Create your own Angular 2
Hello, this article describes the mechanism of work of Angular 2. Today we look under the hood of a popular framework.
This article is a free translation of the Tobias Bosch report - The Angular 2 Compiler. You can find the link to the original report at the end of the article.
Tobias Bosch is an employee of Google and a member of the Angular development team who created most of the components of the compiler. Today he talks about how Angular works from the inside. And this is not something extremely complex.
I hope that you use some of the knowledge gained in your applications. Perhaps you, like our team, will create your own compiler or a small framework. I will talk about how the compiler works and how we achieved our goal.
')
This is all that happens between the application's input data (it can be your commands, patterns, etc.) and your running application.
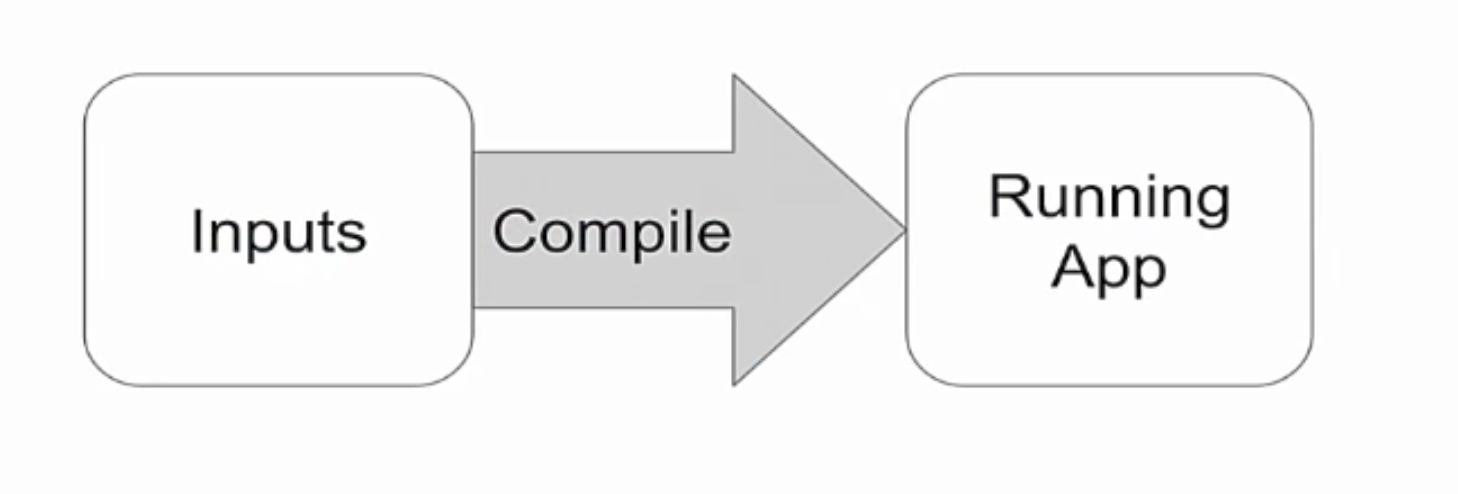
Everything that happens between them is the domain of the compiler. In appearance, it may seem like pure magic. But it is not.

First, we'll talk a little about performance: what is meant by fast work? We will talk about what kind of input data we have.
We will also talk about lexical analysis, what it is, and what the Angular 2 compiler does with analysis. We’ll talk about how Angular 2 takes the analyzed data and processes it. In general, the implementation of this process took place in three attempts; at first there was a simple implementation, then an improved one and an even more improved one. So did we. These are the stages by which we managed to achieve accelerated work of our compiler.
We will also discuss different environments, advantages and disadvantages of dynamic (Just In Time) and static (Ahead Of Time) compilations.
Imagine a situation: I wrote an application and claimed that it works quickly. What I mean? The first thing you might think is that the application loads very quickly. Did you see google amp pages? They load unreal fast. This can be attributed to the concept of "fast."
Perhaps I use a great app. I switch from one heading to another. For example, from the overview to the expanded page, and such transition occurs very quickly. This can also characterize speed.
Or, say, I have a large table and now I just change all its values. I create new values without changing the structure. This is real fast. All these are different aspects of the same concept, different things that need to be addressed in the application.
I would like to stay more detailed at the stage of transition along the paths (switching a route).
The important point is that when moving along paths, the framework destroys and recreates everything anew. It does not adhere to the structure: everything collapses and everything is recreated anew.
How can this process be made quick?
To do something quickly, you need to measure this speed. For this you need a test. One of the performance tests we use is the deep-tree performance test. You may have heard of such. This is a component that is used twice. This is a recursion of a component until a certain depth is reached.
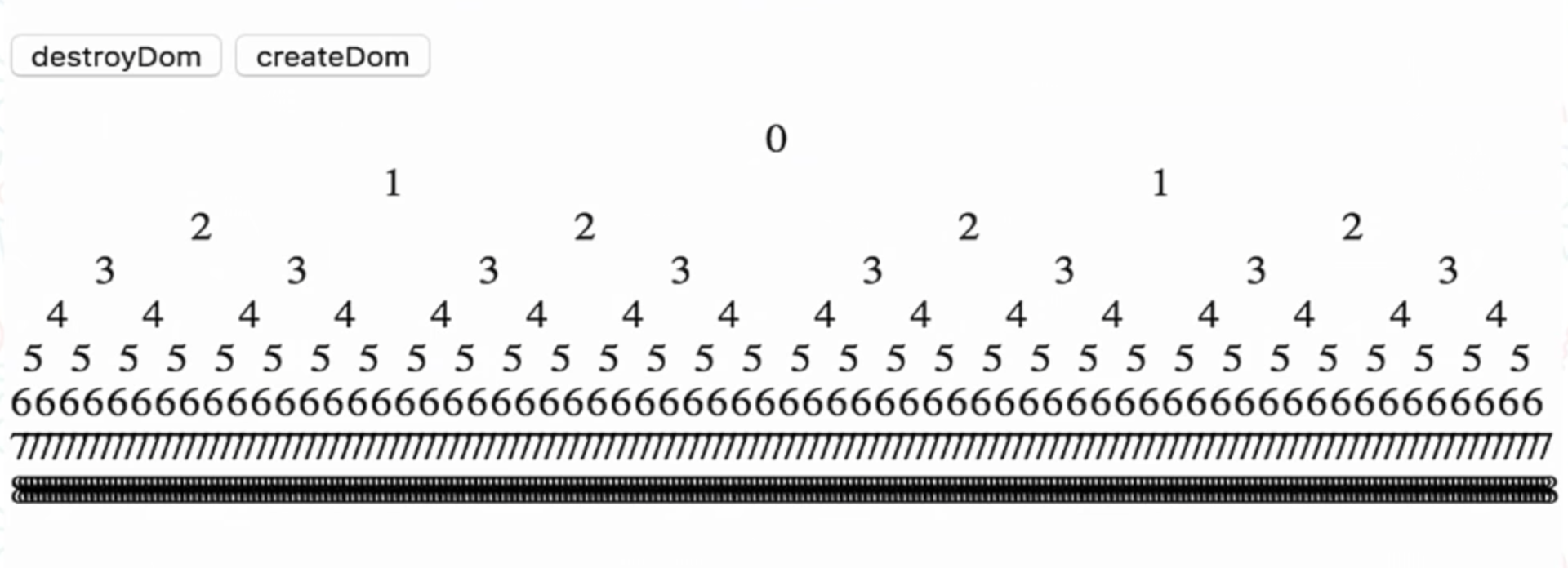
We have 512 components and buttons that can destroy or create these components. Next, we measure how much time it takes to destroy and create components. So there is a transition along the paths. Transition from one view to another. The destruction of everything is the creation of everything.
What input data do we have?
Components
We have components, and I think everyone knows them.
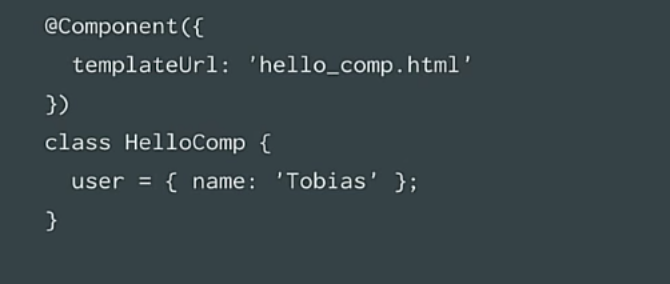
They have a template. You can make the templates inline or put them in a separate file, it is worth remembering that they have context.
Component instances are inherently the context, the data that is used to build a template. In our case, we have a user, the user has a name (in our case, this is my name).
Template
Next we have a template. This is simple HTML, here you can insert something like an input form, you can apply everything that HTML offers.
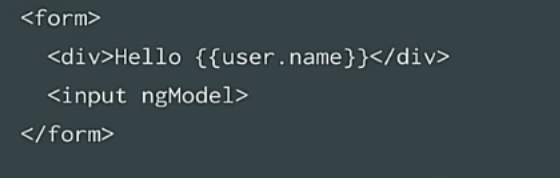
Here we have some new syntax: remember double curly brackets, square brackets and round brackets? This is the binding of Angular to properties or events. Today we will talk only about braces and what they mean. From the point of view of semantics, this means "to take data from a component and place it in a certain place." When data is changed, text should be updated.
Directives

Directives contain a selector - this is a CSS selector. The bottom line is that when Angular passes the markup, if it finds a directive that matches an element, it executes it.
Suppose we have a selector for forms, and with this we kind of say, every time we create a form element, please create this directive.
Similarly with ngModel. When you create the ngModel attribute, you must create a directive.
These directives may have dependencies. This is our expression of addiction.

The dependency has a hierarchical structure, so that ngModel requests ngForm.
And what does Angular do?
He scans the entire tree for the nearest ngForm, which is one level higher in the tree structure. It will not view single-level items, only parent elements.
There are other inputs, but we will not dwell on them in detail.
Everything that is done in Angular passes through the compiler.
Well, we have input. The next thing we need is to understand them.
Is it just a bunch of nonsense, or, after all, does it make any sense?
Suppose we have some kind of template, for example, HTML.
Template view

How can we present it in such a way that the compiler can understand it?
The analyzer is engaged in it. He reads each character and then analyzes the meaning. That is, he creates a tree. Each element has only one object. Suppose there is some name - the name of the element, there are child elements. Let's just say a text node is a JSON object with text properties. We also have item attributes. Let's just say we encode it all as nested lists. The first value is the key, the second is the value of the attribute. And so on, there is nothing complicated. Such a representation is called an abstract syntax tree (ASD, english - AST). You will often hear this concept. This is all HTML.
How can we portray the relationship of an element with data?

We can display this as follows. This is a text node, that is, we have a JSON object with text characteristics. The text is empty because initially there is no text to display. Text depends on incoming data. Incoming data is presented in this expression.
Any expressions are also analyzed for what they mean.
You cannot declare a function inside expressions or use a for loop, but we have such things as pipes with which you can work with expressions.
We can portray this expression, user.name, as a property path. And also we can catch where this expression came from from your template.
Determination of the place of expression
So why is this so important? Why is it important for us to know where exactly this expression came from?
This is because we want to show you error messages at runtime. Let's say that your user knows about these errors.
And then, are there exceptions? For example, it is impossible to read the name from undefined. If this happens, then you need to go to the error debugger and check, set a breakpoint on the first error. Then you must understand exactly where the error occurred.
Angular compiler gives you more information.
