How and why to create a NginX module - theory, practice, profit

Vasily Soshnikov ( Mail.Ru )
Today I will tell you about how to create nginx-modules and, most importantly, try to answer why it should be done. This is not always necessary, but there is a certain range of tasks that can be solved on the side of nginx.

Here is a brief our plan. First, I will introduce the course of the matter, talk about the architecture of nginx. Second, I will try to immediately answer some frequently asked questions, because very often people working at Mail.ru come to me and ask the same questions, and I decided to just bring them out in a small FAQ. Right away, so that there is a better understanding of what will happen next.
')
The most interesting part is anatomy. I will talk about how to create nginx-modules, what types there are, talk a little about the pitfalls, but without all the subtleties, because, you know, nginx is a very complex technology, there are 1000 nuances, 1000 subtleties. And I will try to answer the questions: “Why create them ?,“ Why do we create them in Mail.ru? ”And“ Why did I create them, working not in Mail.ru? ”.
Also last night I decided to write examples, literally templates of nginx-modules, which you can just take and use. At the end I will give a reference. Because my comrades told me that without this my presentation is incomplete.
Let's start with the “Introduction” part and frequently asked questions.
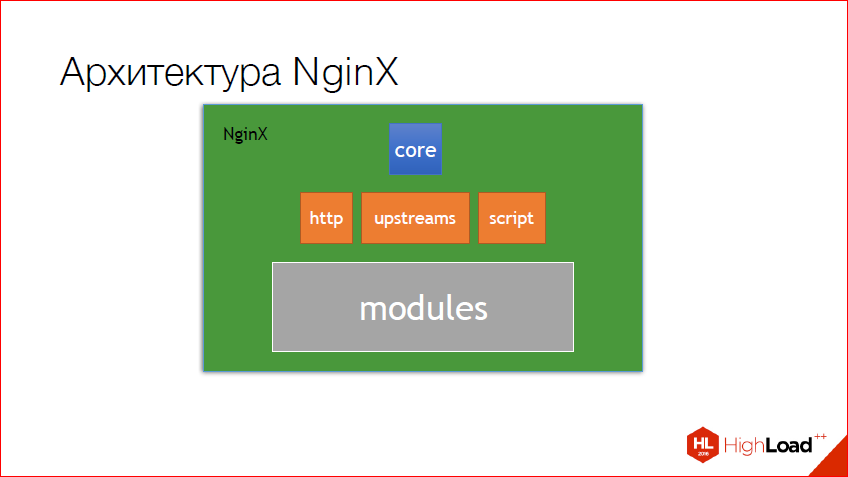
The first is the nginx architecture. I always associate it with a matryoshka. In fact, the way it is. There is a certain core in which there is all basic API from which it is possible to blind everything that you want. In this case, http was cast, upstreams was made from http, and also a scripting engine. And the mail engine, which works with the mail, is also based on the core. Modules that are already written for http are made on the http core. Those. You understand, this is such a matryoshka, there is a base - this is a core, there are layers below and below. And moreover, the lower the layer, the, as a rule, more than any modules. You understand that for http there are a lot of modules, and all of them are based just on the http core, and of the features of nginx.

