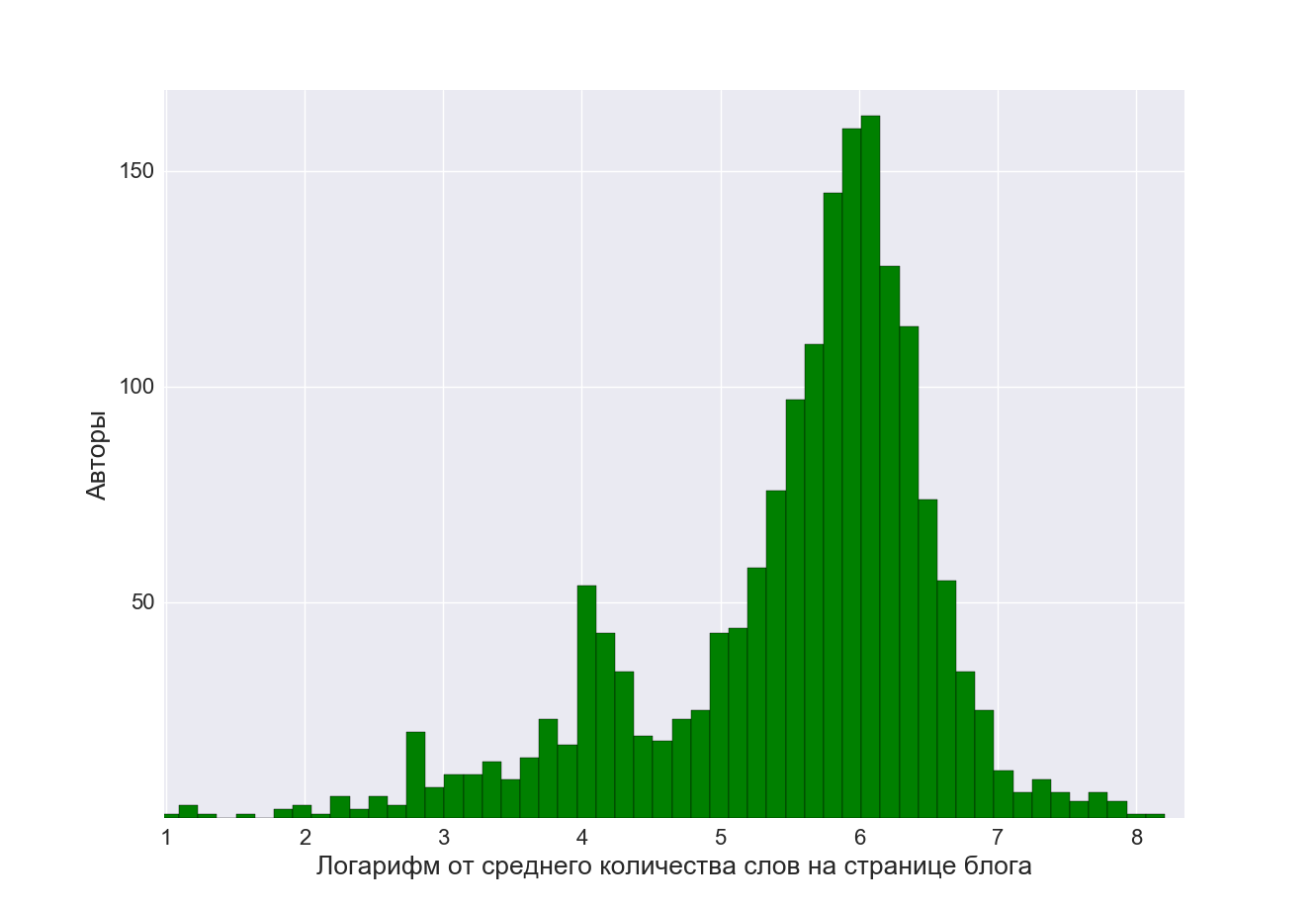
A curious correlation between the verbosity of the authors and their activity. It is impossible to say that short posts are written more than wordy ones, and that amateurs write in the Twitter format take the number of publications. By no means. We saw that the activity of the authors of the two groups was similar.
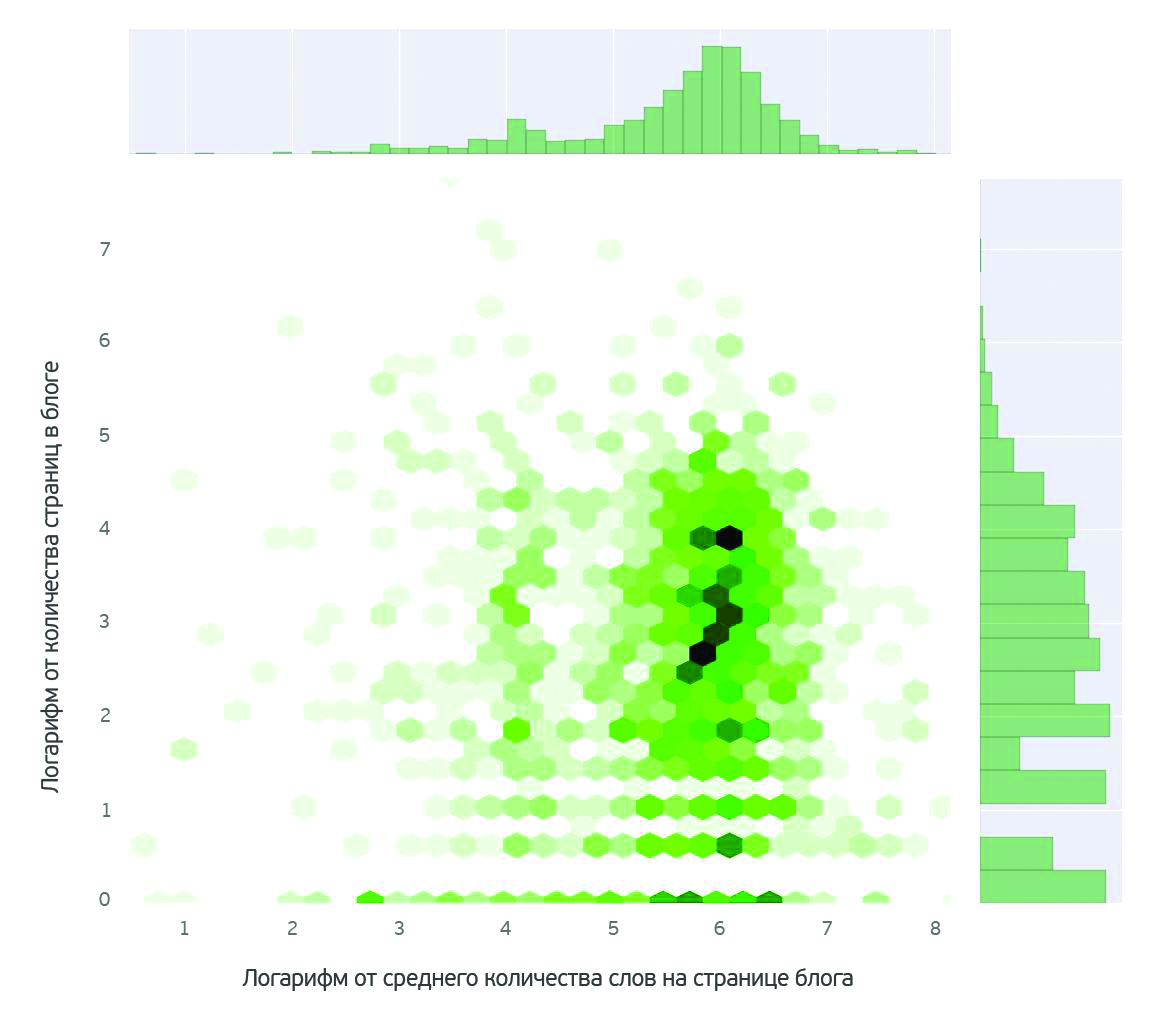
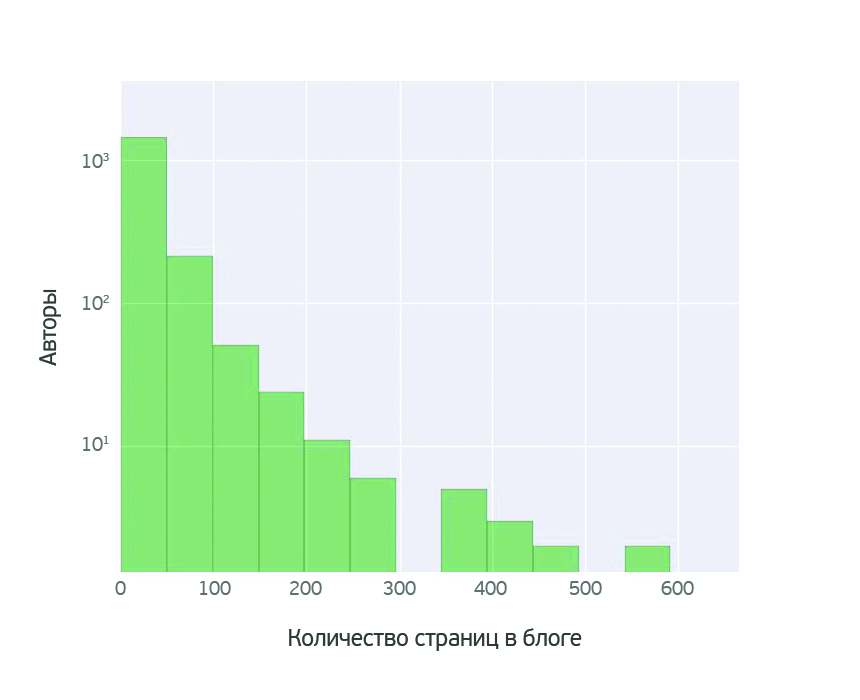
The analysis showed that very few authors write actively. Not more than 20 authors since the appearance of the blog have managed to write more than 300 posts, in most blogs - up to 100 posts, which fit into the framework of the usual statistical laws.
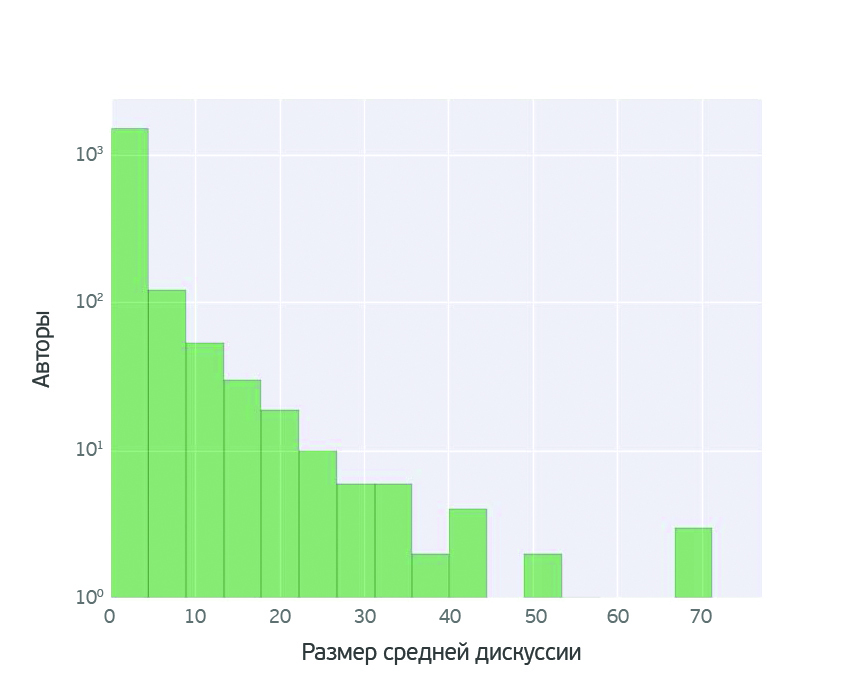
We looked at the discussions in the blogs and found out that the posts of a very small number of bloggers are gaining more than 40 comments. The articles of most authors are not so actively discussed, and an average of 10–20 comments per publication.
The first thing that comes to mind when we talk about the study of the text is the analysis of the tonality of the text, that is, the assessment of the author's emotions - whether they are positive or negative. A lot of models for analyzing emotional coloring have been proposed. Therefore, we did not reinvent the wheel and used ready-made models:
Each model of emotional color evaluation was trained on its own separate corpus of texts. One gave good results on short texts (since I trained on Twitter), the other on more detailed texts (IMDB). Each of the models has its own difficulties with the color of neutral texts, but since we used 4 models, they smoothed out some of the shortcomings of each other and we got a smooth distribution, where -1 means extremely negative emotional evaluation, and +1 is extremely positive.
The combination of four independent models gave the following distribution of texts by emotional coloring.
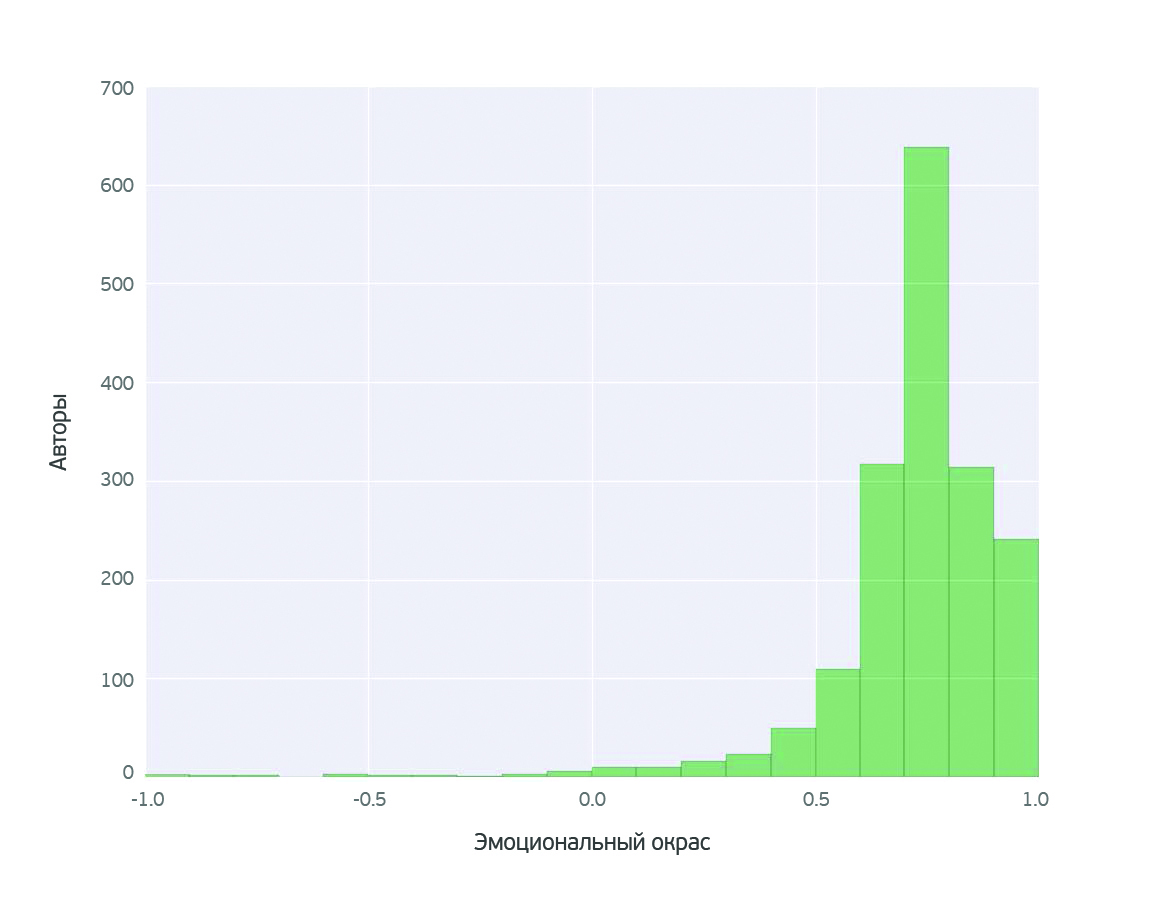
We see an asymmetric quasinormal distribution with a center around 0.72 and a heavy right tail. This means that the absolute majority of blogs have a positive emotional tone. The shift of the average emotional coloring to the positive area is an amazing fact that you can talk about with high statistical significance and which you can easily check on your own by reading several women's blogs taken at random.
