Web crawler using Python and Chrome
Good afternoon dear friends.
Recently, sitting on the couch, I thought that I wanted to make my own spider that could download something from web sites. But to download it should not be a simple download, but like a real nice kind browser (i.e., JavaScript to execute).
Such interesting things came up in my head like Selenium, PhantomJS, Splash and all that. All these things were a bit of a drag on me. Here are the reasons I identified:
')
Actually, to the point. Recently released Headless Chrome . This means that now we already use chrome as a crawler (but this is inaccurate). However, I did not find normal utilities for using it as a crawler. I found only chrome-remote-interface from the list of third-party clients (the rest were extremely boring and completely incomprehensible at first glance).
Having run through the documentation and the finished project, and making sure that no one really implemented the client under Python, I decided to make my client.
The protocol in Chrome Remote Debug is quite simple. First we need to start Chrome with the following parameters:

We now have an API available at http://127.0.0.1:9222/json/ , in which I discovered methods such as list , new , activate , version , which are used to manage tabs.
Also, if we just go to http://127.0.0.1:9222/ , then we can switch to a great web debugger that completely simulates the standard one. It is very convenient to keep track of how chrome’s apish methods work (the debugging window on the right is emulated inside the window, and the browser window is drawn on the canvas).
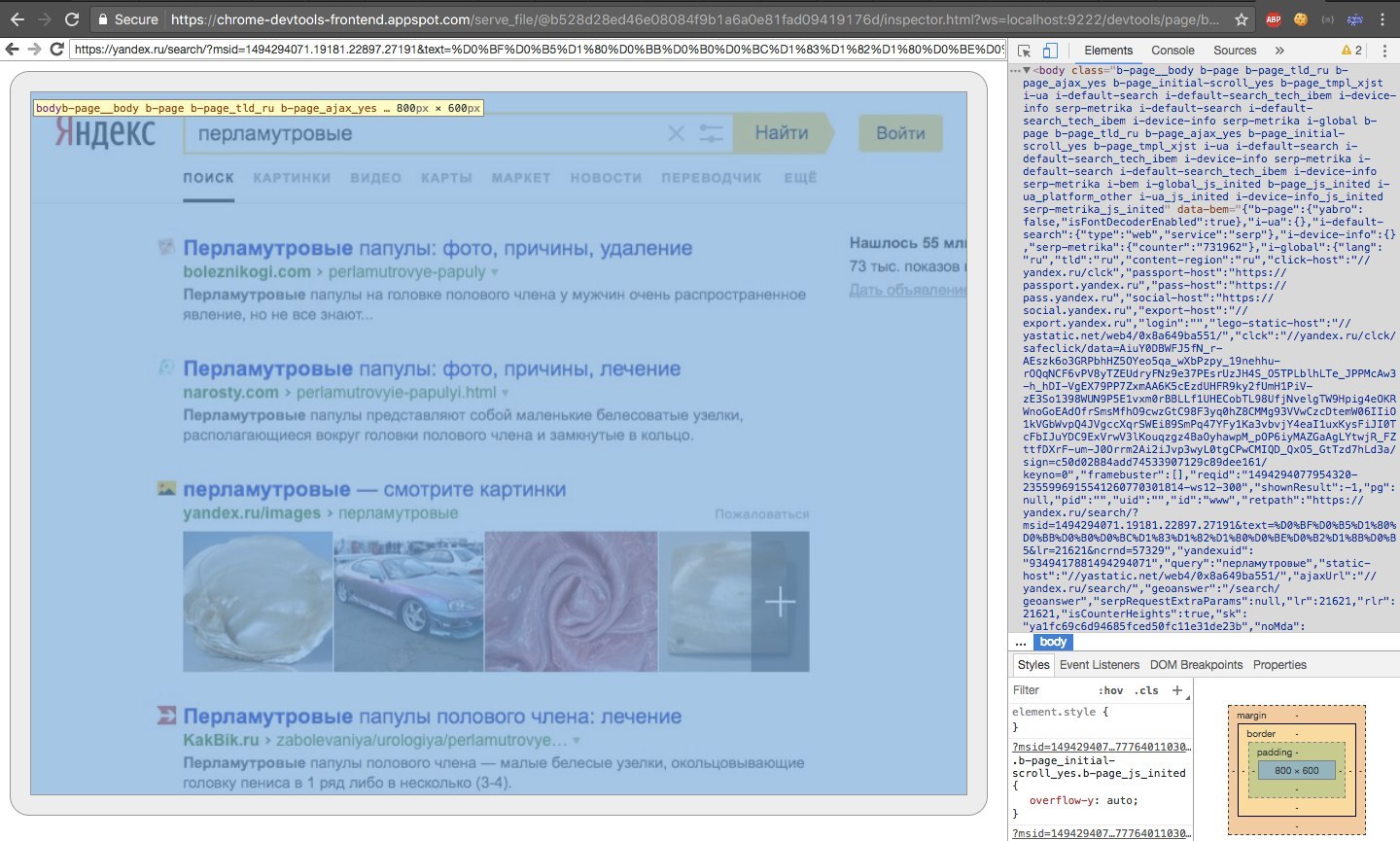
Actually, by going to the list tab, we can find out the address of the web socket, with which we can communicate with the tab.
Then we connect via the web socket to the desired tab, and communicate with it. We can:
After days of tormenting the writing of a functional for myself, I had such a library .
What is in it:

