Scheduling: myths and reality. Yandex experience
In the past couple of years I have been building various planners, and it occurred to me to share my difficult experience with colleagues. We are talking about two categories of colleagues. The first is to learn how to develop your scheduler for 21 days. The second are those who need a new scheduler without SMS and registration at all, just to work. I would especially like to help the second category of people.

First, as usual, it is worth saying a few general words. What is a scheduler (scheduler, or, for simplicity, “scheduler”)? This is a component of the system that distributes the resource or system resources to consumers. Resource sharing can occur in two dimensions: in space and time. Planners often focus on the second dimension. Usually, a resource means a processor, disk, memory and network. But, to be honest, you can share any virtual nonsense. The end of common words.
Along with the word “planner,” other words often flash, causing much more public interest: isolation, honesty, guarantees, delays, deadlines. There are also some phrases: quality of service (QoS), real time, temporal protection. People, as practice shows, often expect from planners magic combinations of properties that cannot be achieved at the same time - with or without a sheduler. If the necessary properties are achieved, then usually planners still remain an unpredictable thing in themselves and during their operation the list of questions only increases. I will try to lift the veil of secrecy of their behavior. But first things first.
')
To explain and predict the behavior of systems where there is a sheduler, people wrote a lot of books, and also developed a whole theory - and not even one. At a minimum, it is worth mentioning the scheduling theory (scheduling theory) and queuing theory (unexpectedly: in the Russian version it is queuing theory). All such theories are quite complex and, frankly, simply boundless. Some formulations of planning tasks, there is a zoo with a special classification . The matter is not facilitated by the fact that most of the problems are known to be NP-complete or NP-hard. Even in successful cases, when there is a polynomial algorithm for finding the optimal solution or a good approximation, it often turns out: for an online version of the problem (when it is not known in advance which queries need to be shared or when they appear) the optimal algorithm does not exist at all and you must be an oracle remove everything "as it should." However, things are not as bad as it may seem. Mankind already knows a lot about shedulerah, and some of them even work.
An excellent illustration of the unpredictable system behavior with a sheduler is today's Internet. It is a system with a lot of shedulers and an absolute lack of guarantees for bandwidth and delay, lack of isolation and justice in the format of the TCP protocol - which, by the way, even now, decades later, is being studied and improved, and such improvements can produce meaningful results.

Recall TCP BBR from Google. The authors unexpectedly say that it was impossible to create TCP BBR without the latest advances in control theory, which are based on non-standard max-plus-algebra. It turns out that it took more than 30 years.
But this is not all about the sheduler, you say, but about the flow control. And you will be absolutely right. The fact is that they are very closely related. In conventional systems, shedulers are placed in front of a bottleneck - a limited resource. It is logical: the resource is in short supply and it seems that it should be divided fairly. Suppose you have such a resource — the city’s road network — and you want to make a sheduler for it (conditionally, on the way out of the garage) to reduce the average travel time. So, it turns out that the average travel time can be easily calculated by applying Little's theorem : it is equal to the ratio of the number of cars in the system to the speed of their entry into the system. If you reduce the dividend, then at the same bandwidth, travel time falls. It turns out that in order to avoid traffic jams, you just need to make sure that there are fewer cars on the roads (your captain). Scheduler with this task will not help if there is no flow control. On the Internet, the problem described is called bufferbloat .
If I wrote a set of rules for “sheduleroostroeniya”, then the first rule would be this: controlling the queues that arise after the scheduler. The most common way for me to control the queue size is MaxInFlight (its advanced version is called MaxInFlightBytes). There is a problem with him: the fact is that it is impossible to choose the right number. Choosing any fixed number will guarantee you either incomplete use of the band (1), or excessive buffering (2) and, as a result, an increase in the average latency, or, if you are very lucky, timeouts and loss of the band.

A good flow control should keep the system at the Kleinrock point between modes (1) and (2), maximizing the throughput / latency ratio (see TCP BBR).
There are two classic areas of fair planning application — the network and the processor. GPS is not a positioning system, but an ideal sheduler, at the same time serving all its users in infinitely small portions. Such a scheduler ensures that max-min is fair. Real shedulers (WFQ, DRR, SFQ, SCFQ, WF2Q) serve consumers in portions of finite size — packets, if we are talking about a network, or time slices, if we are talking about a processor. These sheduler develops so that their behavior was as close as possible to the ideal and that they minimize the lag - the difference in the amount of service received by different users. Then, to manage the dedicated bandwidth, the developer enters the weights of the users and begins to say that they are in isolated systems with less bandwidth. Here lies the deception. In fact, there is no isolation.
