The largest Git repository in the world
Three months have passed since I published my first article about our attempts to scale up Git for very large projects using an initiative that we called the “Git Virtual File System”. Let me remind you: GVFS, in conjunction with some edits to Git, allows you to work with VERY large repositories, virtualizing both the .git folder and the working directory. Instead of downloading the entire repository and checking all the files, the tool dynamically downloads only those fragments that you need, identifying them based on what you have been working on up to this point.
During this time, a lot of things happened, and I want to share with you the news. Three months ago, GVFS was just a dream. Not in the sense that it did not exist - we had a ready implementation - but in that it had not yet shown itself in action. We tried it on large repositories, but did not manage to implement it in the workflow for any significant number of developers. Therefore, we had only a speculative belief that everything will work. Now we have confirmation of this.

Today I wanted to be presenting the results. In addition, we will announce for users the following steps that we plan to take in order to develop GVFS: in particular, adding the ability to contribute to open source and improving functionality in accordance with the needs of our company, partners and customers.
')
During these three months, we have almost completed the Git / GVFS implementation process for the team working with Windows at Microsoft.
If in a nutshell: Windows codebase consists of 3.5 million files; when you upload it to Git, you get a repository about 300 gigabytes in size. Moreover, the company employs about 4,000 engineers; The engineering system daily produces 1,760 assemblies on 440 branches, in addition to pull requests for build validation. All these three circumstances (the number of files, the size of the repository, the pace of work) greatly complicate the case even separately, and taken together make providing a positive experience an incredibly difficult task. Before switching to Git, we used Source Depot and the code was distributed over 40+ repositories, we even had a special tool to manage operations.
At the time of my first article, three months ago, all of our code was stored in a single Git repository, which was used by several hundred programmers to process a very modest percentage of builds (less than 10%). Since then, we have rolled out the project for the entire engineering staff in several stages.
The first, and most massive, jump occurred on March 22, when we transferred the entire Windows OneCore team to the new system - about 2000 people. These 2,000 engineers worked on Source Depot on Friday, and returning to the office after the weekend, they found that they were in for a radically new experience with Git. All weekend, my team sat with their fingers crossed and praying that on Monday we would not be torn apart by an angry crowd of engineers who had all the work stalled. In fact, the Windows team thought very well about backup plans in case something goes wrong; Fortunately, we did not have to resort to them.
But everything went unexpectedly smoothly and the developers were able to adapt to the new conditions from the very first day without sacrificing productivity - to be honest, I was even surprised. Undoubtedly, there were also difficulties. For example, the Windows team, due to its enormous size and specificity of work, often had to merge VERY large branches (we are talking about tens of thousands of changes and thousands of conflicts). Already in the first week, it became clear that our interface for pull requests and resolution of merge conflicts is simply not adapted for such large-scale changes. I had to urgently virtualize the lists and retrieve data with the fetch command in stages so that the interface does not hang. After a couple of days, we coped with it and, on the whole, the week passed on a more positive note than we expected.
One of the ways we used to evaluate the success of the entire event is a survey of engineers. The main question we asked them was “Are you satisfied?”, Although, of course, you did not forget to ask for details. The first survey took place a week after the launch of the project and showed the following results:

(Fully satisfied: 54;
Rather satisfied: 126;
Rather unhappy: 54;
Extremely dissatisfied: 17)
The indicators are not such as to jump for joy, but given that the team just, one might say, the world turned upside down, they had to learn to work using a new scheme and they were still in the process of transition - the results seemed to be quite decent. Yes, out of 2,000 employees, only 251 responded, but welcome to the world of those who are trying to get people to participate in surveys.
Another method we used to measure success was tracking the activities of engineers to check whether the required amount of work was being carried out. For example, we fixed the number of filled code fragments for all official units. Of course, half of the company was still at Source Depot, while the second half had already switched to Git, so our measurements reflected some mixture of their results. In the graph below, you may notice a noticeable decline in the number of filled files at Source Depot and a noticeable rise in pull requests for Git, but the total number remains approximately the same throughout the segment. We decided that based on these data we can conclude: the system works and does not contain significant obstacles to use.