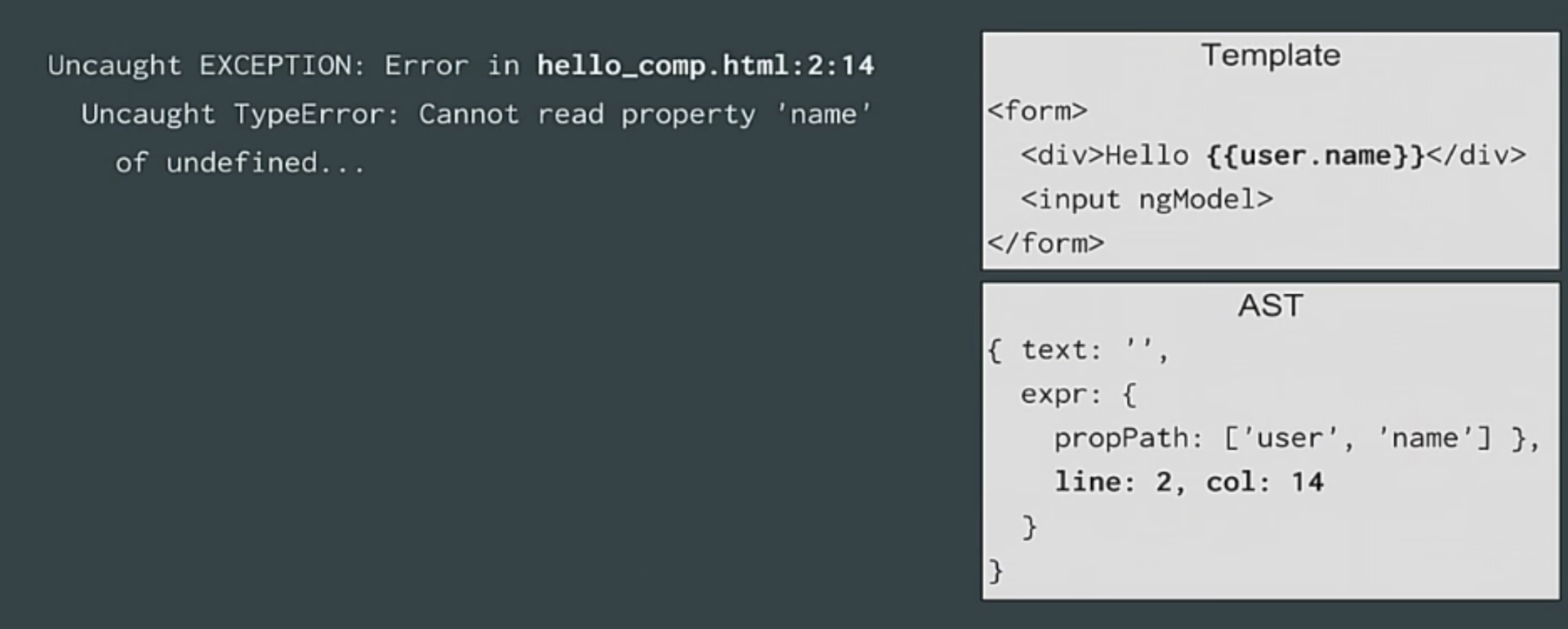
It shows exactly where in the “grow legs” pattern of this error. The goal is to show you that the error originates, for example, from this particular interpolation in the second row, column 14 of your pattern. To do this, we need the row and column numbers to be in the SDA.
Next, what analyzers do we need to build this ASD?
There are many possibilities here. For example, we can use a browser.
The browser is a great HTML parser, right? He does this every day. We had this approach when developing Angular 1, we started using the same approach when developing Angular 2.
Now we do not use the browser for such purposes for two reasons:
Obviously, there is no browser on the server. We could say: in the browser we use the browser, and on the server we use something else. So it was. But then we got into dead ends, for example, with SVG, or with commas, so we needed to have the same semantics everywhere. Therefore, it is easier to insert a fragment of JavaScript, and the analyzer. This is exactly what we do.
So we talked about HTML and expressions.
How do we present the directives we find?
We can display them through JSON objects that represent elements by simply adding another property: directives. And we refer to the constructor functions of these directives.
In our example with input data with ngModel, we can portray this element as a JSON object. It has input name, attributes, ngModel and directives. We have a pointer to constructors, and we also catch dependencies, because we need to specify that if we create ngModel, we need ngForm, and we need to pick up this information.
Given the SDA with HTML information, links and guidelines, how do we bring this all to life? How can this be done the easiest?
First, let's deal with HTML. What is the easiest way to create a DOM element? First, you can use innerHTML. Secondly, you can take an already existing item and clone it. And third, you can call document.createElement.
Let's vote. Who thinks innerHTML is the fastest? And who thinks element.cloneNode will create an element the fastest? Or maybe the fastest way is element.createElement?
Obviously, everything changes over time. But for now:
You say, "OK, let's use element.createElement to create a new DOM element."
This is how Angular 1 worked, and we also started the development of Angular 2. And by tradition, it turns out that this is not a fair comparison, at least not in the case of Angular. In the case of using Angular, we need to create some elements, but, in addition to this, we need to place these elements. In our case, we want to create new text nodes, but we also need to find the one that is responsible for user.name, because later we want to update it.
Therefore, if we compare, then we must compare both the creation and placement. If you use innerHTML or cloneNode, then you have to re-traverse the entire path of the DOM. When using createElement or createTextNode, you bypass these actions. You simply call the method and immediately get its execution. No new constructions and other things.
In this regard, if we compare createElement and createTextNode, they are both about the same in speed (depending on the number of bindings).
Secondly, much less data structures are required. You do not need to keep track of all these indices and stuff, so these methods are simpler and almost equal in speed. Therefore, we use these methods, and other frameworks also switch to this approach.
So we can already create DOM elements.
Now we need to create directives
We need to inject dependencies from the child to the parent. Suppose we have a data structure called ngElement, which includes a DOM element and directives for this element. There is also a parent element. This is a simple tree inside a DOM tree.

And how can we create DOM elements from ASD?
We have a template, we have an element from which we built an SDA. What can we do with all this?
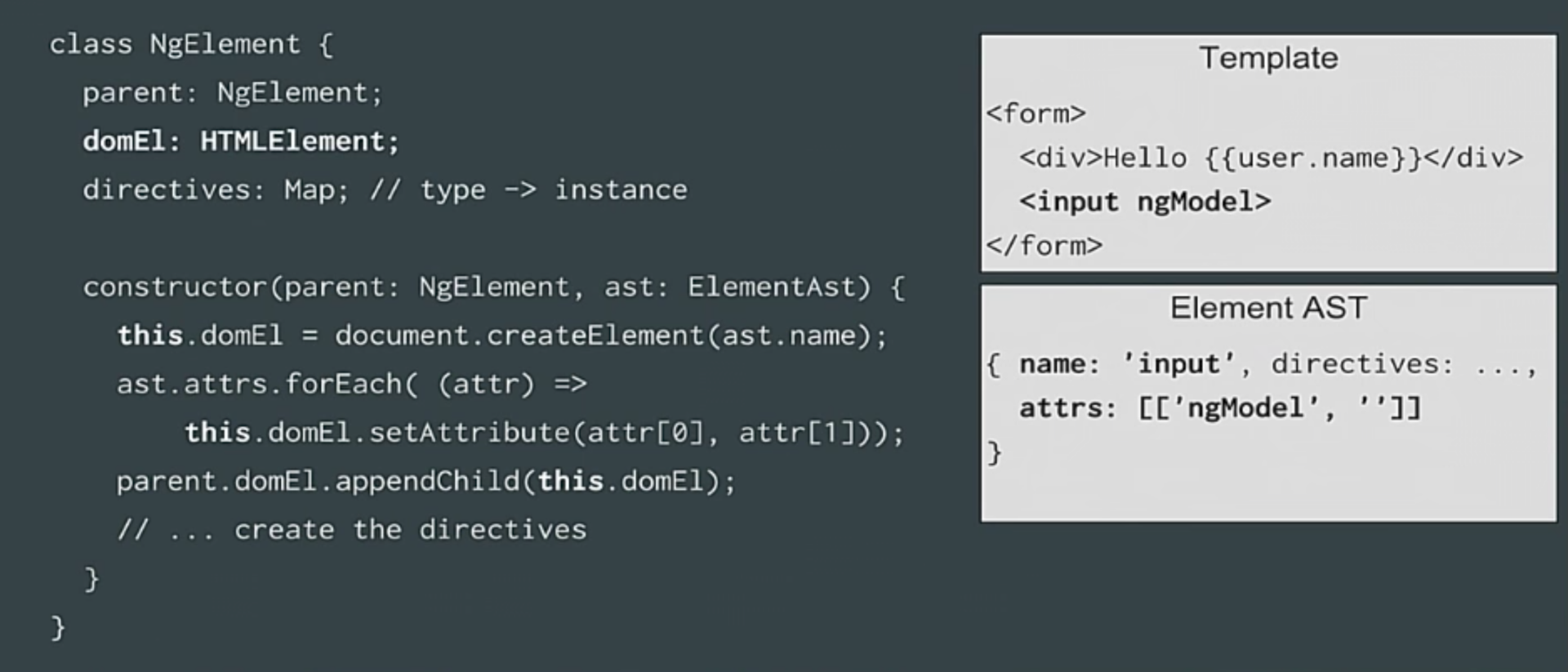
In our ngElement and constructor, we call document.createElement, we look at the attributes and assign them to the elements, and then we add the element to our parent element. As you can see, no magic.
Then go to the directives. How it works?
We look at the bindings, somehow get them (talk about this a bit later) and simply re-call new for the constructor, give it bindings and save the Map. Map will go from directive type (ngModel) to directive instances.
And all this search for directives will work this way: we will have a method that receives a directive that first checks the element itself (if it has a directive). If not, then go back to the parent and check there.
This is the easiest thing to do. We ourselves began in this direction. And it works.
Important detail: bindings. How to display bindings?
You simply create a binding class that has a target - Node. It will be a text node.
The target has a property, in our case it will be the value of the node, this is the place where the value fits. And an expression.
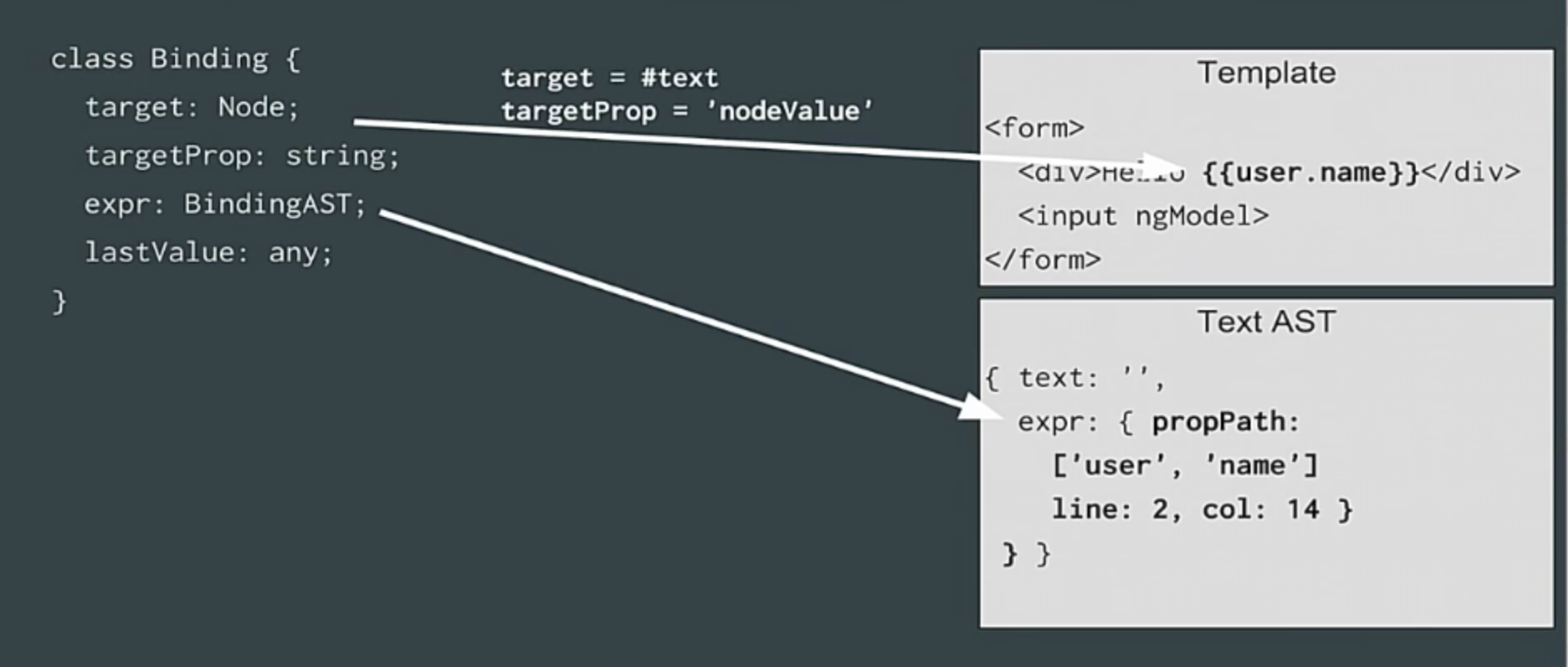
The binding works this way: every time you evaluate an expression or when it simply changes, you save it to the target.