Suppose we have a processor that we want to potentially share between a hundred users. Let's say Vitya is a good user. He sends to the service tasks that are performed in 10 ms, and is ready to wait 1 s, because he understands: there are 99 more users. However, others can send tasks that sometimes run for up to 1 s. Suppose preemption is not possible. Then, in the worst case, Vita will have to wait 99 seconds. Victor, most likely, will want to get out of such a system.
So uninteresting, you say. What kind of system is this - without preemption? The system should be able to offend, and she will be happy. Well, even if at the request execution time of more than 10 ms, we will include preemption, transfer control to the next request and generally use the best fair-known scientists known to science. Will Vitya see the answer in 1 s, as if he were isolated? 10 ms (current request for service) + 99 * 10 ms (requests from other users) + 10 ms (Vitin request) = 1010 ms. This is the maximum waiting time - in other words, in such a system, things are better.
Victor says - a great system! - and sends a request for 1 ms. And he again runs for 1 s (at worst). In a perfectly isolated system, such a request would have been executed in 100 ms, but here it was 10 times worse. Not only can you not get anywhere from this second, other problems will definitely meet in a real system:
It turns out that justice does not provide true isolation, but it divides the strip well. But it was not there. Justice in such classic shedulerah instant. This means that, without sending a request, when it is your turn, you will not receive a resource, and it will be divided among the rest of the volunteers. After a long period of time (for example, 24 hours), it may turn out that the resource was not eaten at all in the proportion in which the weights were given to consumers. In the worst case, consumers can come in any proportions only at those moments when there are no other consumers. As a result, the weight and resource consumption may not be related at all. This is a joke, you say, that never happens. But let us have a distributed system with its own scheduler on each machine. Requests of two users come to two different machines and never compete for a resource, because in fact there are two resources.
If you want to see smooth lines on the charts for an aggregated flow, you should use historical (long-term) equity or quoting. But first ask yourself why you need it.
Suppose you have a fair scheduler with weights and you want to allocate 0.1% of the band for some service traffic, and the remaining 99.9% for the rest. As a result, you get the maximum delay x1000. This phenomenon is called bandwidth-latency coupling. It is a direct consequence of the previous discussion. The maximum delay time is inversely proportional to the width of the selected band. It means that other mechanisms are needed for priority traffic.
Theorem. In any system loaded with more than 100%, the response delay is not limited from above by any number. The proof, I hope, is obvious. Queues will accumulate until something bursts. How wrong to measure and compare the temporal characteristics of systems (including the sheduler), says Gil Tene (you can see or read ). I will leave here only an illustration:

If you no longer need a fair sheduler, you may need a sheduler that is used in real-time systems. Everything is probably good and fast there. Among other things, the correctness of the real-time system depends on the execution of tasks in a given time frame. However, this does not mean that everything happens quickly. For example, deadlines and tasks are of the form “to make and implement a new sheduler before the start of the spring review”. Moreover, the average response time in such systems can be very close to the worst case.
A distinctive feature of RT-systems: they pre-check the schedule for feasibility. “Feasibility” here means the possibility of observing the deadlines of all tasks, and “in advance” is, say, during assembly, during system configuration or when a new task is launched in it. Further, there is a simple way to keep all deadlines in the system, where it is possible in principle. We are talking about real-time-sheduler. For example, it has been proven that the EDF ( Earliest Deadline First ) algorithms are optimal for a single processor. Optimality means that if there is at least some executable schedule for a given set of tasks, then EDF will complete tasks before deadlines.
But there are conditions under which a slender picture of the world collapses and the system ceases to fit into deadlines.
Thus, the EDF, if possible, fulfills deadlines, and if it is not possible - causes maximum damage to the process. Let's put it another way: by minimizing the maximum latency, the EDF fails deadlines for as many tasks as possible. EDF should not be directly applied in conditions of overload - which, as it turns out, is often problematic to predict and / or prevent. However, the methods of struggle still exist .