And one of the most frequently asked questions is about the nginx memory model. Nginx uses pool. It must always be remembered. And we must take the correct pool. Many people make a frequent mistake and try to nail their buffers to the connection, and a keep-alive connection can live for a very long time. You understand that such buffers will accumulate as long as the connection is alive, and nginx can simply leak. Therefore, you should always choose the correct pool. If we want to just save some buffer for the lifetime of the request, it is more logical to nail it to the request, rather than to the connection.
You also need to remember that these pools are periodically cleaned and they have their own life-times. In principle, they are all quite logical, connection lives within a connection, request - within a request, the config is always alive and periodically held. There are also many other contexts, but a little further about them.
Also try to use nginx locators inside nginx. A reference to the API is at the top. Why is it necessary to use them? a) they are faster; b) they are easier to debug if you use Valgrind for nginx. True, in life I did not debug nginx buffers. It was not necessary, because the pool, if everything is done correctly and everything is calculated, it works fine.
But there is such a situation, for example, I recently had when I had to use standard malloc, alloc, reallock. Why? Because in nginx there is no reallock. This is a big problem. If you have some kind of library that uses reallock, then you just can’t replace these allocation functions in the library. Here, a good example is Yajil. Basically, I figured out how to do this, if someone is familiar with Pascal strings, you can simply allocate 4 more nails and nail them into this piece of memory. And use for reallocation the usual nginx'ovskiy allock.
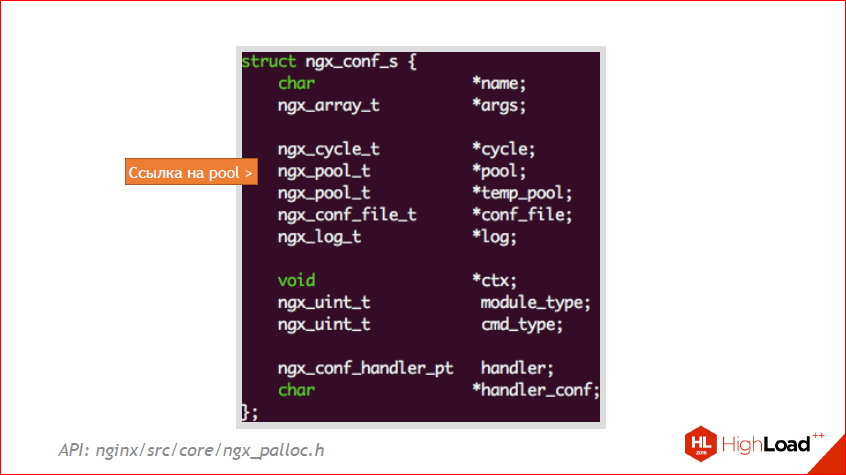
And this example is nginx_conf_s. This is its internal structure. Here you can see just this link on the pool. In this case, if you allocate something within the framework of the config, you will have to live as long as the config is alive. And in nginx, the config always lives until you clean it with handles. But there are different configs there, about this, too, a little further. So you have to remember, you should always look at the structure you want to nail, and approximately understand where it lives. And after some time you will have it all on the machine, but first you need to follow it very clearly.

And now very briefly about what is in nginx, and how its structure in the repository is arranged. At the top of the API, and below - what is there. The first is that in nginx there are a lot of data structures, and try to use them, because: a) they already know about nginx pools; b) this is the most native way to use it with nginx data types, because in nginx almost all data types are either typedef of system types or their own structures.
Also in the nginx core you can find the OS with the API, naturally wrapped in the facade. This can be useful if you are no longer writing your own http-module on nginx, but, let's say, some kind of your own TCP-module, this is also possible. Because http is made on the basis of core and it can be expanded, if desired, somehow. Also there you can find a state-machine, which is responsible for file-file descriptor, and many other useful functions, like logging, working with scripts and configs.

And now the most interesting and most painful, or rather, the most unknown. This is how nginx modules are organized, what types they are. Since I am limited in time, I decided to tell only about the three main ones. And then about the most, probably interesting - it's about upstream. In short, because it is really a topic for a separate report.

Therefore, today we will consider only 3 main modules - these are Handlers, Filters and Proxies. Proxies in short. In fact, there are many other types of modules, as I said, because http, in fact, is also a module, based on the core. But we will not go into such nuances, because it is very long and, again, this is a topic for a separate report.

Everything in nginx is subject to one pattern. This is the Chain of responsibility pattern. In other words, your request from the user goes through the http module, the http module starts some sequence - the chain of modules. And if they all worked well, the user will receive a good answer, if not, then an error will result. The closest analogy is this line of code:

I thought it would be a perfect analogy, I hope, I am right. Everyone understands this line? This is essentially a bash. We get something, we take the first line along the delimeter; doing a variety and counting words. The principle of operation of the nginx-module is very similar to this. Those. If the pipe breaks, the whole chain will fly away from you, and you will get an error in the bash. Also there are signals, etc. Nginx has all the same, so all nginx modules should be treated that way.
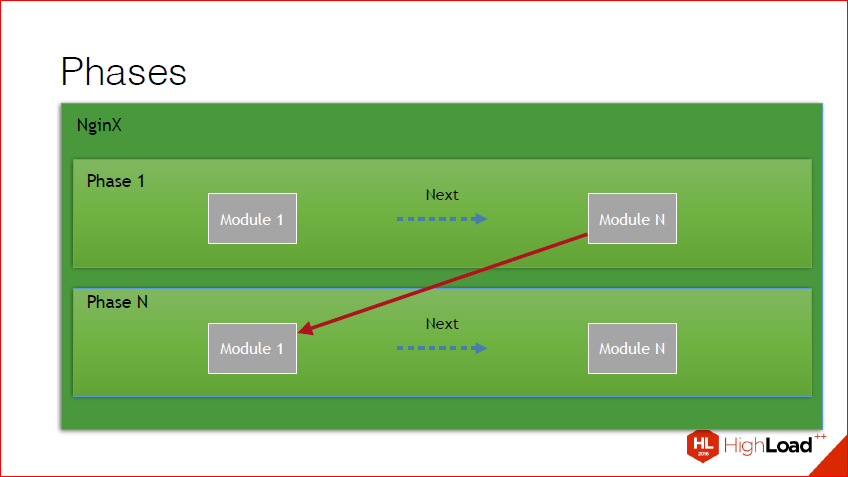
Also, if you dig a little deeper, you can find that in addition to the fact that this chain, this chain is broken into phases. In nginx there are a lot of phases, each phase is called at a certain point in time under certain conditions, all handlers within the phase are traversed, after which the switching takes place with the result of the execution of that phase into another phase. In principle, this drawing illustrates this. We have a certain set of modules in phase, we go through, we get the result, we go to the next phase.
And here are the phases that are now available in nginx_http:
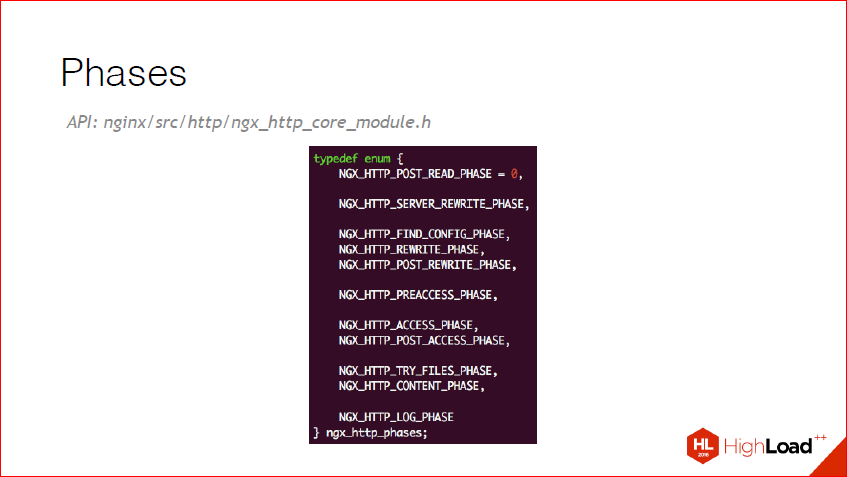
They are self-speaking, I think, there are no questions here. Those. server_rewrite, search config, rewrite normal, content_phase.

And now we proceed directly to how modules are developed. It is to those things that must be done for each module.

