Big data for big science. Lecture in Yandex
The author of this report has been an employee of the Large Hadron Collider (LHC) for 12 years, and last year he began working in parallel with Yandex. In his lecture, Fedor talks about the general principles of the LHC, research objectives, data volumes and how this data is processed.
Under the cut - the decoding and the main part of the slide.
Why did I take the report with pleasure? I have been involved in experimental high-energy physics for almost my entire career. He worked on more than five different detectors, starting from the 90s of the last century, and this is an extremely interesting and exciting work - to explore, to be at the very forefront of the study of the universe.
')
Experiments in high-energy physics are always large, these experiments are quite expensive, and the next step in knowledge is not easy to do. In particular, therefore, behind each experiment, as a rule, there is a certain idea, what do we want to check? As you know, there is a relationship between theory and experiment, this is the cycle of understanding the world. We are seeing something, we are trying to streamline our understanding, to present some models. Good models have predictive power, we can predict something, and we again check it experimentally. And gradually, walking in a spiral, at each turn, we learn something new.
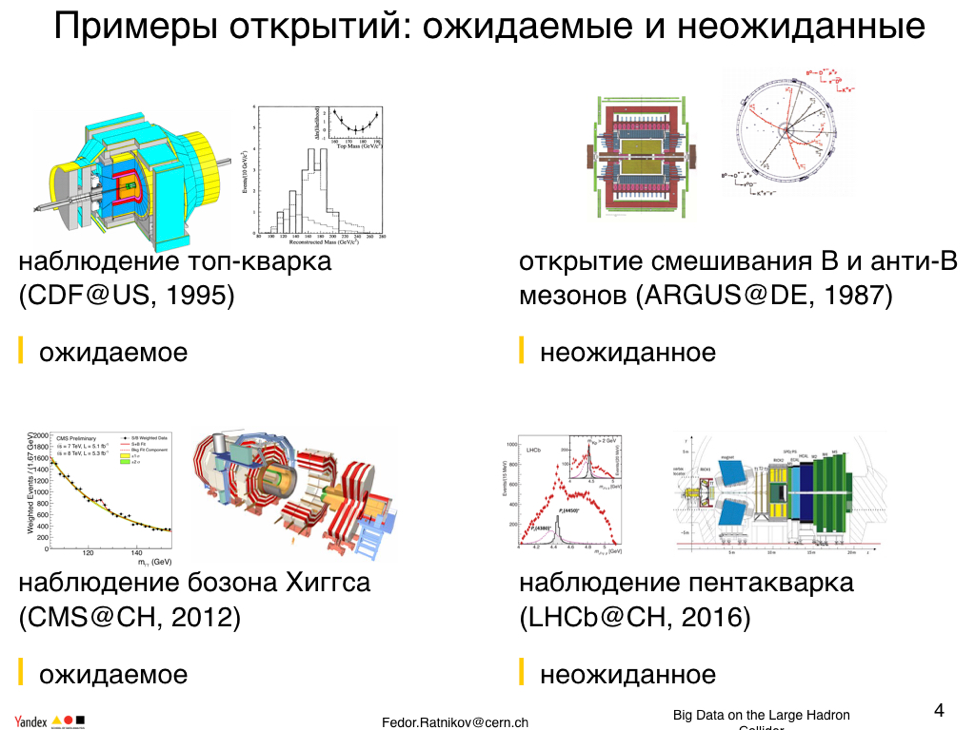
Experiments in which I worked - how did they make discoveries? What were the detectors built for? For example, a CDF detector on Tevatron ? Tevatron was built primarily to open the top quark. He was safely open. By the way, when analyzing the top quark data in my memory for the first time, multi valued analysis data was seriously used. In fact, even then, so long ago, the work was built by the method of machine learning.
Another experiment where I was lucky to work is CMS at LHC. The LHC physical program was aimed at three goals: Higgs, supersymmetry, and quark-gluon plasma. Higgs - this was the number one goal that was successfully completed by 2012.
When we recruit new data, we walk through unknown terrain, we discover unexpected things. Among these was the discovery of the mixing of B-mesons and anti-B-mesons in the last century, which somewhat changed our understanding of the standard model. It was completely unexpected.
In 2016, the Herbie experiment observed a pentaquark, states of this type were observed for a long time, but each time they were resolved. This time I have a feeling that the object that is observed will stand. A truly unique object, this is not a baryon, not a meson, but a new state of matter.