If you look at how bloggers are distributed according to their activity (analysis of the number of pages), you will find that the most prolific bloggers by emotional color work in a very narrow range: 0.74 ± 0.03.

In this case, it is very curious that professional bloggers work in such a narrow range of emotional coloring - as if using some resonant frequency of their audience. Perhaps, a feedback system is obtained: an author with a neutral article receives feedback from readers through comments and next time adjusts to the enthusiastic mood of the audience.
It can be assumed that such a narrow range of moods is associated with professional deformation. However, ourcompetitors colleagues in their studies of texts on the Internet show that positive coloring is characteristic of the female form of communication, while the emotional tone of male conversations is closer to neutral.
Does blog discussion depend on his activity? Surprisingly, no. In the most active blogs, we see fewer comments.
Perhaps this is due to the fact that active bloggers with a large audience have already gained such authority that it is hard to argue with them.
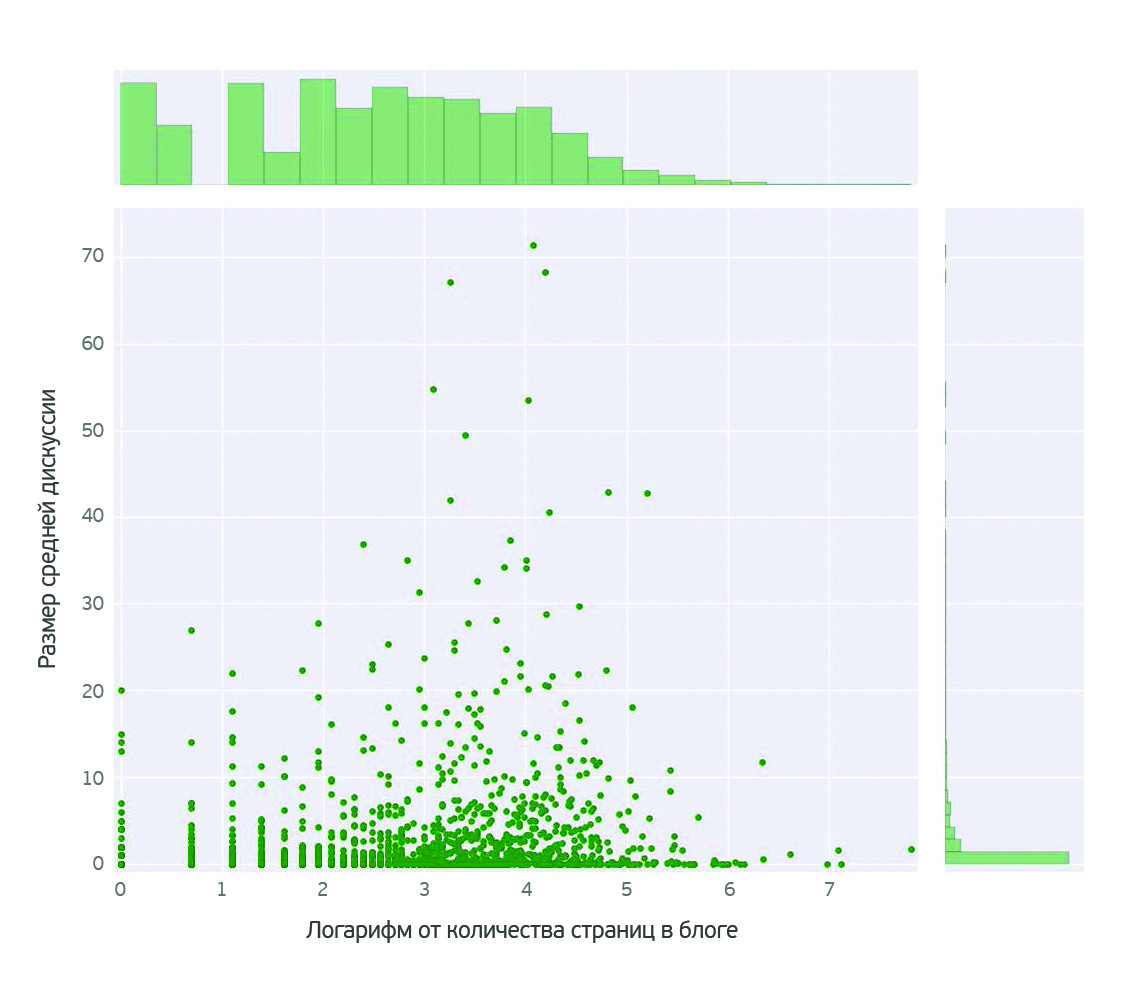
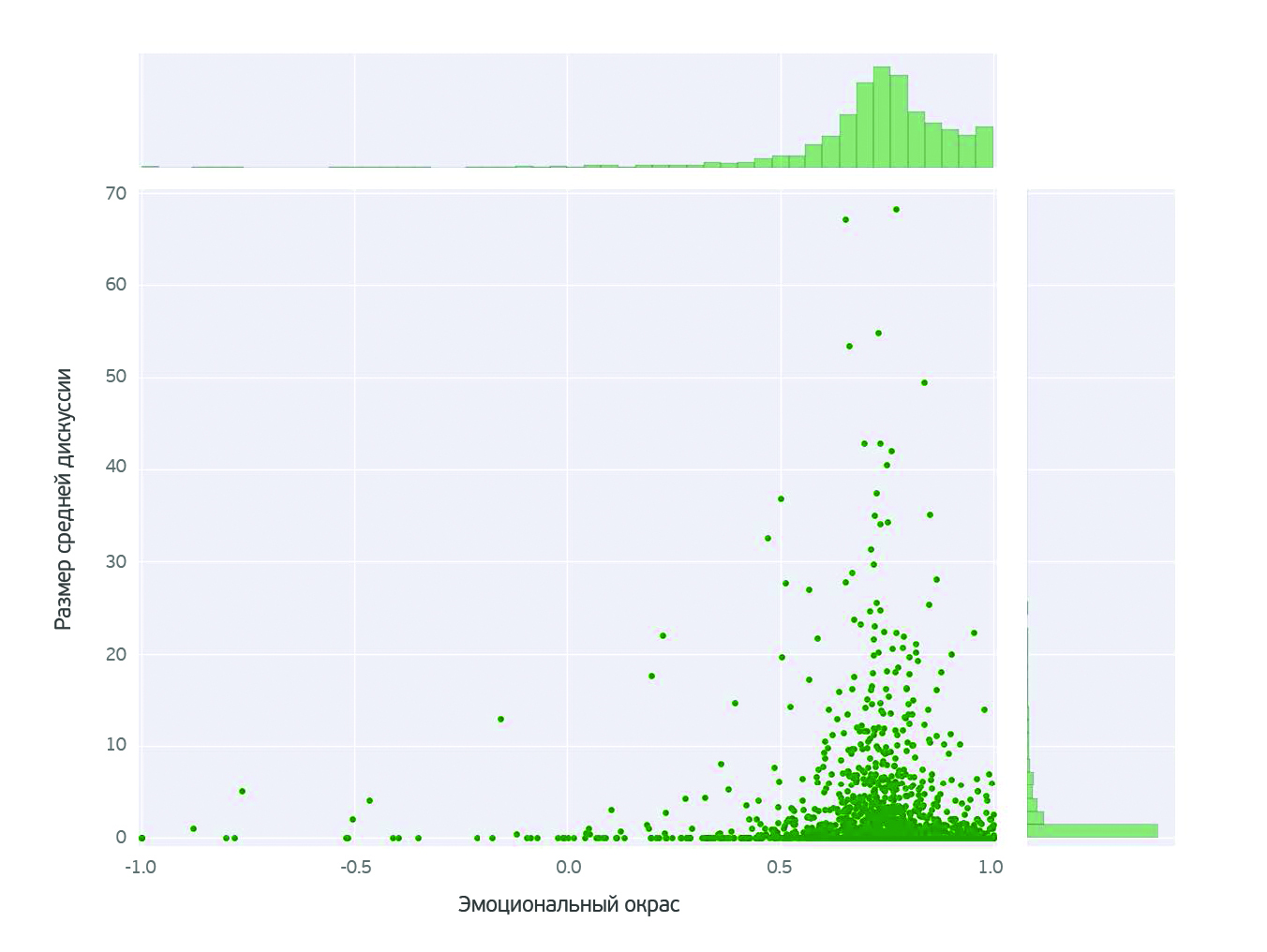
The dependence of the discussion on the emotional color came as a surprise to us. The most discussed blogs are in the positive area of emotional color. It should be borne in mind that this (as shown in the graphs above) are not the most active blogs. The conclusion is obvious: to provoke a discussion, it turns out that it is enough just to praise something beyond measure.
