A bit of reverse-engineering USB flash on the SK6211 controller
Recently, discussing the nuances of USB flash operation on this resource, I faced the fact that the majority of technically literate people, due to the lack of literature, have no idea about the basic principles of operation of NAND controllers, and therefore there are a lot of far from reality statements about the features of device firmware optimization , or wrong conclusions are drawn about the reasons for the failure of the devices themselves.
In order to dispel a bit of illusion, we will use reverse engineering methods to analyze the operation of the SKYMEDI SK6211 NAND controller using the example of a finished product in the form of USB flash 8Gb, released by Kingston.

rice one
For a complete analysis, we first create an imitation of the use of the drive by recording a large number of files, followed by partial accidental deletion and repeated recordings. Next we write the half of the LBA range with zeros, but in addition to the zeros in each “sector” we place at offset 0x0 DWORD with its number. We write the second half of the logical range using the 0x77 pattern (this pattern is relatively convenient for analyzing data noise reduction algorithms).
')
We solder both NAND flash memory chips. In this instance, they are manufactured by Samsung, labeled K9HBG08U1M in the performance of TSOP- 48. Operational characteristics: page size - 2112 bytes, block size - 128 pages, the number of blocks in the plane - 2048, the number of planes in the bank - 4, the number of physical banks - 2. The total capacity of two chips 2112 * 128 * 2048 * 4 * 2 * 2 = 8,858,370,048 bytes.

rice 2
In fig. 2 shows the principle of block numbering (the block consists of 128 pages). It should be noted that this microcircuit can simultaneously perform programming / erasing operations in two planes at once (variations 0.1 and 2.3). Those who wish to study in more detail the features of microcircuits and the nuances of working with them can look for technical documentation (datasheet), which is currently available to the general public K9HBG08U1M.pdf.
To read the chips use the NAND reader included in the complex Flash Extractor. At the time when the SK6211 controller was popular, this data recovery system was almost the only analytical tool that was commercially available.

rice 3
Starting the analysis of the data distribution algorithms by the SK6211 controller, we will learn about its possibilities of parallel operation with microchips from advertising sources, as well as about slightly different two types of error correction codes (ECC). In this publication, due to the vastness of the topic, we omit the description of the features of the operation of error correction codes, and the entire mathematical component associated with them.
The first task in the data analysis is to establish the signs of the noise in the data being written to the memory. To do this, we will search for the 0x77 pattern we have recorded and try to find a lot of pages completely filled with it. But the search results do not lead to success, which allows us to conclude that the data was recorded in a modified form. When scrolling through the dumps, we find a large number of pages filled with a value of 0x88 except the last 64 bytes, as well as a large number of pages filled entirely with 0xFF except 4 bytes at the beginning of each 512 byte block and the last 64 bytes (2112 bytes in page borders). Based on the patterns we recorded on the USB flash, we assume that data is inverted. Before inverting the data, we analyze the contents of the NAND pages to determine the location of the service data. In the places where the pattern is filled, it is very easy to distinguish our inverted uniform value from the service data, which are not composed entirely of identical sequences of bytes.

Figure 4.
The SK6211 in the pages used places 2048 bytes of data ( DA ) and 64 bytes allocates for the storage of service data ( SA ). 4 groups of data of 16 bytes are well traced, which hints at their applicability to the four blocks of 512 contained in the page.
Print the contents of the first 16-byte group of several thousand pages.

rice five
In fig. 5 it is clear that the first 4 bytes remain ordered, and the chaotic content is located in the remaining 12. Therefore, we can assume that the last 12 bytes in each line contain an error correction code. Knowing that the block with which the NAND chip operates is 128 pages, we will calculate the block size of 2112 * 128 = 270 336 (0x42000) bytes. From 0x00108000 we step forward one block, that is, to the page at 0x0014a000.