But we still talk about the data. In this slide, I tried to imagine the position of high energy physics data in the general hierarchy. In today's world, data rules the world, data is analyzed everywhere. I dragged this picture with Wired, but the statistics are given for 2012. What is the data flow typed in various services? Far ahead with the number 3000 RV, business correspondence is breaking ahead; we all write a lot of letters. In second place is Facebook, which we upload there, the seals, oddly enough, take second place in volume, ahead of serious tasks that, say, Google does. In fourth place is the archive of all medical records more or less known, which are used for the development of new methods in medicine. And the following are the data of the LHC, about 15 RV in the code. At the same level go and data from YouTube. That is, the data of one, albeit large, but one experiment of a particular field of physics has a capacity comparable to the largest data sources.
This means that since we are not the biggest, we can use the best practices of Google, Facebook, and other industrial services. However, our data has quite specific properties that require serious adaptation of the available methods. It is interesting to note that high-energy physics was the driver of computer technology from the 60s to the 80s, and then large computer mainframes, data storage systems, were made specifically for high-energy physics tasks.
After that, nuclear tests were banned, and simulation of nuclear explosions became the driver.

Why are we doing this all? Vladimir Igorevich roughly told . In this picture I tried to roughly describe the border of the famous. According to the currently prevailing theory, our universe arose as a result of the Big Bang, which occurred about 13 billion years ago. The universe arose from a bunch of energy that began to expand, particles formed there, they clustered into atoms, into molecules, into matter, and so on. This picture shows the timeline of what happened during the Big Bang.
What happens now, when particles known to us have formed - electrons, neutrons, protons? We more or less understand the physics of these processes. There is a certain border that I have depicted here and which corresponds approximately to the times of 10 -10 s, the energies attainable at the LHC now. This is practically the greatest energy achievable experimentally. This is a border beyond which we can not clearly say anything. What is on the right side at lower energies, we more or less understand and have verified experimentally. What is on the left side ... there are various theories and ideas about this, different scientists present it in different ways, and it is quite difficult to test it experimentally, directly.
The bottom line is that today, when we explore physics at high energies at the collider, we look into the very early history of the Universe. And this story is 10 -10 . This is very little, this is the time for which the light passes 3 cm.

Here are some examples of global physical questions to which we have no answers. There are quite a few of these questions. And if you think about it, there are very dark spots. Dark matter and energy. That matter and energy that we observe is approximately 5% of what we measure through various gravitational observations. This is about the same as you have a flat of 20 square meters, and you receive a heating bill of 1000 meters, and everything is correct, somewhere else the square meters are heated, but you do not understand where they are. Similarly, we do not understand in which particles the dark matter is.
We are researching new properties of matter. In particular, at colliders we produce directly new particles unknown to us. How do we do it? Literally knocked out of nothing. Everyone knows Einstein's formula E = mc 2 , but it also has the opposite meaning: if we concentrate energy in one small area, a new matter can form, an electron pair with a positron or something else. If we concentrate a lot of energy, quite complex particles can be born, which instantly break up into ordinary particles known to us. Therefore, we cannot observe literally new unusual particles. However, we can register their decay products and extract information about what was born from there.
This is the paradigm we are following in experimental high-energy physics. And for this purpose, on the one hand, a high particle accelerator is needed in order to concentrate energy at a certain point, to create these particles. On the other hand, we must surround this point with a kind of detector in order to fix, take a picture of the decay products of the particles.

Photography is a very good association, because now in the detectors most of the information comes from silicon detectors, which are nothing more than a matrix in digital cameras. At CERN at BAC we have four large digital cameras. Four experiments: two general, ATLAS and CMS, and two specialized, HERA-B and Alice.
What are these cameras? The height of the ATLAS detector is 25 meters. I tried to present it in real scale. Weight - 150 thousand tons.
You roughly represent the size of the matrix of the camera. There are about 200 square meters of matrix.
In fact, there are many layers of the matrix in order to register the particles that pass between them.
The coolest thing for these experiments is their speed. They shoot at a speed of 40 million frames per second. 40 million times a second, protons in the collider collide with protons. In each of these collisions, something new is possible. It is rare, but nevertheless, in order not to miss, we must read every collision.
We cannot record as much, we actually record about 200-500 frames per second, but this is also not bad.
In addition, detectors with this speed click for many years with a break for the winter holidays.

