Experiments with malloc and neural networks
More than a year ago, when I was working as an anti-spammer at Mail.Ru Group, I was rolled over, and I wrote about experiments with malloc . At that time, I was pleased to help conduct seminars on AKOS at the FIVT MIPT , and there was a topic about memory allocation. The topic is large and very interesting, and at the same time it covers both the low level of the core and the algorithm-intensive structures itself. In all textbooks it is written that one of the main problems of dynamic memory allocation is its unpredictability. As they say, I would have known a pack - I would have lived in Sochi. If the oracle had previously told the entire plan for which memory would be allocated and freed, then it would have been possible to make an optimal strategy that minimizes heap fragmentation, peak memory consumption, etc. From here, there was a fuss with manual allocators. In the process of thinking, I came across the lack of logging tools malloc() and free() . I had to write them! Just about this was an article (and I also studied macOS). Two parts were planned, but life turned abruptly and it was not until malloc() . So, it's time to restore justice and realize the promise: strike with deep training in predicting work with a bunch .
Inside:
- Improving
libtracemallocinterceptormalloc(). - We build LSTM on Keras - a deep recurrent network.
- We teach the model on the example of the real application ( vcmi / vcmi - and you thought, and here Heroes III?).
- We are surprised by unexpectedly good results.
- We fantasize about the practical application of technology.
- Sources
Interesting? Welcome under cat.
libtracemalloc
In the first article, we logged only malloc() . That implementation had several drawbacks:
- Multithreading was ignored when serializing calls. In other words, we were losing information about which thread the memory was allocated from.
- Multithreading was ignored when writing to a file. The
write()call was made competitively, without a mutex. Despite the fact that POSIX requires its atomicity, in Linux up to version 3.14 there was an unpleasant positioning bug that the Principal himself fixed , and some still test this property in practice . - Not logged in
free().
The following code corrects (1) and (2):
int fd = 0; void* (*__malloc)(size_t) = NULL; pthread_mutex_t write_sync = PTHREAD_MUTEX_INITIALIZER; inline void get_time(long* sec, long* mcsec) { /* ... */ } void* malloc(size_t size) { if (!__malloc) { __malloc = (void*(*)(size_t)) dlsym(RTLD_NEXT, "malloc"); } if (!fd) { fd = open(LOG, O_WRONLY | O_CREAT | O_EXCL, 0666); if (fd < 0) { return __malloc(size); } } long sec, mcsec; get_time(&sec, &mcsec); void* ptr = __malloc(size); char record[64]; pthread_mutex_lock(&write_sync); write(fd, record, sprintf(record, "%ld.%06ld\t%ld\t%zu\t%p\n", sec, mcsec, pthread_self(), size, ptr)); pthread_mutex_unlock(&write_sync); return ptr; } Accordingly, we use pthread_self() and execute write() under the mutex. If you look closely, you can still see O_EXCL in the flags of open() . I added it to correct the behavior during early fork() , i.e. before working with a bunch. Two forked processes simultaneously opened a file and overwritten each other.
It remains to correct (3):
void (*__free)(void*) = NULL; void free (void *ptr) { if (!__free) { __free = (void(*)(void*)) dlsym(RTLD_NEXT, "free"); } if (!fd) { __free(ptr); return; } long sec, mcsec; get_time(&sec, &mcsec); char record[64]; pthread_mutex_lock(&write_sync); write(fd, record, sprintf(record, "%ld.%06ld\t%ld\t-1\t%p\n", sec, mcsec, pthread_self(), ptr)); pthread_mutex_unlock(&write_sync); __free(ptr); } Logging happens completely by analogy with malloc() .
As a result, we get something like the following:
0.000000 140132355127680 552 0x2874040 0.000047 140132355127680 120 0x2874270 0.000052 140132355127680 1024 0x28742f0 0.000079 140132355127680 -1 0x2874270 0.000089 140132355127680 -1 0x28742f0 0.000092 140132355127680 -1 0x2874040 0.000093 140132355127680 -1 (nil) 0.000101 140132355127680 37 0x2874040 0.000133 140132355127680 32816 0x2874070 0.000157 140132355127680 -1 0x2874070 0.000162 140132355127680 8 0x2874070 LSTM at Keras
To begin with, let's define what we specifically want to predict. It would be desirable to predict the sequence of future ones in the preceding call history of malloc() and free() , and immediately with the size. It would be very cool to apply attention (attention) and immediately indicate which parts of the memory will be freed, but I suggest that the inquiring reader be engaged in this - an excellent thesis will be released. Here I will do it easier and I will predict how much memory is released.