rice 6
from the contents of fig. 5 and fig. 6 it is obvious that the 3rd byte plays the role of the page number for the NAND memory block. This assumption is not refuted when viewing all non-empty NAND memory blocks.
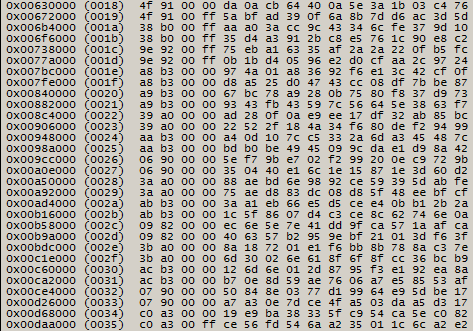
rice 7
In the 0 and 1 bytes of service data in each page for two blocks of constant values. It can be assumed that this pair of bytes is reserved for the block number. We derive all values for all blocks and find that in the low nibble of the first byte, values from 0x0 to 0x3 are used, and in the zero byte, values from 0x00 to 0xFF are run. The high nibble values in the first byte have more diverse meanings. Assume that the numbering uses 10 bits, which are formed from the two low-order bits of the first byte of the service area as the upper part and 8 bits from the zero-byte as the low part. Check the accuracy of the assumptions by outputting numbers for the first 0x400 blocks. Sorting them in ascending order, we note that a chain of numbers from 0x000 to 0x3C3 is sequentially lined up, which confirms the correctness of the assumption. By performing similar checks for the remaining groups of 0x400 blocks, we finally exclude the possibility of erroneous interpretation.
Perform data inversion, with the exception of service data, and analyze the data parallelization mechanism. Let us check the assumption of symmetry of writing to different banks by analyzing the logical numbers in the blocks in each dump. In the case of SK6211, the assumption of symmetric recording is confirmed. Find a block with a logical number 0x000, in which each 512 data block contains a sequence number and zeros as content. Based on the actual location of the data we recorded, we will build a table of the data position.
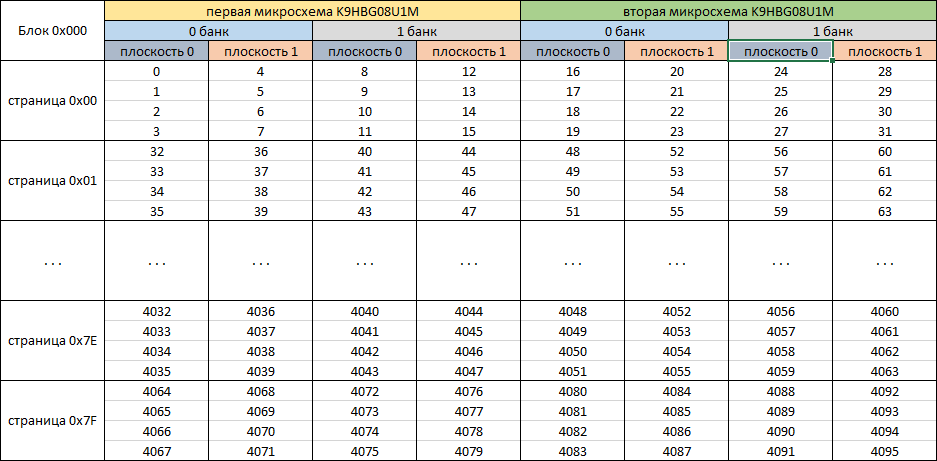
Fig. eight
According to the placement of data, we can see that the controller for this chipset implements the most efficient parallelization to obtain high performance. Taking into account the data parallelization mechanism, we calculate the block size that the translation system operates in the microcode of the drive 0x42000 * 8 = 0x210000 bytes. If we discard the service data, the block size is 0x40000 * 8 = 0x200000 (2,097,152) bytes.
For further analysis, we need to eliminate the scatter of data and collect them into solid blocks of 2 MB each.

rice 9
The first step is the elimination of parallelization between the planes by combining even blocks with odd pages by page.
The second step is to merge with the doubled size of page 0 and 1 banks of each of the NAND memory chips.
The third step is to merge with the quad page size of both NAND memory chips.
When analyzing the contents of blocks of 2 MB in the resulting dump, we observe a monotonically increasing sequence of “sectors” that we numbered, which confirms the correctness of the analysis of the data parallelization algorithm.
Next, on the collection dump, find out the order of the blocks and organization into logical banks.