That is, you may have the following method: first, you evaluate the expression, if it has changed - then update the target and other previously saved values.

As for the exceptions mentioned earlier, we call try catch methods to track the estimation path. When an exception is thrown, we re-generate it and create a model for it from row and column numbers.
So we get the row numbers and columns in which there are errors. This is all we associate into a presentation. This is the last data structure.
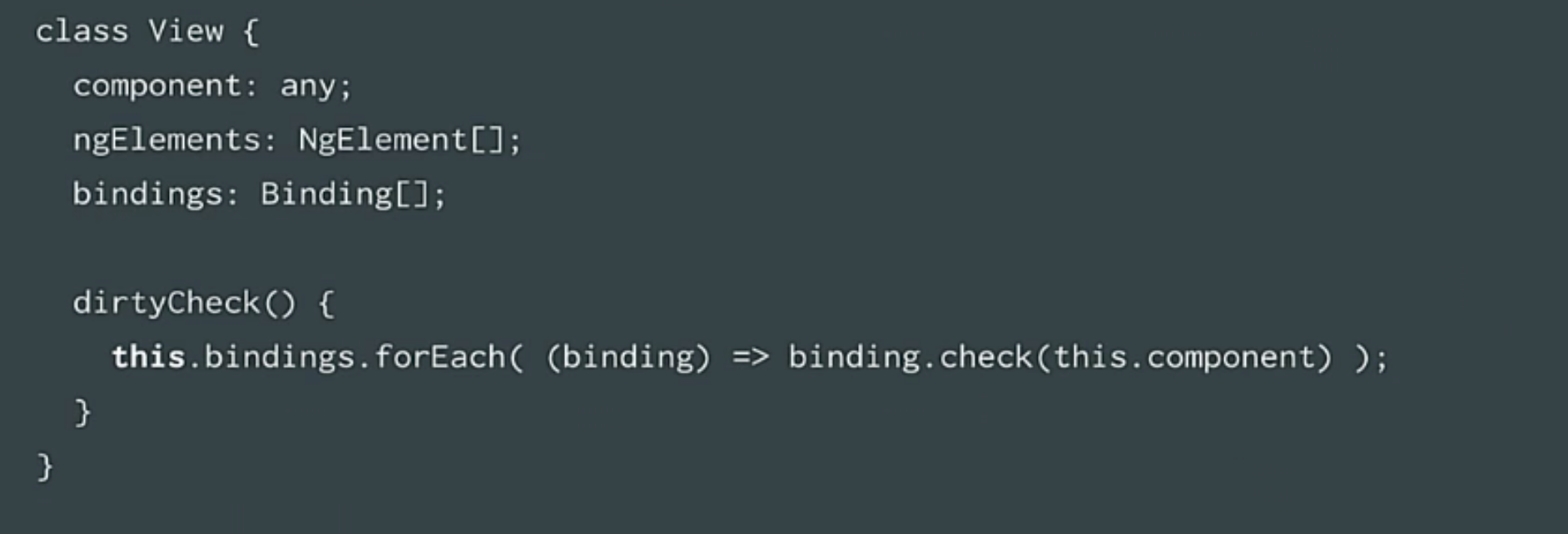
A view is an element of a template. That is, when we look at the error code - we will see a lot of views. These are just template elements. And we combine them into a presentation. A view references a component, ng-elements and bindings, as well as a dirty-check method that scans bindings and checks them.
So we finished the first stage. We have a new compiler. How fast are we? Almost at the same level as Angular 1. Not bad at all. Using the simpler approach, we achieved the same speed. But Angular 1 is not slow.

How do we speed up the process? What is the next step? What have we missed? Let's figure it out.
We need something that is related to our data structures. When it comes to data structures, in fact, this is a very difficult question. If we compare with the last program we wrote, where try-catch appears, but if we discard it, we will see that many functions slow down the process and that many points need to be optimized. If you consider the reason for the slow work of your data structure program, then this is a very difficult question, because they are scattered throughout your program. This is just an assumption that the matter is in data structures.
We conducted experiments and tried to figure it out. We watched these directives: Map inside ngElements.

It turns out that for each element in the DOM tree we create a new map? One could say that there are no directives there, we did not create them. But still, we always create a map, fill it with directives and read information from it. It may be uneconomical, it may overload the memory, the reading still takes some time too.
Alternative approach: you can say: “Okay, we only allow 10 directives for one item. Next, we create an inlinengElement class, 10 properties for directive elements and directive types, and in order to find a directive, we create 10 conditional IF statements. ” It's faster? Maybe.
It does not consume a lot of memory resources, right?
For example, setting: you set the property, not the map. Reading can be a bit slow due to 10 conditions. This is exactly the case for which the JavaScript VM has been optimized. JavaScript VM can create hidden classes (you can google them at your leisure). This makes javascript js faster. Switching to this data structure is what speeds up the processes. Later we look at the results of performance tests. Another thing that needs to be optimized for data structures is the reuse of existing instances.
You can ask a logical question - If some lines are destroyed and others are restored, then why not cache these lines in the cache and change the data as soon as the lines appear? So we did. We created the so-called view cache, which restores old instances of views.
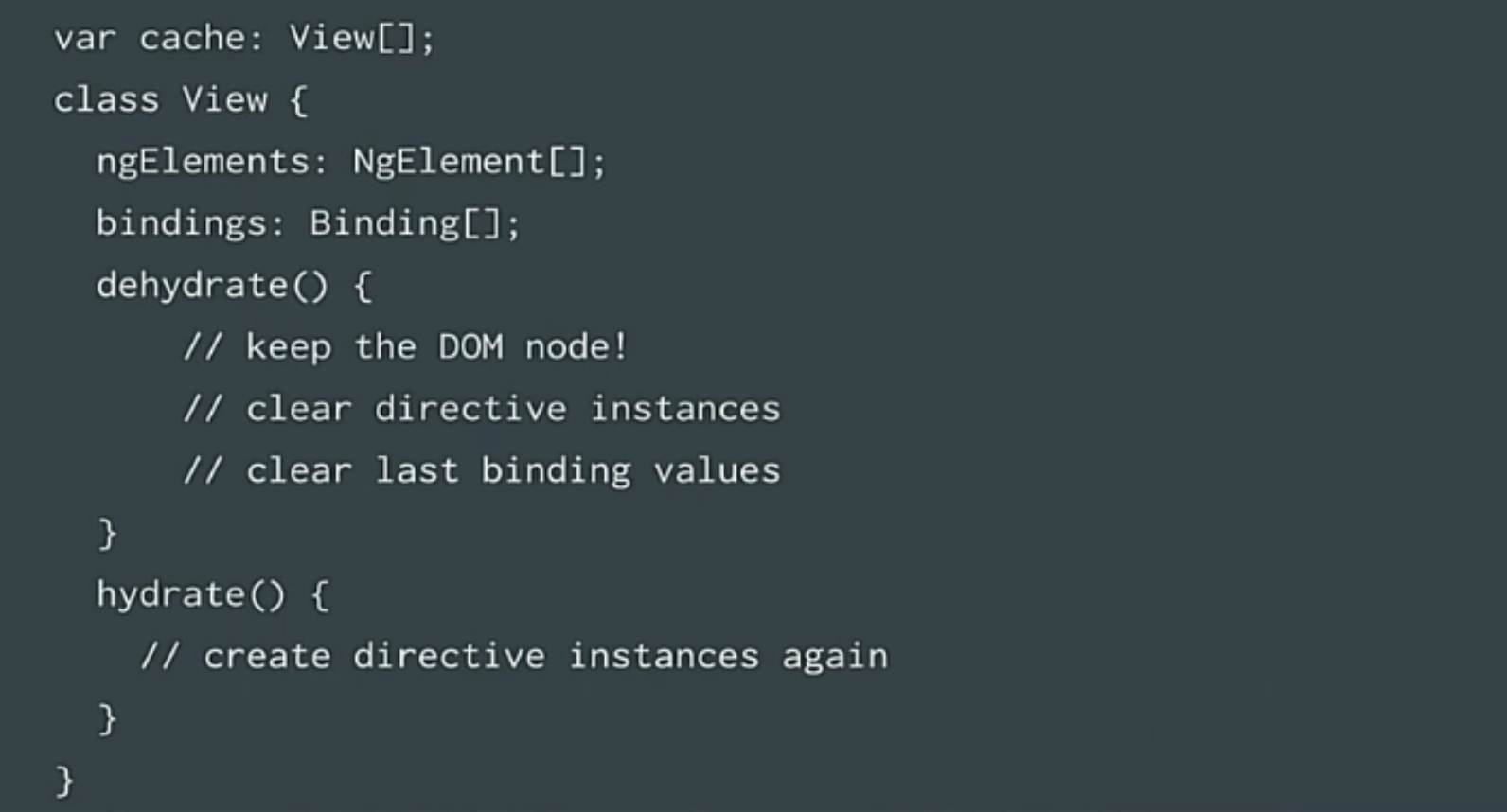
Before you go to the new pool, you need to destroy the state. The state is contained in the directive. So we kill all directives. Further, when there is an exit from a pool, it is necessary to create these directives anew. This is done by the methods of hydrate and dehydrate. We retained the DOM nodes, since everything comes from the model, the entire status is in the model. Therefore, we kept it. And again we conducted a performance test.
Testing environment
So that you understand the results of these tests, it is worth noting that Baseline is a program with manual JavaScript code and hard coding. In such a program, no frameworks were used; the program was written only for this deep-tree test. The program performs dirtyChecking. We took this program as a unit. Everything else is compared in the ratio. Angular 1 received a mark of 5.7.
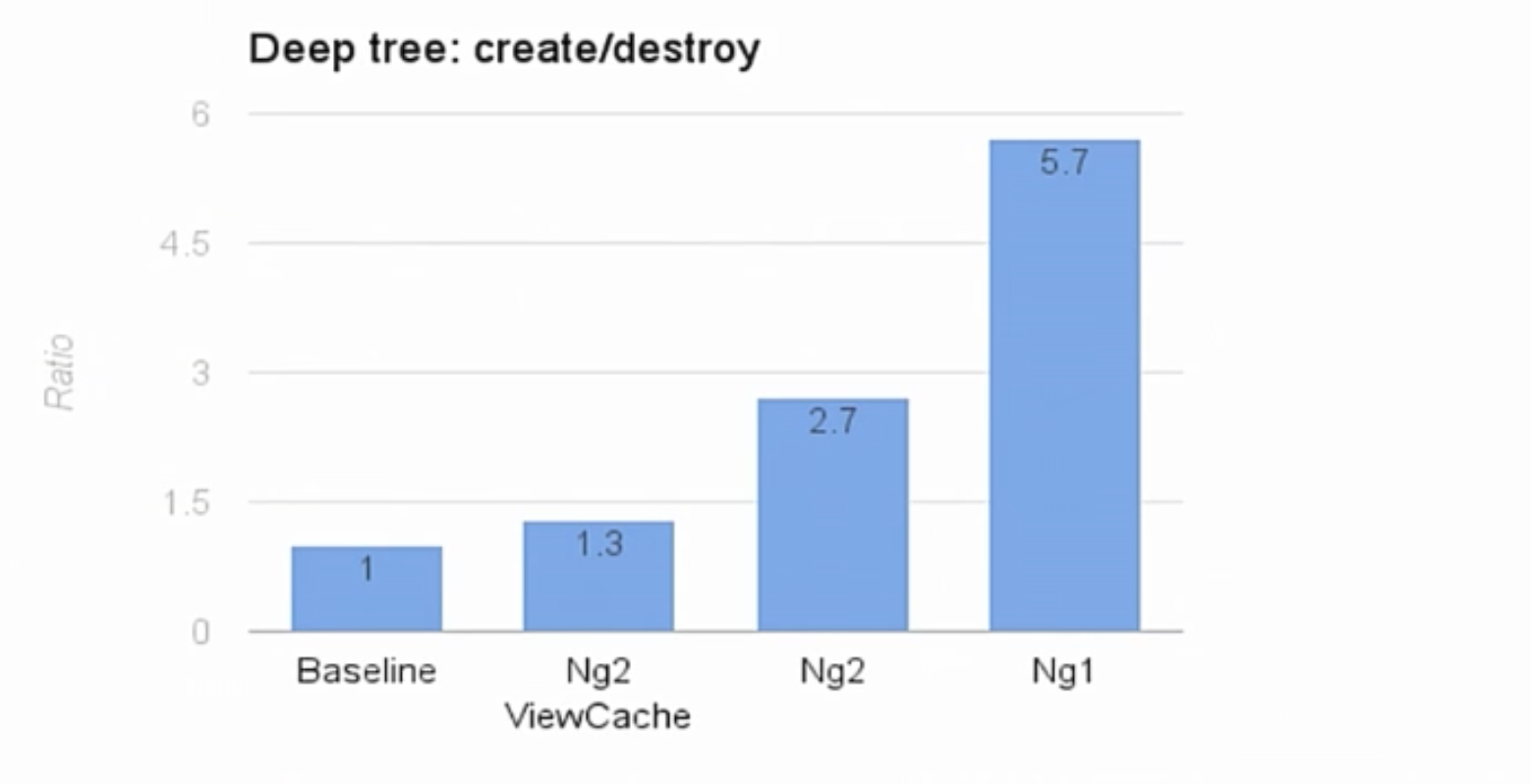
Previously, we showed the same speed with optimized data structures and without view cache. We were at the level of 2.7. So, this is a good indicator. We doubled the speed due to quick access to properties. At first we thought that our work ends there.