In this slide, I reproduce what Vladimir Igorevich explained remarkably. On the right picture that he showed. How often do we have various physical processes as a result of a collision? As a result of proton collisions, only a cluster of energy arises, and anything can be generated from this energy, which is energetically permissible. Usually something ordinary is born: pi-mesons, protons, electrons.
They asked me why you give birth to what you do not need? Why don't you make collisions so that the Higgs boson is born and not tormented by the need to read 40 million events per second? I would say that it is impossible now because of first principles, precisely because of the collision we have, and the only characteristic is energy. The cluster does not know about the Higgs, nor about anything else. All that is born will be born at random. And naturally, that which is born often, we have already observed. We are interested in what is born rarely.
How rare? If the collisions are read at a speed of 40 million collisions per second, then interesting processes, such as the production of the Higgs boson, occur approximately 1 to 10 times per hour. Thus, we should see these events that occur so rarely, against the background of noise from the point of view of data science, which has a frequency of about 10-11 orders of magnitude more.
As an association: what we are trying to do is to see a snowflake of a certain unprecedented shape in the light of a photo flash during a snowfall and against the background of a large snow-covered field. And to be honest, I think the snowflake task I described is much simpler.
Where do we get the data from? The primary source of data is the detector that surrounds the proton collision point. This is what is born out of a bunch of energy that results from a collision of protons.
The detector consists of subdetectors. You know, when sports competitions are filmed, many different cameras are used, which are filmed from different points, and as a result the event as such can be seen in all its diversity.
Detectors are similarly arranged. They consist of several sub-detectors, and each is configured to identify something special.

Here is a segment of the CMS detector, it has sub-detectors: a silicone tracker, the very silicone matrices that I talked about, then there is an electromagnetic calorimeter, that is, a fairly dense medium in which particles release energy. Electromagnetic particles - electron and photon - emit almost all the energy, and we are able to measure it. Next is the hadron calorimeter, which is more dense than the electronic calorimeter, and the particles are already stuck in it - again, hadrons, neutral and charged.
Then there are several layers of the muon system, which is designed to register muons - particles that interact quite a bit with matter. They are charged and simply leave behind ionization. In this picture I show how a muon flies through the detector. Born in the center, he crosses the detector, leaves practically nothing in the calorimeter, in the tracker it can be seen as a sequence of points, and in the muon system it is observed as a sequence of clusters.
The electron is a charged particle, therefore, passing through the tracker, it also leaves the tracks, but as I said, it gets stuck in the electromagnetic calorimeter and gives back almost all of its energy.
What is an electron? This is a sequence of hits in the tracker that lie on one curve. It, in turn, corresponds to a specific particle of a certain energy. It also corresponds to the energy in the electromagnetic calorimeter, which is consistent with the energy obtained from the tracker. Thus, the identification of an electron is literally obtained. If we see a similar correspondence of the signal in the tracker and in the electromagnetic calorimeter, then it is most likely an electron.
A charged hadron flies through an electromagnetic calorimeter with almost no interaction, it lands almost all of its energy in a hadron calorimeter. The idea is the same: we have a track, and there is a corresponding cluster of energies in the calorimeter. We compare them and we can say: OK, if the cluster is in an electromagnetic calorimeter, then it is most likely an electron. If the cluster is in a hadron calorimeter, then it is most likely a hadron.
Suppose a photon can form. It is a neutral particle, it does not bend in a magnetic field, it flies in a straight line. Moreover, it flushes the tracker through, leaving no such hits there, but leaves a cluster in the electromagnetic calorimeter. As a result, we see a detached cluster. Our conclusion: if we have a cluster that the track is looking at, it is an electron. If there is a cluster that no one is looking at, this is a photon. So trackers and work.
In this slide, I summarized how particle identification occurs. Indeed, different types of particles have different signatures.