Fig. ten
We search for a few dozen blocks and collect by ordinal number. According to the results of the collection, we make sure that our sector numbering in the blocks is joined. And the earlier assumption that 10 bits of the first two service bytes are a block number is true.
The total size of the chips is 8,858,370,048 (0x210000000) byte block size in the translator 2,162,688 (0x210000). Total blocks 0x210000000 / 0x210000 = 0x1000 (4096). Based on the digit capacity of the numbers used and the actual numbering, the block numbers cannot exceed 0x400 (1024). From this we can conclude that there are 4 logical banks in the broadcast. Let's conditionally divide the resulting dump into 4 equal parts (0x400 blocks each), estimate the number of blocks in each part, and based on this we assume the number of blocks included in the broadcast in each logical bank.

rice eleven
Note that the size of each logical bank is noticeably less than 0x400. This need is dictated by the fact that “extra” blocks are needed in a certain amount for service structures and, most importantly, for the effective operation of the wear leveling mechanism. The mechanism is implemented according to the principle that each block in which the content changes will be excluded from the broadcast and will fall into the backup, and its place will be taken by the block that was not included in the broadcast and was listed as backup before it was recorded. Taking into account the record counters in each block, the mechanism works quite effectively. The Achilles heel of this algorithm will be an abundance of immutable data, then a relatively small number of blocks will be involved in the rotation.
This principle is very clearly confirmed by the location of the blocks in the dump. According to fig. 10 it can be seen how nonlinear the scatter of blocks from which logical space is realized. Soldering the NAND memory chips back and connecting the USB flash to the computer, performing a certain number of entries in the first 4096 “sectors”, we drop out and read the NAND memory chips, collect and evaluate the order of the blocks in the resulting dump.

