Apache Ignite 2.0 - Machine Learning, a new data storage model, DDL
In May, a new major version of Apache Ignite was released - a distributed platform optimized for working with RAM, which combines a key-value type repository with an SQL99-compatible database, offering full ACID compatibility, high availability, and close to linear scaling from a few nodes to thousands that can be hosted on their own equipment or in the cloud. The Apache Ignite kernel is written in Java, but the platform, in addition to the Java ecosystem, supports native integration with .NET and C ++ applications.
Apache Ignite elastically scales across one or more geo-distributed clusters, providing flexible custom sharding and automatic rebalancing when dynamically adding or removing nodes, providing transparent and fast access to data and calculations using our own API or classic SQL.
In version 2.0, many things under the hood were significantly reworked, the result was the possibility of implementing a number of significant functional changes, some of which are noticeable now, and some will appear in the next versions.
')
Looking ahead, we will hold 2 events that are associated with Apache Ignite, more about them can be found at the end of the article.

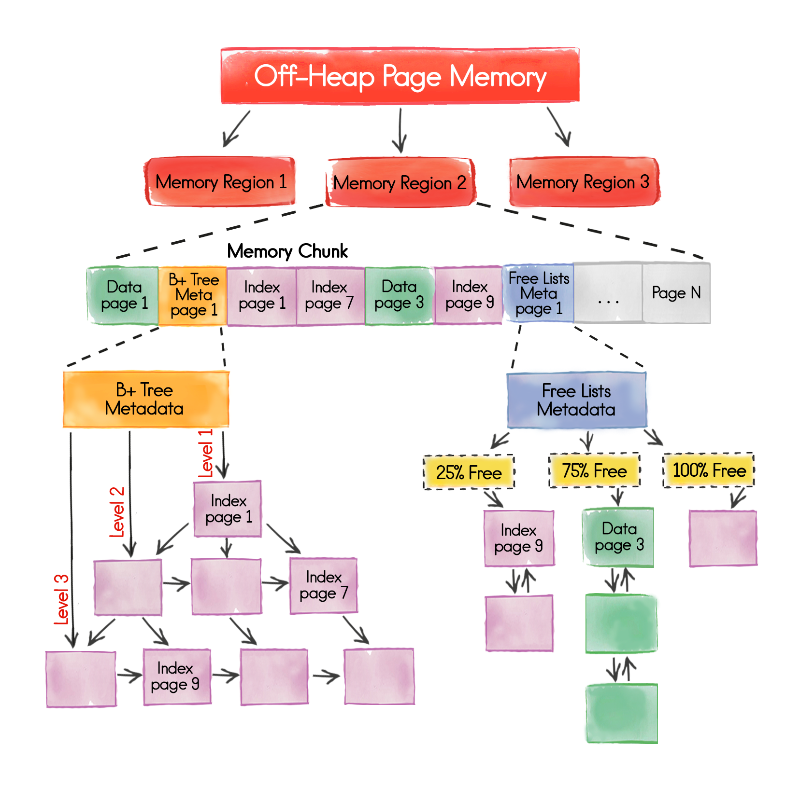
Apache Ignite by default works with RAM, stores data in it in a distributed form and performs calculations there. One of the key innovations of version 2.0 is a completely redesigned memory management architecture called Page Memory. And this is very important.
The new approach to data storage is much more complicated and thoughtful than the old one, it allows you to avoid problems with memory fragmentation, significantly speed up work with SQL and minimize the effect of GC pauses on the functioning of the system. Moreover, the new architecture allows you to work seamlessly with both RAM and disk. In version 2.0, this feature is not yet available, but soon we will be able to learn about our plans for development in this area in more detail.
The new architecture can be found in general terms in the figure below, as well as in a special section of the documentation .
The goal of Apache Ignite is to build a platform that includes many closely integrated modules, not just a distributed Data Grid storage, using which developers can solve tasks of various degrees of complexity, from very light (I want a fast distributed cache) to very heavy (I I want real-time distributed HTAP computing on large data stored in data centers in different parts of the Earth, while I would like to integrate with Cassandra, Spark, Hadoop, etc.).
Unfortunately, a bundle of components for one of the “hottest” areas of modern IT — machine learning — was missing from Apache Ignite. Up to this point.
