Everything you didn't know about the CAP theorem
During my first experience with distributed systems, I was constantly confronted with a certain CAP-theorem, I had to dig a little to learn and understand it from all sides. I am not a database wizard, but I hope that my little exploration of the world of distributed systems will be useful for ordinary developers. In the article I will talk about what CAP is, its problems and alternatives, and also consider some popular database systems through the CAP prism.
This theorem was presented at a symposium on the principles of distributed computing in 2000 by Eric Brewer. In 2002, Seth Gilbert and Nancy Lynch of MIT published a formal proof of the Brewer hypothesis, making it a theorem.
According to Brewer, he wanted the community to start a discussion about compromises in distributed systems and after some years began to amend it and make reservations.
CAP states that in a distributed system it is possible to select only 2 of the 3 properties:
')
There are already sufficiently visual proofs of this theorem, therefore I will give references to Bauman University and proof in the form of the service “Call me, remind!” .
Many articles boil down to such a simple triangle.
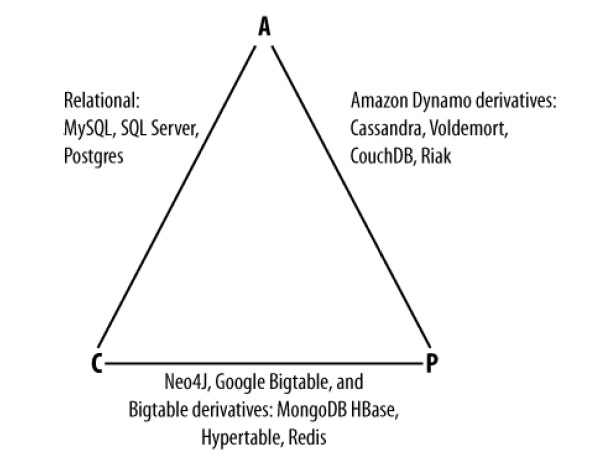
To use CAP theorems in practice, I chose the 3 most, in my opinion, suitable and quite popular database systems: Postgresql, MongoDB, Cassandra.
The following items refer to the Postgresql abstract distributed database.
Thus, the system can not continue to work in the case of a partition, but provides strong consistency and availability. This is a CA system!
The following items refer to the MongoDB abstract distributed DB.
Thus, the system can continue to work in case of network separation, but the CAP-availability of all nodes is lost. This is a CP system!