rice 12
As we can see, with the remaining order of the remaining blocks unchanged, the block with the logical number 0x000 “migrated” to another place. At the old address, all the pages of the block, both in the user data area and in the service area, are completely filled with 0xFF, which indicates the clearing of this block and exclusion from the broadcast.
Comparing the two resulting dumps, in addition to the changed data in the zero block, there will be changes in the service data, after analyzing which we can establish how the structure of the translator is formed.
This analysis method allows you to get enough data about the algorithm of the USB NAND controller to use them to recover information from damaged drives based on the controller under study, and also allows you to see the mechanisms of data parallelization and wear leveling in action. Also, based on the translator device and USB flash analysis (we conduct additional analysis activities on a drive formatted in FAT32 and filled with several thousand files), you can see that for blocks with file system structures there is no preferred block allocation.
Next post: Recovering Data from a Seagate FreeAgent Go External Hard Drive
Previous publication: Recovering Data from a Damaged RAID 5 Array to a Linux NAS
In order to dispel a bit of illusion, we will use reverse engineering methods to analyze the operation of the SKYMEDI SK6211 NAND controller using the example of a finished product in the form of USB flash 8Gb, released by Kingston.
rice one
For a complete analysis, we first create an imitation of the use of the drive by recording a large number of files, followed by partial accidental deletion and repeated recordings. Next we write the half of the LBA range with zeros, but in addition to the zeros in each “sector” we place at offset 0x0 DWORD with its number. We write the second half of the logical range using the 0x77 pattern (this pattern is relatively convenient for analyzing data noise reduction algorithms).
')
We solder both NAND flash memory chips. In this instance, they are manufactured by Samsung, labeled K9HBG08U1M in the performance of TSOP- 48. Operational characteristics: page size - 2112 bytes, block size - 128 pages, the number of blocks in the plane - 2048, the number of planes in the bank - 4, the number of physical banks - 2. The total capacity of two chips 2112 * 128 * 2048 * 4 * 2 * 2 = 8,858,370,048 bytes.
rice 2
In fig. 2 shows the principle of block numbering (the block consists of 128 pages). It should be noted that this microcircuit can simultaneously perform programming / erasing operations in two planes at once (variations 0.1 and 2.3). Those who wish to study in more detail the features of microcircuits and the nuances of working with them can look for technical documentation (datasheet), which is currently available to the general public K9HBG08U1M.pdf.
To read the chips use the NAND reader included in the complex Flash Extractor. At the time when the SK6211 controller was popular, this data recovery system was almost the only analytical tool that was commercially available.
rice 3
Starting the analysis of the data distribution algorithms by the SK6211 controller, we will learn about its possibilities of parallel operation with microchips from advertising sources, as well as about slightly different two types of error correction codes (ECC). In this publication, due to the vastness of the topic, we omit the description of the features of the operation of error correction codes, and the entire mathematical component associated with them.
The first task in the data analysis is to establish the signs of the noise in the data being written to the memory. To do this, we will search for the 0x77 pattern we have recorded and try to find a lot of pages completely filled with it. But the search results do not lead to success, which allows us to conclude that the data was recorded in a modified form. When scrolling through the dumps, we find a large number of pages filled with a value of 0x88 except the last 64 bytes, as well as a large number of pages filled entirely with 0xFF except 4 bytes at the beginning of each 512 byte block and the last 64 bytes (2112 bytes in page borders). Based on the patterns we recorded on the USB flash, we assume that data is inverted. Before inverting the data, we analyze the contents of the NAND pages to determine the location of the service data. In the places where the pattern is filled, it is very easy to distinguish our inverted uniform value from the service data, which are not composed entirely of identical sequences of bytes.
Figure 4.
The SK6211 in the pages used places 2048 bytes of data ( DA ) and 64 bytes allocates for the storage of service data ( SA ). 4 groups of data of 16 bytes are well traced, which hints at their applicability to the four blocks of 512 contained in the page.
Print the contents of the first 16-byte group of several thousand pages.
rice five
In fig. 5 it is clear that the first 4 bytes remain ordered, and the chaotic content is located in the remaining 12. Therefore, we can assume that the last 12 bytes in each line contain an error correction code. Knowing that the block with which the NAND chip operates is 128 pages, we will calculate the block size of 2112 * 128 = 270 336 (0x42000) bytes. From 0x00108000 we step forward one block, that is, to the page at 0x0014a000.
rice 6
from the contents of fig. 5 and fig. 6 it is obvious that the 3rd byte plays the role of the page number for the NAND memory block. This assumption is not refuted when viewing all non-empty NAND memory blocks.
rice 7
