Machine Learning for an Insurance Company: Realistic Ideas
Friday is a great day to start something, for example, a new cycle of articles on machine learning. In the first part, the WaveAccess team tells you why you need machine learning at an insurance company and how they tested the realism of the idea of predicting peak costs.

Today, machine learning is effectively used to automate tasks that require a large amount of routine manual labor and are hard to program in the traditional way. For example, these are tasks with a large number of influencing variables: identification of spam letters, searching for information in the text, and so on. In such situations, the use of machine learning becomes especially popular.
A large number of successful projects with the use of machine learning has been implemented in the USA, and these are mainly solutions from the field of intelligent applications. The companies that developed them have changed the market and the rules of the game in their industry. For example, Amazon introduced a referral shopping system on its website - and this predetermined today's look of online stores. Google, through machine learning algorithms, has developed a targeted advertising system that offers the user customized products based on information known about him. Netflix, Pandora (Internet radio), Uber became key figures in their markets and set a further development vector for them, and the decisions were based on machine learning.
')
An important financial indicator for an insurance company is the difference between the cost of insurance sold and the cost of compensation for insured events.
Because cost reduction is critical to this business, companies use a large number of proven methods, but are always looking for new opportunities.
For a health insurance company (our client), predicting the cost of treating insured persons is a good way to cut costs. If it is known that in the next month or two a sufficiently large amount will be required for client treatment, you should take a closer look at it more closely: for example, transfer it to more qualified curators, offer to undergo diagnostic examinations in advance, monitor the implementation of the doctors' recommendations, and so on. reduce in some cases the cost of future treatment.
But how to predict the cost of treatment for each client, when there are more than a million?
One option may be an individual analysis of information known about the patient. So you can predict, for example, a sharp increase (if we consider the relative values) or just the peak (absolute values) of costs. The data in this problem contains a lot of noise, so you cannot count on a result close to 100% of correct predictions. However, since we are talking about statistics unbalanced by class, even 50% of the predicted peaks at 80-90% of the predicted no increase in costs can provide important information for the company. Such a task can be effectively solved only by means of machine learning. Of course, you can manually pick up a set of rules based on already existing data, which will be very rough and inefficient in the long term compared to machine learning algorithms, since it is almost impossible to manually select the optimal boundary values and coefficients.
In such projects, the implementation of a software package in the form of a web service is often relevant. To implement machine learning, the client considered 2 of the most well-known solutions in this area: MS Azure ML and Amazon ML.
Since Amazon ML only supports 1 algorithm — linear regression (and its adaptation for classification tasks is logistic). This limits the possibilities of implementable solutions.
Microsoft Azure ML is a more flexible service:
As for the decision of the tasks set on the project the difficult composition of algorithms was required, selected Azure. However, since it is impossible to talk about the benefits of an integrated approach to solving machine learning problems, in this article we will limit ourselves to simple algorithms, and we will consider more complex variations in the following articles.
Let us verify the realism of the idea of predicting peak costs. As initial data, to obtain the baseline, we take the raw data: the patient's age, the number of doctor's visits, the amount of money spent on the client for the last several months. The border for the peak of costs for the next month will be $ 1,000. We will upload data to Azure and divide them into a training and test sample in the ratio of 4 to 1 (we will not conduct validation at this stage, so the sample is not provided for it in this situation).