Disadvantages of the second stage
We have created applications on this base. But then we saw the flaws:
Class view
Then a thought came to us: let's take another look at our view class. What is there with us?
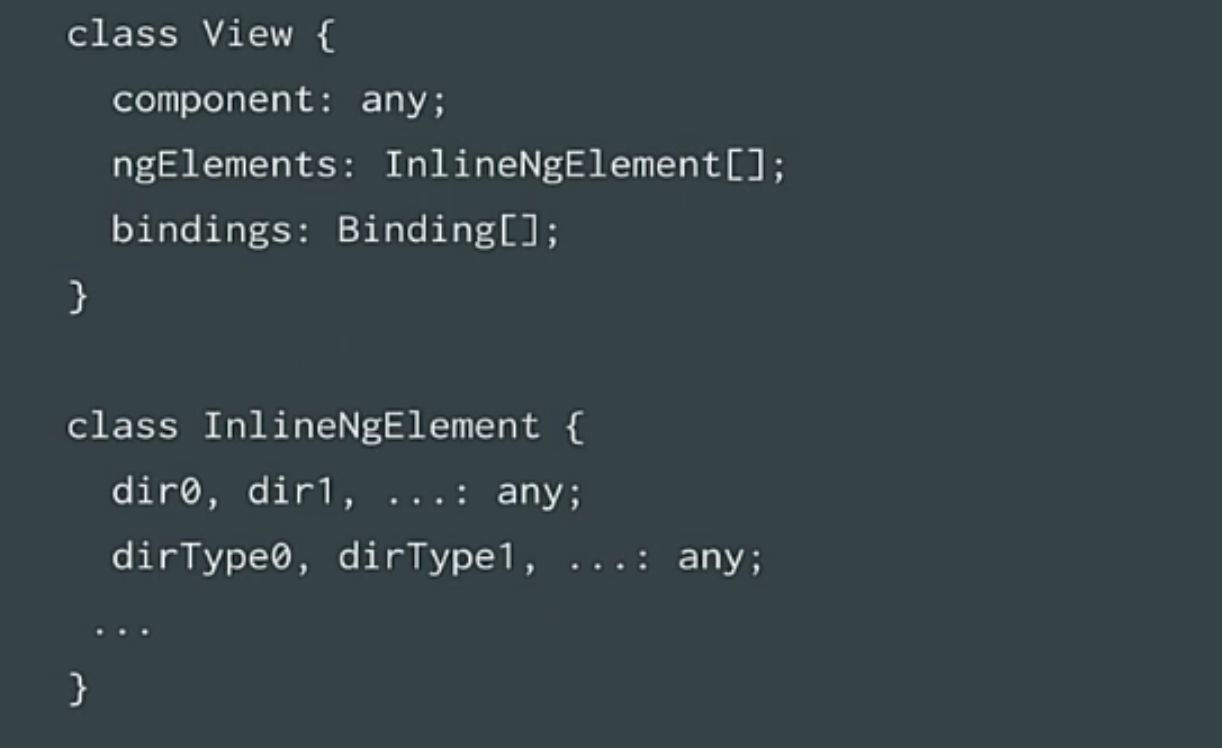
We have a component - these are already optimized ngelement, right? We have bindings. But the view class still contains these arrays. Can we create an InlineView that also uses properties only? No arrays. Is it possible It turned out, yes.
What does this look like? Like that.
Template
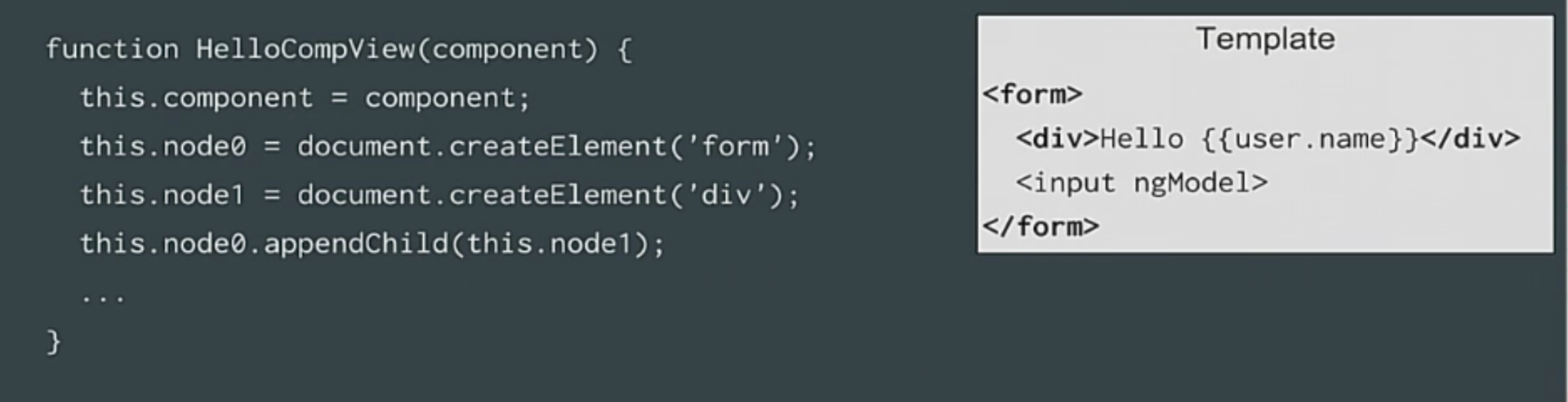
So, we, as before, will have a template, and for each element we will simply create code. For this template, we will create code that displays our view class.In the constructor for each element, we call document.createElement, which will be stored in the Node0 property - for the first element, for the second, we will call document.createElement, which will be stored in Node1. Next, when we need to attach an element to its parent, we have properties, right? We just need to do everything in the right order. We can use the property to refer to the previous state. This is what we do with the DOM.
Directives
We do the same with directives. We have properties for each instance. And again, we just need to make sure that the order of actions is correct: that the dependencies come first, and then those components that use these dependencies. That we first use ngForm, and then - ngModel.
Bindings
Next, bindings. We simply create code that performs dirty-check. We take our expressions, convert them back to JavaScript. In this case, it will be this.component user.name. This means that we pull user.name out of the component, compare it with the previous value, which is also a property. If the value has changed - we update the text node. In the end, we reduce everything to a view with a data structure. It has only properties. There are no arrays, Map, fast access through properties is used everywhere.
This greatly speeds up the process. Soon I will show you the numbers so you can see this.
The question is: how do we do it?
Let's say someone needs to create a string that evaluates this new class. How it's done?We simply apply what we did in implementation 101 in our current implementation.
The bottom line is this: If we previously created DOM nodes, we are now creating code to create DOM nodes. If earlier we compared elements, now we create code to compare elements. Finally, If we previously used directive instances or DOM nodes, we now store properties where directive instances and DOM nodes are stored. In this case, the code looks like this.
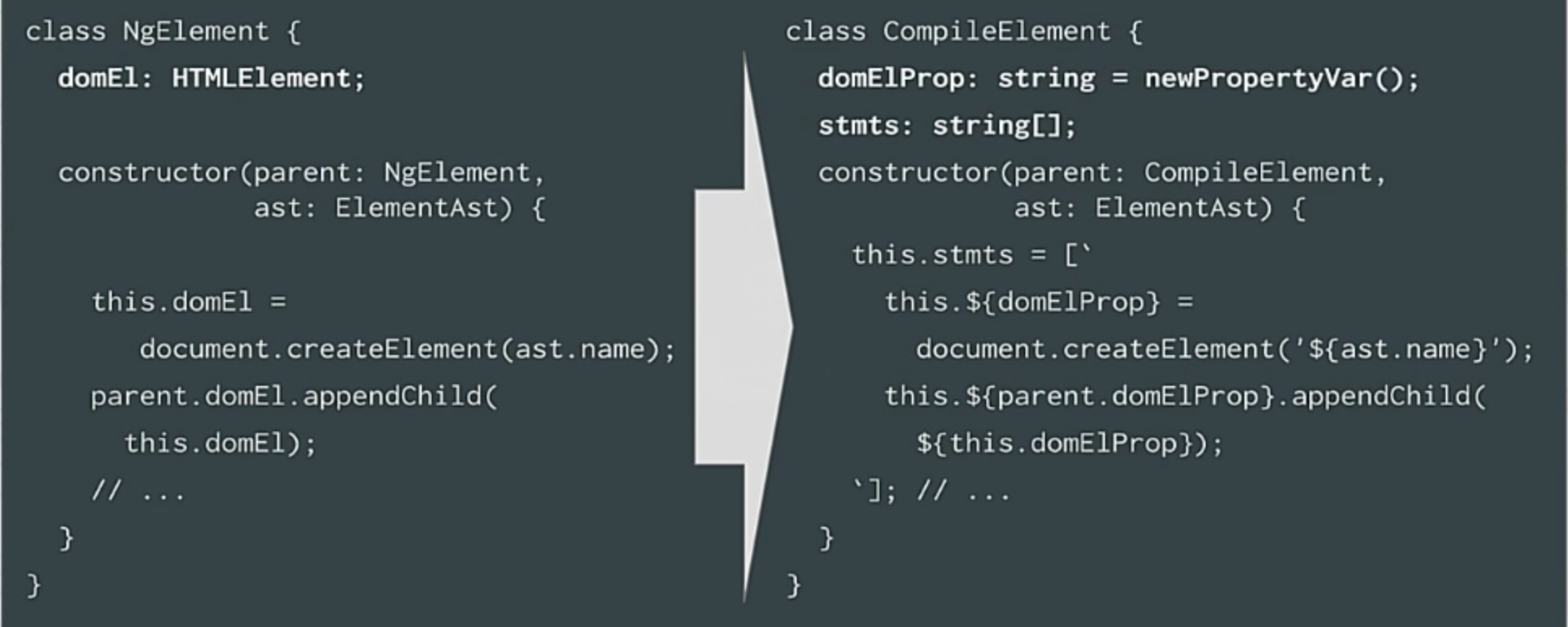
Previously, we had our ngelement, now we have a compileElement. In fact, these classes now exist in the compiler. There is a compileElement, compileView, and so on.
The mapping will be like this: we used to have a DOM element, but now we only have a property in which the DOM element is stored. Previously, we called document.createElement, but now we create a string with this new string interpolation, which is great for creating code in which we say that this.document + the name of its property is equivalent to document.createElement called ASD.
Finally, if earlier we called appendChild, now we are creating code to attach the child element to the parent element. The same thing happens with the search for directive dependencies. Everything happens according to the same algorithm, only now we are creating code for this purpose.
