We raise the price monitoring service of competitors
Anyone who works in e-commerce sooner or later faces the need to be first among competitors. One of the most effective tools in this matter is price management. The results of marketing research show that among those consumers who are willing to change the supplier of industrial equipment and tools, one-third cites low price as a decisive factor in choosing a new supplier. On the Internet there are a lot of different services, but for one reason or another they did not fit.
Ways to get information about competitor prices
Instruments
Historically, the online store is at 1C-Bitrix, so the price monitoring was written in php. But this is the wrong approach, so the algorithm for parsing on Node.js will be described below.
')
For example, take the iphone product in different stores and we will monitor its price.
Create a table of competitors:
Next, we need a URL for products and a list of elements in the HTML document. Create a table of lists of elements:
Create a table that will store url, prices, etc .:
An example of filling the competitors table:

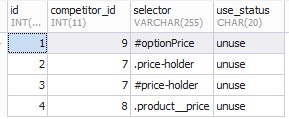
An example of filling the competitors_selector table:
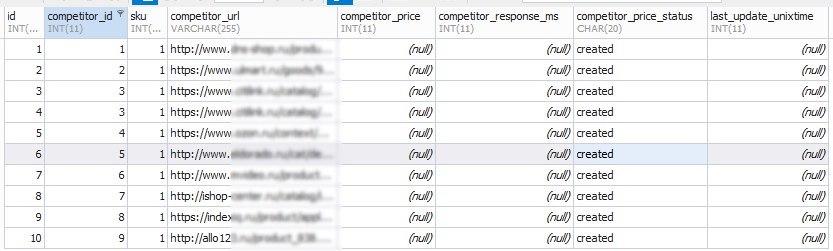
An example of filling the competitors_data table:
The data from competitors_selector is populated based on selectors:

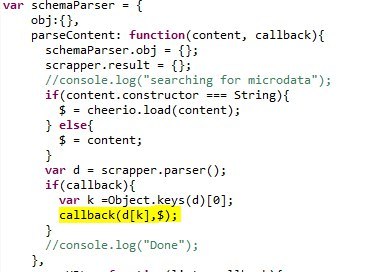
At the moment, every self-respecting online store uses microdata . There is a huge number of parsers in various programming languages. Since we decided what we are writing on Node.js, we will use the excellent semantic-schema-parser module. The module itself fits in 149 lines and under the hood it has an excellent cheerio content parser . We will slightly modify the module by adding the $ object to the callback.
But do not forget that many online stores still do not use microdata . The competitors_selector data comes into play here. In the request options, we put a maximum of 5 redirects, a user-agent as a yandex bot, and a timeout of 2 seconds.
To download html use the library needle . To simplify the formation of queries to the database, we use the templayed template engine .
Queries to the database:
The parsing algorithm is as follows:
The Scraping class code is shown below. The code uses a bicycle to simultaneously analyze the url asynchronously. Initially, the idea was:
But for now the implementation is as follows:
As a result, we obtain the following data:
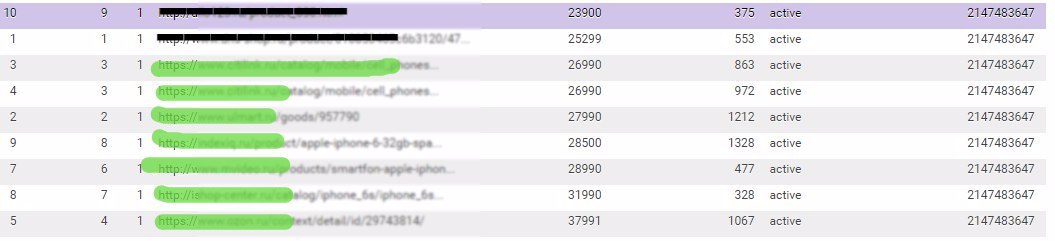
The image shows that you can track the most expensive and cheapest price of a competitor, the server response time. Now you can send it into pricing, for revising the pricing policy.