To determine the load (load factor) in RT systems, a simple periodic model of the following form is used. There are tasks that arrive once every T i ms and require exclusive resource ownership for C i ms in the worst case. Then load factor is defined as the requested resource time for one second of real time, that is, U = C 1 / T 1 + ... + C n / T n . In such a simple model, everything is clear, but how to calculate the load factor, if we have no periods, but only current tasks and their deadlines?
Then the load factor is determined differently. Current tasks are sorted by deadline. Next, starting with a single query with the lowest deadline in the set M, we go through all the queries and add them to this set. M at each step contains requests that must be fully executed by a certain point in time t. We divide their total residual value (if suddenly we have already partially completed some of them) for the remaining time t - now. The obtained value is the load factor U of the set M. To get the current load factor, it remains to find the maximum of all the obtained U. The value found, as you can guess, varies greatly in time and can easily be greater than 1. Schedule impossible with the help of EDF then when load factor> 1.

If it is important for you to keep deadlines, then as a metric, which you should follow, you need to use the described load factor, and not traditional recycling (the fraction of the time when the system was in a busy state).
In real-time-systems there is a term temporal protection. It is used to describe a situation where no user behavior can jeopardize the enforceability of the deadlines for other users. In fact, behind these words there is a simple fact: when a task is completed longer than we expected, it must be forbidden to be executed. To implement this idea, there is a set of mechanisms that bypass all crutches that are ignored by non-real-time-shedulers. As a result, the task is reduced to reserving a band with a pair of numbers (Q, P), where Q is the consumer's budget (ms) and P is the replenishment period of the budget (ms). Simple conclusion: the consumer will receive a Q / P resource. Further, the theory ensures the implementation of tasks of no more than Q ms in size, coming no more than once in P ms, for a deadline of P ms - provided there is no overload (oversubscription). That is, Q 1 / P 1 + ... + Q n / P n <1. Excellent theory. There are even various ways to distribute an unused resource (reclaiming).
But Vitya not stop. He even comes to such a system, and with the same desire to receive his 10 ms on request. In addition to Viti, there are still 99 users in the system. This means that we must reserve 1% of the band for Viti, that is, Q / P = 1/100. Having demanded that the Q value be at least 10 ms, we will ensure the execution of the request in one period. Suppose Q = 10 ms. Then P = Q / (1/100) = 100Q = 1 s. This is the guarantee of our sheduler.
Of course, 1000 ms is a better result than 1010 ms, but not much. But if Victor comes with the desire to receive 1 ms, we are guaranteed to be able to give him an answer in 100 ms. Such a scheduler does not have a minimum quantum, and it will switch the context the minimum necessary number of times - which, by the way, is very important for disks. When no one requires answers for very short periods of time, the disk automatically starts up the largest chunks of data and the throughput increases.
There is another important difference between the redundant scheme and the usual fair sheduler scheme. It consists in the fact that we can more accurately predict when the execution of a query that has entered the system ends, and use this knowledge in other parts of the system.
Thus, a fair real-time planner has several useful properties compared to a regular fair scheduler (such as predictability, minimal overhead, greater flexibility), but this does not include a dramatic improvement in the worst response time.
First, as usual, it is worth saying a few general words. What is a scheduler (scheduler, or, for simplicity, “scheduler”)? This is a component of the system that distributes the resource or system resources to consumers. Resource sharing can occur in two dimensions: in space and time. Planners often focus on the second dimension. Usually, a resource means a processor, disk, memory and network. But, to be honest, you can share any virtual nonsense. The end of common words.
Along with the word “planner,” other words often flash, causing much more public interest: isolation, honesty, guarantees, delays, deadlines. There are also some phrases: quality of service (QoS), real time, temporal protection. People, as practice shows, often expect from planners magic combinations of properties that cannot be achieved at the same time - with or without a sheduler. If the necessary properties are achieved, then usually planners still remain an unpredictable thing in themselves and during their operation the list of questions only increases. I will try to lift the veil of secrecy of their behavior. But first things first.
')
Myth number 1. What's so complicated?