First, any module in nginx starts with a config. In nginx there is a certain way of naming such structures for your module and for any other modules and even for internal nginx. It is to use such a naming convention, i.e. ngx_http shows that we are doing something for http now. Next is the name of your module - it could be anything. And accordingly, one of the types of config - main, server, loc - and _conf.
By the way, we posted in open access the video of the last five years of the conference of developers of high-loaded systems HighLoad ++ . Watch, learn, share and subscribe to the YouTube channel .
Everyone remembers nginx_config? This one is from there. There is main - this is the most global scoop, there is a server, a beta server, and there is a location. Location if - also consider the location, only specific. In fact, these configs and these structures may be merged at different stages, i.e. nothing prevents you from making this structure so that it is present both in main, in the server, in the location and in the location if, nothing. All that is needed is to write one function and set a bit-mask defined. More on this later.
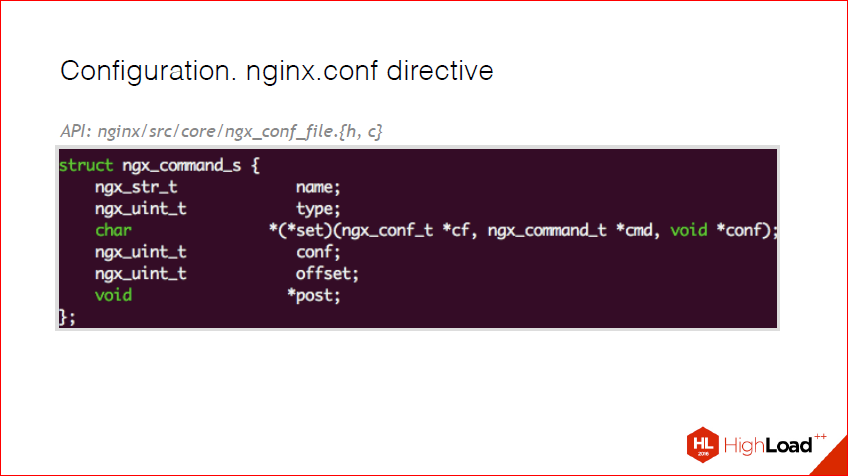
Directives. There are directives in the nginx config. And, accordingly, when you develop your module, you should understand that you must give some kind of pen to administrators and users. In nginx, there is a special structure for this - ngx_command_s. I put all the references on the API here, so you can then just see, there is nothing complicated there. And here, in essence, all that is present is the name. The name is how your directive is presented in nginx config. This is the type, and it is the mask that this directive is. Those. it is present in the location, in the main conf, server conf. Callback exists to parse the value of this variable. There is a large set of ready-made callbacks. For example, if we use ngx_string, and we just need to save a line, then we should not implement this callback, but take already ready from nginx. And then a few system fields, I will tell about them on the next slide.
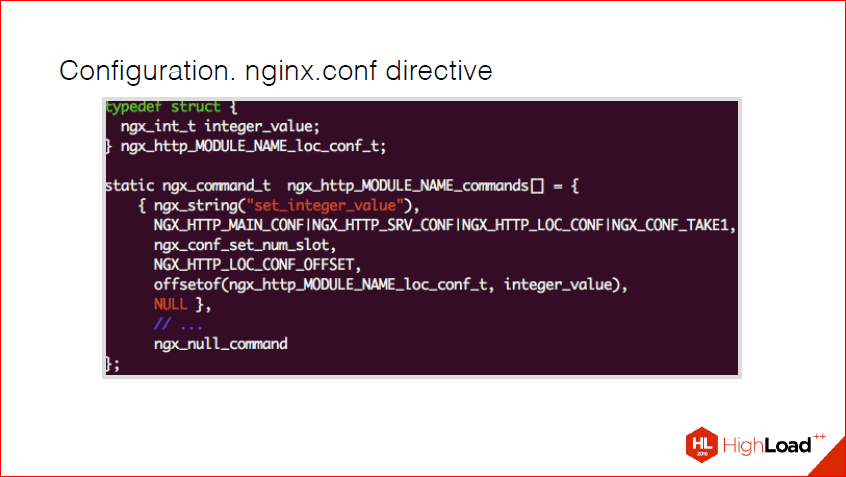
Suppose we create a module called MODULE_NAME. Here, we have a certain variable, a regular integer, and we want to transfer this integer to the config. All we need is to declare such a structure in this array. If we had many different variables, we would have many elements of this array. And so, as I said, this mask, here in this case, this bitmap says that one argument is taken. Here that this directive may be present in the location of the kofig, server config, and in the main config. If I still wanted to have a location if, I would have to add another piece of this mask.
Accordingly, it is a nginx-function, it exists for parsing the usual ones. This is specifically to save time so that this function is not performed every time. offsetof simply indicates where this field is located in our structure, this is the good old C-shny hack. I will not focus on it, because, in fact, in this context it should be taken as given. Those. he does not carry a semantic load.
And this array ends with the usual ngx_null_command - a marker indicating that the array has ended. Because in nginx almost everything that you declare inside your module is static, and it is externalized somewhere, because now there are two ways in nginx how to develop modules — this is either compiled with nginx or the load module, but more on that later. In this case, it must be remembered that for the time being everything will be static, and that a final marker is needed, because it goes through this array to the end, to this marker.
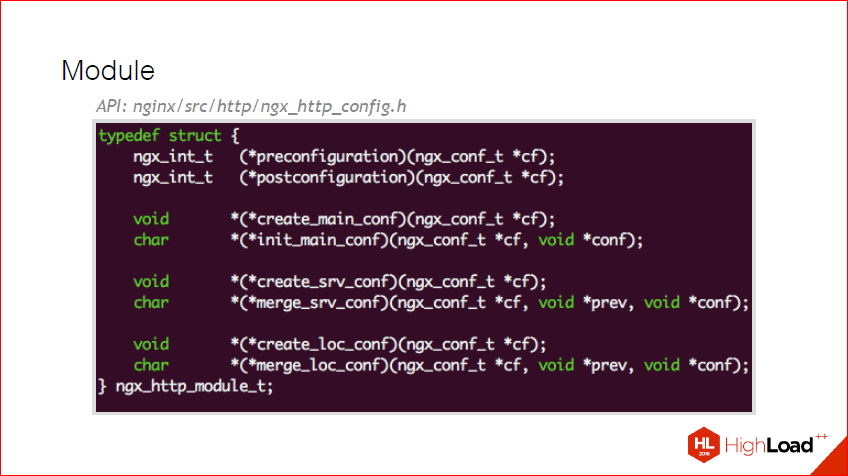
Here, we created some directives, it all works well for us, but now we need to do install inside nginx, create a config and its merge. For this there is such a structure as ngx_http_module_t. It is also quite simple, there are several stages of installation, this is preconfiguration, this is before any postconfiguration configuration occurs, as well as several other functions, which are described in more detail in the next slide.

