Avito Picture Store History

But what if you are given the task of organizing the storage and distribution of static files? Surely many will think that everything is simple. And if there are a billion, several hundred terabytes of such files and several billions of requests per day to them? Also, many different systems will send files of different formats and sizes for storage. This quest does not seem so simple. Under the cut, the story of how we solved such a problem, what difficulties arose and how we overcame them.
Avito has developed rapidly since the early days. For example, the speed of downloading new images for ads has increased several times in the early years. This required us at the initial stage to solve issues related to the architecture as quickly and efficiently as possible, in conditions of limited resources. In addition, we have always preferred simple solutions that require few resources for support. The principle of KISS (“Keep it short and simple”) is still one of the values of our company.
First decisions
The question of how to store and how to give pictures of ads, appeared immediately, as the ability to add photos to the ad, of course, is key for users - buyers want to see what they are buying.
')
At that time, Avito fit in less than 10 servers. The first and fastest solution was to store image files in a directory tree on a single server and synchronize over the crown to the backup.
The path to the file was determined based on the unique digital identifier of the images. At first there were two levels of nesting with 100 directories on each.

Over time, the place on the server began to come to an end, and something had to be done about it. This time we chose to use network storage mounted on multiple servers. The network storage was previously provided to us by the data center itself as a service in a test mode, and according to our test measurements, at that time it worked satisfactorily. But with the growth of the load, it began to slow down. Optimization of storage by the data center did not help dramatically and was not always operational. Our possibilities to influence how storage is optimized were limited and we could not be sure that the possibilities of such optimizations would not be exhausted sooner or later. By that time, our server fleet increased significantly and began to be calculated in dozens. An attempt was made to quickly raise distributed glusterfs. However, it worked satisfactorily only under a small load. As soon as they were taken out at full capacity, the cluster “collapsed”, or all requests to it “hung”. Attempts to tweak it have failed.
We realized that we needed something else. The requirements for a new storage system were identified:
- as simple as possible
- built from simple and proven components
- not taking much support resources
- maximum possible and simple control over what is happening
- good potential for scaling
- very quick implementation and migration dates from the current solution
- some images are unavailable during server repair (servers were repaired to us more or less quickly)
- It is possible to lose a small part of the pictures in case of complete destruction of one of the servers. I must say that during the entire existence of Avito, this has never happened before. 3 * Ugh.
New scheme
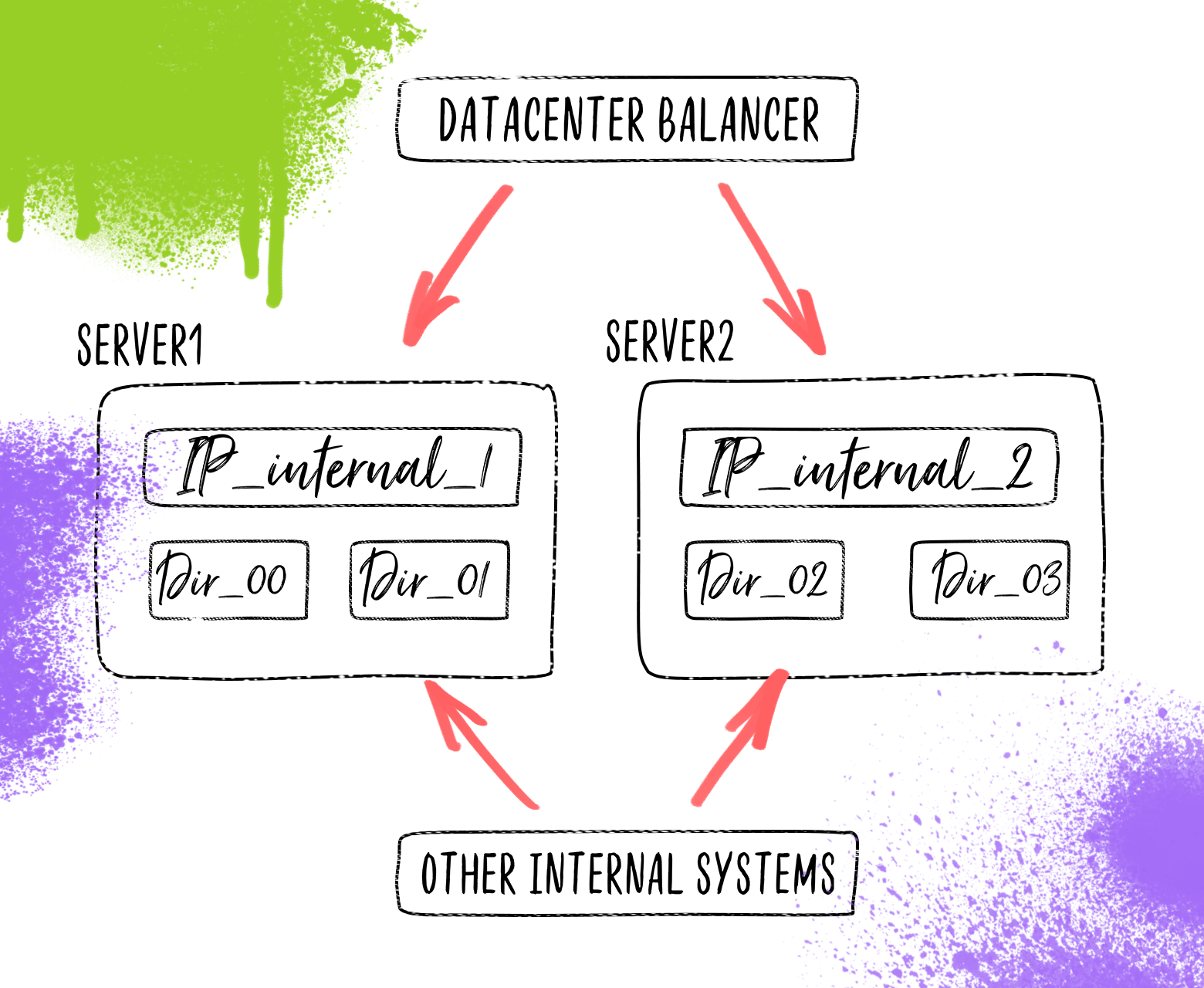
In the image for simplicity, only four nodes on two servers are shown.
During the discussion came to this scheme. Files will be stored in the same directory tree, but the top-level directories are distributed across a group of servers. It must be said that by that time we had servers with the same disk configuration, the disks on which were “idle”. Files are sent all the same nginx. On each server, IPs are raised that correspond to a specific top-level directory located on the server. At that time, we didn’t think about balancing traffic, since the data center did it for us. The logic of balancing was that, depending on the domain to which the request came (there were a total of 100 domains), send a request to an internal IP that was already on the correct server.
The question arose of how the site code will upload pictures to the repository, if it is also distributed across different servers. It was logical to use the same http protocol by which the file came to us from the user. Began to look for what we can use as a service that will receive files on the server side, which stores files. The eye fell on the nginx open module for file upload. However, in the course of his study it turned out that the logic of his work does not fit into our scheme. But this is open source, and we have programming experience in C. For a short time, in breaks between other tasks, the module was finalized and now, working as part of nginx, it received files and saved them in the correct directory. Looking ahead, I will say that in the process of working in production a memory leak was revealed, which at first was treated by restarting at night, and then, when there was time, they found the cause and corrected it.