In order to evaluate the effectiveness of blogs, in terms of disseminating information (do they read them, do reposts), we tried to use ready-made tools for estimating Internet traffic.
Among the metrics reflecting the number of readers and citations in the network, I will highlight the following.
Alexa Rank - a popular counter for the number of visitors and the number of site views, is not established on all Internet resources, so it is not always possible to use its data.
The Yandex Thematic Citation Index (TIC, Thematic Yandex Citation Index ) defines the “authoritativeness” of an Internet resource, taking into account the qualitative characteristics of links to it from other sites, but is not very common in the English-language segment of the Network.
Google Page Rank - calculates the quantity and quality of links to the blog in order to assess the importance of the resource for the audience; is the main indicator for the promotion of sites. The main advantage of Google Page Rank is that it is present in all sites, but in many web pages it is clearly inadequate (and this is its big drawback). In addition, because of the terms of the license agreement, there are restrictions on using Google Page Rank, which makes it difficult to use it even for studies such as ours.
All of the above determined our choice: we tried YandexTIC and AlexaRank. I note that all these metrics are related to the volume of the audience (how many times the author is cited, how many people read it), have their own shortcomings and therefore cannot claim to be exhaustive. Therefore, it is worth looking for additional tools to assess the popularity of the author.
In order to somehow measure the popularity of the authors, we resorted to the Klout score . This metric is used in social networks to assess the influence of a person: his social connections and the citation of his posts. This metric, independent of the previous ones, assesses both the audience of readers and the number of reposts in social networks. It is noteworthy that a loud case was associated with the Klout score in 2011: two candidates claimed the post of vice-president of one of the companies, one of whom advised giants such as America Online , Ford and Kraft for 15 years, while the second could not boast such an outstanding experience but he had a weighty trump card - Klout score equal to 67. In the aforementioned case, a candidate with a higher Klout score received a position. In our case, it turned out that for our authors, the average Klout score is 40.1. Perhaps for a vice president with fifteen years of experience such a Klout score will be low, but for our bloggers this is a normal value: the studied beauty bloggers are not centers of gigantic social clusters, “our” bloggers are closer to ordinary people with average activity in the network .

If you trace the relationship of Klout score and emotional color, you can find an interesting trend.
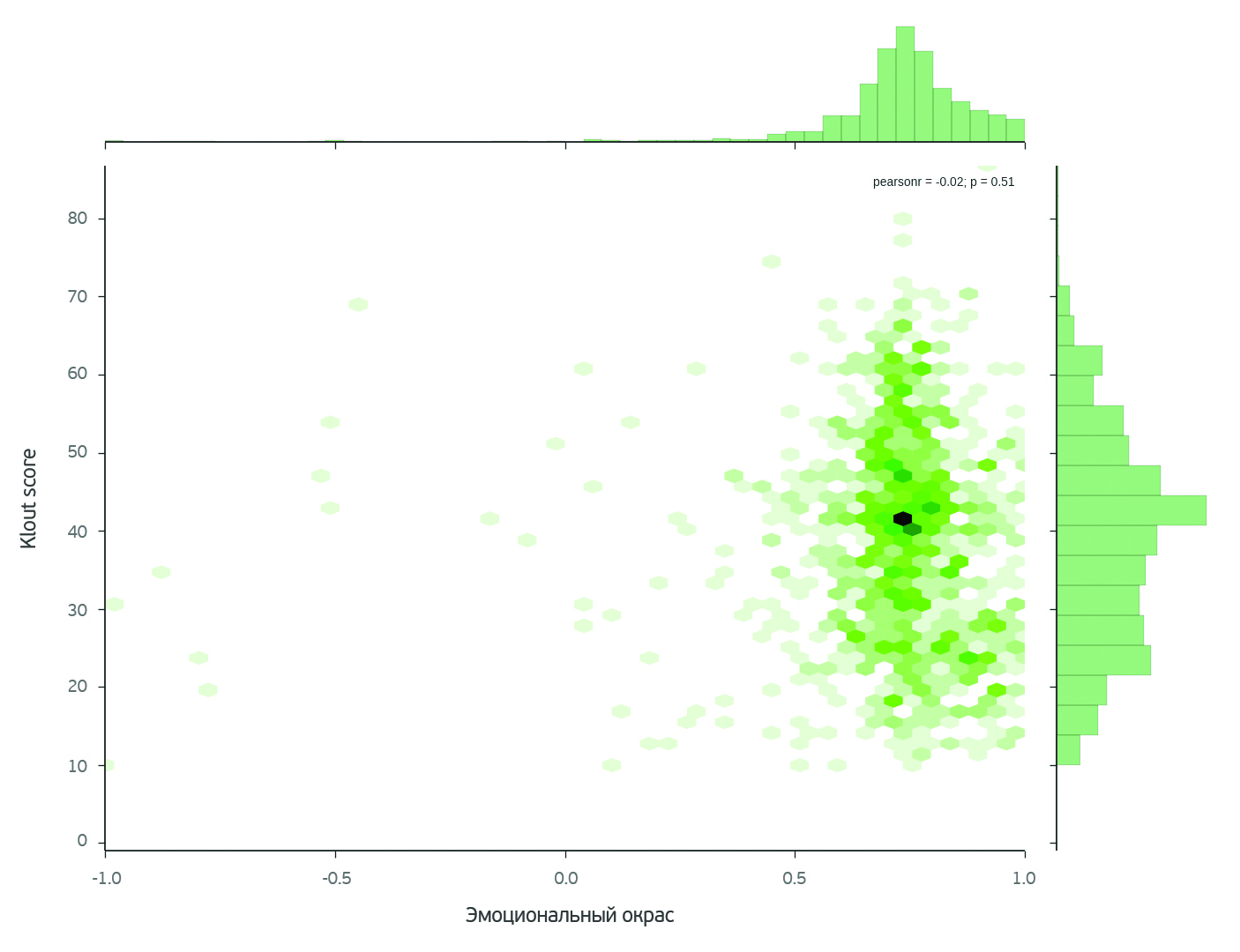
The graph shows that there is a group of bloggers who have a low Klout score, and the emotional color is clearly higher than the “resonant” value. This means that such an author is just beginning to write (therefore there are few articles), but his emotional color is overestimated. Perhaps this is a psychological phenomenon associated with a new activity: the author tries to embellish either on purpose or in his “rose-colored glasses”, i.e. he himself is in high spirits. In any case, if the author continues to write, he will evolve into lower emotions through feedback in the comments.