On April 22, we rolled out a product for another 1000 engineers; a little later, May 12 - for the next 300-400. Adaptation of each next wave occurred in the same patterns as the previous ones, and at the moment 3500 of the 4,000 Windows engineers switched to Git. The remaining teams are currently bringing their projects to completion and are trying to determine the optimal time for the transition, but I think by the end of the month all the staff will be covered.
The amount of data the system works with is astounding. Let's look at specific numbers:
As you can see, this is a huge number of operations on a very extensive code base.
The survey shows that not everyone is satisfied with the status quo. We have collected a lot of data on this subject, and the reasons are very different - from the fact that not all tools support Git, to the annoyance that you have to learn something new. But the main problem is performance, and that's what I want to make out in detail. Rolling out Git, we knew that in terms of performance, it was still flawed, and we learned a lot in the implementation process. We track performance for a number of key operations. Here are the data that telemetry systems have collected on the work of 3,500 engineers using GVFS.
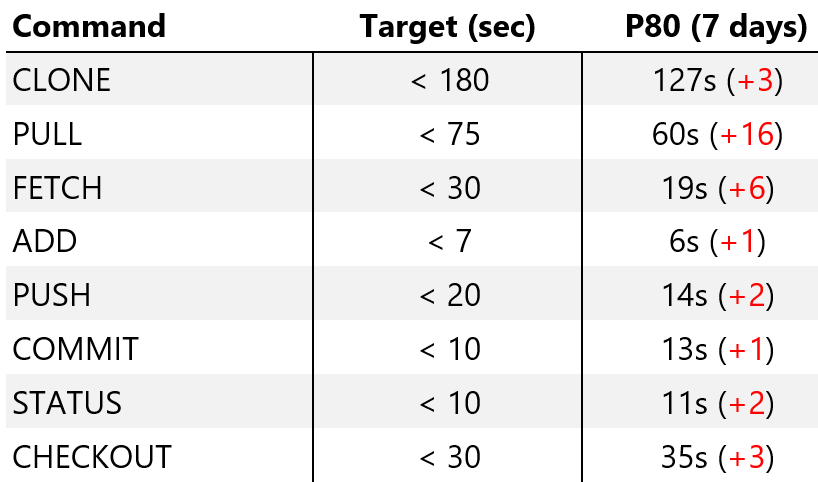
Here you see the “goal” (we counted it as the worst of the allowable values — not what we are striving for, but a threshold, below which it is impossible to lower the system to work at all). The results for the 80th percentile for the last seven days and the difference with the results of the previous week are also shown. (As you can see, everything slows down - we will talk about this in more detail later).
So that you have something to compare with, I’ll say this: if we tried to do something similar on “classic Git”, before we started working on it, many of the teams would be executed from thirty minutes to several hours, and some would never have come to completion. The fact that the majority is being processed in 20 seconds and less is a huge step forward, although in the constant 10-15 second waiting intervals, too, of course, nothing good.
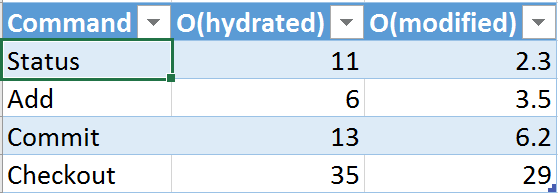
When we just rolled out the project, the results were much better. This has become for us one of the main discoveries. If you read the introductory post , where I give a general idea of GFVS, it says how we worked on Git and GVFS to make the number of operations not proportional to the total number of files in the repository, but the number of "read" files. As it turns out, over time, engineers are creeping apart in a code base and touching more and more files, which leads to a problem that we call “over hydration”. As a result, we have a bunch of files that someone once touched, but after that did not use and definitely did not make any changes. As a result, performance drops. People can “clean up” their lists of calls, but this is an extra hassle and no one does, and the system’s work slows down and slows down.
This forced us to launch another series of modifications to improve performance called “O (modified)”, which change many of the key commands, making them proportional to the number of modified files (in the sense that there are changes for which the commit has not yet been made). We’ll add these changes to the main version that week, so I don’t have any static data yet, but the testing of the pilot version has shown good results.