This is what the prog looks like, which loads the page and gives the length of each response to the request:
Here we use the Kolbek system. The most interesting: start and any :
My code seemed to me quite elegant, and I will use it further, even though the protocol is a bit damp. If someone wants to discuss, then write here, in Github or mail me.
However, there was one thing but because of which I still cry. With the help of remote API it is impossible to intercept and modify requests and responses. As I understand it - this is possible through mojo , which allows chrome to be used as a library.
However, I thought that compiling unstable chrome and the lack of a Python interlayer would be a great misfortune for me (now there is C ++ and JavaScript in the process of development).
Hope the article was helpful. Thank.

Recently, sitting on the couch, I thought that I wanted to make my own spider that could download something from web sites. But to download it should not be a simple download, but like a real nice kind browser (i.e., JavaScript to execute).
Such interesting things came up in my head like Selenium, PhantomJS, Splash and all that. All these things were a bit of a drag on me. Here are the reasons I identified:
')
- The fact is that I would like to write on my favorite python, because I really don't like JavaScript, which already means that most would not work (or had to glue them somehow, which also sucks).
- Also, these headless browsers are updated as when.
- But Selenium is a very nice thing, but I did not find how to track the page loading there, or at least an adequate way to tear out a cookie or ask it. I heard that many lovers of selenium would inject into a JavaScript page, which is crazy for me, because about six months ago I made a site that would pick up any JavaScript calls from the site and could potentially determine my spider. I really would not like such incidents. I want my spider to look like a browser as accurately as possible.
Actually, to the point. Recently released Headless Chrome . This means that now we already use chrome as a crawler (but this is inaccurate). However, I did not find normal utilities for using it as a crawler. I found only chrome-remote-interface from the list of third-party clients (the rest were extremely boring and completely incomprehensible at first glance).
Having run through the documentation and the finished project, and making sure that no one really implemented the client under Python, I decided to make my client.
The protocol in Chrome Remote Debug is quite simple. First we need to start Chrome with the following parameters:
chrome --incognito --remote-debugging-port=9222 --headless We now have an API available at http://127.0.0.1:9222/json/ , in which I discovered methods such as list , new , activate , version , which are used to manage tabs.
Also, if we just go to http://127.0.0.1:9222/ , then we can switch to a great web debugger that completely simulates the standard one. It is very convenient to keep track of how chrome’s apish methods work (the debugging window on the right is emulated inside the window, and the browser window is drawn on the canvas).
Actually, by going to the list tab, we can find out the address of the web socket, with which we can communicate with the tab.
Then we connect via the web socket to the desired tab, and communicate with it. We can:
- Run query
- Subscribe to events in the tab
After days of tormenting the writing of a functional for myself, I had such a library .
What is in it:
- Automatic swap of the latest protocol version
- Python Protocol Wrapper Protocol
- Synchronous and asynchronous client (synchronous for debugging only)
- Hopefully convenient tab abstraction
This is what the prog looks like, which loads the page and gives the length of each response to the request:
import asyncio import chrome_remote_interface if __name__ == '__main__': class callbacks: async def start(tabs): await tabs.add() async def tab_start(tabs, tab): await tab.Page.enable() await tab.Network.enable() await tab.Page.navigate(url='http://github.com') async def network__loading_finished(tabs, tab, requestId, **kwargs): try: body = tabs.helpers.unpack_response_body(await tab.Network.get_response_body(requestId=requestId)) print('body length:', len(body)) except tabs.FailReponse as e: print('fail:', e) async def page__frame_stopped_loading(tabs, tab, **kwargs): print('finish') tabs.terminate() async def any(tabs, tab, callback_name, parameters): pass # print('Unknown event fired', callback_name) asyncio.get_event_loop().run_until_complete(chrome_remote_interface.Tabs.run('localhost', 9222, callbacks)) Here we use the Kolbek system. The most interesting: start and any :
- start (tabs, tab) - called at startup.
- any (tabs, tab, callback_name, parameters) - called if the event was not found in the list of callbacks.
- network__response_received (tabs, tab, ** kwargs) is an example of the Network.responseReceived library event.
My code seemed to me quite elegant, and I will use it further, even though the protocol is a bit damp. If someone wants to discuss, then write here, in Github or mail me.
However, there was one thing but because of which I still cry. With the help of remote API it is impossible to intercept and modify requests and responses. As I understand it - this is possible through mojo , which allows chrome to be used as a library.
However, I thought that compiling unstable chrome and the lack of a Python interlayer would be a great misfortune for me (now there is C ++ and JavaScript in the process of development).
Hope the article was helpful. Thank.
Source: https://habr.com/ru/post/328800/
All Articles