We worked with the trademark, the real name of which we, of course, will not reveal, and in the article for convenience we call it “Baba Yaga”. All products of this brand have extended, wordy names, for example, “Face Cream Baba Yaga”.
We applied the Fuzzy String Matching technique to the entire body of texts and tried to find references to the brand and its products in all the texts.
Fuzzy String Matching is based on an analysis of Levenshtein distance , which indicates letter differences in words. Strictly speaking, the Levenshtein distance determines the minimum number of changes to a single character (its removal, replacement, addition) necessary to turn one word into another. The distance obtained using the Python fuzzywuzzy module is normalized in the range from 0 to 100. Thus, completely different words will have a similarity measure equal to 0, and identical words will have a similarity measure equal to 100. For example, in a bearded joke about the difference between the bread and beer measure of similarity will be zero: in order to get beer from bread, you need to replace all four letters.
It should be noted that we were lucky with the brand names of the products, since they were not monosyllabic (like the well-known boa soap), but consisted of several words by which one could understand the type and, in part, the purpose of the product, for example, “Baba Yaga Face Oil”. Fuzzy String Matching allows you to catch partial references with appropriate settings, for example, “Face Oil”, and we tried to play with it.
Posts in which the desired product was mentioned by 90% in the Fuzzy String Matching metric were marked as “good”. The brand had about 100 products, so each article was tested for each product more than 100 times.
The relevance rating for the author was taken as the sum of all “good” articles. Normalization for the number of articles was not intentionally introduced so that authors with a large number of articles take the lead.
Subsequently, we used the natural logarithm of the resulting rating. For example, authors with 30, 10, and five “good” articles received a corresponding relevance rating of 3.4, 2.3, and 1.6.
The approach is simple, however, due to the large number of articles and a large number of products, the law of large numbers and the CLT (central limit theorem) began to work, and we received reasonable estimates.
To speed up the process and improve accuracy, we switched to using the distance obtained using the Word2Vec model; however, even with the initial approach, we obtained a result that can be used in further work.
Based on the listed techniques, we built the authors rating. It is based on:

It should be noted that we don’t give preference to bloggers with a large number of pages, because there are both active blogs with a volume of more than 500 posts, and low-active authors with a number of posts less than 100. There are also no preferences for the number of comments. I note that in terms of emotional color, they are all positive and work in the range from 0.70 to 0.78.
We have carefully studied the leader of the list. It turned out that he had published an article dedicated to our brand. It was a laudatory ode to the whole brand, without analyzing and describing specific products.
So, the rating of bloggers is built, now we need to connect authors and products that they can give for review. For this you need:
Products for promotion were chosen almost arbitrarily. In fact, the choice fell on them due to the fact that the statistics of their sales seriously stood out against the background of other products.
The first two products were very popular, which means that it was possible to further increase the number of potential buyers.
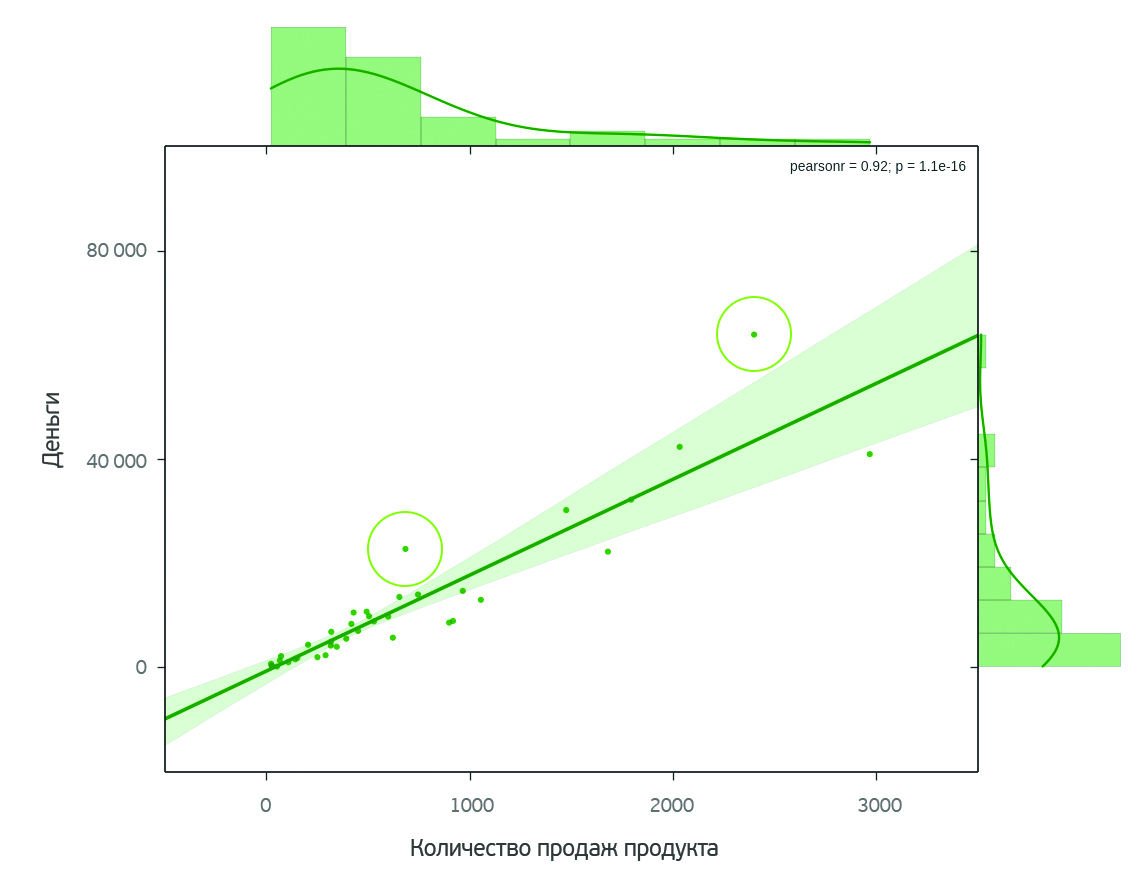
The second two selected products have recently entered the market and have not yet had time to show themselves to the full. Promotion would definitely not hurt them. These products stand out on the graph of the dependence of the value of the product on the number of its sales.