We, for example, want that what we announced earlier, our directive should be correct at the location. All that needs to be done for this is to hammer into our two callbacks that we ourselves declared inside our module, and using ngx_palloc to preallocate our config. And make it merge. In nginx, if this is a primitive type that nginx understands, there is already a large set of functions to merge any variables. If this is your own some type, say, you have some very tricky line that needs to be parsed, say xml, and you want to write it in a separate structure, then you will need to describe the function and merge, and the set of such a variable and pass it to the callback. And at the stage of merge config in this function, you can do some additional checks and say that such an error has occurred. Here you can also log in and do something else.

Everything, we have a merjitsya config, we received directives. Now the most interesting thing is how to tell nginx that our module has appeared? For this, there is ngx_module_t - this is a special type. And, again, it is declared a static inside our object builder, i.e. ordinary variable. You describe, transfer the context, these commands that we have formed, and additional callbacks are also possible for more flexible control. Those. suppose if we want some specific action on the init master, on the way out of our master, etc. Here, in principle, I think everything is also clear, there are no questions. Just extra knobs for control. For example, why is this needed? Let's think about it, if our module used shared memory, we would definitely want to unlock it when exiting and killing a thread. For this and there are these pens - for additional action.
Proceeding from this point, I think everyone understood, or they already know how to create nginx modules. All that needs to be done is, in essence, to describe several static variables and declare several callbacks and that's it. And our module will pick up. But, that's not all, now the most important nuance is how to add a handler to the phases and how to make filters. Just in order for us to call our functions on some events inside nginx.

And now we will talk about it. About handlers and filters. These are two different entities.
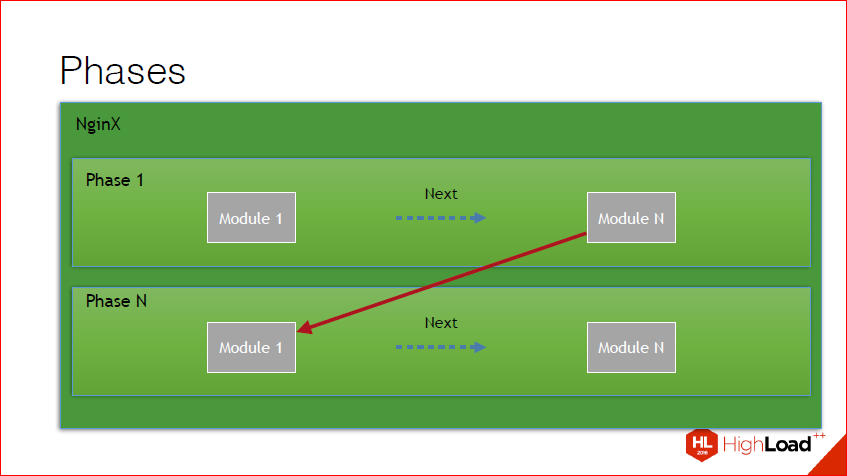
I'll get back to the phases just in case. Phases cause a certain point in time, cause a certain chain, end the chain and go to the next phase, and so on until all the phases have passed, or the phase is not interrupted. And just handlers work with phases. Those. What is a handler? You can bind any function to any of these phases. And now I will show you how this is done.