Cassandra uses the master-master replication scheme, which in effect means an AP system in which network separation leads to the self-sufficient operation of all nodes.
It would seem that everything is simple ... But this is not so.
A lot of detailed and interesting articles are written on the topic of problems in the CAP theorem, here, on Habré, so I will leave the link to CAP no longer relevant and the myths about the CAP theorem . Be sure to read them, but treat each article as a kind of new look and do not take it too close to your heart, because some are scolded, others are praised. I myself will not go too far, but I will try to give some necessary compilation.
So, the problems of the CAP theorem:
Consistency in CAP actually means linearizability (and it is really difficult to achieve). To explain what linearity is, let's look at the following picture:
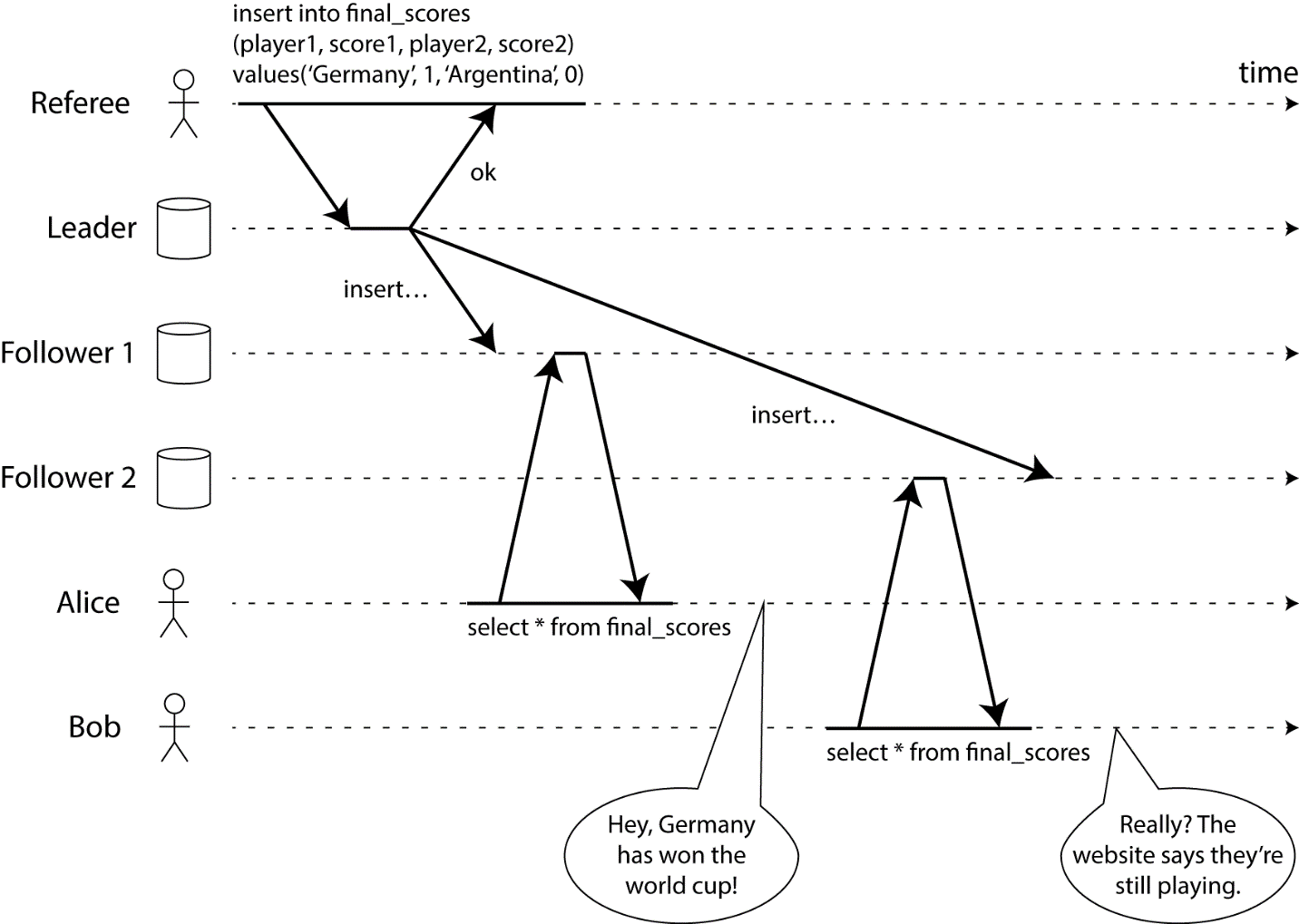
In the case described, the referee finished the game, but not every client gets the same result. To make its system linearized, we need to instantly synchronize data between the referee and other data sources so that when the referee finishes the game, each client will receive the correct information.
Availability in CAP, based on the definition, has two serious problems. The first is that there is no concept of partial availability, or some degree of it (percentages for example), but there is only full accessibility. The second problem is unlimited response time to requests, i.e. even if the system responds in an hour, it is still available.
Resistance to distribution does not include fallen nodes, and here's why:
Therefore, you need to remember about the ability of the system to recover, but beyond the CAP theorem.