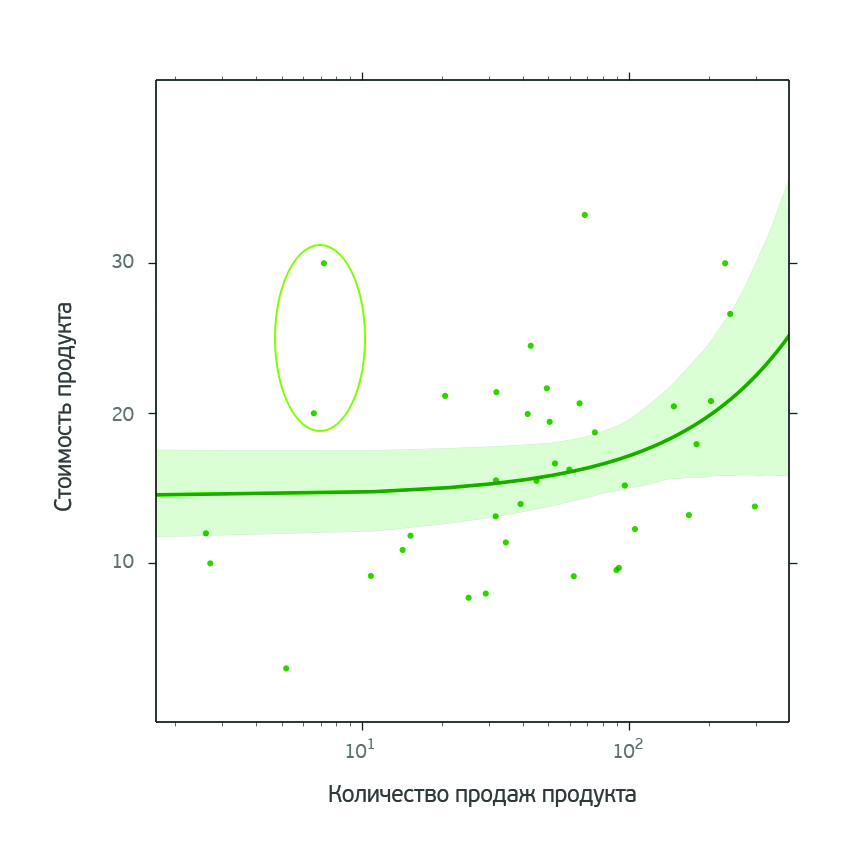 In principle, such an analysis can be carried out for any of the products. The choice of a particular product is not fundamental.
In principle, such an analysis can be carried out for any of the products. The choice of a particular product is not fundamental.
In the blogs of each author you can find topics interesting for brand promotion. What do the authors write about? To find out the list of topics for each blog, we will create a matrix, each row of which will correspond to a post, indicate the keywords in the columns, and the cell color will indicate the TF-IDF index (you can read about the use of the TF-IDF method, for example, here and here ) keyword. Accordingly, the more intensely the cell is colored, the more references to the word we have found and the more important this word in context. Examples of words for the formation of the table: "make-up", "face", "body", "scrub", "lotion", "oil", "cleansing", "conditioner", etc.
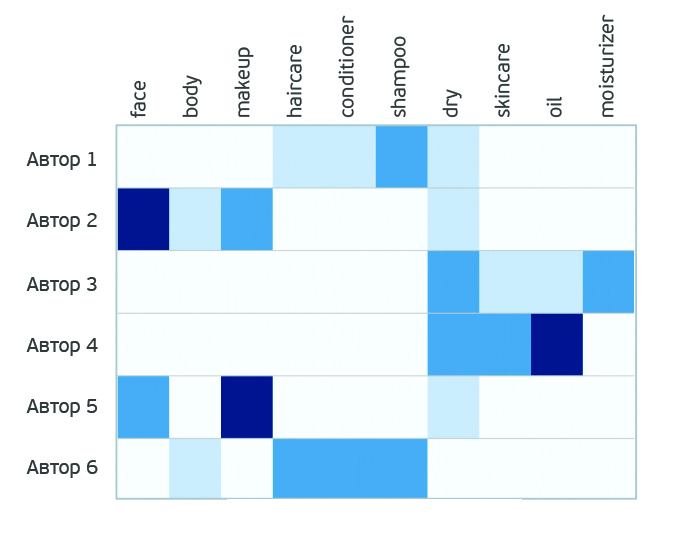
Next, the NMF method is applied , which allows us to decompose our matrix into two smaller ones: “authors” / “intermediate measurement” and “intermediate measurement” / “words”. The only factorization condition we have imposed is that the values should not be negative, that is, they should all be greater than or equal to 0.
“Intermediate measurement” in this case can be interpreted as topics. Thus, we laid out the authors on the themes of their texts.
The NMF method used to obtain the topics of texts can usually compete with the LDA and LSA (pLSA) methods, but one more powerful tool in this area is worth mentioning : BigARTM , which we are currently switching to. It should be noted that the basic idea of matrix decomposition is also present in the BigARTM method, but its advantage lies in the flexible possibility of using regularizers

Now you need to compare the name of the brand products with the selected topics. This can be done using the Fuzzy String Matching approach already used, but it is better and more accurate to use the distance measured using the Word2Vec model.
One thing to consider here: if the product name is fully spelled out in the title of the post, most likely it was a review post, that is, the author has already written about the product and he shouldn’t suggest to do it again.
We get a colorful matrix, where the color indicates the degree of correlation of the author with the product. The authors-products matrix is sorted by our authors rating.
The authors' rating was based in part on the mentioning of the brand’s products in the texts. After sorting by authors, color distribution can be observed, which is focused on authors with high ratings and fading as the rating decreases.

This color distribution was obtained using a separate mathematical approach (TF-IDF, NMF, etc), and it is in good agreement with our initial result obtained using simple counting of references. Thus, on the one hand, we confirm the adequacy of our rating, and on the other hand, we demonstrate the reasonableness of the results obtained using a number of more complex mathematical techniques. The consistency of the results obtained by various methods speaks in our favor.
To promote the product, we do not need to involve a lot of people. Take the first forty authors. For them, the matrix will look like this:

From the author-product matrix, we extract the most resonant peaks, after which the column with the peak is discarded. Thus, for each author, we get only one product. So, our goal has been achieved: the authors have established a connection with the products.
Thus, according to the results of the study of the initial body of articles of beauty blogs using the Klout score social activity metrics, as well as taking into account the emotional color of the articles, we discovered a number of features of beauty bloggers. These features must be considered when organizing advertising campaigns through beauty bloggers. In addition, we found the main topics of blog articles. On the found topics we correlated the products with the authors so that the product was closest to the blog audience.
We did the initial analysis using accessible and simple text methods (Fuzzy String Matching, TF-IDF, NMF), but already at this level we obtained the main results, which were then only refined.
It turned out that this cosmetic company works with 30% of the investigated authors. Of course, the beauty brand was glad to receive data on the remaining 70% in order to expand its influence in the blogosphere. Later we were given access to a detailed description of the products, data on ingredients and other characteristics, which allowed us to take the work to a new level, we began to actively use Word2Vec and BigARTM. The described analysis began to evolve into a tool that perfectly complements the recommendation system prepared by the CleverDATA team for the brand.
The demonstration of our results attracted four more beauty brands with which we are now collaborating. Naturally, in the blogosphere, each brand is interested in exploring and developing its own theme, corresponding to its product niche.
The recommendations of specific bloggers to promote products change over time, because The blogosphere is growing and evolving. Therefore, a regular review of authors and monitoring of blogs is important for brands not only to promote products, but also to understand their place in the industry.
We are currently working on crawling blogs regularly and are developing the ability to quickly display the audience’s reaction to new articles with product reviews. Thus, the brand will be able to quickly receive feedback on its products without ordering expensive marketing research. We also plan to connect more information from social networks: social networks are very interesting to brands to attract a new audience.

A source
Most companies attach their products to blogging reviews based on the intuition and professionalism of marketers. In fact, brands are moving blindly, because personal acquaintances with bloggers, friendships and agreements without statistical data and analytical calculations sometimes turn out to be very unreliable.
I have to say, we found out the following:
')
- Beauty industry blogs are written mostly in a positive emotional color;
- novice bloggers tend to overestimated emotions;
- master bloggers work in a narrow emotional range;
- the hottest discussions take place on medium-sized blogs, while blog giants are turning into a broadcasting tool;
- Most beauty bloggers are ordinary people on social networks.
