Artists map, awkward search for links in the data and how to reinvent the wheel
Recently watched a series of videos popularized mathematics. There, he tries to talk about mathematical analysis and linear algebra a bit from the perspective of a person who “as if” would invent it from scratch. That is, it tries to make simple and understandable visualizations of relatively complex concepts accessible, as if explaining them from the position of a person who seemed to have invented this for the first time. Relatively recently I read an article on Habré about unsupervised learning and saw the section on Affinity Propagation there . As it turned out, we used this particular cluster analysis method purely intuitively, without knowing it.
TLDR for this article . If you want an interactive visualization, go here .
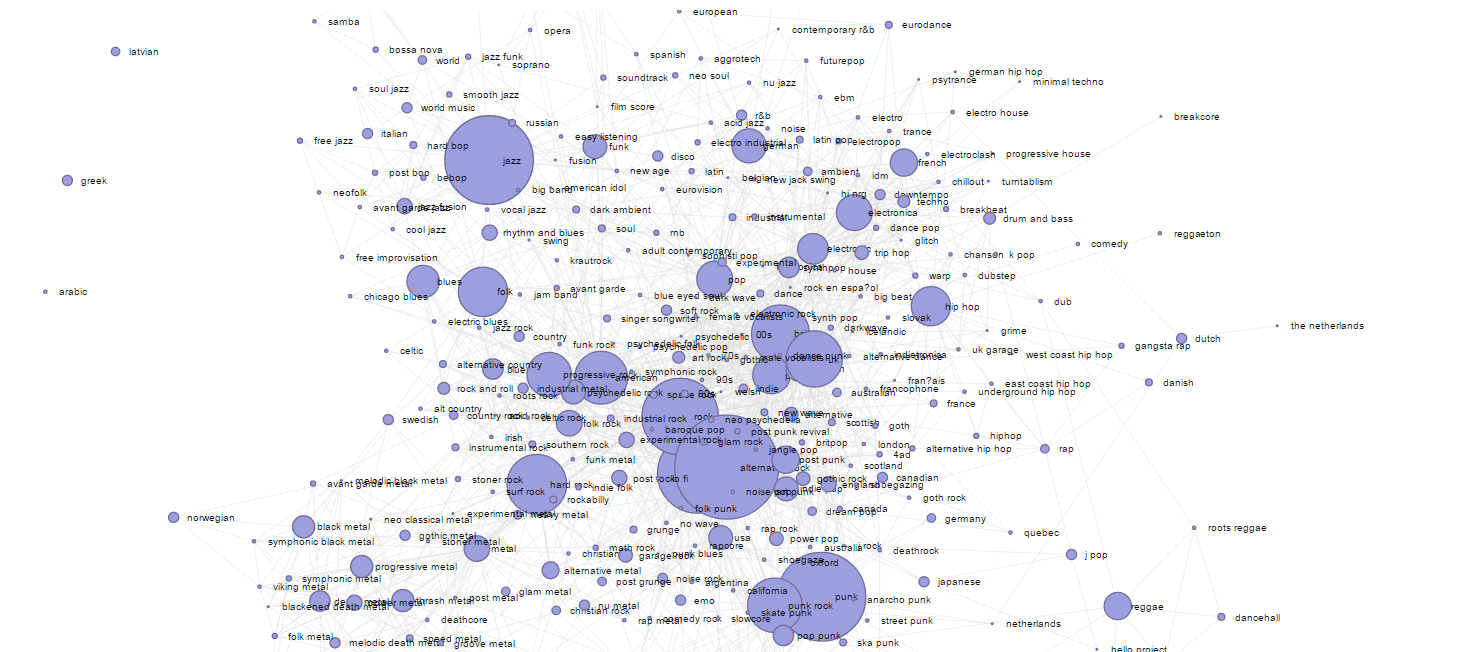
In this visualization, in the form of a graph, the connections between the music genres of ~ 25,000 of the most popular artists of the world are shown, with the size of the roundelet showing the popularity of this genre, and the size of the edge of the graph - the strength of the connection.
Eureka times
')
This visualization is a visualization made on the D3.js library (we found a template somewhere) on the data of similarity of groups. Baseline data and your recursion can be started here . The data processing algorithm was approximately the same (it was all a long time ago, I remember in general terms, jpn did not use it then):
Then, when we did this, we did not know about python and data science (lolshto?) And everything was done by combining SQL queries, manipulating CSV files and multiplying the resulting matrices. When we cleaned the base of the company and sent everyone a cherished email, in which everything was done, everything that was done and the specified diagram was shown ... in response, we received nothing. No one asked a single question. Everyone was just indifferent. Our painstaking data went on prod, extending the life of the tag system for a couple of years (there was fierce rubbish, because there was no curation and control over data filling), and in response we received silent silence and reproaches of the format “why did we spend so much time for some shit? " The fact that such information is incredibly useful for building recommendations, similarity ratings, cross-sales and increasing linking on the site also went unnoticed.