As you remember, with us when declaring a module we could transfer additional pens. Suppose here at postconfiguration, i.e. when we have already completed the directives, we received variables, filled them, we must do if we want to add some phase, add a function during initialization and, accordingly, describe the following in this function - what we get, as you can see, the content of the phases from nginx core config, because it's all in the http core lives. And just add your function there with the usual array_push. And everything, at us this function will be caused on content.
In other words, what is content phase? When someone returns an answer, we have content phases jerking, and we can do anything there, say, we can count the number of words in the response from the server or additionally compress it with some kind of our own algorithm. And every time when someone returns the answer, be it a file, be it something else, this function will be called. In it, we can already work with the http-request, pull out the data we need, add something there, or, conversely, delete it. And so we can do with each phase. The main thing to remember is that all phases are called at different times. In other words, if you need to work with content, you do not need to add your handler to the log phase. Because the log phase occurs when you need to write something, roughly speaking. There you can, on the contrary, collect some additional statistics, if you are interested in this phase. And in this phase you need to process content.
By the way, I remembered a good example. The last time I did the content phase, I had to generate a picture on the fly for the counter at top.mail.ru. Here is a good example. Those. I just did nothing, I just generated this new image depending on the query parameters, depending on the counter id, etc.

Filters. This is a slightly different entity. What are filters? Remember our chain? Filters are, in fact, a simple, simply-connected list of some filters.

And all you need to do to add your own handler to a specific filter is to simply take the nginx static variable called top_header_filter, add your handler there and that’s it. In this case, this is our header_filter, and your handler will be called each time at some time during the processing of the headers.
Good practical example. We need to set our cookies for the counter and check. All you need to do is add a new header filter and check out the headers that come in and somehow convert to a normal cookie. This is a good example of why this is used.
Another good example of why this is used. Everyone knows such a directive as add_header, a standard nginx directive. She uses these headers.
Those. it can do anything with http headers. And the whole installation always looks like this. In fact, there is still a body, I forgot about it. He has the same ideology, the same list, but it works at the stage of content processing.

And the most interesting. Our structure is request. If you ever develop for nginx, this structure will become your best friend. You will often go to this code, perhaps you will forget something about it so that you can jump on it quickly. She is huge, you need to know her. There are a lot of nuances. Therefore, if you want to develop something, get acquainted with this structure, there is nothing complicated there, you just need to read and understand. It keeps the connection itself, the headers that came from the user, which are gone to the user, she keeps all handler handlers in her, her own pool, which works on this request. She also stores the body. Moreover, when you need to deduct guaranteed whole body, or send guaranteed ... because nginx is all pipe, in fact, it works all the time as pipe, it can not accumulate to the end. If you need to send something exactly guaranteed, you need to call special functions and use a specific request. More precisely, the specific structure of the request that came to your handler.

And here we come to the most interesting and most difficult moment of nginx - this is the chain buffer. In nginx, any work with any buffer is a chain buffer. This is, in fact, a single-linked list of buffers. It is very tricky, it can be in a file, it can be shared memory, it can be read only memory, it can be temporary memory. I thought that I would not go into the chain buffer, because there are so many nuances. The main thing that you need to know about it is that your message can come, but in general the body, not in one piece, it can come in buffers, in small-small pieces. This is especially important when you are developing upstream. Because in the upstream you may come in 4K or even in byte, if you need to parse it all, you will need to make some kind of tricky parser that works with chains. In the examples in the read me I will give a reference later, I dropped about two such upstream ones, who would be interested in how to implement a stream parser inside nginx. Because there is still such an important rule - nginx can not be blocked. You have one worker. Even if there is a ThreadPool, it is rare for them who use it, if you blocked this worker for a long time, you lost a lot of rps. This, too, must always be remembered.
And back again, after this lyrical digression, to the Chain buffer. In principle, the whole structure looks like this:

Those. we have a position, last, if this file is file_pos, tags and a bunch of flags. And, in principle, all these comments are now taken from nginx. They must be remembered. Imagine, in your filter or your handler, a piece of memory has come to anything, which is marked that it cannot be modified, then you do not have the right to modify such content. You have to copy it yourself, change it as you want, and give it away. Therefore, these flags must be constantly checked.
Or another good example. Many modules that I wrote do not work with chain buffer if there is a checkmark in_file. Because I wanted there was such a requirement that it work quickly. If, God forbid, nginx starts to pull from a file, from its cache or from somewhere else, then it all dies. Therefore, in this case, it is very logical to check the chain buffer for the fact that it is not in_file, if you do not need it, and write to the admin in the log: "Friend, remove the buffer size, please." This is also a good structure with which you should make friends.
And here is an example, this is me from my upstream module.