However, from the detector itself we get just a report. In a silicone detector, for example, we simply read signals from pixels, etc. We have about a million illuminated cells in the detector, which are shot at 40 MHz. This is 40 terabytes of data per second.
At the moment, we cannot handle such a stream, although technically we are already approaching the possibilities. Therefore, the data is stored in local buffers on the detector. And during this time, using a small amount of information, we must determine: is this event completely uninteresting or potentially interesting, and should it be left to work? We need to decide this, suppress the total rate by three orders of magnitude. And so, as the red arrow on the right shows, we jump from the total rate somewhere below.
This is a typical classification task. Now we are actively using machine learning methods, Yandex is widely involved in this - then Tanya will tell you everything .
We lowered the rate by three orders of magnitude, now we can exhale, we have a little more time, we can produce better processing of events, we can restore some local objects. If these objects, which were restored in certain sub-detectors, are linked together, global pattern recognition is obtained. Thus, we suppress three more orders, again we select particles, possibly interesting ones, from completely uninteresting ones.
What we have selected here goes into memory and is stored in the data center. We are saving one event out of a million. The rest of the events are lost forever. So it is very important that this selection has good efficiency. If we have lost something, it will not be restored.
Then our event is recorded on tapes, we can work with them quietly, engage in reconstruction and analysis. And this way from the initial detectors to the final physical result is nothing more than a very aggressive multi-step reduction of the dimension of the problem. Removing from the detector about 10 million data, we first cluster them into neighboring objects, then reconstruct them into objects such as particle tracks, then select objects that are decay products, and ultimately we get the result.

For this we need powerful enough computer resources. High energy physics uses distributed computer resources. In this slide, to give an idea of the number, 120,000 cores and about 200 petabytes of capacity on the disks are used for the CMS collaboration.
The system is distributed, so data transfer is an important component. Technically, we use dedicated lines for this, practically our communication channels, which are used specifically for high-energy physics.

In this slide, I wanted to compare our data transfer tasks with industrial data transfer tasks. For example, compare with Netflix, the largest streaming media content provider in the United States. It is interesting in that it transmits approximately the same amount of data per year as the LHC. But the task of the LHC is much more complicated. We are transferring more data to fewer clients, so it's not easy for us to organize data replication. This is the approach Nettlix solves its problem with.

Here are the resources we use. About the computer, I spoke. It is important that all these resources are used by researchers, and experiments in high particle physics are always huge collaborations. So, about 10,000 people should be merged into our resources, who are happy to work synchronously. This requires appropriate technology, and the result of the use of these resources, the many years of work of tens of thousands of people, is a scientific result.

An example is the CMS article, which is characterized as the discovery of the Higgs boson. Vladimir explained about the statistics, errors and so on. You will never see a scientific article where the “discovery of something” is written, precisely because to make a discovery is to put an end. No, we are an experimental science, we observe something. The conclusion of this article is that we observe such and such a boson with such a mass in such and such limits with such a probability and, according to such parameters, its properties coincide with the properties of the Higgs boson.

. , 36 . — , 136 . , , . .

, , . . . , , , . , , , .

, 2012 . .

, . 2012 , . . , ? . . , — , — ? . , , , . , , . , .

, , 750 GeV, , , , , . .
, , , . , - , . .