I do not yet have all the values, but I selected for example a few fields from the table above and inserted the corresponding numbers in the O (hydrated) column. In the added column O (modified) I gave the results that we obtained for the same commands using the optimized version that we are going to roll out next week. Unit of measurement there and there - seconds. As you can see, in general and in general, noticeable progress is observed: somewhere the speed has increased slightly, somewhere - twice, and somewhere - five. We have high hopes for these improvements and we expect that they will qualitatively change the user experience. I’m not quite happy (I’ll not calm down until Status takes less than a second), but still we’ve made great progress.
Another important area of performance that I did not touch on in the previous post is the geographical distribution of teams. Windows engineers are scattered around the globe - the United States, Europe, Central Asia, India, China, and so on. Pulling large amounts of data over long distances, often with far from ideal bandwidth, is a serious problem. To cope with it, we created a proxy solution on Git for GVFS, which allows you to cache data from Git at the output. We also used a proxy to unload very large amounts of traffic (say, build servers) from the main Visual Studio Team Services service, so that the user experience does not suffer even during the hours when the load is maximum. In total, we have 20 proxies for Git (which, by the way, we simply incorporated into the already existing Team Foundation Server Proxy) around the world.
To give you a better idea of what effect this has had, let me give you an example. The Windows Team Services account is located in the Azure data center, on the west coast of the United States. Above, I pointed out that for a Windows engineer, the cloning operation on the 80th percentile takes 127 seconds. Since most of the engineers work from Redmond, this value is relevant primarily for them. We conducted a test at the North Carolina branch, which is both farther from the center and has less bandwidth. Without using a proxy for the same operation, it took about 25 minutes. With a configured and updated proxy, the time was reduced to 70 seconds (that is, faster than in the Redmond office - the team does not use a proxy and hundreds of miles of Internet cables separate them from Azure). 70 seconds to 25 minutes is an improvement of almost 95%.
In general, Git with GVFS is absolutely ready to use and can be applied to projects of incredible scale. The results show that the productivity of our engineers does not suffer. However, we still have a lot of work to do before the system will be improved so that the staff will be pleased with it. The work done in O (modified), which we will roll out next week, will be a big step in this direction, but it will take several months of additional work to say with a clear conscience that everything that needs to be done.
If you want to learn more about the technical difficulties that we encountered in the process of scaling Git and ensuring a good level of performance, I recommend a series of articles on scaling Git and GVFS from Saeed Noursalehi. Very fascinating reading.
GVFS is an open source project, and we invite everyone to try it out. All you have to do is download and install it, create an account in Visual Studio Team Services with the Git repository, and you can proceed. Since the first publication of GVFS, we have progressed well. Among the most significant changes include:
1. We began to regularly update the code base, gradually moving to the "open" model of development. At the moment, all recent changes (including everything that was done for O (modified)) have been published, and we plan to periodically download updates in the future.
2. At the time of the first publication, we were not ready to accept input from third-party developers. Today we have reached the stage when we can officially declare that we are open to this practice. It seems to us that the basic infrastructure is already sufficiently laid to give people the opportunity to take and develop it with us. If someone wants to connect and help, we will be happy.
3. GVFS relies on the Windows file system, which we call GVFlt. Until now, the driver, access to which we have provided, was unsigned (as it was still being actively worked on). Obviously, this greatly complicated the lives of those who wanted to try it out. Now we have released a signed version of GVFlt, in which all roughness has been eliminated (so, you no longer have to disable BitLocker for installation). But although we have a signed GVFlt driver, this is only a temporary solution. We plan to implement the relevant features in a future version of Windows and are currently working on the details.
4. After speaking at the Git Merge conference, we began to actively discuss the nuances of scaling Git and, in particular, GVFS with a wide range of professionals interested in this topic. We had a very productive talk with other large companies (Google, Facebook), which faced the same difficulties, and began to share our experience and approach. We also worked with several popular Git clients to make sure they are compatible with GVFS. These included:
We will continue to work hard on scaling Git to accommodate large teams and massive code bases at Microsoft. Since we first started talking about this project three months ago, a lot has happened. In particular, we:
It was an exciting experience for Microsoft and a serious challenge for my team and the Windows team. I am delighted with what we have already achieved, but I am not inclined to underestimate the amount of work that still remains. If you also often find yourself in situations where you have to work with very large code bases, but with all your heart you want to switch to Git, I urge you to try GVFS. At the moment, Visual Studio is the only backend solution that supports the GVFS protocol with all the innovations. In the future, if the project will be in demand, we will add GVFS support also to Team Foundation Server; We also negotiated with other Git services, whose creators are considering the possibility of ensuring compatibility in the future.