I wrote 6 modules for nginx. Only one opensource, and I showed the code from it. What I told you. Those.here, however, the upstream chain buffer is used, not the requester buffer, but the logic is the same. What you just need to check the flags and these flags need to somehow definitely respond. This is a sample code that now works for many. Here, in particular, tp_transcode is a streaming parser, which I did for a long time and painfully.

So we got to the Proxies. About proksyah, as I said, or upstream, or load-balancers, I do not know how to properly characterize them, because they are all similar to tz. implementation. Therefore, I will tell only the very idea why this exists. But without details, because there are so many nuances.

Basically, what is upstream? This is a proxy pass. What does a proxy pass do? In fact, everything that he does, in a chain-mode, gives data to backends, can balance them according to different rules. Nothing prevents you from screwing any protocol there. Suppose we have some kind of daemon that works on the protobuff; nothing prevents nginx from balancing it with the protocol conversion. Those.at the entrance - http, https with some kind of json or even raw protobuf. And you can convert it to a clean protobuf and give it to the application server or to any other protocol. This is the whole idea of upstream.
And, in fact, upstream is a ready-made API inside nginx, which allows you to: a) easily configure such balancing by key, say, some other criteria; b) make backups, i.e. in case all upstreams have fallen off, it will follow a different url. And a lot of different pens for upstream. How many files can be, what timeouts, etc. And everything is available out of the box.
I didn’t have time to add an example of how to do upstreames, but I’ll finish it and post it by reference, which I’ll give. I hope I clearly explained what upstream is and what can be done with it.
Also, in addition, if you do not need conversions to another protocol, you can use them for custom balancing. However, in my opinion, now it is not required, because there is OpenResty, and there is an excellent directive balancer_by_lua, i.e. balancing can be written on lua with any custom logic, I do not know, even go to the radish, however, it all dies under load, but this can be done. Dies-dies. Checked.I tried, my CPU took off at the ceiling, perhaps because of the lua-lines, I suspect because there is balancing on the url when I tried.

And the most sensitive issue was that tons of copies were broken on it, thousands of admins wept, thousands of developers swore at admins. This is deployment.

I forgot to say about the assembly first. Here is a new way to build. In nginx it has recently changed. I did not show the old one, and I did not write a single word about it. I just took from my repository what the typical configuration of this conf, nginx looks like, to add a module. In essence, this is bash, or shell. It just describes a few variables on the shell and that's it. You can even link a C ++ runtime here instead of this static library if you want. This is no problem. Moreover, to be honest, I linked to nginx ++ runtime. This is no problem. The main thing is that the expection in nginx does not penetrate from the pros, because nginx will smash into shchi. Because C is not very friendly with the positives. Here we simply describe what and where it lies.

And then we just fill in these variables, as I wrote above, nginx-variables, and call the auto-module. The module is located inside the nginx repository, where you can see it. This is a new build method and you need to use it, because the old build method will not be soon, as soon as everyone moves to fresh nginx.

Delivery.Here it is a sore subject, and I waited for it long and hard.
For probably three years, all the time we just build our nginx with a bunch of modules and just deploy it. The main thing is separate from the system nginx paths. This is very important, because some wake-up admin will want to put a nginx with the status, write apt-get install nginx and completely put your server. Therefore it is very important.
Plus, we have several projects where there are several completely different nginx modules. It happened, because these are different projects inside mail.ru. And I do not know why it is not to unite, there are no contradictions, it just happened. And we have come to that, we just break up by the name of the project on the way, where we put all this. This is actually pain and suffering, but now it is.
The second way, which appeared relatively recently, is, however, non-working so far - it is possible to load SO'shki in nginx. Why is it non-working? Because nginx checks the fingerprint of this SO's binary. And in order for it to accept this module, you have a large number of nginx build flags and your module must match.
Now I have figured out a way to solve this. Here we have, let's say, the Debian system, and there we can pull out the information with which flags nginx was compiled. And nothing prevents your module from assembling with the same flags, and then packing it. I have not tried to put it on rails, but now I think in this direction, because loading modules is easier. But it is now more painful, because there is a problem with the fingerprint. It seems like the guys are trying to solve it, if you believe their wiki.
And the second option, it is less popular, at least inside mail.ru, maybe in reality it is popular. This is a docker. People take the usual nginx, the usual ways and just make docker image out of it, put it on the server and launch it. I do not know how common this is, but people use it here.