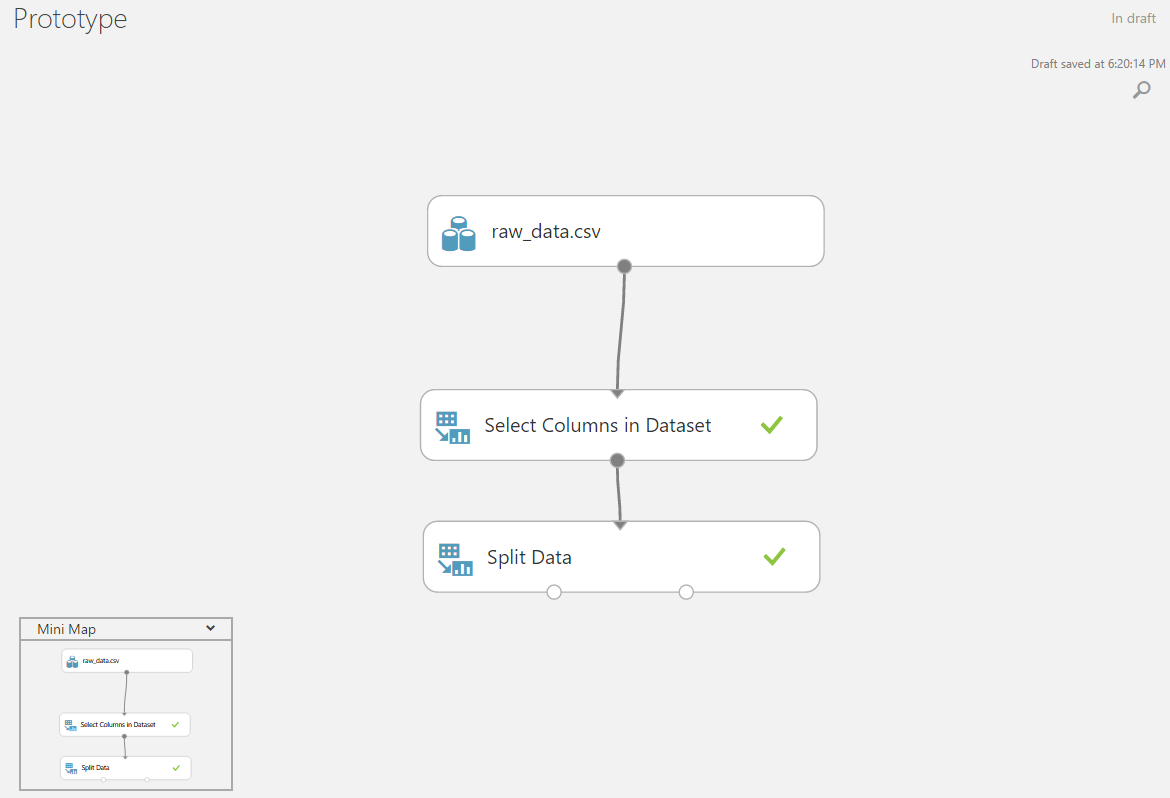
If there are more columns in the loaded data than needed, or vice versa, some data is from another source - they can be easily merged or removed from the input data matrix.
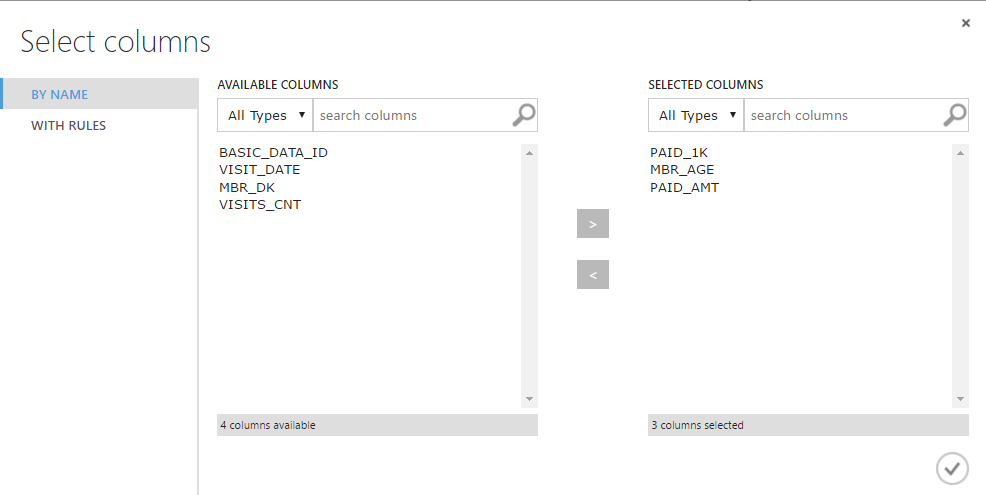
Choose (for training) the simplest version of the algorithm - logistic regression. This conservative method is often used first to get a point for further comparison; in certain tasks, it may be the most appropriate and show the best result.