During this time, a lot of things happened, and I want to share with you the news. Three months ago, GVFS was just a dream. Not in the sense that it did not exist - we had a ready implementation - but in that it had not yet shown itself in action. We tried it on large repositories, but did not manage to implement it in the workflow for any significant number of developers. Therefore, we had only a speculative belief that everything will work. Now we have confirmation of this.
Today I wanted to be presenting the results. In addition, we will announce for users the following steps that we plan to take in order to develop GVFS: in particular, adding the ability to contribute to open source and improving functionality in accordance with the needs of our company, partners and customers.
')
Windows to Git: Live
During these three months, we have almost completed the Git / GVFS implementation process for the team working with Windows at Microsoft.
If in a nutshell: Windows codebase consists of 3.5 million files; when you upload it to Git, you get a repository about 300 gigabytes in size. Moreover, the company employs about 4,000 engineers; The engineering system daily produces 1,760 assemblies on 440 branches, in addition to pull requests for build validation. All these three circumstances (the number of files, the size of the repository, the pace of work) greatly complicate the case even separately, and taken together make providing a positive experience an incredibly difficult task. Before switching to Git, we used Source Depot and the code was distributed over 40+ repositories, we even had a special tool to manage operations.
At the time of my first article, three months ago, all of our code was stored in a single Git repository, which was used by several hundred programmers to process a very modest percentage of builds (less than 10%). Since then, we have rolled out the project for the entire engineering staff in several stages.
The first, and most massive, jump occurred on March 22, when we transferred the entire Windows OneCore team to the new system - about 2000 people. These 2,000 engineers worked on Source Depot on Friday, and returning to the office after the weekend, they found that they were in for a radically new experience with Git. All weekend, my team sat with their fingers crossed and praying that on Monday we would not be torn apart by an angry crowd of engineers who had all the work stalled. In fact, the Windows team thought very well about backup plans in case something goes wrong; Fortunately, we did not have to resort to them.
But everything went unexpectedly smoothly and the developers were able to adapt to the new conditions from the very first day without sacrificing productivity - to be honest, I was even surprised. Undoubtedly, there were also difficulties. For example, the Windows team, due to its enormous size and specificity of work, often had to merge VERY large branches (we are talking about tens of thousands of changes and thousands of conflicts). Already in the first week, it became clear that our interface for pull requests and resolution of merge conflicts is simply not adapted for such large-scale changes. I had to urgently virtualize the lists and retrieve data with the fetch command in stages so that the interface does not hang. After a couple of days, we coped with it and, on the whole, the week passed on a more positive note than we expected.
One of the ways we used to evaluate the success of the entire event is a survey of engineers. The main question we asked them was “Are you satisfied?”, Although, of course, you did not forget to ask for details. The first survey took place a week after the launch of the project and showed the following results:
(Fully satisfied: 54;
Rather satisfied: 126;
Rather unhappy: 54;
Extremely dissatisfied: 17)
The indicators are not such as to jump for joy, but given that the team just, one might say, the world turned upside down, they had to learn to work using a new scheme and they were still in the process of transition - the results seemed to be quite decent. Yes, out of 2,000 employees, only 251 responded, but welcome to the world of those who are trying to get people to participate in surveys.
Another method we used to measure success was tracking the activities of engineers to check whether the required amount of work was being carried out. For example, we fixed the number of filled code fragments for all official units. Of course, half of the company was still at Source Depot, while the second half had already switched to Git, so our measurements reflected some mixture of their results. In the graph below, you may notice a noticeable decline in the number of filled files at Source Depot and a noticeable rise in pull requests for Git, but the total number remains approximately the same throughout the segment. We decided that based on these data we can conclude: the system works and does not contain significant obstacles to use.
On April 22, we rolled out a product for another 1000 engineers; a little later, May 12 - for the next 300-400. Adaptation of each next wave occurred in the same patterns as the previous ones, and at the moment 3500 of the 4,000 Windows engineers switched to Git. The remaining teams are currently bringing their projects to completion and are trying to determine the optimal time for the transition, but I think by the end of the month all the staff will be covered.