In the 0 and 1 bytes of service data in each page for two blocks of constant values. It can be assumed that this pair of bytes is reserved for the block number. We derive all values for all blocks and find that in the low nibble of the first byte, values from 0x0 to 0x3 are used, and in the zero byte, values from 0x00 to 0xFF are run. The high nibble values in the first byte have more diverse meanings. Assume that the numbering uses 10 bits, which are formed from the two low-order bits of the first byte of the service area as the upper part and 8 bits from the zero-byte as the low part. Check the accuracy of the assumptions by outputting numbers for the first 0x400 blocks. Sorting them in ascending order, we note that a chain of numbers from 0x000 to 0x3C3 is sequentially lined up, which confirms the correctness of the assumption. By performing similar checks for the remaining groups of 0x400 blocks, we finally exclude the possibility of erroneous interpretation.
Perform data inversion, with the exception of service data, and analyze the data parallelization mechanism. Let us check the assumption of symmetry of writing to different banks by analyzing the logical numbers in the blocks in each dump. In the case of SK6211, the assumption of symmetric recording is confirmed. Find a block with a logical number 0x000, in which each 512 data block contains a sequence number and zeros as content. Based on the actual location of the data we recorded, we will build a table of the data position.
Fig. eight
According to the placement of data, we can see that the controller for this chipset implements the most efficient parallelization to obtain high performance. Taking into account the data parallelization mechanism, we calculate the block size that the translation system operates in the microcode of the drive 0x42000 * 8 = 0x210000 bytes. If we discard the service data, the block size is 0x40000 * 8 = 0x200000 (2,097,152) bytes.
For further analysis, we need to eliminate the scatter of data and collect them into solid blocks of 2 MB each.
rice 9
The first step is the elimination of parallelization between the planes by combining even blocks with odd pages by page.
The second step is to merge with the doubled size of page 0 and 1 banks of each of the NAND memory chips.
The third step is to merge with the quad page size of both NAND memory chips.
When analyzing the contents of blocks of 2 MB in the resulting dump, we observe a monotonically increasing sequence of “sectors” that we numbered, which confirms the correctness of the analysis of the data parallelization algorithm.
Next, on the collection dump, find out the order of the blocks and organization into logical banks.
Fig. ten
We search for a few dozen blocks and collect by ordinal number. According to the results of the collection, we make sure that our sector numbering in the blocks is joined. And the earlier assumption that 10 bits of the first two service bytes are a block number is true.
The total size of the chips is 8,858,370,048 (0x210000000) byte block size in the translator 2,162,688 (0x210000). Total blocks 0x210000000 / 0x210000 = 0x1000 (4096). Based on the digit capacity of the numbers used and the actual numbering, the block numbers cannot exceed 0x400 (1024). From this we can conclude that there are 4 logical banks in the broadcast. Let's conditionally divide the resulting dump into 4 equal parts (0x400 blocks each), estimate the number of blocks in each part, and based on this we assume the number of blocks included in the broadcast in each logical bank.
rice eleven
Note that the size of each logical bank is noticeably less than 0x400. This need is dictated by the fact that “extra” blocks are needed in a certain amount for service structures and, most importantly, for the effective operation of the wear leveling mechanism. The mechanism is implemented according to the principle that each block in which the content changes will be excluded from the broadcast and will fall into the backup, and its place will be taken by the block that was not included in the broadcast and was listed as backup before it was recorded. Taking into account the record counters in each block, the mechanism works quite effectively. The Achilles heel of this algorithm will be an abundance of immutable data, then a relatively small number of blocks will be involved in the rotation.
This principle is very clearly confirmed by the location of the blocks in the dump. According to fig. 10 it can be seen how nonlinear the scatter of blocks from which logical space is realized. Soldering the NAND memory chips back and connecting the USB flash to the computer, performing a certain number of entries in the first 4096 “sectors”, we drop out and read the NAND memory chips, collect and evaluate the order of the blocks in the resulting dump.
rice 12
As we can see, with the remaining order of the remaining blocks unchanged, the block with the logical number 0x000 “migrated” to another place. At the old address, all the pages of the block, both in the user data area and in the service area, are completely filled with 0xFF, which indicates the clearing of this block and exclusion from the broadcast.
Comparing the two resulting dumps, in addition to the changed data in the zero block, there will be changes in the service data, after analyzing which we can establish how the structure of the translator is formed.
This analysis method allows you to get enough data about the algorithm of the USB NAND controller to use them to recover information from damaged drives based on the controller under study, and also allows you to see the mechanisms of data parallelization and wear leveling in action. Also, based on the translator device and USB flash analysis (we conduct additional analysis activities on a drive formatted in FAT32 and filled with several thousand files), you can see that for blocks with file system structures there is no preferred block allocation.
Next post: Recovering Data from a Seagate FreeAgent Go External Hard Drive
Previous publication: Recovering Data from a Damaged RAID 5 Array to a Linux NAS
Source: https://habr.com/ru/post/329596/
All Articles