. , , . . . . — computer science , . .
. , , , welcome. .
Under the cut - the decoding and the main part of the slide.
Why did I take the report with pleasure? I have been involved in experimental high-energy physics for almost my entire career. He worked on more than five different detectors, starting from the 90s of the last century, and this is an extremely interesting and exciting work - to explore, to be at the very forefront of the study of the universe.
')
Experiments in high-energy physics are always large, these experiments are quite expensive, and the next step in knowledge is not easy to do. In particular, therefore, behind each experiment, as a rule, there is a certain idea, what do we want to check? As you know, there is a relationship between theory and experiment, this is the cycle of understanding the world. We are seeing something, we are trying to streamline our understanding, to present some models. Good models have predictive power, we can predict something, and we again check it experimentally. And gradually, walking in a spiral, at each turn, we learn something new.
Experiments in which I worked - how did they make discoveries? What were the detectors built for? For example, a CDF detector on Tevatron ? Tevatron was built primarily to open the top quark. He was safely open. By the way, when analyzing the top quark data in my memory for the first time, multi valued analysis data was seriously used. In fact, even then, so long ago, the work was built by the method of machine learning.
Another experiment where I was lucky to work is CMS at LHC. The LHC physical program was aimed at three goals: Higgs, supersymmetry, and quark-gluon plasma. Higgs - this was the number one goal that was successfully completed by 2012.
When we recruit new data, we walk through unknown terrain, we discover unexpected things. Among these was the discovery of the mixing of B-mesons and anti-B-mesons in the last century, which somewhat changed our understanding of the standard model. It was completely unexpected.
In 2016, the Herbie experiment observed a pentaquark, states of this type were observed for a long time, but each time they were resolved. This time I have a feeling that the object that is observed will stand. A truly unique object, this is not a baryon, not a meson, but a new state of matter.
But we still talk about the data. In this slide, I tried to imagine the position of high energy physics data in the general hierarchy. In today's world, data rules the world, data is analyzed everywhere. I dragged this picture with Wired, but the statistics are given for 2012. What is the data flow typed in various services? Far ahead with the number 3000 RV, business correspondence is breaking ahead; we all write a lot of letters. In second place is Facebook, which we upload there, the seals, oddly enough, take second place in volume, ahead of serious tasks that, say, Google does. In fourth place is the archive of all medical records more or less known, which are used for the development of new methods in medicine. And the following are the data of the LHC, about 15 RV in the code. At the same level go and data from YouTube. That is, the data of one, albeit large, but one experiment of a particular field of physics has a capacity comparable to the largest data sources.
This means that since we are not the biggest, we can use the best practices of Google, Facebook, and other industrial services. However, our data has quite specific properties that require serious adaptation of the available methods. It is interesting to note that high-energy physics was the driver of computer technology from the 60s to the 80s, and then large computer mainframes, data storage systems, were made specifically for high-energy physics tasks.
After that, nuclear tests were banned, and simulation of nuclear explosions became the driver.
Why are we doing this all? Vladimir Igorevich roughly told . In this picture I tried to roughly describe the border of the famous. According to the currently prevailing theory, our universe arose as a result of the Big Bang, which occurred about 13 billion years ago. The universe arose from a bunch of energy that began to expand, particles formed there, they clustered into atoms, into molecules, into matter, and so on. This picture shows the timeline of what happened during the Big Bang.
What happens now, when particles known to us have formed - electrons, neutrons, protons? We more or less understand the physics of these processes. There is a certain border that I have depicted here and which corresponds approximately to the times of 10 -10 s, the energies attainable at the LHC now. This is practically the greatest energy achievable experimentally. This is a border beyond which we can not clearly say anything. What is on the right side at lower energies, we more or less understand and have verified experimentally. What is on the left side ... there are various theories and ideas about this, different scientists present it in different ways, and it is quite difficult to test it experimentally, directly.
The bottom line is that today, when we explore physics at high energies at the collider, we look into the very early history of the Universe. And this story is 10 -10 . This is very little, this is the time for which the light passes 3 cm.
Here are some examples of global physical questions to which we have no answers. There are quite a few of these questions. And if you think about it, there are very dark spots. Dark matter and energy. That matter and energy that we observe is approximately 5% of what we measure through various gravitational observations. This is about the same as you have a flat of 20 square meters, and you receive a heating bill of 1000 meters, and everything is correct, somewhere else the square meters are heated, but you do not understand where they are. Similarly, we do not understand in which particles the dark matter is.