The amount of data the system works with is astounding. Let's look at specific numbers:
- In total, over 4 months of the repository existence, more than 250,000 Git commits were committed;
- 8,421 average pushes per day;
- 2,500 pull requests and 6,600 code inspections on average per working day;
- 4,352 active branches;
- 1,760 official assemblies per day.
As you can see, this is a huge number of operations on a very extensive code base.
GVFS performance when working on large-scale projects
The survey shows that not everyone is satisfied with the status quo. We have collected a lot of data on this subject, and the reasons are very different - from the fact that not all tools support Git, to the annoyance that you have to learn something new. But the main problem is performance, and that's what I want to make out in detail. Rolling out Git, we knew that in terms of performance, it was still flawed, and we learned a lot in the implementation process. We track performance for a number of key operations. Here are the data that telemetry systems have collected on the work of 3,500 engineers using GVFS.
Here you see the “goal” (we counted it as the worst of the allowable values — not what we are striving for, but a threshold, below which it is impossible to lower the system to work at all). The results for the 80th percentile for the last seven days and the difference with the results of the previous week are also shown. (As you can see, everything slows down - we will talk about this in more detail later).
So that you have something to compare with, I’ll say this: if we tried to do something similar on “classic Git”, before we started working on it, many of the teams would be executed from thirty minutes to several hours, and some would never have come to completion. The fact that the majority is being processed in 20 seconds and less is a huge step forward, although in the constant 10-15 second waiting intervals, too, of course, nothing good.
When we just rolled out the project, the results were much better. This has become for us one of the main discoveries. If you read the introductory post , where I give a general idea of GFVS, it says how we worked on Git and GVFS to make the number of operations not proportional to the total number of files in the repository, but the number of "read" files. As it turns out, over time, engineers are creeping apart in a code base and touching more and more files, which leads to a problem that we call “over hydration”. As a result, we have a bunch of files that someone once touched, but after that did not use and definitely did not make any changes. As a result, performance drops. People can “clean up” their lists of calls, but this is an extra hassle and no one does, and the system’s work slows down and slows down.
This forced us to launch another series of modifications to improve performance called “O (modified)”, which change many of the key commands, making them proportional to the number of modified files (in the sense that there are changes for which the commit has not yet been made). We’ll add these changes to the main version that week, so I don’t have any static data yet, but the testing of the pilot version has shown good results.
I do not yet have all the values, but I selected for example a few fields from the table above and inserted the corresponding numbers in the O (hydrated) column. In the added column O (modified) I gave the results that we obtained for the same commands using the optimized version that we are going to roll out next week. Unit of measurement there and there - seconds. As you can see, in general and in general, noticeable progress is observed: somewhere the speed has increased slightly, somewhere - twice, and somewhere - five. We have high hopes for these improvements and we expect that they will qualitatively change the user experience. I’m not quite happy (I’ll not calm down until Status takes less than a second), but still we’ve made great progress.
Another important area of performance that I did not touch on in the previous post is the geographical distribution of teams. Windows engineers are scattered around the globe - the United States, Europe, Central Asia, India, China, and so on. Pulling large amounts of data over long distances, often with far from ideal bandwidth, is a serious problem. To cope with it, we created a proxy solution on Git for GVFS, which allows you to cache data from Git at the output. We also used a proxy to unload very large amounts of traffic (say, build servers) from the main Visual Studio Team Services service, so that the user experience does not suffer even during the hours when the load is maximum. In total, we have 20 proxies for Git (which, by the way, we simply incorporated into the already existing Team Foundation Server Proxy) around the world.
To give you a better idea of what effect this has had, let me give you an example. The Windows Team Services account is located in the Azure data center, on the west coast of the United States. Above, I pointed out that for a Windows engineer, the cloning operation on the 80th percentile takes 127 seconds. Since most of the engineers work from Redmond, this value is relevant primarily for them. We conducted a test at the North Carolina branch, which is both farther from the center and has less bandwidth. Without using a proxy for the same operation, it took about 25 minutes. With a configured and updated proxy, the time was reduced to 70 seconds (that is, faster than in the Redmond office - the team does not use a proxy and hundreds of miles of Internet cables separate them from Azure). 70 seconds to 25 minutes is an improvement of almost 95%.