And now, probably, the most provocative thing - why create them?

The answer to the forehead is because there are always new technologies, new ones. If you want to contribute your part to the nginx contribution, albeit from the side, you can add some cool feature to nginx or add a new technology inside nginx. Let's say http 3.0 appears, it will be a new module.

Here, this is my argument, which often resulted in many disputes "Why do I need an nginx-module?". This is what many use - nginx ReverseProxy - to balance into some advantages, which all they do is tell nginx or the client how to work. Those.in such a situation it is more logical, when there are no states, nothing, instead of ReverseProxy, to write an nginx-module, especially in high-loaded projects. Of course, if you have some kind of application, it’s already harder, but, again, you have to look at the task. And so we went to the solution of business problems.

Here is a typical example, these were my 3 penultimate modules for the top mail.ru. Before that, we had an ordinary http-server there, written by hands, no one knows when it was written, it was almost impossible to maintain it, it was constantly breaking down, there were problems, etc. And it was a volitional decision - just take and rewrite all the logic in nginx. Make several modules. A module that distributes cookies, a module that generates a JS file that gives up the counter, and two additional image modules special for this project. 4 modules even turned out.
What is he doing?In fact, it receives this data from the user, forms a line and asynchronously it logs to disk. After that, these logs are raised by the counter and counted. When I made these modules on nginx, we got better on the CPU, as it turned out. Finally, the SSL wound up correctly, because before that it worked incorrectly. It's hard to make kosher SSL inside your application. It hurts. Especially check it out.
So, a good example, statistic analytics. Fits perfectly. There are no states, there are cookies, as a rule, all your states are stored by the user. There is an atomic increment, if you have such logic, it is simply done.

Advertising systems. Generally perfect case. Here either OpenResty, or directly on the nginx-module to write, depends on your needs. Because it is a classic of the genre, I will not even add there. There are almost no states at all, you need some kind of mapka or shared memory between nginx and your demon, which will already have all the connections. Generally, the ideal case. But I'm not sure about OpenResty, to be honest.

And protocol conversion. Admittedly, people, we all have http, we all have browsers, etc. And when we write heaps of a binary protocol, it all pours out of us, that somewhere there is http, then why do we need extra layers? You can just write upstream, which will convert http to X protocol. Everything is quite simple and in fact it is not so difficult. This is actually my work in the evenings 2 weeks. I think you will have about the same amount of it. Moreover, it was still a heavy protocol with strange handshakes.
And here is the linkOn examples that promised, there are 3 examples, a little bit of references on a couple of upstream'ov. There is a very primitive code, literally 100 lines of code, everything that I said is there, plus it makes additional logic. For example, Word Count on the body when filtering, the substitution of content, etc. Those.it can be copied and even indulged. There is a special make file, there is an instruction on how to build it. I will try to expand this and write a comment in the code.
Contacts
→ github
This report is a transcript of one of the best speeches at a professional conference of developers of highload systems Highload ++ , specifically, the “Backend” section.
In our opinion, the report " Proxy HTTP requests by web accelerator " will be an excellent addition to this material , which visitors of HighLoad ++ Junior can hear in three weeks and read Habr's readers in a few months.
- How HTTP proxying works without cache;
What are persistent connections and how do they differ from HTTP keep alive;
How, when and how many connections can set up an HTTP accelerator with upstream;
What becomes of the requests that are waiting for the queue to be sent to the upstream connection, but upstream is out of the box and resets the connection every 100 requests;
What is HTTP pipelining, and how it is used by modern HTTP accelerators;
What are nonidempotent requests, and why you need to worry about them.
Source: https://habr.com/ru/post/328978/
All Articles