How IBM Watson cognitive system learns and answers questions. Part 1

Over the past ten years, technology has leaped forward. The Internet of Things, cloud systems, forms of artificial intelligence, neural networks and cognitive technologies. All this appeared relatively recently, but all this is actively changing our lives. IBM has made significant efforts to make a positive change. All this is done not for the sake of pleasure, but with a quite practical purpose. The fact is that the needs of modern science and business are extremely high. And in order to meet these needs, new tools are needed. One of them is IBM Watson, a cognitive platform that is capable of learning, identifying links between individual elements of the largest data set, and interacting with its environment, including users.
On Habrahabr and Geektimes, our company has repeatedly talked about the benefits IBM Watson can bring. But how does the system work? In general, its capabilities are based on an analysis of the environment and various factors. Thanks to this, the platform is able to make certain decisions and provide answers to the questions asked. Below is a relatively brief summary of the principles of operation of several components of the work of a cognitive system. This training, language processing and answers to questions.
How watson learns
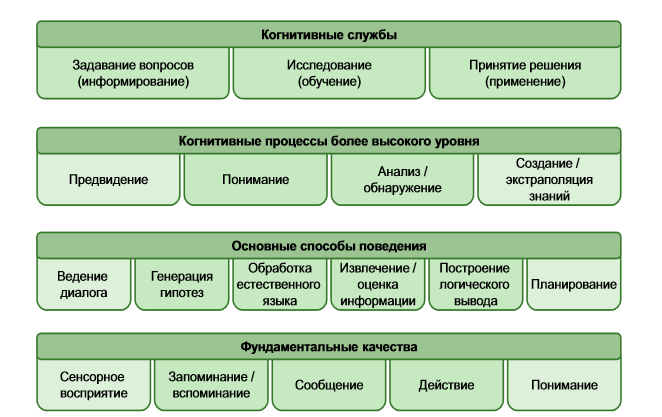
The key elements of the cognitive system work are the emulation of certain features of a person’s thinking that are involved in making decisions and answering questions.
')
Watson training is conducted in several stages. The very first one is downloading information. The system developers are trying to make it suitable for use in all areas of science, technology ... but anything.
It all starts with the download of relevant information on a specific topic in the database Watson. Here you can recall Sherlock Holmes and his explanation of the effectiveness of the deductive method and the importance of relevant knowledge. Holmes, studying a certain question, “loaded” only the information that directly related to this question into memory. The same with Watson - when developers decide to teach the system a new subject, they load only relevant information into memory which is relevant to the subject matter of the training. Outdated and not too relevant data are checked and screened out. This is an ongoing process.
Then comes the turn of IBM Watson - data pre-processing begins with the construction of indexes and other metadata, allowing for more efficient work in the future. A “knowledge graph” is created to represent the key concept of the material being mastered.
Upon completion of the preprocessing of the data, people who help Watson interpret the data begin to work again. This is done with the help of machine learning, when the expert begins to work with the system in the form of question-answer. This method helps to create linguistic patterns related to the topic being studied.
Another way to process and assimilate data is the constant interaction of Watson with users. Experts regularly evaluate this activity and help Watson improve their capabilities, answer increasingly difficult questions, update previously received information. The developers' goal is to teach the Watson cognitive system to answer questions in a way that a person does. That is, emulate human decision making. This is necessary both for science, medicine, and business.
This, in fact, is about “dynamic learning”, when Watson becomes smarter, getting feedback from users and developers, learning from their own mistakes.
How does Watson work with natural language?
Regardless of whether the question is asked orally or in writing, the system needs to be able to analyze complex semantic constructions, understanding not only the semantic but also the emotional load of the text. In order for Watson to correctly determine the meaning of the text, the developers integrated the question and answer system of content analytics into the system (Deep Question * Answering, DeepQA). This is the basis of the foundations; the work of the cognitive platform is built on this system.
Thanks to her, Watson can understand what is being said to him and give an adequate and relevant answer. But for the machine to understand the language of man is extremely difficult. Many definitions of words and terms are illogical. To take the same expression “burn with shame” - a person understands him perfectly (unless, of course, he heard before). For a machine, this expression is nonsense if this car is not a Watson. System developers are gradually teaching Watson to understand idioms, establishing lexical connections and building patterns, as mentioned above.
In addition, the system can recognize the emotional content of the text. To this end , in 2016, three APIs were immediately added : ToneAnalyzer , EmotionAnalysis and VisualRecognition . TexttoSpeech (TTS) service has been updated to provide new opportunities for emotions, as well as access to the Expressive TTS speech module API (work on it has been going on for 12 years). In general, modules and services that help the system work with natural language are developed and added constantly. This is one of the components of dynamic learning, as mentioned above. Constant progress, development is one of the objectives of the project, which is quite successfully implemented.