The next point is that predicting the exact size of RMSE is a rotten and disastrous idea. I tried: the network treacherously converges to the average value on all. Therefore, I introduce size classes in powers of two, just like that of the famous buddy allocator . In other words, the prediction problem is posed as a classification problem. Example:
| the size | the class |
|---|---|
| one | one |
| 2 | 2 |
| 3 | 2 |
| four | 3 |
| five | 3 |
| 6 | 3 |
In total we have 32 classes, having put mental (incorrect) restriction on malloc(uint32_t size) . In fact, there is 64-bit size_t , and you can allocate more than 4 GiB.
We will take the class from free() from the corresponding malloc() call, since we know the pointer to the memory being freed. To somehow distinguish the classes of malloc() from the classes of free() , we add to the last 32. Total only 64 classes. This, frankly, quite a bit. If there are any regularities in our data, then any even the most stupid network should learn something from them. The following code parses the log received from libtracemalloc .
threads = defaultdict(list) ptrs = {} with gzip.open(args.input) as fin: for line in fin: parts = line[:-1].split(b"\t") thread = int(parts[1]) size = int(parts[2]) ptr = parts[3] if size > -1: threads[thread].append(size.bit_length()) ptrs[ptr] = size else: size = ptrs.get(ptr, 0) if size > 0: del ptrs[ptr] threads[thread].append(32 + size.bit_length()) As you can see, we save new pointers and delete old ones, as if emulating a bunch. Now we need to turn the threads dictionary into digestible x and y .
train_size = sum(max(0, len(v) - maxlen) for v in threads.values()) try: x = numpy.zeros((train_size, maxlen), dtype=numpy.int8) except MemoryError as e: log.error("failed to allocate %d bytes", train_size * maxlen) raise e from None y = numpy.zeros((train_size, 64), dtype=numpy.int8) offset = 0 for _, allocs in sorted(threads.items()): for i in range(maxlen, len(allocs)): x[offset] = allocs[i - maxlen:i] y[offset, allocs[i].bit_length()] = 1 offset += 1 Here maxlen is the length of the context by which we will predict. By default, I set it to 100. It remains to create the model itself. In this case - 2 layers of LSTM and polingling above, as standard.
from keras import models, layers, regularizers, optimizers model = models.Sequential() embedding = numpy.zeros((64, 64), dtype=numpy.float32) numpy.fill_diagonal(embedding, 1) model.add(layers.embeddings.Embedding( 64, 64, input_length=x[0].shape[-1], weights=[embedding], trainable=False)) model.add(getattr(layers, layer_type)( neurons, dropout=dropout, recurrent_dropout=recurrent_dropout, return_sequences=True)) model.add(getattr(layers, layer_type)( neurons // 2, dropout=dropout, recurrent_dropout=recurrent_dropout)) model.add(layers.Dense(y[0].shape[-1], activation="softmax")) optimizer = getattr(optimizers, optimizer)(lr=learning_rate, clipnorm=1.) model.compile(loss="categorical_crossentropy", optimizer=optimizer, metrics=["accuracy", "top_k_categorical_accuracy"]) 
To handle memory with care, I use untrained Embedding and do not do one hot encoding beforehand. So x and y 8-bit (64 <256), and the minibatch is 32-bit. This is important because very short-running programs manage to generate tens of millions of samples. neurons default is neurons 128, no dropouts. Let's start learning!
model.fit(x, y, batch_size=batch_size, epochs=epochs, validation_split=validation) I was forced to export TF_CPP_MIN_LOG_LEVEL=1 , otherwise Tensorflow was spamming PoolAllocators.
results
As an experimental, let's take vcmi / vcmi - the GPL-implementation of the third- person engine, which I've been contributing to. A very complete and quite good implementation, but the guys urgently need autotests. And since I was talking, I really want to screw the Python API to the engine and try to implement neural network AI. Sometimes people object, they say that Heroes have many degrees of freedom. I answer that no one forces AlphaGo to do right away; you can start small, with fights.