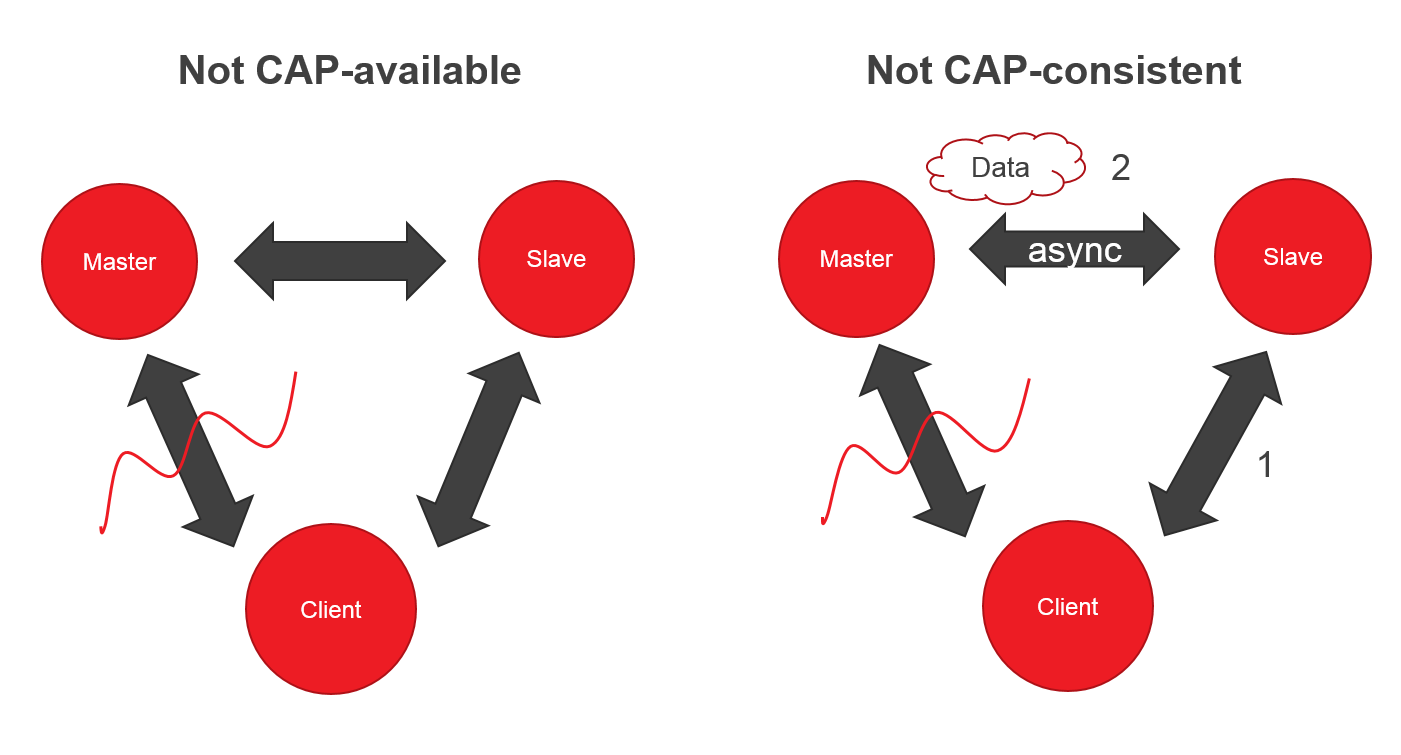
Communication between nodes usually occurs through an asynchronous network, which can delay or delete messages. The Internet and all our data centers have this property, and these are not unlikely incidents, so CA systems are rarely considered as part of the development.
Imagine a system in which two nodes (Master, Slave) and a client. If suddenly you have lost contact with the Master, the client can read from the Slave, but cannot write - there is no CAP-availability.
Ok, like the CP system, but if the Master and Slave are synchronized asynchronously, then the client can request data from the Slave before successful synchronization - we lose CAP-consistency.
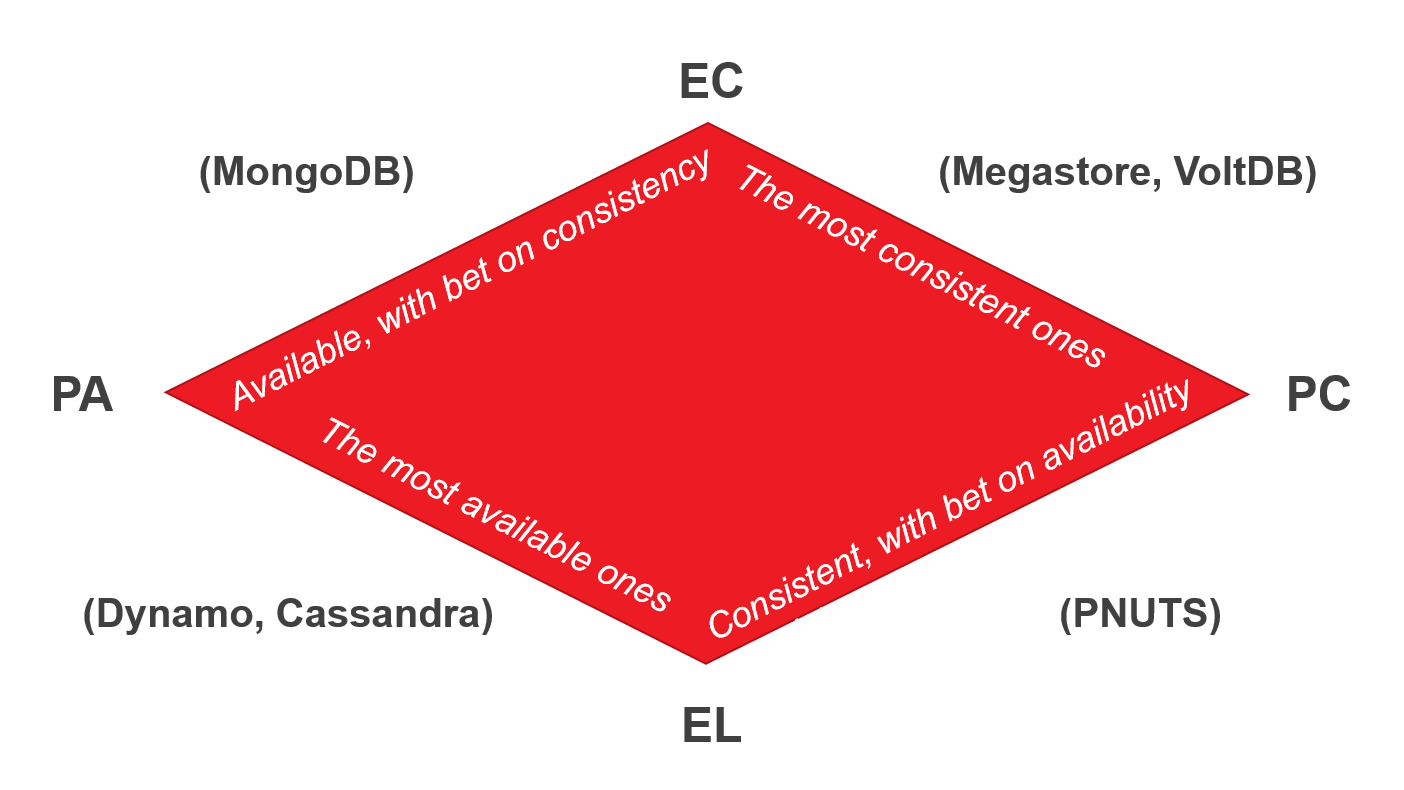
Pure AP systems may include just 2 number generators. Pure CP systems may not be available at all. I will try to come to an agreed state and will not answer us. Go ahead, CP systems give us not the strong consistency that we expect, but eventual consistency. We'll talk about it a little later.
In the end, it's just an attempt to classify something abstract, so you don't need to reinvent the wheel. I recommend using the following approach when trying to work with distributed databases:
The PACELC theorem was first described and formalized by Daniel J. Abadi from Yale University in 2012. Since the PACELC theorem is based on CAP, it also uses its definitions.
The whole theorem reduces to IF P -> (C or A), ELSE (C or L).
Latency is the time for which the client will receive an answer and which is regulated by some level of consistency. Latency (latency), in a sense, represents the degree of availability.
BASE is a peculiar contrast to ACID, which tells us that true coherence cannot be achieved in the real world and cannot be modeled in highly scalable systems.
What is behind BASE:
I was asked several times about what is better than ACID or BASE - it depends on your project. For example, if your data is not critical, and the user really cares about the speed of interaction, BASE would be the best option. If it's the other way around - ACID will help you make the system as reliable as possible in terms of data.
Now that we know about most of the pitfalls, let's try to look at the same popular database systems from the perspective of knowledge gained.
Postgresql does allow for many different system configurations, so it’s very difficult to describe them. Let's just take the classic Master-Slave replication with implementation through Slony.
Let's find out something new about MongoDB:
Thanks for attention!
CAP theorem
This theorem was presented at a symposium on the principles of distributed computing in 2000 by Eric Brewer. In 2002, Seth Gilbert and Nancy Lynch of MIT published a formal proof of the Brewer hypothesis, making it a theorem.
According to Brewer, he wanted the community to start a discussion about compromises in distributed systems and after some years began to amend it and make reservations.
What is behind CAP
CAP states that in a distributed system it is possible to select only 2 of the 3 properties:
')
- C (consistency) - consistency. Each reading will give you the most recent entry.
- A (availability) - availability. Each node (not fallen) always successfully executes requests (for reading and writing).
- P (partition tolerance) - resistance to distribution. Even if there is no connection between nodes, they continue to work independently of each other.
There are already sufficiently visual proofs of this theorem, therefore I will give references to Bauman University and proof in the form of the service “Call me, remind!” .
Basically this is all a triangle.
Many articles boil down to such a simple triangle.