After that, I remember the episode when one of the company's managers tried to enter feedback on events in the form of a single asterisk. This did not reach implementation either for the reason described above. What kind of collaborative filtering there is =)
It was both funny and sad that in fact we “groped” the working algorithm and made it work on the prod, but as everyone says, it doesn’t matter.
Eureka two
The second moment of a similar eureka is a primitive algorithm of collaborative filtering (best of all on the knee, it is explained here in the form of an xlsx file). In theory, the “correct” algorithm works like this:
In practice, without knowing about it and about the python, I did so. I calculated some indicator that had a Poisson distribution and tried to normalize it and bring it to normal. It looks like this:

With a set of indicators looks like this:

Then I selected weights by linear and logistic regressions. In fact, a very rough analogue of such a method is obtained, but where instead of latent factors are certain heuristics, invented by me and having fairly good statistical properties.
In general, if you have not yet understood, then my thought is this:
TLDR for this article . If you want an interactive visualization, go here .
In this visualization, in the form of a graph, the connections between the music genres of ~ 25,000 of the most popular artists of the world are shown, with the size of the roundelet showing the popularity of this genre, and the size of the edge of the graph - the strength of the connection.
Eureka times
')
This visualization is a visualization made on the D3.js library (we found a template somewhere) on the data of similarity of groups. Baseline data and your recursion can be started here . The data processing algorithm was approximately the same (it was all a long time ago, I remember in general terms, jpn did not use it then):
- Take the base Musicbrainz;
- Unpack it ( if necessary - contact, there is an unpacked copy in PostgreSQL somewhere a year ago );
- Take the data of all artists, all albums with genres;
- Build the distribution of the number of albums, genres, tracks per artist. Build a distribution of the popularity of genres;
- Take logarithms of this data and clean them from obvious garbage, rare or very frequent "garbage" values;
- Then followed a series of steps related to the base of the company where I worked, which are less important (in fact, we also linked genres, cleaned our internal base of debris, set values, etc., etc.);
- Taking as a measure of similarity the number of identical genres among artists, construct a distance metric between i) artists ii) between genres;
- In fact, as I recall, in practice we did this by multiplying matrices of ~ 25,000 rows;
- As a result, we received measures of the similarity of artists and musical genres;
- The similarity of the artists turned out to be so-so, since, on average, the artist had several tags, but the similarity of the genres was excellent;
- With handwriting and cluster analysis, we merged genres into groups of genres;
Then, when we did this, we did not know about python and data science (lolshto?) And everything was done by combining SQL queries, manipulating CSV files and multiplying the resulting matrices. When we cleaned the base of the company and sent everyone a cherished email, in which everything was done, everything that was done and the specified diagram was shown ... in response, we received nothing. No one asked a single question. Everyone was just indifferent. Our painstaking data went on prod, extending the life of the tag system for a couple of years (there was fierce rubbish, because there was no curation and control over data filling), and in response we received silent silence and reproaches of the format “why did we spend so much time for some shit? " The fact that such information is incredibly useful for building recommendations, similarity ratings, cross-sales and increasing linking on the site also went unnoticed.
After that, I remember the episode when one of the company's managers tried to enter feedback on events in the form of a single asterisk. This did not reach implementation either for the reason described above. What kind of collaborative filtering there is =)
It was both funny and sad that in fact we “groped” the working algorithm and made it work on the prod, but as everyone says, it doesn’t matter.
Eureka two
The second moment of a similar eureka is a primitive algorithm of collaborative filtering (best of all on the knee, it is explained here in the form of an xlsx file). In theory, the “correct” algorithm works like this:
- There is a selection of conditional reviews on movies;
- From a priori considerations, the number of latent (unobservable factors) is chosen - let's say people rate films on 5 criteria;
- Random weights are generated that mediate the user-latent factor and film-latent factor relationships;
- The model also includes constants (bias values);
- The method of gradient descent or its equivalent is the optimization of weights (see the xls file at the link above);
In practice, without knowing about it and about the python, I did so. I calculated some indicator that had a Poisson distribution and tried to normalize it and bring it to normal. It looks like this:
With a set of indicators looks like this:
Then I selected weights by linear and logistic regressions. In fact, a very rough analogue of such a method is obtained, but where instead of latent factors are certain heuristics, invented by me and having fairly good statistical properties.
In general, if you have not yet understood, then my thought is this:
- Do what you like;
- Do not listen to "advisers" and all those who "know best", but do nothing;
- Do not despair if dark personalities, dark moments and dark situations will meet on your way;
- Try to improve your work, yourself and the world at least bit by bit every day;
Source: https://habr.com/ru/post/329250/
All Articles