Apache Ignite 2.0 adds support for basic machine learning algebra adapted for distributed computing. We understand that while we offer very low-level tools, we are not going to dwell on this. In future versions, this basic algebra will become the basis on which we will build distributed implementations of the basic machine learning algorithms: regressions, classification trees, etc.
In the meantime, you can familiarize yourself with examples on GitHub and try to touch the current product with your hands.
From this release in Apache Ignite, initial DDL support is added to the DML. Now you can create and, importantly, change the indices without interrupting the work of the cluster nodes using the classic SQL syntax. This is one of the most awaited features that our users have requested so much. And this is just the beginning! In subsequent releases, more and more DDL operations will appear, including CREATE TABLE, ALTER TABLE, etc. Read more about current features in the documentation .
In honor of the release of Apache Ignite 2.0, we plan to hold 2 events:
- webinar June 7, which will tell about the innovations of version 2.0 in English
- Ignition.meetup (), which will be held in Moscow in the near future (to be announced separately), where it will be possible to exchange experience in Russian, ask questions and hear about real case building solutions on the platform
Apache Ignite elastically scales across one or more geo-distributed clusters, providing flexible custom sharding and automatic rebalancing when dynamically adding or removing nodes, providing transparent and fast access to data and calculations using our own API or classic SQL.
In version 2.0, many things under the hood were significantly reworked, the result was the possibility of implementing a number of significant functional changes, some of which are noticeable now, and some will appear in the next versions.
')
Looking ahead, we will hold 2 events that are associated with Apache Ignite, more about them can be found at the end of the article.
New storage architecture
Apache Ignite by default works with RAM, stores data in it in a distributed form and performs calculations there. One of the key innovations of version 2.0 is a completely redesigned memory management architecture called Page Memory. And this is very important.
The new approach to data storage is much more complicated and thoughtful than the old one, it allows you to avoid problems with memory fragmentation, significantly speed up work with SQL and minimize the effect of GC pauses on the functioning of the system. Moreover, the new architecture allows you to work seamlessly with both RAM and disk. In version 2.0, this feature is not yet available, but soon we will be able to learn about our plans for development in this area in more detail.
The new architecture can be found in general terms in the figure below, as well as in a special section of the documentation .
Machine learning
The goal of Apache Ignite is to build a platform that includes many closely integrated modules, not just a distributed Data Grid storage, using which developers can solve tasks of various degrees of complexity, from very light (I want a fast distributed cache) to very heavy (I I want real-time distributed HTAP computing on large data stored in data centers in different parts of the Earth, while I would like to integrate with Cassandra, Spark, Hadoop, etc.).
Unfortunately, a bundle of components for one of the “hottest” areas of modern IT — machine learning — was missing from Apache Ignite. Up to this point.
Apache Ignite 2.0 adds support for basic machine learning algebra adapted for distributed computing. We understand that while we offer very low-level tools, we are not going to dwell on this. In future versions, this basic algebra will become the basis on which we will build distributed implementations of the basic machine learning algorithms: regressions, classification trees, etc.
In the meantime, you can familiarize yourself with examples on GitHub and try to touch the current product with your hands.
Data Definition Language
From this release in Apache Ignite, initial DDL support is added to the DML. Now you can create and, importantly, change the indices without interrupting the work of the cluster nodes using the classic SQL syntax. This is one of the most awaited features that our users have requested so much. And this is just the beginning! In subsequent releases, more and more DDL operations will appear, including CREATE TABLE, ALTER TABLE, etc. Read more about current features in the documentation .
Also among the changes
- Ignite.NET: plugin system support for Ignite.NET ;
- Ignite.C ++: remote calling of C ++ code on the cluster, in this version so far only in continuous queries;
- Spring Data integration makes it easy to deploy Apache Ignite, making it easy to use with a common framework for building applications;
- integration with RocketMQ ;
- Hibernate 5 L2 cache support;
- and much more
Webinar and Meetup
In honor of the release of Apache Ignite 2.0, we plan to hold 2 events:
- webinar June 7, which will tell about the innovations of version 2.0 in English
- Ignition.meetup (), which will be held in Moscow in the near future (to be announced separately), where it will be possible to exchange experience in Russian, ask questions and hear about real case building solutions on the platform
Source: https://habr.com/ru/post/329318/
All Articles