We put into practice
To use CAP theorems in practice, I chose the 3 most, in my opinion, suitable and quite popular database systems: Postgresql, MongoDB, Cassandra.
Let's look at Postgresql
The following items refer to the Postgresql abstract distributed database.
- Master-Slave replication is one of the common solutions.
- Synchronization with Master in asynchronous / synchronous mode
- The transaction system uses a two-phase commit to ensure consistency.
- If a partition occurs, you cannot interact with the system (mostly)
Thus, the system can not continue to work in the case of a partition, but provides strong consistency and availability. This is a CA system!
Let's look at MongoDB
The following items refer to the MongoDB abstract distributed DB.
- MongoDB provides strong consistency, because it is a system with one Master node, and all entries go to it by default.
- Automatic master change, in case of separation from other nodes.
- In the event of a network split, the system will stop taking records until it can be sure that it can safely complete them.
Thus, the system can continue to work in case of network separation, but the CAP-availability of all nodes is lost. This is a CP system!
Look at Cassandra
Cassandra uses the master-master replication scheme, which in effect means an AP system in which network separation leads to the self-sufficient operation of all nodes.
It would seem that everything is simple ... But this is not so.
CAP problems
A lot of detailed and interesting articles are written on the topic of problems in the CAP theorem, here, on Habré, so I will leave the link to CAP no longer relevant and the myths about the CAP theorem . Be sure to read them, but treat each article as a kind of new look and do not take it too close to your heart, because some are scolded, others are praised. I myself will not go too far, but I will try to give some necessary compilation.
So, the problems of the CAP theorem:
- Far from the real world definitions
- As part of the development, the choice mainly lies between the CP and the AP
- Many systems - just P
- Clean AP and CP systems may not be what you expect.
What is wrong with the definitions?
Consistency in CAP actually means linearizability (and it is really difficult to achieve). To explain what linearity is, let's look at the following picture:
In the case described, the referee finished the game, but not every client gets the same result. To make its system linearized, we need to instantly synchronize data between the referee and other data sources so that when the referee finishes the game, each client will receive the correct information.
Availability in CAP, based on the definition, has two serious problems. The first is that there is no concept of partial availability, or some degree of it (percentages for example), but there is only full accessibility. The second problem is unlimited response time to requests, i.e. even if the system responds in an hour, it is still available.
Resistance to distribution does not include fallen nodes, and here's why:
- By definition. In the availability and spelled "... every node (if not failed) always ..."
- Based on the evidence. The proofs of the CAP theorem state that some code must be executed on the nodes.
- Well, some of my (and not only) conjectures. In case of a node fall, the system can recover, communicate with other nodes and continue working as if nothing had happened. In case of network separation, you will have to wait for the connection to be restored.
Therefore, you need to remember about the ability of the system to recover, but beyond the CAP theorem.
AP / CP selection
Communication between nodes usually occurs through an asynchronous network, which can delay or delete messages. The Internet and all our data centers have this property, and these are not unlikely incidents, so CA systems are rarely considered as part of the development.
Many systems are just P
Imagine a system in which two nodes (Master, Slave) and a client. If suddenly you have lost contact with the Master, the client can read from the Slave, but cannot write - there is no CAP-availability.
Ok, like the CP system, but if the Master and Slave are synchronized asynchronously, then the client can request data from the Slave before successful synchronization - we lose CAP-consistency.
Clean AP and CP systems
Pure AP systems may include just 2 number generators. Pure CP systems may not be available at all. I will try to come to an agreed state and will not answer us. Go ahead, CP systems give us not the strong consistency that we expect, but eventual consistency. We'll talk about it a little later.
How to live with it
In the end, it's just an attempt to classify something abstract, so you don't need to reinvent the wheel. I recommend using the following approach when trying to work with distributed databases:
- Remember the definitions of CAP and their limitations.
- Use the PACELC theorem instead of CAP, it allows you to look at the system from another perspective.
- Remember the principles of ACID / BASE and how they apply to your system.
- Any gestures should be done, given the project you are working on.
PACELC
The PACELC theorem was first described and formalized by Daniel J. Abadi from Yale University in 2012. Since the PACELC theorem is based on CAP, it also uses its definitions.
The whole theorem reduces to IF P -> (C or A), ELSE (C or L).
Latency is the time for which the client will receive an answer and which is regulated by some level of consistency. Latency (latency), in a sense, represents the degree of availability.