I think that our most interesting discoveries, which this article is devoted to, will be useful to anyone who somehow comes into contact with the promotion of products on the web. For example, whether the popularity of a blog depends on the activity of the blogger and how the audience responds to the general mood of the post. And besides this, I would like to tell about the possibilities of Text mining using the example of the analysis of the blogosphere .
Working on the project, we developed a number of approaches and techniques, which in our case showed good results, but it is ineffective to apply them on any other package without calibration. Therefore, I did not give the code, but in detail I tell about the case itself, the methods used and the main conclusions.
So let's go!
It is no secret that textual information is one of the main types of information in modern society; therefore, text analysis can not only reveal implicit patterns, but also be useful in a commercial application.
We did not have to collect data - the array was collected earlier, as a result of crawling beauty blogs. True, for our tasks it turned out to be very raw and demanded preprocessing. In addition, the texts were naturally not marked up, so it was not possible to use machine learning tools with the teacher.
Cut off the excess
A source
An array of beauty blogs consisted of about 100 thousand pages, or rather 98,496. We first were delighted: 100 thousand pages is a good corpus for the upcoming study. But it turned out that it was very noisy, and after cleaning only 59.6% remained suitable for analysis.
40.4% of the data were blank pages and error pages, pages not in English (23,461), photo and video materials without text (2,315), articles from the techcrunch.com resource not related to the beauty industry (obviously, this is a resource on which the crawler collecting material was tested, and its contribution in the general corpus was noticeable - 3,402 pages).
Of course, getting at the disposal of almost 60 thousand pages, suitable for analysis, is also not bad. It turned out that about 2 thousand unique blogs correspond to this text volume, that is, minus cloned and similar materials, this volume of text was created by two thousand unique authors.
And who is the author?
A source
Beauty and health blogs are mostly women's topics. If the exact gender composition of the entire English-language blogosphere is questionable, then everything is unambiguous in blogs about cosmetics and a healthy lifestyle: here most of the authors and readers are women. What are these women blogging talking about? This is the main question that we had to solve in order to understand how to most effectively promote the beauty industry products in the blogosphere. To answer this key question, we first try to explore how women say in blogs.
The bloggers' author style, of course, varies. But according to the size of posts, their authors can be combined into two groups: miniaturists bloggers with posts up to 100 words (20% of all authors), and bloggers who prefer full-weight texts of 200-500 words (~ 80%).
A curious correlation between the verbosity of the authors and their activity. It is impossible to say that short posts are written more than wordy ones, and that amateurs write in the Twitter format take the number of publications. By no means. We saw that the activity of the authors of the two groups was similar.
The analysis showed that very few authors write actively. Not more than 20 authors since the appearance of the blog have managed to write more than 300 posts, in most blogs - up to 100 posts, which fit into the framework of the usual statistical laws.
Talkers blog
We looked at the discussions in the blogs and found out that the posts of a very small number of bloggers are gaining more than 40 comments. The articles of most authors are not so actively discussed, and an average of 10–20 comments per publication.
Emotional flow
The first thing that comes to mind when we talk about the study of the text is the analysis of the tonality of the text, that is, the assessment of the author's emotions - whether they are positive or negative. A lot of models for analyzing emotional coloring have been proposed. Therefore, we did not reinvent the wheel and used ready-made models:
- Sentity (https://sentity.io/),
- Twinword (https://www.twinword.com/),
- Textualinsights (http://www.textualinsights.com/),
- VivekN ( https://github.com/vivekn/sentiment-web ).
Each model of emotional color evaluation was trained on its own separate corpus of texts. One gave good results on short texts (since I trained on Twitter), the other on more detailed texts (IMDB). Each of the models has its own difficulties with the color of neutral texts, but since we used 4 models, they smoothed out some of the shortcomings of each other and we got a smooth distribution, where -1 means extremely negative emotional evaluation, and +1 is extremely positive.
The combination of four independent models gave the following distribution of texts by emotional coloring.
We see an asymmetric quasinormal distribution with a center around 0.72 and a heavy right tail. This means that the absolute majority of blogs have a positive emotional tone. The shift of the average emotional coloring to the positive area is an amazing fact that you can talk about with high statistical significance and which you can easily check on your own by reading several women's blogs taken at random.
If you look at how bloggers are distributed according to their activity (analysis of the number of pages), you will find that the most prolific bloggers by emotional color work in a very narrow range: 0.74 ± 0.03.
In this case, it is very curious that professional bloggers work in such a narrow range of emotional coloring - as if using some resonant frequency of their audience. Perhaps, a feedback system is obtained: an author with a neutral article receives feedback from readers through comments and next time adjusts to the enthusiastic mood of the audience.
It can be assumed that such a narrow range of moods is associated with professional deformation. However, our
Negotiability
Does blog discussion depend on his activity? Surprisingly, no. In the most active blogs, we see fewer comments.
Perhaps this is due to the fact that active bloggers with a large audience have already gained such authority that it is hard to argue with them.
The dependence of the discussion on the emotional color came as a surprise to us. The most discussed blogs are in the positive area of emotional color. It should be borne in mind that this (as shown in the graphs above) are not the most active blogs. The conclusion is obvious: to provoke a discussion, it turns out that it is enough just to praise something beyond measure.
Blog popularity
In order to evaluate the effectiveness of blogs, in terms of disseminating information (do they read them, do reposts), we tried to use ready-made tools for estimating Internet traffic.
Among the metrics reflecting the number of readers and citations in the network, I will highlight the following.
Alexa Rank - a popular counter for the number of visitors and the number of site views, is not established on all Internet resources, so it is not always possible to use its data.
The Yandex Thematic Citation Index (TIC, Thematic Yandex Citation Index ) defines the “authoritativeness” of an Internet resource, taking into account the qualitative characteristics of links to it from other sites, but is not very common in the English-language segment of the Network.
Google Page Rank - calculates the quantity and quality of links to the blog in order to assess the importance of the resource for the audience; is the main indicator for the promotion of sites. The main advantage of Google Page Rank is that it is present in all sites, but in many web pages it is clearly inadequate (and this is its big drawback). In addition, because of the terms of the license agreement, there are restrictions on using Google Page Rank, which makes it difficult to use it even for studies such as ours.
All of the above determined our choice: we tried YandexTIC and AlexaRank. I note that all these metrics are related to the volume of the audience (how many times the author is cited, how many people read it), have their own shortcomings and therefore cannot claim to be exhaustive. Therefore, it is worth looking for additional tools to assess the popularity of the author.
In order to somehow measure the popularity of the authors, we resorted to the Klout score . This metric is used in social networks to assess the influence of a person: his social connections and the citation of his posts. This metric, independent of the previous ones, assesses both the audience of readers and the number of reposts in social networks. It is noteworthy that a loud case was associated with the Klout score in 2011: two candidates claimed the post of vice-president of one of the companies, one of whom advised giants such as America Online , Ford and Kraft for 15 years, while the second could not boast such an outstanding experience but he had a weighty trump card - Klout score equal to 67. In the aforementioned case, a candidate with a higher Klout score received a position. In our case, it turned out that for our authors, the average Klout score is 40.1. Perhaps for a vice president with fifteen years of experience such a Klout score will be low, but for our bloggers this is a normal value: the studied beauty bloggers are not centers of gigantic social clusters, “our” bloggers are closer to ordinary people with average activity in the network .
If you trace the relationship of Klout score and emotional color, you can find an interesting trend.
The graph shows that there is a group of bloggers who have a low Klout score, and the emotional color is clearly higher than the “resonant” value. This means that such an author is just beginning to write (therefore there are few articles), but his emotional color is overestimated. Perhaps this is a psychological phenomenon associated with a new activity: the author tries to embellish either on purpose or in his “rose-colored glasses”, i.e. he himself is in high spirits. In any case, if the author continues to write, he will evolve into lower emotions through feedback in the comments.