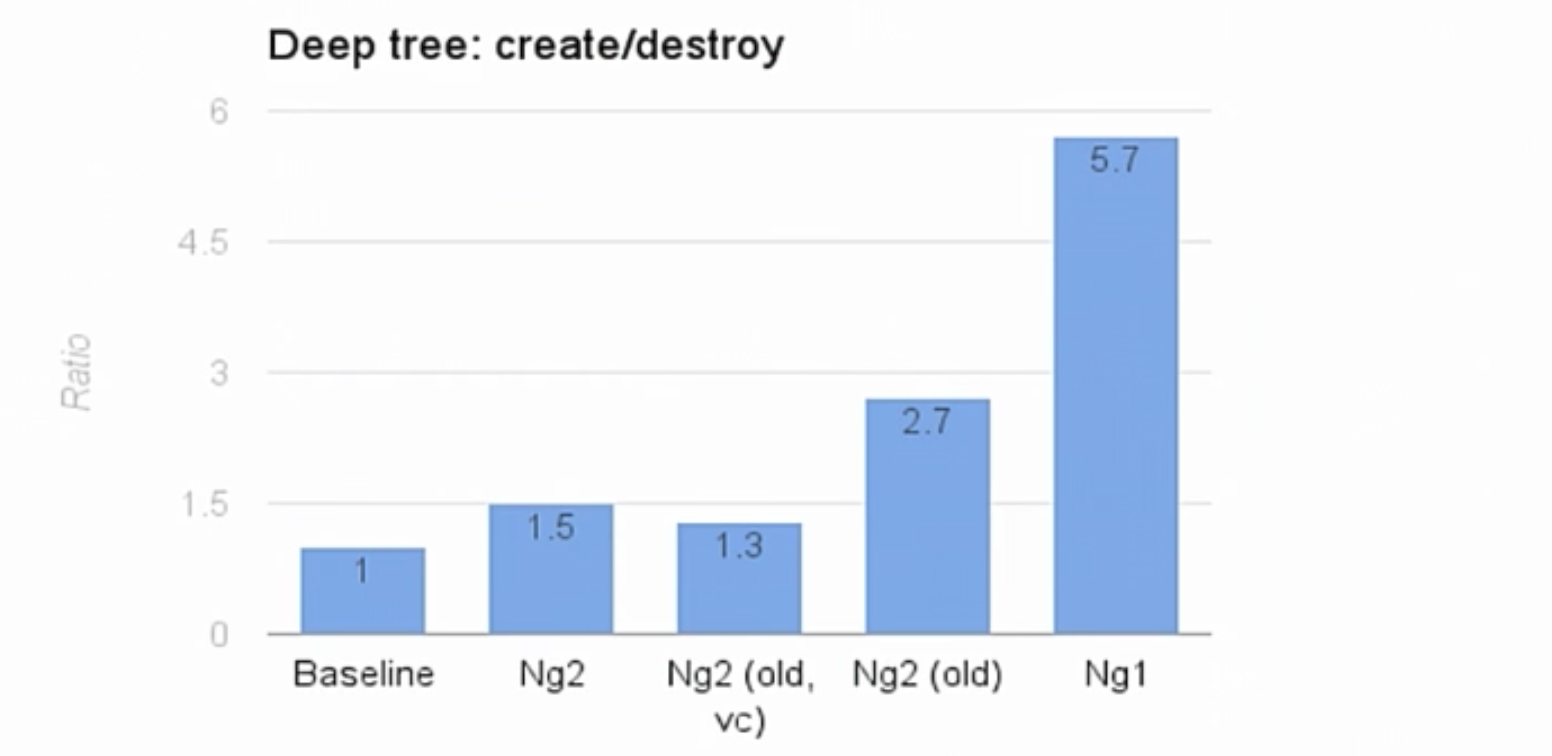
If we now look at the indicators, we will see that now we have greatly increased the speed. If earlier our indicator was 2.7, now it is 1.5. It is almost twice as fast. ViewCache, as before, remains slightly faster. But we have excluded the option of using it, and you already know the reasons for our decision. We did a great job and could have finished. But no.
Dynamic (Just in Time) compilation
So, at first we talked about dynamic (Just in Time) compilation. Dynamic means that we compile in the browser.
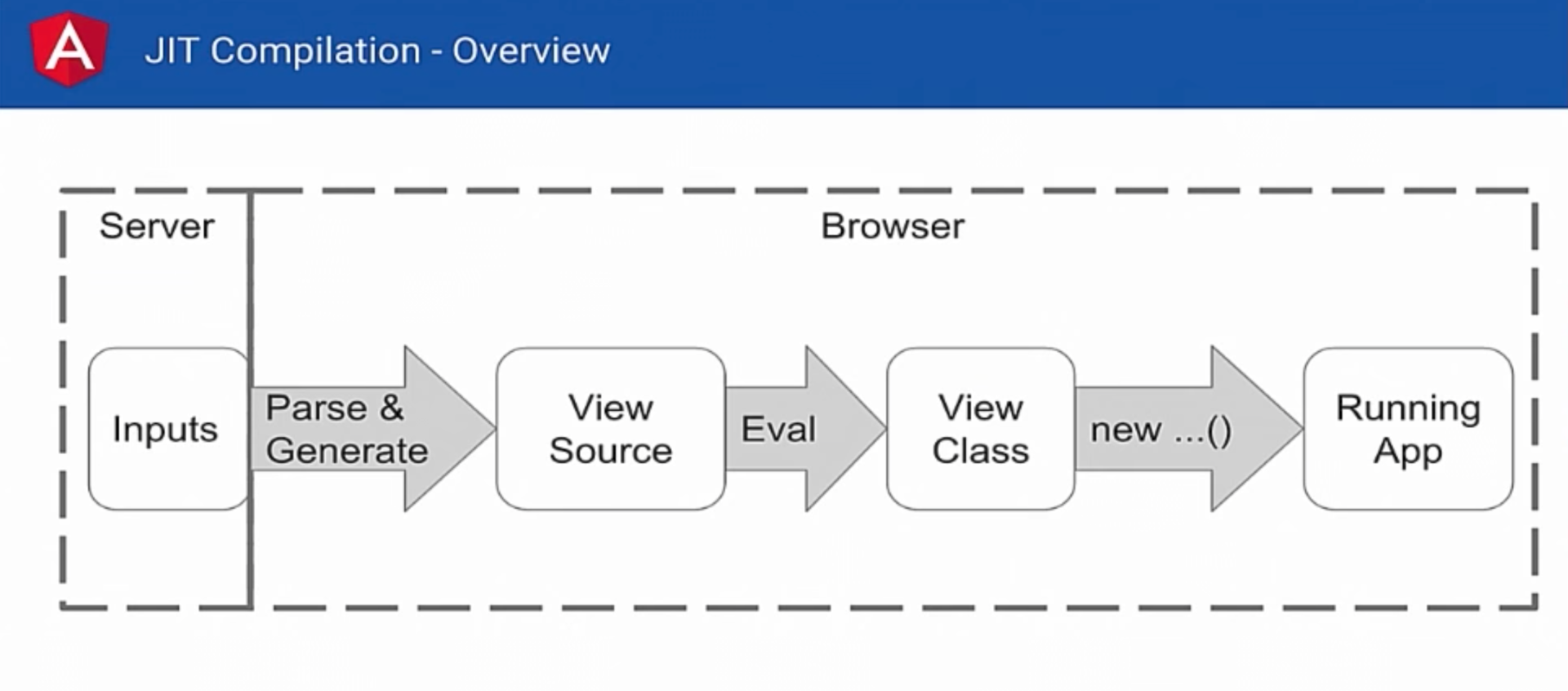
Recall that it works like this: you have any input data that is on your server. The browser loads and takes them, analyzes everything, creates the original view class. Now we need to evaluate this source code in order to get another class. After that we can create this class, and then we get a working application. There are certain problems with this part:
So, if we use improved minification while the compiler is running, this is what happens.
There are our components, our markup, loaded into the browser, the browser analyzes the template and creates the view class. So far, everything is going fine. The browser uses user.name, the component also contains user.name, just this user.name is minified using advanced minification technology. Thus, the component is called, say, C1, and my user suddenly turns out to be just U, and the name is N. The problem is that the minifier does not know about my template. After all, the template is still user.name.
So, the template is executed, still creates user.name, which simply does not exist in the component. There are certain solutions to this problem. You can tell the component that it is not necessary to minimize this property. But this is not what we need. We need to enable us to minify this property, but this will not work with real-time compilation and evaluation.
Static (Ahead of Time) compilation
It is for this reason that our next step was the appearance of a static (Ahead of Time) compilation. It works as follows.

Again we have input data that is analyzed on the server, and the view class is also created on the server.
Then the browser simply picks them up, loads them as plain script (as you load your regular JavaScript code), and then simply creates the necessary elements.
This compilation method is great because: The analysis happens on the server (and therefore it is fast), the compiler does not need to be transferred to the browser (and this is also excellent). Also, we no longer use the assessment, because it is a script. Therefore, this compilation is suitable for any browser.
Also, static compilation is great for improved minification, because now we create the view class on the server, and if we run the minifier, we can also minify our view classes. Now, when the minifier performs its work, we get the renamed properties in the classes.
Great, now we can use improved minification. Therefore, our speed indicators have dropped even lower.
Disadvantages of static compilation
So now we have a static compilation. Now everything is fine, yes? But as always, there are drawbacks. The first problem is that with static compilation, we need to create different code.
For evaluation in the browser, you need to create code according to the standard ES5. You create code that uses local variables, or that takes arguments passed to a function. You do not use require.js or anything like that.
Since the code is generated on the server, it was necessary to generate TypeScript code for two reasons:
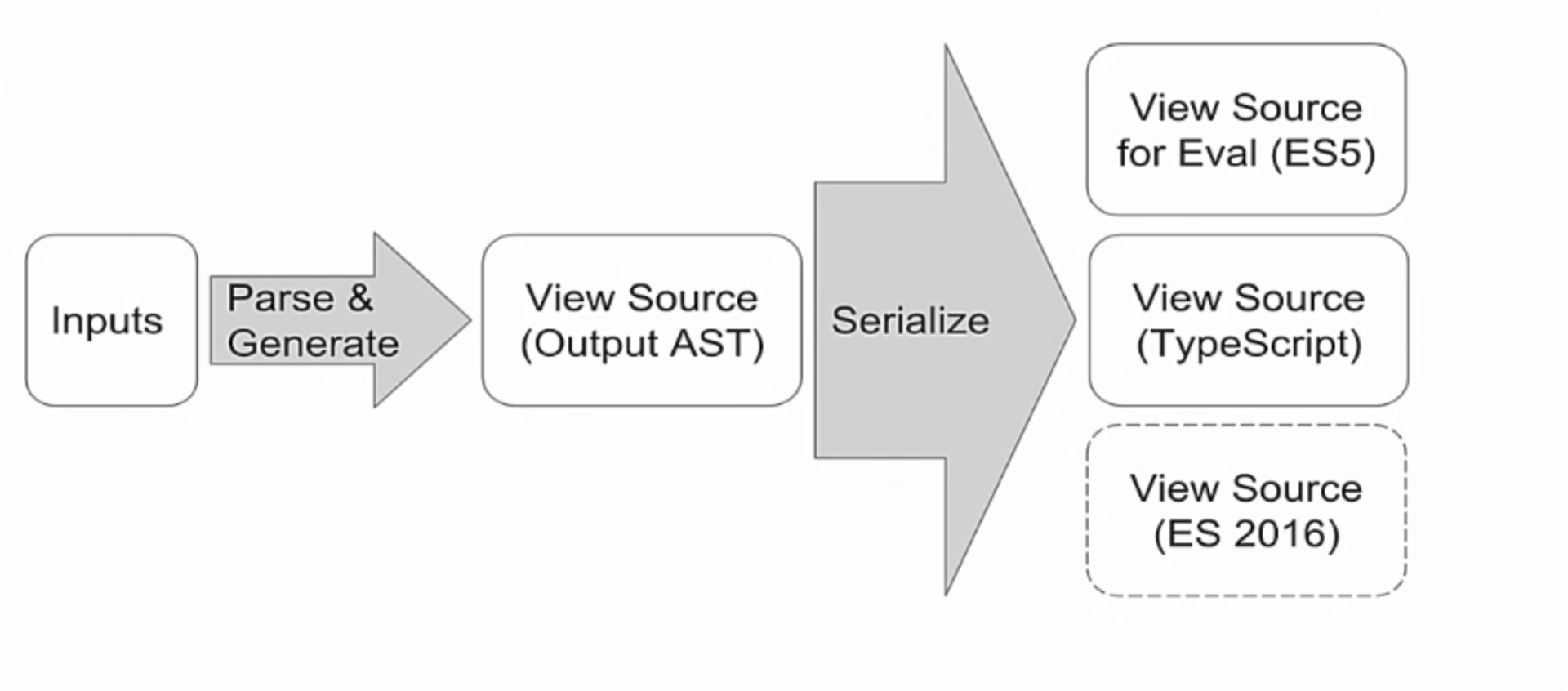
How did we manage to provide support for ES6 2016?