Loads grow
Over time, we began to use this storage not only for images, but also for other static files, flexibly adjusting with the help of nginx parameters affecting performance and access to files.
As the number of requests and the amount of data increased, we faced (and sometimes foresaw in advance) a number of problems that, under conditions of high loads, required making quick and effective decisions.
One of these problems was the balancing that the data center provided for us at the F5 Viprion load balancer. We decided to remove it from the traffic processing path by allocating 100 external IPs (one for each node). So we removed the bottleneck, accelerated data delivery and increased reliability.
The number of files in one directory was increasing, which resulted in slowing down of components due to the increased time of reading the contents of directories. In response, we added another level from 100 directories. We received 100 ^ 3 = 1M directories for each storage node and increased overall speed.
We have experimented a lot with optimal configuration of nginx and disk cache parameters. In the picture that we observed, we had the impression that the disk cache does not give a full return from caching, and caching with nginx in tmpfs works better, but clearing its cache noticeably loads the system during peak hours. First of all, we included the logging of nginx requests into a file and wrote our daemon, which late in the evening read this file, cleaned it, detected the most relevant files, and cleared the rest of the cache. Thus, we have limited the clearing of the cache to the night period, when the load on the system is not great. It worked quite successfully for a period, up to a certain level of load. Building statistics and clearing the cache ceased to fit into the night interval; moreover, it was clear that disk space would come to an end in the near future.
We decided to organize a second level of data storage, similar to the first, but with some differences:
- 50 times the size of the disk subsystem on each server; however, the speed of the disks may be less.
- an order of magnitude fewer servers
- external access to files is possible only through proxying through the first level
This gave us the opportunity to:
- more flexible caching options
- use cheaper storage equipment for the main part of the data
- even easier to scale the system in the future
However, this required some complication of the system configuration and code for downloading new files to the storage system.
The diagram below shows how two storage nodes (00 and 01) can be placed on two storage levels using one server on the first level and one on the second. It is clear that you can place a different number of nodes on the server, and the number of servers at each storage level can be from one to one hundred. All nodes and servers in the diagram are not shown for simplification.

In the image, for simplicity, only two nodes on two servers are shown.
Conclusion
What did we get in the end? Static file storage system, which can be easily understood by a mid-level specialist, built on reliable, proven open elements, which, if necessary, can be replaced or modified with a small price. In this case, the system can provide users with dozens of PB data per day and store hundreds of terabytes of data.
Cons, too. For example, the lack of data replication, complete protection from equipment failure. And although initially, when designing the system, it was immediately determined and coordinated in accordance with the risk assessment, we have a set of additional tools that allow leveling these drawbacks (system backups, scripts for testing, restoring, synchronizing, moving, etc.)
In the future plans to add the ability to flexibly configure replication for a part of the files, most likely through some delayed queue.
I deliberately didn’t go into the details of implementation, the logic of the work (I don’t say anything at all), the nuances of the settings so as not to delay the article and bring the main idea: if you want to build a good strong system, then one of the right ways could be to use open proven products connected in a relatively simple and reliable scheme. Normally do, it will be normal!
Source: https://habr.com/ru/post/328778/
All Articles