To explain and predict the behavior of systems where there is a sheduler, people wrote a lot of books, and also developed a whole theory - and not even one. At a minimum, it is worth mentioning the scheduling theory (scheduling theory) and queuing theory (unexpectedly: in the Russian version it is queuing theory). All such theories are quite complex and, frankly, simply boundless. Some formulations of planning tasks, there is a zoo with a special classification . The matter is not facilitated by the fact that most of the problems are known to be NP-complete or NP-hard. Even in successful cases, when there is a polynomial algorithm for finding the optimal solution or a good approximation, it often turns out: for an online version of the problem (when it is not known in advance which queries need to be shared or when they appear) the optimal algorithm does not exist at all and you must be an oracle remove everything "as it should." However, things are not as bad as it may seem. Mankind already knows a lot about shedulerah, and some of them even work.
Myth number 2. Shedulers solve all problems
An excellent illustration of the unpredictable system behavior with a sheduler is today's Internet. It is a system with a lot of shedulers and an absolute lack of guarantees for bandwidth and delay, lack of isolation and justice in the format of the TCP protocol - which, by the way, even now, decades later, is being studied and improved, and such improvements can produce meaningful results.
Recall TCP BBR from Google. The authors unexpectedly say that it was impossible to create TCP BBR without the latest advances in control theory, which are based on non-standard max-plus-algebra. It turns out that it took more than 30 years.
But this is not all about the sheduler, you say, but about the flow control. And you will be absolutely right. The fact is that they are very closely related. In conventional systems, shedulers are placed in front of a bottleneck - a limited resource. It is logical: the resource is in short supply and it seems that it should be divided fairly. Suppose you have such a resource — the city’s road network — and you want to make a sheduler for it (conditionally, on the way out of the garage) to reduce the average travel time. So, it turns out that the average travel time can be easily calculated by applying Little's theorem : it is equal to the ratio of the number of cars in the system to the speed of their entry into the system. If you reduce the dividend, then at the same bandwidth, travel time falls. It turns out that in order to avoid traffic jams, you just need to make sure that there are fewer cars on the roads (your captain). Scheduler with this task will not help if there is no flow control. On the Internet, the problem described is called bufferbloat .
If I wrote a set of rules for “sheduleroostroeniya”, then the first rule would be this: controlling the queues that arise after the scheduler. The most common way for me to control the queue size is MaxInFlight (its advanced version is called MaxInFlightBytes). There is a problem with him: the fact is that it is impossible to choose the right number. Choosing any fixed number will guarantee you either incomplete use of the band (1), or excessive buffering (2) and, as a result, an increase in the average latency, or, if you are very lucky, timeouts and loss of the band.
A good flow control should keep the system at the Kleinrock point between modes (1) and (2), maximizing the throughput / latency ratio (see TCP BBR).
Myth number 3. Justice is needed for isolation
There are two classic areas of fair planning application — the network and the processor. GPS is not a positioning system, but an ideal sheduler, at the same time serving all its users in infinitely small portions. Such a scheduler ensures that max-min is fair. Real shedulers (WFQ, DRR, SFQ, SCFQ, WF2Q) serve consumers in portions of finite size — packets, if we are talking about a network, or time slices, if we are talking about a processor. These sheduler develops so that their behavior was as close as possible to the ideal and that they minimize the lag - the difference in the amount of service received by different users. Then, to manage the dedicated bandwidth, the developer enters the weights of the users and begins to say that they are in isolated systems with less bandwidth. Here lies the deception. In fact, there is no isolation.
Suppose we have a processor that we want to potentially share between a hundred users. Let's say Vitya is a good user. He sends to the service tasks that are performed in 10 ms, and is ready to wait 1 s, because he understands: there are 99 more users. However, others can send tasks that sometimes run for up to 1 s. Suppose preemption is not possible. Then, in the worst case, Vita will have to wait 99 seconds. Victor, most likely, will want to get out of such a system.
So uninteresting, you say. What kind of system is this - without preemption? The system should be able to offend, and she will be happy. Well, even if at the request execution time of more than 10 ms, we will include preemption, transfer control to the next request and generally use the best fair-known scientists known to science. Will Vitya see the answer in 1 s, as if he were isolated? 10 ms (current request for service) + 99 * 10 ms (requests from other users) + 10 ms (Vitin request) = 1010 ms. This is the maximum waiting time - in other words, in such a system, things are better.
Victor says - a great system! - and sends a request for 1 ms. And he again runs for 1 s (at worst). In a perfectly isolated system, such a request would have been executed in 100 ms, but here it was 10 times worse. Not only can you not get anywhere from this second, other problems will definitely meet in a real system:
- Unpredictable variable number of users - if there are not 100, but 1000, they will have to wait 10 s.