In fact, if you are familiar with compilers, then there is a common pattern. Instead of creating rows, a data structure is created that is similar to the output, but this data structure, this ASD, can be serialized into different output data.
ASD contains features such as declaring a variable, calling methods, and so on, plus types. Then for ES5 we just serialize it all without types, and for TypeScript we serialize it with types.
It looks like this: our generated ASD output, inside the declared variables (we specify declare var name EL). This will create a var el code in TypeScript and create a type. In ES5, the type will be omitted.
Next we can call the method. First we read the document variable (since this is a global variable). And then for it we can call the createElement method with these arguments.
We placed literal with a value of “div”, because if you analyze strings, you must escape them correctly. The value may contain quotes, so when reading the code you need to screen them, skip. Therefore, this is the way we can do it. The good news is that now our generated code looks the same on both the server and the browser. No different parts of the code.
The second problem we encountered when developing a static compiler is the selection of metadata. Take a look at this code.

What is the problem with this code? Let's say we have some kind of directive that has a dependency on cookies, and if you have cookies, the directive does something else. It works. You can compile. Super.
But this does not work with static compilation. If you think why? If this is all down to the level of ES5, you will receive just such a code.
What does the decorator ultimately do? It adds a property to your constructor for the metadata. At the end, he simply adds SomeDir with notes.
The problem is that if you run this on the server, it will not work. After all, there is no document on the server. What to do?
You can offer to build a browser environment on the server, declare a document variable, a window variable, and so on. In some cases it will work, but in most cases it will not. The second method (we are now well versed in the ASD, right?) Is to process the ASD and remove the metadata from it without evaluating the code. In the ASD this can be represented somehow.
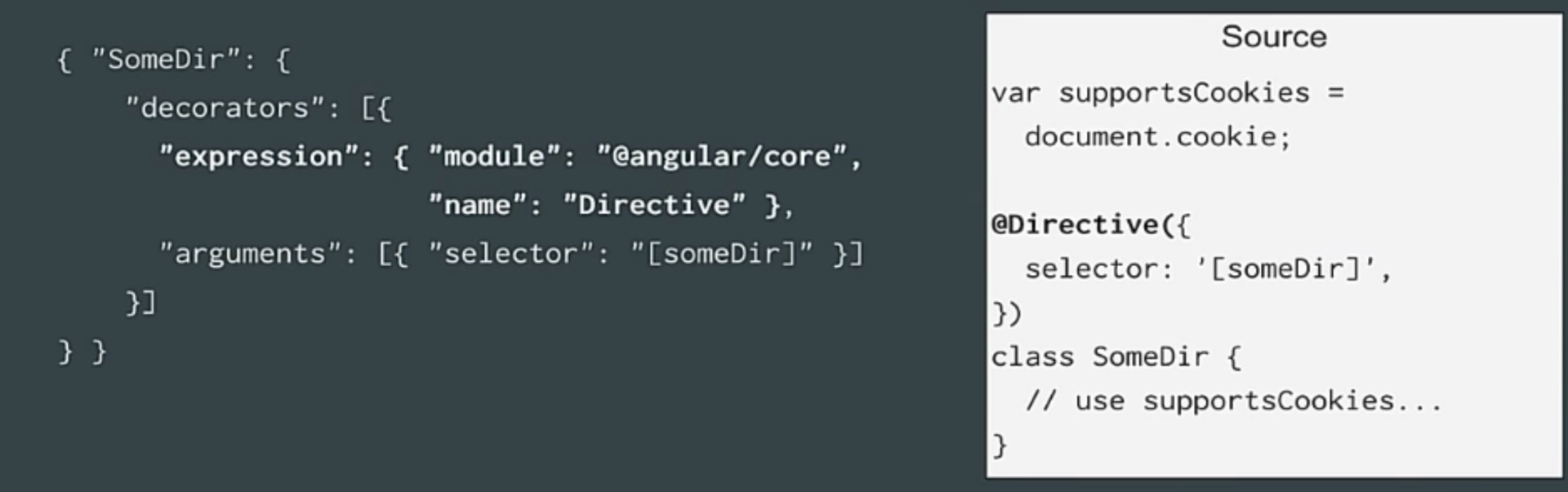
Thus, our class SomeDir in the ASD may have a property decorators, which refers to the element that you call (this expression, where the directive plus the arguments are defined). The following happens. We pull metadata into JSON files, then our static compiler takes these files and creates a template from them. Obviously, there are limitations. We do not evaluate JavaScript code directly, so you can not do everything that you used to do in the browser.
So, our static compiler limits us, but you can put a note. But if you use the above method, it will work in all cases.
Well, let's look at performance tests again.
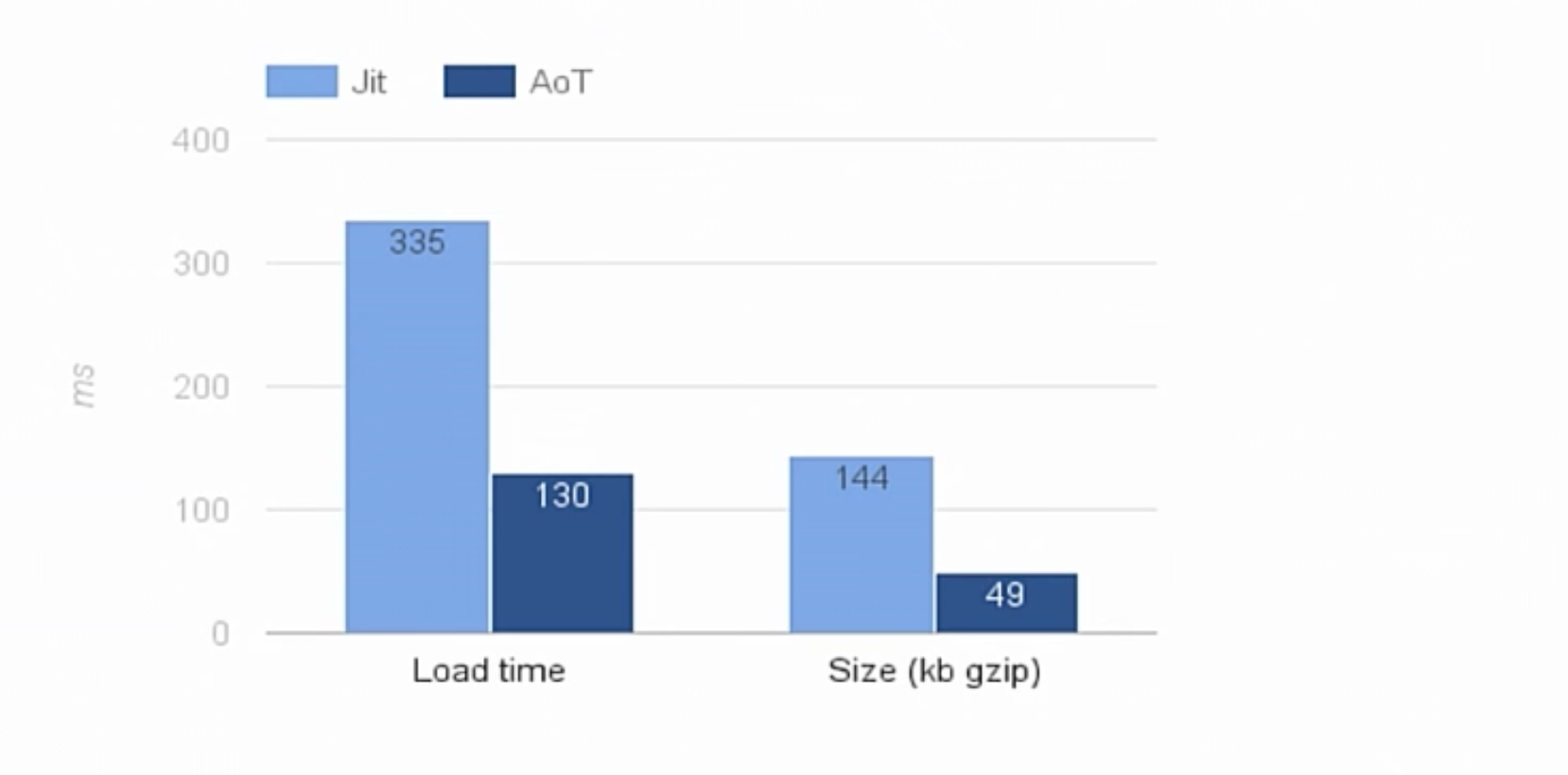
This is a simple program written by us. And the time of its loading has decreased very significantly. This is because we no longer perform the analysis, and also because the Angular 2 compiler no longer loads. It is almost three times faster. The size has also been reduced from the already mined ones in the gzip format, 144 kilobytes to 49. For comparison, the React library with improved minification weighs 46kb now.
And now some illustrative examples.
Suppose we have an Angular component, we have ngForm and ngModel. ngModel has a ngForm as a dependency.
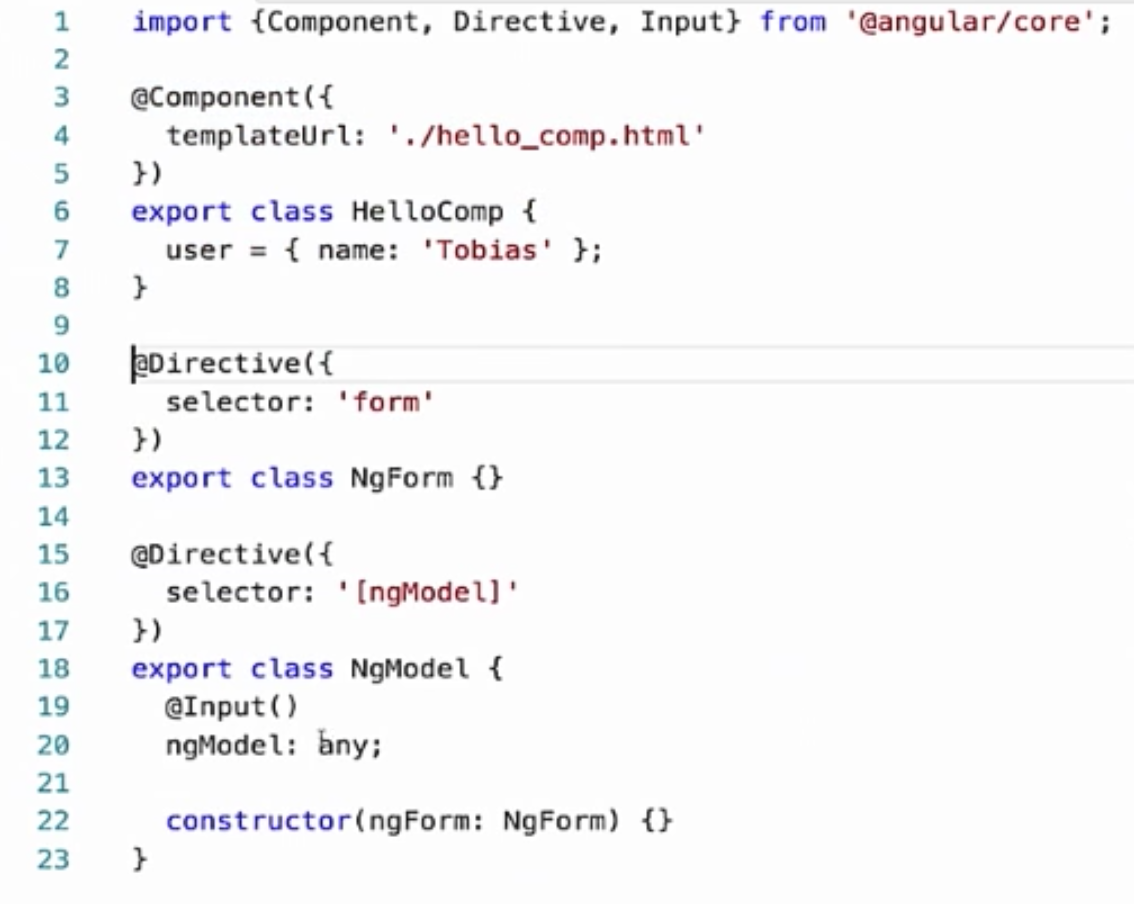
Add here NGC - these are _node modules that cover the TypeScript compiler, because when you pull out and support metadata, these modules depend on TypeScript. And if we look at the generated code, we will see that it looks very familiar. We have user.name. If its value changes, we update the input to the directive. We simply compare with the previous value and set it.