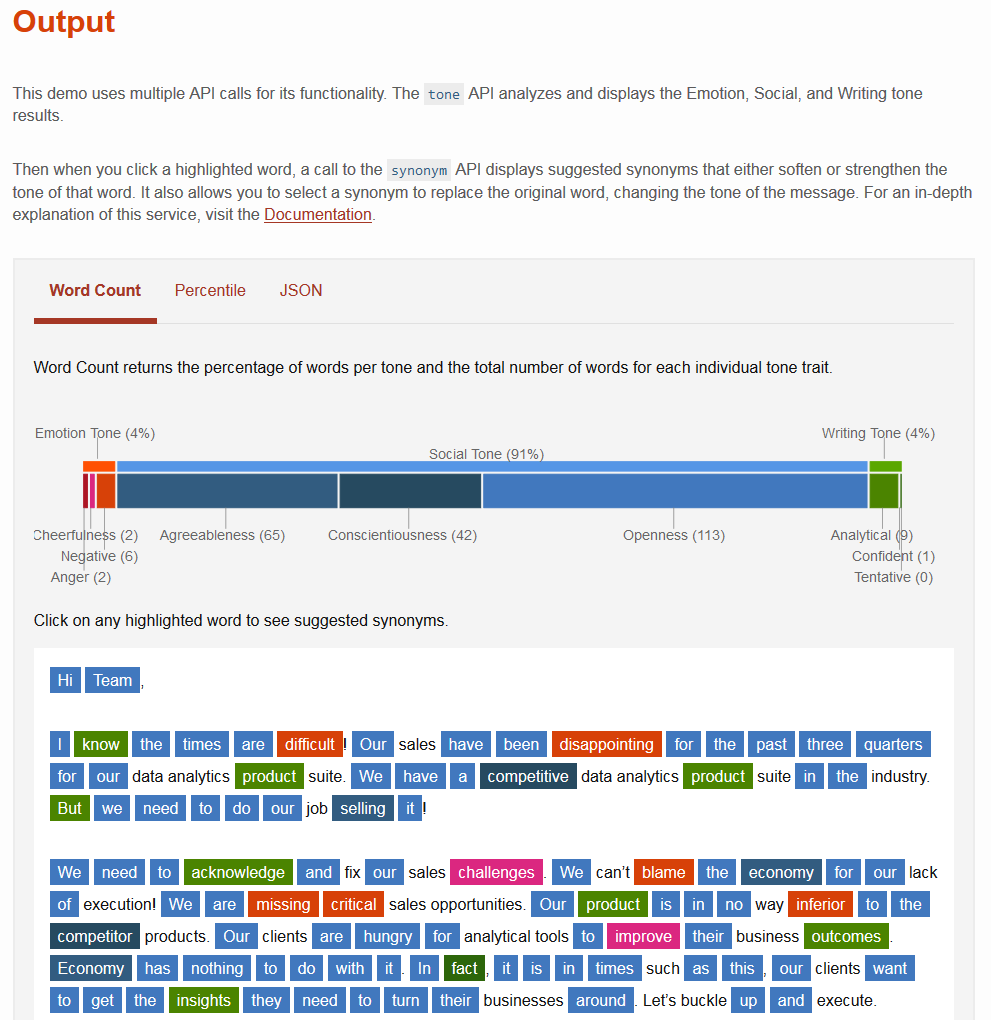
One example of an analysis of the semantic and emotional content of a letter with the IBM Watson system.
Watson is now able to define the style of presentation in the text, identify emotions, including positive and negative, as well as recognize and classify images.
How does Watson answer questions?
If simplistic, then everything looks as follows.
1. In order for the system to answer any question, there must be relevant data in its memory. This has already been mentioned above. Experts download various information into the system, where this data is indexed in order to be able to use it if necessary.
2. Further questions are sent to the system in text or voice form.
3. The questions are analyzed by the system, Watson selects a search query and begins to search for the necessary relevant information in its database. This can be compared to how Google works.
4. A number of hypotheses are generated by analyzing phrases that with a certain degree of probability can contain the desired answer. A deep comparison of the language of the question and the language of each of the possible answers is performed. Formed database of search query results.
5. Each result is evaluated in a certain way, receiving a score. This analyzes the extent to which the answer is relevant to the question area.
6. The higher the score of one of the answers, the higher it is ranked.
7. If Watson, after final analysis, considers his answer relevant and relevant, it is provided to the user.
The actual process of finding an answer to a question is much more complicated, since each phrase is worked through with the help of several algorithms, often working in parallel mode. For Watson, hundreds of logical inference algorithms have been developed. Some of them search for matching terms and synonyms, others consider temporal and spatial features, and still others search and analyze the necessary sources of contextual information.
In order to get the correct answer, the system also refers to additional data sources. For example, news on the Internet, technical literature, reference books. All materials in a row are not copied, but are checked for relevance with screening of irrelevant information. This process takes just seconds due to the tremendous performance of the cognitive platform.
Concluding this material, it is worth noting that the article reveals not all the questions of interest to our readers. Please ask questions in the comments, and we will collect the answers of our specialists and publish combined materials "based on" comments. This is probably one of the best options to answer the questions you are really interested in.
Source: https://habr.com/ru/post/329826/
All Articles