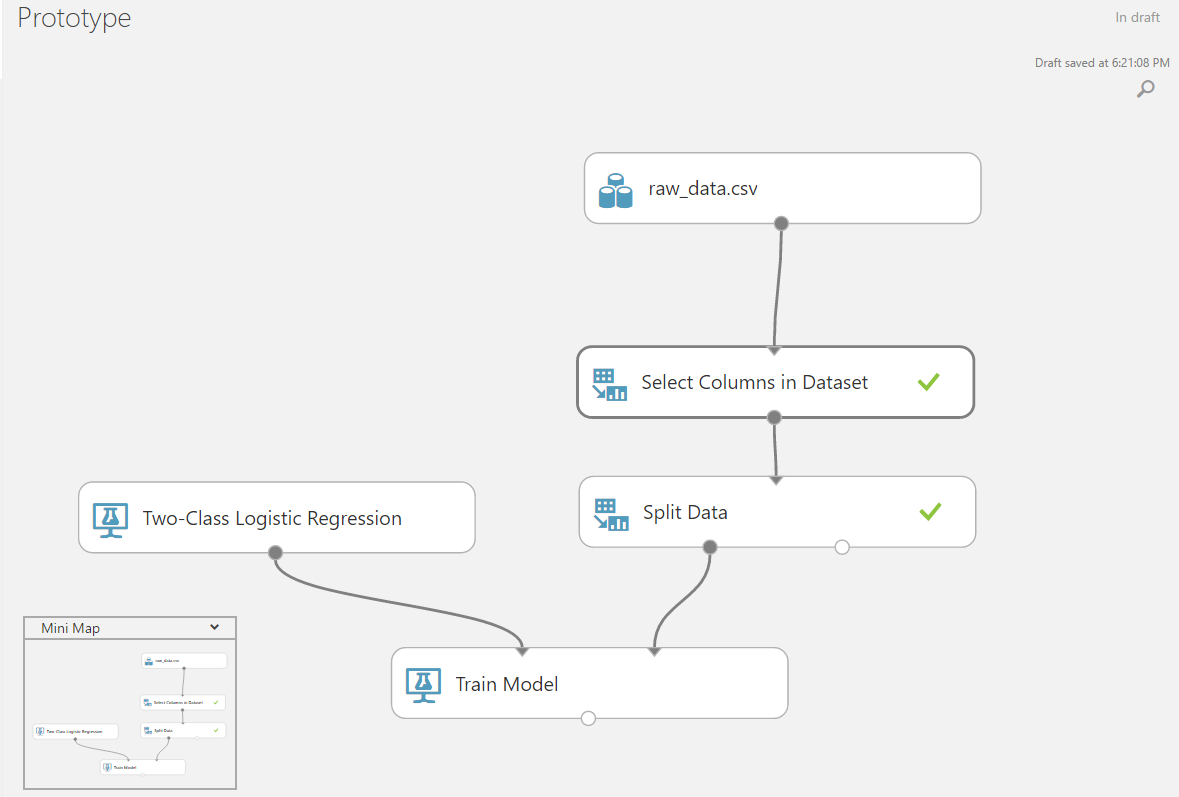
Add the learning and testing blocks of the algorithm and associate the source data with them.

For convenience of checking the results, you can add a block for evaluating the results of the algorithm, where you can experiment with the boundary between the classes.
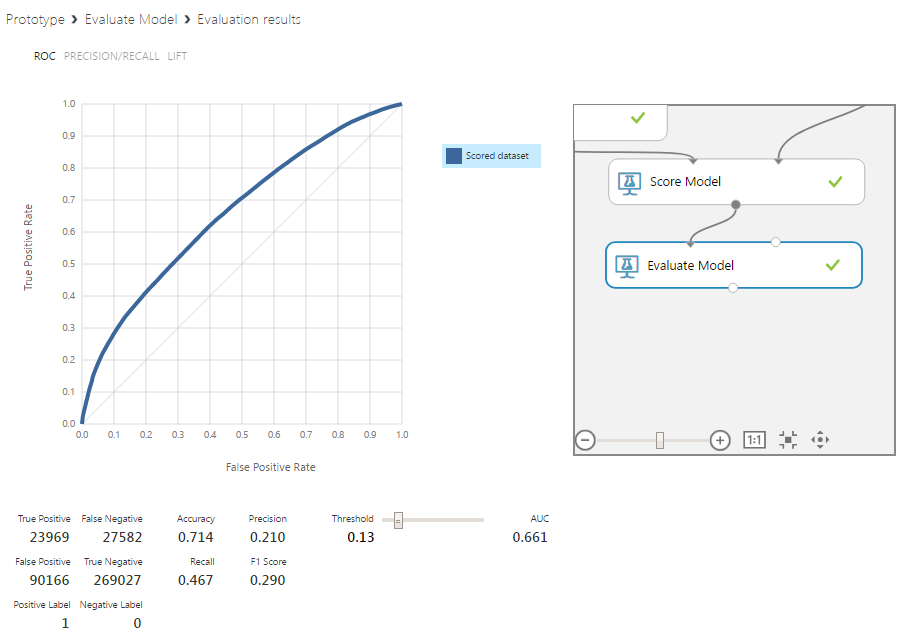
In our experiment, the base algorithm on the raw data at the boundary of the separation of classes, set to 0.13, predicted about 45% of the peaks and 75% of their absence. This indicates that the concept should be developed on more complex schemes, which will be done in the future.
In the following articles we will look at the analysis of data, the work of other algorithms and their combinations, the fight against retraining and incorrect data.
The WaveAccess team creates technically complex, high-load and fault-tolerant software for companies from different countries. Commentary by Alexander Azarov, Head of Machine Learning at WaveAccess:
The series of articles "Machine learning for an insurance company"
Introduction
Today, machine learning is effectively used to automate tasks that require a large amount of routine manual labor and are hard to program in the traditional way. For example, these are tasks with a large number of influencing variables: identification of spam letters, searching for information in the text, and so on. In such situations, the use of machine learning becomes especially popular.