There is a good side to this. Suppose in my template I change user.name to wrongName. Our template refers to user.name, not user. wrongName. Now, when we look at the generated code, TypeScript will generate an error.

Because these views have types based on the type of the component. And now when you compile them, you will discover the errors of your code, simply because we used TypeScript. We needed nothing else.
We did well, but we strive to become even better.
Our goal is to reach a size of 10 kb gzip. The size of some of our prototypes is 25 kb and I have a few ideas on how to make the compiler even smaller. Next, we want to be even faster than our starting point Baseline. We realize that this is not the limit, and we can be even faster than Baseline.
You will not notice any changes. You will make changes, generate different code. The only thing - you will see the difference only in speed.
We talked about performance, about different aspects of performance.
We discussed input.
We learned what analysis is, ASD (AST). I talked about how we can present the template and how to implement it.
We learned that document.createElement is great for the Angular framework.
We learned that quick access by properties and hidden classes are great tools for optimizing your code.
We learned that code generation (if done correctly, that is, not only with the help of evaluation, but also with the support of offline, as well as output of the ASD) is an excellent and powerful thing. This will help you in generating hidden classes.
We talked about static (Ahead Of Time) and dynamic (Just In Time) compilations, as well as things that can be optimized.
Finally, we looked at a good example. On the slide there is a link to my presentation.
Thank you so much for your attention.
This article is a free translation of the Tobias Bosch report - The Angular 2 Compiler. You can find the link to the original report at the end of the article.
An overlook
Tobias Bosch is an employee of Google and a member of the Angular development team who created most of the components of the compiler. Today he talks about how Angular works from the inside. And this is not something extremely complex.
I hope that you use some of the knowledge gained in your applications. Perhaps you, like our team, will create your own compiler or a small framework. I will talk about how the compiler works and how we achieved our goal.
')
What is a compiler?
This is all that happens between the application's input data (it can be your commands, patterns, etc.) and your running application.
Everything that happens between them is the domain of the compiler. In appearance, it may seem like pure magic. But it is not.
What will we look at today?
First, we'll talk a little about performance: what is meant by fast work? We will talk about what kind of input data we have.
We will also talk about lexical analysis, what it is, and what the Angular 2 compiler does with analysis. We’ll talk about how Angular 2 takes the analyzed data and processes it. In general, the implementation of this process took place in three attempts; at first there was a simple implementation, then an improved one and an even more improved one. So did we. These are the stages by which we managed to achieve accelerated work of our compiler.
We will also discuss different environments, advantages and disadvantages of dynamic (Just In Time) and static (Ahead Of Time) compilations.
Performance: what does fast work mean?
Imagine a situation: I wrote an application and claimed that it works quickly. What I mean? The first thing you might think is that the application loads very quickly. Did you see google amp pages? They load unreal fast. This can be attributed to the concept of "fast."
Perhaps I use a great app. I switch from one heading to another. For example, from the overview to the expanded page, and such transition occurs very quickly. This can also characterize speed.
Or, say, I have a large table and now I just change all its values. I create new values without changing the structure. This is real fast. All these are different aspects of the same concept, different things that need to be addressed in the application.
Crossing the paths
I would like to stay more detailed at the stage of transition along the paths (switching a route).
The important point is that when moving along paths, the framework destroys and recreates everything anew. It does not adhere to the structure: everything collapses and everything is recreated anew.
How can this process be made quick?
To do something quickly, you need to measure this speed. For this you need a test. One of the performance tests we use is the deep-tree performance test. You may have heard of such. This is a component that is used twice. This is a recursion of a component until a certain depth is reached.
We have 512 components and buttons that can destroy or create these components. Next, we measure how much time it takes to destroy and create components. So there is a transition along the paths. Transition from one view to another. The destruction of everything is the creation of everything.
What input data do we have?
Components
We have components, and I think everyone knows them.
They have a template. You can make the templates inline or put them in a separate file, it is worth remembering that they have context.
Component instances are inherently the context, the data that is used to build a template. In our case, we have a user, the user has a name (in our case, this is my name).
Template
Next we have a template. This is simple HTML, here you can insert something like an input form, you can apply everything that HTML offers.
Here we have some new syntax: remember double curly brackets, square brackets and round brackets? This is the binding of Angular to properties or events. Today we will talk only about braces and what they mean. From the point of view of semantics, this means "to take data from a component and place it in a certain place." When data is changed, text should be updated.
Directives
Directives contain a selector - this is a CSS selector. The bottom line is that when Angular passes the markup, if it finds a directive that matches an element, it executes it.
Suppose we have a selector for forms, and with this we kind of say, every time we create a form element, please create this directive.
Similarly with ngModel. When you create the ngModel attribute, you must create a directive.
These directives may have dependencies. This is our expression of addiction.
The dependency has a hierarchical structure, so that ngModel requests ngForm.
And what does Angular do?
He scans the entire tree for the nearest ngForm, which is one level higher in the tree structure. It will not view single-level items, only parent elements.
There are other inputs, but we will not dwell on them in detail.
Everything that is done in Angular passes through the compiler.
Well, we have input. The next thing we need is to understand them.
Is it just a bunch of nonsense, or, after all, does it make any sense?
The process of lexical analysis
First stage
Suppose we have some kind of template, for example, HTML.
Template view
How can we present it in such a way that the compiler can understand it?
The analyzer is engaged in it. He reads each character and then analyzes the meaning. That is, he creates a tree. Each element has only one object. Suppose there is some name - the name of the element, there are child elements. Let's just say a text node is a JSON object with text properties. We also have item attributes. Let's just say we encode it all as nested lists. The first value is the key, the second is the value of the attribute. And so on, there is nothing complicated. Such a representation is called an abstract syntax tree (ASD, english - AST). You will often hear this concept. This is all HTML.
How can we portray the relationship of an element with data?
We can display this as follows. This is a text node, that is, we have a JSON object with text characteristics. The text is empty because initially there is no text to display. Text depends on incoming data. Incoming data is presented in this expression.
Any expressions are also analyzed for what they mean.
You cannot declare a function inside expressions or use a for loop, but we have such things as pipes with which you can work with expressions.
We can portray this expression, user.name, as a property path. And also we can catch where this expression came from from your template.
Determination of the place of expression
So why is this so important? Why is it important for us to know where exactly this expression came from?
This is because we want to show you error messages at runtime. Let's say that your user knows about these errors.
And then, are there exceptions? For example, it is impossible to read the name from undefined. If this happens, then you need to go to the error debugger and check, set a breakpoint on the first error. Then you must understand exactly where the error occurred.
Angular compiler gives you more information.
It shows exactly where in the “grow legs” pattern of this error. The goal is to show you that the error originates, for example, from this particular interpolation in the second row, column 14 of your pattern. To do this, we need the row and column numbers to be in the SDA.
Next, what analyzers do we need to build this ASD?
There are many possibilities here. For example, we can use a browser.
The browser is a great HTML parser, right? He does this every day. We had this approach when developing Angular 1, we started using the same approach when developing Angular 2.
Now we do not use the browser for such purposes for two reasons:
- From the browser can not get the numbers of rows and columns. When analyzing HTML, the browser simply does not use them.
- we want Angular to work on the server as well.
Obviously, there is no browser on the server. We could say: in the browser we use the browser, and on the server we use something else. So it was. But then we got into dead ends, for example, with SVG, or with commas, so we needed to have the same semantics everywhere. Therefore, it is easier to insert a fragment of JavaScript, and the analyzer. This is exactly what we do.
So we talked about HTML and expressions.
How do we present the directives we find?
We can display them through JSON objects that represent elements by simply adding another property: directives. And we refer to the constructor functions of these directives.
In our example with input data with ngModel, we can portray this element as a JSON object. It has input name, attributes, ngModel and directives. We have a pointer to constructors, and we also catch dependencies, because we need to specify that if we create ngModel, we need ngForm, and we need to pick up this information.
Given the SDA with HTML information, links and guidelines, how do we bring this all to life? How can this be done the easiest?
First, let's deal with HTML. What is the easiest way to create a DOM element? First, you can use innerHTML. Secondly, you can take an already existing item and clone it. And third, you can call document.createElement.
Let's vote. Who thinks innerHTML is the fastest? And who thinks element.cloneNode will create an element the fastest? Or maybe the fastest way is element.createElement?
Obviously, everything changes over time. But for now:
- innerHTML is the slowest option. This is obvious, because the browser must call up its analyzer, take your string, go through each character and build the DOM element. Obviously, this is very slow.

- element.cloneNode is the fastest way, because the browser already has a built projection, and it simply clones this projection. It’s just adding another item to memory. This is all you need to do.
- document.createElement is something between the two previous methods. This method is very close to element.cloneNode. Slightly slower, but very close.

You say, "OK, let's use element.createElement to create a new DOM element."
This is how Angular 1 worked, and we also started the development of Angular 2. And by tradition, it turns out that this is not a fair comparison, at least not in the case of Angular. In the case of using Angular, we need to create some elements, but, in addition to this, we need to place these elements. In our case, we want to create new text nodes, but we also need to find the one that is responsible for user.name, because later we want to update it.
Therefore, if we compare, then we must compare both the creation and placement. If you use innerHTML or cloneNode, then you have to re-traverse the entire path of the DOM. When using createElement or createTextNode, you bypass these actions. You simply call the method and immediately get its execution. No new constructions and other things.
In this regard, if we compare createElement and createTextNode, they are both about the same in speed (depending on the number of bindings).
Secondly, much less data structures are required. You do not need to keep track of all these indices and stuff, so these methods are simpler and almost equal in speed. Therefore, we use these methods, and other frameworks also switch to this approach.
So we can already create DOM elements.
Now we need to create directives
We need to inject dependencies from the child to the parent. Suppose we have a data structure called ngElement, which includes a DOM element and directives for this element. There is also a parent element. This is a simple tree inside a DOM tree.
And how can we create DOM elements from ASD?
We have a template, we have an element from which we built an SDA. What can we do with all this?
In our ngElement and constructor, we call document.createElement, we look at the attributes and assign them to the elements, and then we add the element to our parent element. As you can see, no magic.
Then go to the directives. How it works?
We look at the bindings, somehow get them (talk about this a bit later) and simply re-call new for the constructor, give it bindings and save the Map. Map will go from directive type (ngModel) to directive instances.
And all this search for directives will work this way: we will have a method that receives a directive that first checks the element itself (if it has a directive). If not, then go back to the parent and check there.
This is the easiest thing to do. We ourselves began in this direction. And it works.
Important detail: bindings. How to display bindings?
You simply create a binding class that has a target - Node. It will be a text node.
The target has a property, in our case it will be the value of the node, this is the place where the value fits. And an expression.
The binding works this way: every time you evaluate an expression or when it simply changes, you save it to the target.
That is, you may have the following method: first, you evaluate the expression, if it has changed - then update the target and other previously saved values.
As for the exceptions mentioned earlier, we call try catch methods to track the estimation path. When an exception is thrown, we re-generate it and create a model for it from row and column numbers.
So we get the row numbers and columns in which there are errors. This is all we associate into a presentation. This is the last data structure.
A view is an element of a template. That is, when we look at the error code - we will see a lot of views. These are just template elements. And we combine them into a presentation. A view references a component, ng-elements and bindings, as well as a dirty-check method that scans bindings and checks them.
So we finished the first stage. We have a new compiler. How fast are we? Almost at the same level as Angular 1. Not bad at all. Using the simpler approach, we achieved the same speed. But Angular 1 is not slow.
Second stage
How do we speed up the process? What is the next step? What have we missed? Let's figure it out.