Working with the brand
We worked with the trademark, the real name of which we, of course, will not reveal, and in the article for convenience we call it “Baba Yaga”. All products of this brand have extended, wordy names, for example, “Face Cream Baba Yaga”.
We applied the Fuzzy String Matching technique to the entire body of texts and tried to find references to the brand and its products in all the texts.
Fuzzy String Matching is based on an analysis of Levenshtein distance , which indicates letter differences in words. Strictly speaking, the Levenshtein distance determines the minimum number of changes to a single character (its removal, replacement, addition) necessary to turn one word into another. The distance obtained using the Python fuzzywuzzy module is normalized in the range from 0 to 100. Thus, completely different words will have a similarity measure equal to 0, and identical words will have a similarity measure equal to 100. For example, in a bearded joke about the difference between the bread and beer measure of similarity will be zero: in order to get beer from bread, you need to replace all four letters.
It should be noted that we were lucky with the brand names of the products, since they were not monosyllabic (like the well-known boa soap), but consisted of several words by which one could understand the type and, in part, the purpose of the product, for example, “Baba Yaga Face Oil”. Fuzzy String Matching allows you to catch partial references with appropriate settings, for example, “Face Oil”, and we tried to play with it.
Posts in which the desired product was mentioned by 90% in the Fuzzy String Matching metric were marked as “good”. The brand had about 100 products, so each article was tested for each product more than 100 times.
The relevance rating for the author was taken as the sum of all “good” articles. Normalization for the number of articles was not intentionally introduced so that authors with a large number of articles take the lead.
Subsequently, we used the natural logarithm of the resulting rating. For example, authors with 30, 10, and five “good” articles received a corresponding relevance rating of 3.4, 2.3, and 1.6.
The approach is simple, however, due to the large number of articles and a large number of products, the law of large numbers and the CLT (central limit theorem) began to work, and we received reasonable estimates.
To speed up the process and improve accuracy, we switched to using the distance obtained using the Word2Vec model; however, even with the initial approach, we obtained a result that can be used in further work.
Authors rating
Based on the listed techniques, we built the authors rating. It is based on:
- the number of blog posts
- number of comments
- AlexaRank + YandexTIC metrics,
- degree of relevance of a blog to brand products,
- emotional color
- Klout score.
It should be noted that we don’t give preference to bloggers with a large number of pages, because there are both active blogs with a volume of more than 500 posts, and low-active authors with a number of posts less than 100. There are also no preferences for the number of comments. I note that in terms of emotional color, they are all positive and work in the range from 0.70 to 0.78.
We have carefully studied the leader of the list. It turned out that he had published an article dedicated to our brand. It was a laudatory ode to the whole brand, without analyzing and describing specific products.
So, the rating of bloggers is built, now we need to connect authors and products that they can give for review. For this you need:
- select products for review,
- highlight the main themes of the authors,
- match selected topics with product names,
- find the optimal connection between the product and the blog.
Selection of products for promotion
Products for promotion were chosen almost arbitrarily. In fact, the choice fell on them due to the fact that the statistics of their sales seriously stood out against the background of other products.
The first two products were very popular, which means that it was possible to further increase the number of potential buyers.
The second two selected products have recently entered the market and have not yet had time to show themselves to the full. Promotion would definitely not hurt them. These products stand out on the graph of the dependence of the value of the product on the number of its sales.
In principle, such an analysis can be carried out for any of the products. The choice of a particular product is not fundamental.Authors and their topics
In the blogs of each author you can find topics interesting for brand promotion. What do the authors write about? To find out the list of topics for each blog, we will create a matrix, each row of which will correspond to a post, indicate the keywords in the columns, and the cell color will indicate the TF-IDF index (you can read about the use of the TF-IDF method, for example, here and here ) keyword. Accordingly, the more intensely the cell is colored, the more references to the word we have found and the more important this word in context. Examples of words for the formation of the table: "make-up", "face", "body", "scrub", "lotion", "oil", "cleansing", "conditioner", etc.
Next, the NMF method is applied , which allows us to decompose our matrix into two smaller ones: “authors” / “intermediate measurement” and “intermediate measurement” / “words”. The only factorization condition we have imposed is that the values should not be negative, that is, they should all be greater than or equal to 0.
“Intermediate measurement” in this case can be interpreted as topics. Thus, we laid out the authors on the themes of their texts.
The NMF method used to obtain the topics of texts can usually compete with the LDA and LSA (pLSA) methods, but one more powerful tool in this area is worth mentioning : BigARTM , which we are currently switching to. It should be noted that the basic idea of matrix decomposition is also present in the BigARTM method, but its advantage lies in the flexible possibility of using regularizers
To each according to the possibilities
Now you need to compare the name of the brand products with the selected topics. This can be done using the Fuzzy String Matching approach already used, but it is better and more accurate to use the distance measured using the Word2Vec model.
One thing to consider here: if the product name is fully spelled out in the title of the post, most likely it was a review post, that is, the author has already written about the product and he shouldn’t suggest to do it again.
We get a colorful matrix, where the color indicates the degree of correlation of the author with the product. The authors-products matrix is sorted by our authors rating.
The authors' rating was based in part on the mentioning of the brand’s products in the texts. After sorting by authors, color distribution can be observed, which is focused on authors with high ratings and fading as the rating decreases.
This color distribution was obtained using a separate mathematical approach (TF-IDF, NMF, etc), and it is in good agreement with our initial result obtained using simple counting of references. Thus, on the one hand, we confirm the adequacy of our rating, and on the other hand, we demonstrate the reasonableness of the results obtained using a number of more complex mathematical techniques. The consistency of the results obtained by various methods speaks in our favor.
To promote the product, we do not need to involve a lot of people. Take the first forty authors. For them, the matrix will look like this:
From the author-product matrix, we extract the most resonant peaks, after which the column with the peak is discarded. Thus, for each author, we get only one product. So, our goal has been achieved: the authors have established a connection with the products.
Summing up
Thus, according to the results of the study of the initial body of articles of beauty blogs using the Klout score social activity metrics, as well as taking into account the emotional color of the articles, we discovered a number of features of beauty bloggers. These features must be considered when organizing advertising campaigns through beauty bloggers. In addition, we found the main topics of blog articles. On the found topics we correlated the products with the authors so that the product was closest to the blog audience.
We did the initial analysis using accessible and simple text methods (Fuzzy String Matching, TF-IDF, NMF), but already at this level we obtained the main results, which were then only refined.
It turned out that this cosmetic company works with 30% of the investigated authors. Of course, the beauty brand was glad to receive data on the remaining 70% in order to expand its influence in the blogosphere. Later we were given access to a detailed description of the products, data on ingredients and other characteristics, which allowed us to take the work to a new level, we began to actively use Word2Vec and BigARTM. The described analysis began to evolve into a tool that perfectly complements the recommendation system prepared by the CleverDATA team for the brand.
The demonstration of our results attracted four more beauty brands with which we are now collaborating. Naturally, in the blogosphere, each brand is interested in exploring and developing its own theme, corresponding to its product niche.
The recommendations of specific bloggers to promote products change over time, because The blogosphere is growing and evolving. Therefore, a regular review of authors and monitoring of blogs is important for brands not only to promote products, but also to understand their place in the industry.
We are currently working on crawling blogs regularly and are developing the ability to quickly display the audience’s reaction to new articles with product reviews. Thus, the brand will be able to quickly receive feedback on its products without ordering expensive marketing research. We also plan to connect more information from social networks: social networks are very interesting to brands to attract a new audience.
Source: https://habr.com/ru/post/329892/
All Articles