A little bit about BASE
BASE is a peculiar contrast to ACID, which tells us that true coherence cannot be achieved in the real world and cannot be modeled in highly scalable systems.
What is behind BASE:
- Basic Availability. The system responds to any request, but this response may contain error or inconsistent data.
- Soft-state. System state may change over time due to changes in final consistency.
- Eventual consistency. The system will eventually become consistent. She will continue to accept data and will not check every transaction for consistency.
I was asked several times about what is better than ACID or BASE - it depends on your project. For example, if your data is not critical, and the user really cares about the speed of interaction, BASE would be the best option. If it's the other way around - ACID will help you make the system as reliable as possible in terms of data.
A fresh look
Now that we know about most of the pitfalls, let's try to look at the same popular database systems from the perspective of knowledge gained.
Postgresql
Postgresql does allow for many different system configurations, so it’s very difficult to describe them. Let's just take the classic Master-Slave replication with implementation through Slony.
- The system works in accordance with ACID (there are a couple of problems with a two-phase commit, but this is outside the scope of the article).
- If the connection is broken, Slony will try to switch to the new Master, and we have a new master with its consistency.
- When the system is operating normally, Slony does everything to achieve strong consistency. In fact, ACID is the cause of the big delay in this system.
- The system classification is PC / EC (A).
MongoDB
Let's find out something new about MongoDB:
- This is ACID in a limited sense at the document level.
- In the case of a distributed system, it's all about that BASE.
- In the absence of network separations, the system ensures that the read and write will be consistent.
- If the master node drops or loses communication with the rest of the system, some data will not be replicated. The system will select a new wizard to remain available for reading and writing. (The new master and the old master are inconsistent).
- The system is considered PA / EC (A), since most of the nodes remain CAP-available in the event of a break. Remember that CAP MongoDB is usually referred to as CP. PACELC creator, Daniel J. Abadi, says that there are far more problems with consistency than accessibility, therefore PA.
Cassandra
- Designed for “high-speed” interaction (low-latency interactions).
- ACID at record level.
- In the case of a distributed system, it's all about that BASE.
- If a disconnect occurs, the remaining nodes continue to function.
- In the case of normal operation, the system uses consistency levels to reduce latency.
- The system is referred to as PA / EL (A).
findings
- Compromise of distributed systems - this is what should begin the design process.
- It is rather difficult to classify an abstract system, it is much better to first form requirements based on the technical specifications, and only then correctly configure the required database system.
- Do not overwork, we are just curious developers, if there is any doubt, consult an expert.
Thanks for attention!
Useful sources
dzone.com/articles/better-explaining-cap-theorem
blog.thislongrun.com/2015/03/the-confusing-cap-and-acid-wording.html
neo4j.com/blog/acid-vs-base-consistency-models-explained
databases.about.com/od/databasetraining/a/databasesbegin.htm
brooker.co.za/blog/2014/07/16/pacelc.html
www.postgresql.org/files/developer/transactions.pdf
www.airpair.com/postgresql/posts/sql-vs-nosql-ko-postgres-vs-mongo
jennyxiaozhang.com/nosql-hbase-vs-cassandra-vs-mongodb
blog.thislongrun.com/2015/04/the-unclear-cp-vs-ca-case-in-cap.html
www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
cs-www.cs.yale.edu/homes/dna/papers/abadi-pacelc.pdf
blog.thislongrun.com/2015/03/dead-nodes-dont-bite.html
queue.acm.org/detail.cfm?id=2462076
blog.thislongrun.com/2015/03/the-confusing-cap-and-acid-wording.html
neo4j.com/blog/acid-vs-base-consistency-models-explained
databases.about.com/od/databasetraining/a/databasesbegin.htm
brooker.co.za/blog/2014/07/16/pacelc.html
www.postgresql.org/files/developer/transactions.pdf
www.airpair.com/postgresql/posts/sql-vs-nosql-ko-postgres-vs-mongo
jennyxiaozhang.com/nosql-hbase-vs-cassandra-vs-mongodb
blog.thislongrun.com/2015/04/the-unclear-cp-vs-ca-case-in-cap.html
www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
cs-www.cs.yale.edu/homes/dna/papers/abadi-pacelc.pdf
blog.thislongrun.com/2015/03/dead-nodes-dont-bite.html
queue.acm.org/detail.cfm?id=2462076
Source: https://habr.com/ru/post/328792/
All Articles