We need something that is related to our data structures. When it comes to data structures, in fact, this is a very difficult question. If we compare with the last program we wrote, where try-catch appears, but if we discard it, we will see that many functions slow down the process and that many points need to be optimized. If you consider the reason for the slow work of your data structure program, then this is a very difficult question, because they are scattered throughout your program. This is just an assumption that the matter is in data structures.
We conducted experiments and tried to figure it out. We watched these directives: Map inside ngElements.
It turns out that for each element in the DOM tree we create a new map? One could say that there are no directives there, we did not create them. But still, we always create a map, fill it with directives and read information from it. It may be uneconomical, it may overload the memory, the reading still takes some time too.
Alternative approach: you can say: “Okay, we only allow 10 directives for one item. Next, we create an inlinengElement class, 10 properties for directive elements and directive types, and in order to find a directive, we create 10 conditional IF statements. ” It's faster? Maybe.
It does not consume a lot of memory resources, right?
For example, setting: you set the property, not the map. Reading can be a bit slow due to 10 conditions. This is exactly the case for which the JavaScript VM has been optimized. JavaScript VM can create hidden classes (you can google them at your leisure). This makes javascript js faster. Switching to this data structure is what speeds up the processes. Later we look at the results of performance tests. Another thing that needs to be optimized for data structures is the reuse of existing instances.
You can ask a logical question - If some lines are destroyed and others are restored, then why not cache these lines in the cache and change the data as soon as the lines appear? So we did. We created the so-called view cache, which restores old instances of views.
Before you go to the new pool, you need to destroy the state. The state is contained in the directive. So we kill all directives. Further, when there is an exit from a pool, it is necessary to create these directives anew. This is done by the methods of hydrate and dehydrate. We retained the DOM nodes, since everything comes from the model, the entire status is in the model. Therefore, we kept it. And again we conducted a performance test.
Testing environment
So that you understand the results of these tests, it is worth noting that Baseline is a program with manual JavaScript code and hard coding. In such a program, no frameworks were used; the program was written only for this deep-tree test. The program performs dirtyChecking. We took this program as a unit. Everything else is compared in the ratio. Angular 1 received a mark of 5.7.
Previously, we showed the same speed with optimized data structures and without view cache. We were at the level of 2.7. So, this is a good indicator. We doubled the speed due to quick access to properties. At first we thought that our work ends there.
Disadvantages of the second stage
We have created applications on this base. But then we saw the flaws:
- ViewCache is not good with memory. Imagine you are switching query processing routes. Your old requests remain in memory, because they are cached, aren't they? The question is when to delete requests from the cache? In fact, this is a very difficult question. It would be possible to create several simple elements that would allow the user to choose whether to cache something or not. But it would be, at least, strange.
- Another problem: DOM elements are hidden. For example, the element is in focus. Even if you do not have a focus binding, and the element can be both in focus and outside of it, its removal or return can change the focus of this or other elements. We did not think about it. There are related bugs. It was possible to go this way: we could completely remove the elements, to remove their condition, and even restore them. But that would nullify ViewCache if we had to recreate the DOM. After all, we had a rate of 2.7. How could we have reached speed in such a situation?
Third stage
Class view
Then a thought came to us: let's take another look at our view class. What is there with us?
We have a component - these are already optimized ngelement, right? We have bindings. But the view class still contains these arrays. Can we create an InlineView that also uses properties only? No arrays. Is it possible It turned out, yes.
What does this look like? Like that.
Template
So, we, as before, will have a template, and for each element we will simply create code. For this template, we will create code that displays our view class.In the constructor for each element, we call document.createElement, which will be stored in the Node0 property - for the first element, for the second, we will call document.createElement, which will be stored in Node1. Next, when we need to attach an element to its parent, we have properties, right? We just need to do everything in the right order. We can use the property to refer to the previous state. This is what we do with the DOM.
Directives
We do the same with directives. We have properties for each instance. And again, we just need to make sure that the order of actions is correct: that the dependencies come first, and then those components that use these dependencies. That we first use ngForm, and then - ngModel.
Bindings
Next, bindings. We simply create code that performs dirty-check. We take our expressions, convert them back to JavaScript. In this case, it will be this.component user.name. This means that we pull user.name out of the component, compare it with the previous value, which is also a property. If the value has changed - we update the text node. In the end, we reduce everything to a view with a data structure. It has only properties. There are no arrays, Map, fast access through properties is used everywhere.
This greatly speeds up the process. Soon I will show you the numbers so you can see this.
The question is: how do we do it?
Let's say someone needs to create a string that evaluates this new class. How it's done?We simply apply what we did in implementation 101 in our current implementation.
The bottom line is this: If we previously created DOM nodes, we are now creating code to create DOM nodes. If earlier we compared elements, now we create code to compare elements. Finally, If we previously used directive instances or DOM nodes, we now store properties where directive instances and DOM nodes are stored. In this case, the code looks like this.
Previously, we had our ngelement, now we have a compileElement. In fact, these classes now exist in the compiler. There is a compileElement, compileView, and so on.
The mapping will be like this: we used to have a DOM element, but now we only have a property in which the DOM element is stored. Previously, we called document.createElement, but now we create a string with this new string interpolation, which is great for creating code in which we say that this.document + the name of its property is equivalent to document.createElement called ASD.
Finally, if earlier we called appendChild, now we are creating code to attach the child element to the parent element. The same thing happens with the search for directive dependencies. Everything happens according to the same algorithm, only now we are creating code for this purpose.
If we now look at the indicators, we will see that now we have greatly increased the speed. If earlier our indicator was 2.7, now it is 1.5. It is almost twice as fast. ViewCache, as before, remains slightly faster. But we have excluded the option of using it, and you already know the reasons for our decision. We did a great job and could have finished. But no.
Dynamic (Just in Time) compilation
So, at first we talked about dynamic (Just in Time) compilation. Dynamic means that we compile in the browser.
Recall that it works like this: you have any input data that is on your server. The browser loads and takes them, analyzes everything, creates the original view class. Now we need to evaluate this source code in order to get another class. After that we can create this class, and then we get a working application. There are certain problems with this part:
- , . - , , . . , . , . .
- – , , Angular . , , .
- – eval. eval , - - . eval, , .
(, — eval ) - , (, ). , , . , Angular . .
- , , . ( , , ), - , :
- -, , , , .
- -, . , , . Closure ( « »), Google .
So, if we use improved minification while the compiler is running, this is what happens.
There are our components, our markup, loaded into the browser, the browser analyzes the template and creates the view class. So far, everything is going fine. The browser uses user.name, the component also contains user.name, just this user.name is minified using advanced minification technology. Thus, the component is called, say, C1, and my user suddenly turns out to be just U, and the name is N. The problem is that the minifier does not know about my template. After all, the template is still user.name.
So, the template is executed, still creates user.name, which simply does not exist in the component. There are certain solutions to this problem. You can tell the component that it is not necessary to minimize this property. But this is not what we need. We need to enable us to minify this property, but this will not work with real-time compilation and evaluation.
Static (Ahead of Time) compilation
It is for this reason that our next step was the appearance of a static (Ahead of Time) compilation. It works as follows.
Again we have input data that is analyzed on the server, and the view class is also created on the server.
Then the browser simply picks them up, loads them as plain script (as you load your regular JavaScript code), and then simply creates the necessary elements.
This compilation method is great because: The analysis happens on the server (and therefore it is fast), the compiler does not need to be transferred to the browser (and this is also excellent). Also, we no longer use the assessment, because it is a script. Therefore, this compilation is suitable for any browser.
Also, static compilation is great for improved minification, because now we create the view class on the server, and if we run the minifier, we can also minify our view classes. Now, when the minifier performs its work, we get the renamed properties in the classes.
Great, now we can use improved minification. Therefore, our speed indicators have dropped even lower.
Disadvantages of static compilation
So now we have a static compilation. Now everything is fine, yes? But as always, there are drawbacks. The first problem is that with static compilation, we need to create different code.
For evaluation in the browser, you need to create code according to the standard ES5. You create code that uses local variables, or that takes arguments passed to a function. You do not use require.js or anything like that.
Since the code is generated on the server, it was necessary to generate TypeScript code for two reasons:
- First, we wanted to check the types of your expressions (whether they exist in the components).
- -, TypeScript. , , . — , require.js, system.js, Google Closure, .
- , ES6 2016.
How did we manage to provide support for ES6 2016?
In fact, if you are familiar with compilers, then there is a common pattern. Instead of creating rows, a data structure is created that is similar to the output, but this data structure, this ASD, can be serialized into different output data.
ASD contains features such as declaring a variable, calling methods, and so on, plus types. Then for ES5 we just serialize it all without types, and for TypeScript we serialize it with types.
It looks like this: our generated ASD output, inside the declared variables (we specify declare var name EL). This will create a var el code in TypeScript and create a type. In ES5, the type will be omitted.
Next we can call the method. First we read the document variable (since this is a global variable). And then for it we can call the createElement method with these arguments.
We placed literal with a value of “div”, because if you analyze strings, you must escape them correctly. The value may contain quotes, so when reading the code you need to screen them, skip. Therefore, this is the way we can do it. The good news is that now our generated code looks the same on both the server and the browser. No different parts of the code.
The second problem we encountered when developing a static compiler is the selection of metadata. Take a look at this code.
What is the problem with this code? Let's say we have some kind of directive that has a dependency on cookies, and if you have cookies, the directive does something else. It works. You can compile. Super.
But this does not work with static compilation. If you think why? If this is all down to the level of ES5, you will receive just such a code.
What does the decorator ultimately do? It adds a property to your constructor for the metadata. At the end, he simply adds SomeDir with notes.
The problem is that if you run this on the server, it will not work. After all, there is no document on the server. What to do?
You can offer to build a browser environment on the server, declare a document variable, a window variable, and so on. In some cases it will work, but in most cases it will not. The second method (we are now well versed in the ASD, right?) Is to process the ASD and remove the metadata from it without evaluating the code. In the ASD this can be represented somehow.
Thus, our class SomeDir in the ASD may have a property decorators, which refers to the element that you call (this expression, where the directive plus the arguments are defined). The following happens. We pull metadata into JSON files, then our static compiler takes these files and creates a template from them. Obviously, there are limitations. We do not evaluate JavaScript code directly, so you can not do everything that you used to do in the browser.
So, our static compiler limits us, but you can put a note. But if you use the above method, it will work in all cases.
Well, let's look at performance tests again.
This is a simple program written by us. And the time of its loading has decreased very significantly. This is because we no longer perform the analysis, and also because the Angular 2 compiler no longer loads. It is almost three times faster. The size has also been reduced from the already mined ones in the gzip format, 144 kilobytes to 49. For comparison, the React library with improved minification weighs 46kb now.
And now some illustrative examples.
Suppose we have an Angular component, we have ngForm and ngModel. ngModel has a ngForm as a dependency.
Add here NGC - these are _node modules that cover the TypeScript compiler, because when you pull out and support metadata, these modules depend on TypeScript. And if we look at the generated code, we will see that it looks very familiar. We have user.name. If its value changes, we update the input to the directive. We simply compare with the previous value and set it.
There is a good side to this. Suppose in my template I change user.name to wrongName. Our template refers to user.name, not user. wrongName. Now, when we look at the generated code, TypeScript will generate an error.
Because these views have types based on the type of the component. And now when you compile them, you will discover the errors of your code, simply because we used TypeScript. We needed nothing else.
We did well, but we strive to become even better.
Our goal is to reach a size of 10 kb gzip. The size of some of our prototypes is 25 kb and I have a few ideas on how to make the compiler even smaller. Next, we want to be even faster than our starting point Baseline. We realize that this is not the limit, and we can be even faster than Baseline.
You will not notice any changes. You will make changes, generate different code. The only thing - you will see the difference only in speed.
As a conclusion
We talked about performance, about different aspects of performance.
We discussed input.
We learned what analysis is, ASD (AST). I talked about how we can present the template and how to implement it.
We learned that document.createElement is great for the Angular framework.
We learned that quick access by properties and hidden classes are great tools for optimizing your code.
We learned that code generation (if done correctly, that is, not only with the help of evaluation, but also with the support of offline, as well as output of the ASD) is an excellent and powerful thing. This will help you in generating hidden classes.
We talked about static (Ahead Of Time) and dynamic (Just In Time) compilations, as well as things that can be optimized.
Finally, we looked at a good example. On the slide there is a link to my presentation.
Thank you so much for your attention.
Links to materials
Source: https://habr.com/ru/post/329782/
All Articles