In general, Git with GVFS is absolutely ready to use and can be applied to projects of incredible scale. The results show that the productivity of our engineers does not suffer. However, we still have a lot of work to do before the system will be improved so that the staff will be pleased with it. The work done in O (modified), which we will roll out next week, will be a big step in this direction, but it will take several months of additional work to say with a clear conscience that everything that needs to be done.
If you want to learn more about the technical difficulties that we encountered in the process of scaling Git and ensuring a good level of performance, I recommend a series of articles on scaling Git and GVFS from Saeed Noursalehi. Very fascinating reading.
Try GVFS yourself
GVFS is an open source project, and we invite everyone to try it out. All you have to do is download and install it, create an account in Visual Studio Team Services with the Git repository, and you can proceed. Since the first publication of GVFS, we have progressed well. Among the most significant changes include:
1. We began to regularly update the code base, gradually moving to the "open" model of development. At the moment, all recent changes (including everything that was done for O (modified)) have been published, and we plan to periodically download updates in the future.
2. At the time of the first publication, we were not ready to accept input from third-party developers. Today we have reached the stage when we can officially declare that we are open to this practice. It seems to us that the basic infrastructure is already sufficiently laid to give people the opportunity to take and develop it with us. If someone wants to connect and help, we will be happy.
3. GVFS relies on the Windows file system, which we call GVFlt. Until now, the driver, access to which we have provided, was unsigned (as it was still being actively worked on). Obviously, this greatly complicated the lives of those who wanted to try it out. Now we have released a signed version of GVFlt, in which all roughness has been eliminated (so, you no longer have to disable BitLocker for installation). But although we have a signed GVFlt driver, this is only a temporary solution. We plan to implement the relevant features in a future version of Windows and are currently working on the details.
4. After speaking at the Git Merge conference, we began to actively discuss the nuances of scaling Git and, in particular, GVFS with a wide range of professionals interested in this topic. We had a very productive talk with other large companies (Google, Facebook), which faced the same difficulties, and began to share our experience and approach. We also worked with several popular Git clients to make sure they are compatible with GVFS. These included:
- Atlassian SourceTree - SourceTree was the first tool that was validated for compatibility with GVFS; An update has already been released, which introduced some changes for a smoother workflow.
- Tower - The Tower team is pleased to announce that they are working on adding GVFS support to the Windows version of the application. In the near future, the corresponding functionality will be available in a free update.
- Visual Studio - by itself, it would be nice for our own Visual Studio Git to work well with GVFS. We will implement GVFS support in version 2017.3, the first preview of which (with all the necessary support) will be released in early June.
- Git on Windows - as part of our Git scaling initiative, we made a number of changes under Git on Windows (for example, the Git command line), including support for GVFS. Now we have a special branch for Windows created on Git, but over time we want to transfer everything to the main version of the code.
Summarizing what was said
We will continue to work hard on scaling Git to accommodate large teams and massive code bases at Microsoft. Since we first started talking about this project three months ago, a lot has happened. In particular, we:
- successfully implemented a project for 3,500 engineers;
- hooked up a proxy and improved productivity;
- updated the open source and gave other users the opportunity to make edits / contributions;
- provided a signed GVFlt driver to make it easier to use the service;
- began to work with other teams to implement support in popular tools - SourceTree, Tower, Visual Studio, and so on;
- published several articles where, from a technical point of view, our approach to scaling Git and GVFS is discussed in detail.
It was an exciting experience for Microsoft and a serious challenge for my team and the Windows team. I am delighted with what we have already achieved, but I am not inclined to underestimate the amount of work that still remains. If you also often find yourself in situations where you have to work with very large code bases, but with all your heart you want to switch to Git, I urge you to try GVFS. At the moment, Visual Studio is the only backend solution that supports the GVFS protocol with all the innovations. In the future, if the project will be in demand, we will add GVFS support also to Team Foundation Server; We also negotiated with other Git services, whose creators are considering the possibility of ensuring compatibility in the future.
Source: https://habr.com/ru/post/329878/
All Articles