We are researching new properties of matter. In particular, at colliders we produce directly new particles unknown to us. How do we do it? Literally knocked out of nothing. Everyone knows Einstein's formula E = mc 2 , but it also has the opposite meaning: if we concentrate energy in one small area, a new matter can form, an electron pair with a positron or something else. If we concentrate a lot of energy, quite complex particles can be born, which instantly break up into ordinary particles known to us. Therefore, we cannot observe literally new unusual particles. However, we can register their decay products and extract information about what was born from there.
This is the paradigm we are following in experimental high-energy physics. And for this purpose, on the one hand, a high particle accelerator is needed in order to concentrate energy at a certain point, to create these particles. On the other hand, we must surround this point with a kind of detector in order to fix, take a picture of the decay products of the particles.
Photography is a very good association, because now in the detectors most of the information comes from silicon detectors, which are nothing more than a matrix in digital cameras. At CERN at BAC we have four large digital cameras. Four experiments: two general, ATLAS and CMS, and two specialized, HERA-B and Alice.
What are these cameras? The height of the ATLAS detector is 25 meters. I tried to present it in real scale. Weight - 150 thousand tons.
You roughly represent the size of the matrix of the camera. There are about 200 square meters of matrix.
In fact, there are many layers of the matrix in order to register the particles that pass between them.
The coolest thing for these experiments is their speed. They shoot at a speed of 40 million frames per second. 40 million times a second, protons in the collider collide with protons. In each of these collisions, something new is possible. It is rare, but nevertheless, in order not to miss, we must read every collision.
We cannot record as much, we actually record about 200-500 frames per second, but this is also not bad.
In addition, detectors with this speed click for many years with a break for the winter holidays.
In this slide, I reproduce what Vladimir Igorevich explained remarkably. On the right picture that he showed. How often do we have various physical processes as a result of a collision? As a result of proton collisions, only a cluster of energy arises, and anything can be generated from this energy, which is energetically permissible. Usually something ordinary is born: pi-mesons, protons, electrons.
They asked me why you give birth to what you do not need? Why don't you make collisions so that the Higgs boson is born and not tormented by the need to read 40 million events per second? I would say that it is impossible now because of first principles, precisely because of the collision we have, and the only characteristic is energy. The cluster does not know about the Higgs, nor about anything else. All that is born will be born at random. And naturally, that which is born often, we have already observed. We are interested in what is born rarely.
How rare? If the collisions are read at a speed of 40 million collisions per second, then interesting processes, such as the production of the Higgs boson, occur approximately 1 to 10 times per hour. Thus, we should see these events that occur so rarely, against the background of noise from the point of view of data science, which has a frequency of about 10-11 orders of magnitude more.
As an association: what we are trying to do is to see a snowflake of a certain unprecedented shape in the light of a photo flash during a snowfall and against the background of a large snow-covered field. And to be honest, I think the snowflake task I described is much simpler.
Where do we get the data from? The primary source of data is the detector that surrounds the proton collision point. This is what is born out of a bunch of energy that results from a collision of protons.
The detector consists of subdetectors. You know, when sports competitions are filmed, many different cameras are used, which are filmed from different points, and as a result the event as such can be seen in all its diversity.
Detectors are similarly arranged. They consist of several sub-detectors, and each is configured to identify something special.
Here is a segment of the CMS detector, it has sub-detectors: a silicone tracker, the very silicone matrices that I talked about, then there is an electromagnetic calorimeter, that is, a fairly dense medium in which particles release energy. Electromagnetic particles - electron and photon - emit almost all the energy, and we are able to measure it. Next is the hadron calorimeter, which is more dense than the electronic calorimeter, and the particles are already stuck in it - again, hadrons, neutral and charged.
Then there are several layers of the muon system, which is designed to register muons - particles that interact quite a bit with matter. They are charged and simply leave behind ionization. In this picture I show how a muon flies through the detector. Born in the center, he crosses the detector, leaves practically nothing in the calorimeter, in the tracker it can be seen as a sequence of points, and in the muon system it is observed as a sequence of clusters.
The electron is a charged particle, therefore, passing through the tracker, it also leaves the tracks, but as I said, it gets stuck in the electromagnetic calorimeter and gives back almost all of its energy.