- High context switching cost. For example, if you schedule HDD requests, switching between users may imply seektime at the level of 8 ms and, as a result, result in a maximum wait of 800 ms, a decrease in the disk bandwidth and an increase in the queues of all users.
- Often such Viti do not want to make a single request, but send them over and over. Requests pile up in front of the scheduler and wait for each other.
- Other priority traffic.
- Not the best known scientist can add an additional delay (for specific numbers and formulas, look for the keywords latency-rate server ).
Myth number 4. Justice is needed to divide the strip according to weight.
It turns out that justice does not provide true isolation, but it divides the strip well. But it was not there. Justice in such classic shedulerah instant. This means that, without sending a request, when it is your turn, you will not receive a resource, and it will be divided among the rest of the volunteers. After a long period of time (for example, 24 hours), it may turn out that the resource was not eaten at all in the proportion in which the weights were given to consumers. In the worst case, consumers can come in any proportions only at those moments when there are no other consumers. As a result, the weight and resource consumption may not be related at all. This is a joke, you say, that never happens. But let us have a distributed system with its own scheduler on each machine. Requests of two users come to two different machines and never compete for a resource, because in fact there are two resources.
If you want to see smooth lines on the charts for an aggregated flow, you should use historical (long-term) equity or quoting. But first ask yourself why you need it.
Myth number 5. Give me a narrow channel for priority traffic
Suppose you have a fair scheduler with weights and you want to allocate 0.1% of the band for some service traffic, and the remaining 99.9% for the rest. As a result, you get the maximum delay x1000. This phenomenon is called bandwidth-latency coupling. It is a direct consequence of the previous discussion. The maximum delay time is inversely proportional to the width of the selected band. It means that other mechanisms are needed for priority traffic.
Myth number 6. I loaded the system to full capacity and started to measure the delay.
Theorem. In any system loaded with more than 100%, the response delay is not limited from above by any number. The proof, I hope, is obvious. Queues will accumulate until something bursts. How wrong to measure and compare the temporal characteristics of systems (including the sheduler), says Gil Tene (you can see or read ). I will leave here only an illustration:
Myth number 7. Real-time scheduler can guarantee my deadlines.
If you no longer need a fair sheduler, you may need a sheduler that is used in real-time systems. Everything is probably good and fast there. Among other things, the correctness of the real-time system depends on the execution of tasks in a given time frame. However, this does not mean that everything happens quickly. For example, deadlines and tasks are of the form “to make and implement a new sheduler before the start of the spring review”. Moreover, the average response time in such systems can be very close to the worst case.
A distinctive feature of RT-systems: they pre-check the schedule for feasibility. “Feasibility” here means the possibility of observing the deadlines of all tasks, and “in advance” is, say, during assembly, during system configuration or when a new task is launched in it. Further, there is a simple way to keep all deadlines in the system, where it is possible in principle. We are talking about real-time-sheduler. For example, it has been proven that the EDF ( Earliest Deadline First ) algorithms are optimal for a single processor. Optimality means that if there is at least some executable schedule for a given set of tasks, then EDF will complete tasks before deadlines.
But there are conditions under which a slender picture of the world collapses and the system ceases to fit into deadlines.
- Overrun In hard-RT-systems it is assumed that we know how much the task will be performed at worst. However, this is not the case in a non-ideal world, and the completion of a task may take more time. If we allow the task to run longer than expected, we will put at risk the feasibility of other tasks. In the case of EDF, a domino effect will occur.
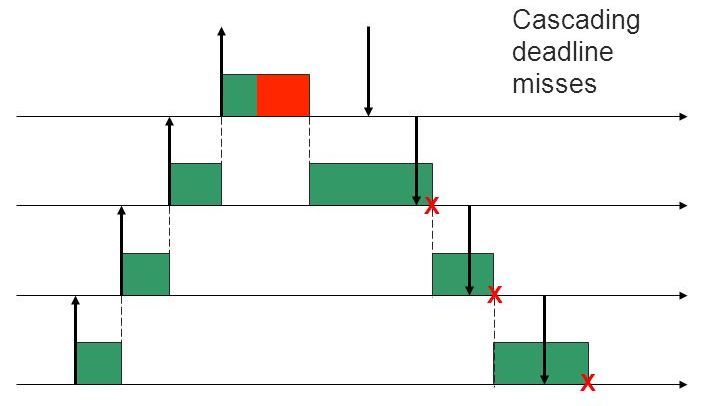
- Overload. It is possible that the newly arrived task does not fit into the desired time frame. If we accept it, we will again get a domino effect. Usually, in such cases, they overload the system and take measures to eliminate it. For example - refuse new or some current tasks in the implementation. Another option is a scheme with the revision of guarantees and postponing the deadlines of some tasks.