A large number of successful projects with the use of machine learning has been implemented in the USA, and these are mainly solutions from the field of intelligent applications. The companies that developed them have changed the market and the rules of the game in their industry. For example, Amazon introduced a referral shopping system on its website - and this predetermined today's look of online stores. Google, through machine learning algorithms, has developed a targeted advertising system that offers the user customized products based on information known about him. Netflix, Pandora (Internet radio), Uber became key figures in their markets and set a further development vector for them, and the decisions were based on machine learning.
')
Why does an insurance company need machine learning?
An important financial indicator for an insurance company is the difference between the cost of insurance sold and the cost of compensation for insured events.
Because cost reduction is critical to this business, companies use a large number of proven methods, but are always looking for new opportunities.
For a health insurance company (our client), predicting the cost of treating insured persons is a good way to cut costs. If it is known that in the next month or two a sufficiently large amount will be required for client treatment, you should take a closer look at it more closely: for example, transfer it to more qualified curators, offer to undergo diagnostic examinations in advance, monitor the implementation of the doctors' recommendations, and so on. reduce in some cases the cost of future treatment.
But how to predict the cost of treatment for each client, when there are more than a million?
One option may be an individual analysis of information known about the patient. So you can predict, for example, a sharp increase (if we consider the relative values) or just the peak (absolute values) of costs. The data in this problem contains a lot of noise, so you cannot count on a result close to 100% of correct predictions. However, since we are talking about statistics unbalanced by class, even 50% of the predicted peaks at 80-90% of the predicted no increase in costs can provide important information for the company. Such a task can be effectively solved only by means of machine learning. Of course, you can manually pick up a set of rules based on already existing data, which will be very rough and inefficient in the long term compared to machine learning algorithms, since it is almost impossible to manually select the optimal boundary values and coefficients.
Machine learning implementation
In such projects, the implementation of a software package in the form of a web service is often relevant. To implement machine learning, the client considered 2 of the most well-known solutions in this area: MS Azure ML and Amazon ML.
Since Amazon ML only supports 1 algorithm — linear regression (and its adaptation for classification tasks is logistic). This limits the possibilities of implementable solutions.
Microsoft Azure ML is a more flexible service:
- a large number of built-in algorithms + support for embedding your code in R and Python;
- embedded tools have everything you need for basic work in the areas of classification, clustering, regression, computer vision, working with text, etc .;
- there is a functional for preprocessing, manipulation and organization of data;
- the modules in Azure ML are organized as flowcharts, which makes the entry threshold low, and the work is intuitive — therefore Azure ML has become a convenient prototyping tool that allows you to quickly implement basic solutions to test the viability of hypotheses, ideas and projects.
As for the decision of the tasks set on the project the difficult composition of algorithms was required, selected Azure. However, since it is impossible to talk about the benefits of an integrated approach to solving machine learning problems, in this article we will limit ourselves to simple algorithms, and we will consider more complex variations in the following articles.
Prototyping
Let us verify the realism of the idea of predicting peak costs. As initial data, to obtain the baseline, we take the raw data: the patient's age, the number of doctor's visits, the amount of money spent on the client for the last several months. The border for the peak of costs for the next month will be $ 1,000. We will upload data to Azure and divide them into a training and test sample in the ratio of 4 to 1 (we will not conduct validation at this stage, so the sample is not provided for it in this situation).
If there are more columns in the loaded data than needed, or vice versa, some data is from another source - they can be easily merged or removed from the input data matrix.
Choose (for training) the simplest version of the algorithm - logistic regression. This conservative method is often used first to get a point for further comparison; in certain tasks, it may be the most appropriate and show the best result.
Add the learning and testing blocks of the algorithm and associate the source data with them.
For convenience of checking the results, you can add a block for evaluating the results of the algorithm, where you can experiment with the boundary between the classes.
In our experiment, the base algorithm on the raw data at the boundary of the separation of classes, set to 0.13, predicted about 45% of the peaks and 75% of their absence. This indicates that the concept should be developed on more complex schemes, which will be done in the future.
In the following articles we will look at the analysis of data, the work of other algorithms and their combinations, the fight against retraining and incorrect data.
About the authors
The WaveAccess team creates technically complex, high-load and fault-tolerant software for companies from different countries. Commentary by Alexander Azarov, Head of Machine Learning at WaveAccess:
Machine learning allows you to automate areas where expert opinions currently dominate. This makes it possible to reduce the influence of the human factor and increase the scalability of the business.
Source: https://habr.com/ru/post/329082/
All Articles