What is an electron? This is a sequence of hits in the tracker that lie on one curve. It, in turn, corresponds to a specific particle of a certain energy. It also corresponds to the energy in the electromagnetic calorimeter, which is consistent with the energy obtained from the tracker. Thus, the identification of an electron is literally obtained. If we see a similar correspondence of the signal in the tracker and in the electromagnetic calorimeter, then it is most likely an electron.
A charged hadron flies through an electromagnetic calorimeter with almost no interaction, it lands almost all of its energy in a hadron calorimeter. The idea is the same: we have a track, and there is a corresponding cluster of energies in the calorimeter. We compare them and we can say: OK, if the cluster is in an electromagnetic calorimeter, then it is most likely an electron. If the cluster is in a hadron calorimeter, then it is most likely a hadron.
Suppose a photon can form. It is a neutral particle, it does not bend in a magnetic field, it flies in a straight line. Moreover, it flushes the tracker through, leaving no such hits there, but leaves a cluster in the electromagnetic calorimeter. As a result, we see a detached cluster. Our conclusion: if we have a cluster that the track is looking at, it is an electron. If there is a cluster that no one is looking at, this is a photon. So trackers and work.
In this slide, I summarized how particle identification occurs. Indeed, different types of particles have different signatures.
However, from the detector itself we get just a report. In a silicone detector, for example, we simply read signals from pixels, etc. We have about a million illuminated cells in the detector, which are shot at 40 MHz. This is 40 terabytes of data per second.
At the moment, we cannot handle such a stream, although technically we are already approaching the possibilities. Therefore, the data is stored in local buffers on the detector. And during this time, using a small amount of information, we must determine: is this event completely uninteresting or potentially interesting, and should it be left to work? We need to decide this, suppress the total rate by three orders of magnitude. And so, as the red arrow on the right shows, we jump from the total rate somewhere below.
This is a typical classification task. Now we are actively using machine learning methods, Yandex is widely involved in this - then Tanya will tell you everything .
We lowered the rate by three orders of magnitude, now we can exhale, we have a little more time, we can produce better processing of events, we can restore some local objects. If these objects, which were restored in certain sub-detectors, are linked together, global pattern recognition is obtained. Thus, we suppress three more orders, again we select particles, possibly interesting ones, from completely uninteresting ones.
What we have selected here goes into memory and is stored in the data center. We are saving one event out of a million. The rest of the events are lost forever. So it is very important that this selection has good efficiency. If we have lost something, it will not be restored.
Then our event is recorded on tapes, we can work with them quietly, engage in reconstruction and analysis. And this way from the initial detectors to the final physical result is nothing more than a very aggressive multi-step reduction of the dimension of the problem. Removing from the detector about 10 million data, we first cluster them into neighboring objects, then reconstruct them into objects such as particle tracks, then select objects that are decay products, and ultimately we get the result.
For this we need powerful enough computer resources. High energy physics uses distributed computer resources. In this slide, to give an idea of the number, 120,000 cores and about 200 petabytes of capacity on the disks are used for the CMS collaboration.
The system is distributed, so data transfer is an important component. Technically, we use dedicated lines for this, practically our communication channels, which are used specifically for high-energy physics.
In this slide, I wanted to compare our data transfer tasks with industrial data transfer tasks. For example, compare with Netflix, the largest streaming media content provider in the United States. It is interesting in that it transmits approximately the same amount of data per year as the LHC. But the task of the LHC is much more complicated. We are transferring more data to fewer clients, so it's not easy for us to organize data replication. This is the approach Nettlix solves its problem with.
Here are the resources we use. About the computer, I spoke. It is important that all these resources are used by researchers, and experiments in high particle physics are always huge collaborations. So, about 10,000 people should be merged into our resources, who are happy to work synchronously. This requires appropriate technology, and the result of the use of these resources, the many years of work of tens of thousands of people, is a scientific result.
An example is the CMS article, which is characterized as the discovery of the Higgs boson. Vladimir explained about the statistics, errors and so on. You will never see a scientific article where the “discovery of something” is written, precisely because to make a discovery is to put an end. No, we are an experimental science, we observe something. The conclusion of this article is that we observe such and such a boson with such a mass in such and such limits with such a probability and, according to such parameters, its properties coincide with the properties of the Higgs boson.
. , 36 . — , 136 . , , . .
, , . . . , , , . , , , .
, 2012 . .
, . 2012 , . . , ? . . , — , — ? . , , , . , , . , .
, , 750 GeV, , , , , . .
, , , . , - , . .
. , , . . . . — computer science , . .
. , , , welcome. .
Source: https://habr.com/ru/post/329132/
All Articles