Thus, the EDF, if possible, fulfills deadlines, and if it is not possible - causes maximum damage to the process. Let's put it another way: by minimizing the maximum latency, the EDF fails deadlines for as many tasks as possible. EDF should not be directly applied in conditions of overload - which, as it turns out, is often problematic to predict and / or prevent. However, the methods of struggle still exist .
Myth number 8. System can not be loaded more than 100%
To determine the load (load factor) in RT systems, a simple periodic model of the following form is used. There are tasks that arrive once every T i ms and require exclusive resource ownership for C i ms in the worst case. Then load factor is defined as the requested resource time for one second of real time, that is, U = C 1 / T 1 + ... + C n / T n . In such a simple model, everything is clear, but how to calculate the load factor, if we have no periods, but only current tasks and their deadlines?
Then the load factor is determined differently. Current tasks are sorted by deadline. Next, starting with a single query with the lowest deadline in the set M, we go through all the queries and add them to this set. M at each step contains requests that must be fully executed by a certain point in time t. We divide their total residual value (if suddenly we have already partially completed some of them) for the remaining time t - now. The obtained value is the load factor U of the set M. To get the current load factor, it remains to find the maximum of all the obtained U. The value found, as you can guess, varies greatly in time and can easily be greater than 1. Schedule impossible with the help of EDF then when load factor> 1.
If it is important for you to keep deadlines, then as a metric, which you should follow, you need to use the described load factor, and not traditional recycling (the fraction of the time when the system was in a busy state).
Myth number 9. Fair Real Time Planner
In real-time-systems there is a term temporal protection. It is used to describe a situation where no user behavior can jeopardize the enforceability of the deadlines for other users. In fact, behind these words there is a simple fact: when a task is completed longer than we expected, it must be forbidden to be executed. To implement this idea, there is a set of mechanisms that bypass all crutches that are ignored by non-real-time-shedulers. As a result, the task is reduced to reserving a band with a pair of numbers (Q, P), where Q is the consumer's budget (ms) and P is the replenishment period of the budget (ms). Simple conclusion: the consumer will receive a Q / P resource. Further, the theory ensures the implementation of tasks of no more than Q ms in size, coming no more than once in P ms, for a deadline of P ms - provided there is no overload (oversubscription). That is, Q 1 / P 1 + ... + Q n / P n <1. Excellent theory. There are even various ways to distribute an unused resource (reclaiming).
But Vitya not stop. He even comes to such a system, and with the same desire to receive his 10 ms on request. In addition to Viti, there are still 99 users in the system. This means that we must reserve 1% of the band for Viti, that is, Q / P = 1/100. Having demanded that the Q value be at least 10 ms, we will ensure the execution of the request in one period. Suppose Q = 10 ms. Then P = Q / (1/100) = 100Q = 1 s. This is the guarantee of our sheduler.
Of course, 1000 ms is a better result than 1010 ms, but not much. But if Victor comes with the desire to receive 1 ms, we are guaranteed to be able to give him an answer in 100 ms. Such a scheduler does not have a minimum quantum, and it will switch the context the minimum necessary number of times - which, by the way, is very important for disks. When no one requires answers for very short periods of time, the disk automatically starts up the largest chunks of data and the throughput increases.
There is another important difference between the redundant scheme and the usual fair sheduler scheme. It consists in the fact that we can more accurately predict when the execution of a query that has entered the system ends, and use this knowledge in other parts of the system.
Thus, a fair real-time planner has several useful properties compared to a regular fair scheduler (such as predictability, minimal overhead, greater flexibility), but this does not include a dramatic improvement in the worst response time.
Source: https://habr.com/ru/post/328976/
All Articles