Clone, collect the vcmi code, get the original resources, run the game and collect the heap call log:
# ... easy ... LD_PRELOAD=/path/to/libtracemalloc.so /path/to/vcmiclient I launched Arrogance, wandered a couple of weeks, got resources. The speed sags heavily, but this is not valgrind. The resulting log unloaded on Google Drive - 94MiB. Distribution on the first 32 classes:
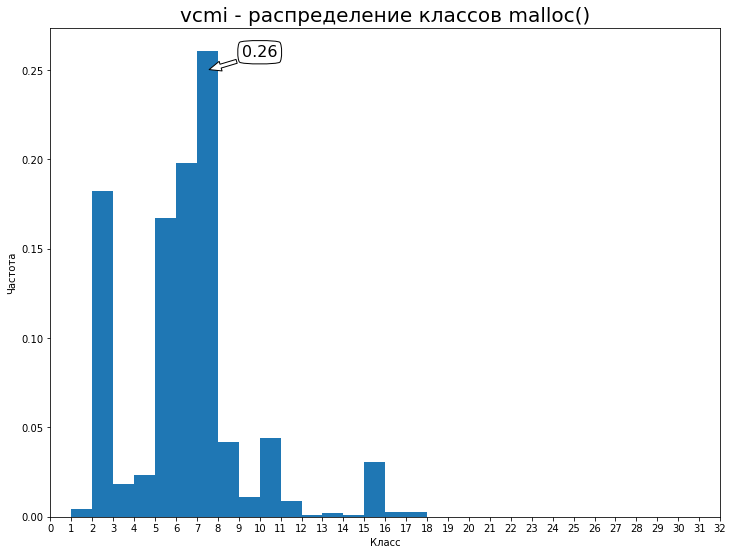
So our baseline is 0.26 accuracy. Let's try to improve it. The training of the model took 10.5 hours per era on Pascal Titan (2 epochs, 21 hours, validation_split = 15%). In general, the second era does not greatly change the result and only one is enough. Such metrics turned out:
loss: 0.0512 val_loss: 0.1160 acc: 0.9837 val_acc: 0.9711 top_k_categorical_accuracy: 1.0000 val_top_k_categorical_accuracy: 0.9978 In my opinion, it came out very cool. We achieved 97% accuracy of validation, which means approximately 20 correct predictions with an accuracy higher than 50%. If we replace LSTM with GRU, then it will be possible to reduce the epoch time to 8 hours with slightly better metrics.
What I see vectors of development of the model:
- Increasing the number of neurons in the forehead, perhaps, will give an improvement in metrics.
- Experiments with architecture, metaparameters. At a minimum, you need to investigate the dependence on the length of the context and the number of layers.
- Enrich the prediction context by expanding the call stack and using debuginfo. From the chain of functions to the full source code.
The size of the trained model is 1 megabyte, which is much less than the full story - 98MB in gzip. I am sure that having properly networked the network, it will be possible to reduce it without compromising quality.
Future
“Wait,” the reader will say, “no one in their right mind will drive the network forward with each call to malloc.” Of course, when every cycle counts, multiplying the matrix 128 by 100 by 64 looks silly. But I have objections:
- You need to run the network every 20 calls or even less. If technology is improved, this number will increase.
- Multi-core processors have long become commonplace, and they are far from being used 100%. During periods of program downtime, on a block in some
read(), we have a tangible time quantum and resources for inference. - Not far off neuroaccelerators. TPU is already manufactured by Google , IBM , Samsung . Why not use them to speed up existing "simple" programs, analyzing their behavior over time and dynamically adapting runtime to them.
TL; DR
Model RNN to predict the dynamic allocation and release of memory in the game Heroes III managed to train with an accuracy of 97%, which is very unexpected and cool. There is a prospect to implement the idea in practice to create memory allocators of the new generation.
 Source code machine learning is a new, exciting topic. Come to source {d} tech talks conference on June 3, there will be Chalz Sutton, the author of half of all articles and Georgios Giusius, the star of Mining Software Repositories and the founder of GHTorrent . Participation is free, the number of places is limited.
Source code machine learning is a new, exciting topic. Come to source {d} tech talks conference on June 3, there will be Chalz Sutton, the author of half of all articles and Georgios Giusius, the star of Mining Software Repositories and the founder of GHTorrent . Participation is free, the number of places is limited.
')
Source: https://habr.com/ru/post/329518/
All Articles