Summing up, I would like to say that with the use of microdata the parsing of the names of goods, prices and categories is greatly simplified. But there is still a big fly in the ointment:
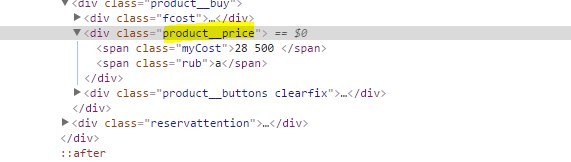
Those stores that do not use microdata use not class id as selectors, which is correct from the layout point of view, but complicates parsing (for example, in the document we can have 7 elements with price = class, and prices will only be in 4, 5, 6, 10). Also, the price does not always exist in a convenient format:
At the moment, with the advent of microdata, parsing has become much easier.
In the next article I will try to show how the algorithm of automatic matching of the competitor's url card and the card in the online store is implemented.
Ways to get information about competitor prices
- The easiest and most effective way to monitor prices at the moment is pricelab . But in it you can check only those products that are already participating in Yandex.Market. That is, your main competitor must be in Yandex.Market, the product you are interested in must also be unloaded, and you yourself must unload your product.
What are the disadvantages that this entails? Considering the fact that in Yandex.Market the price of a click is proportional to the price of SKU , many will not place specialized products with a high price in it, and it will be unprofitable to place such goods themselves.
We have implemented a small script for price monitoring with pricelab, but some key positions are not downloaded in pricelab. - Agree with a competitor’s employee. This is not entirely correct and honest way. Therefore, immediately rejected.
- Parsing competitor site. This is a popular method and it goes almost for nothing. Below it will be described it.
Instruments
- Database.
- Algorithm parsing.
Historically, the online store is at 1C-Bitrix, so the price monitoring was written in php. But this is the wrong approach, so the algorithm for parsing on Node.js will be described below.
')
For example, take the iphone product in different stores and we will monitor its price.
Create a table of competitors:
competitors
CREATE TABLE panda.competitors ( id int(11) NOT NULL AUTO_INCREMENT, name varchar(50) DEFAULT NULL, PRIMARY KEY (id) ) ENGINE = INNODB CHARACTER SET utf8 COLLATE utf8_general_ci; Next, we need a URL for products and a list of elements in the HTML document. Create a table of lists of elements:
competitors_selector
CREATE TABLE panda.competitors_selector ( id int(11) NOT NULL AUTO_INCREMENT, competitor_id int(11) DEFAULT NULL, selector varchar(255) DEFAULT NULL, use_status CHAR(20) DEFAULT 'unused', PRIMARY KEY (id) ) ENGINE = INNODB CHARACTER SET utf8 COLLATE utf8_general_ci; Create a table that will store url, prices, etc .:
competitors_data
CREATE TABLE panda.competitors_data ( id INT(11) NOT NULL AUTO_INCREMENT, competitor_id INT(11) DEFAULT NULL, sku INT(11) DEFAULT NULL, competitor_url VARCHAR(255) DEFAULT NULL, competitor_price INT(11) DEFAULT NULL, competitor_response_ms INT(11) DEFAULT NULL, competitor_price_status CHAR(20) DEFAULT 'created', last_update_unixtime INT(11) DEFAULT NULL, PRIMARY KEY (id) ) ENGINE = INNODB CHARACTER SET utf8 COLLATE utf8_general_ci; An example of filling the competitors table:
An example of filling the competitors_selector table:
An example of filling the competitors_data table:
The data from competitors_selector is populated based on selectors:
At the moment, every self-respecting online store uses microdata . There is a huge number of parsers in various programming languages. Since we decided what we are writing on Node.js, we will use the excellent semantic-schema-parser module. The module itself fits in 149 lines and under the hood it has an excellent cheerio content parser . We will slightly modify the module by adding the $ object to the callback.
But do not forget that many online stores still do not use microdata . The competitors_selector data comes into play here. In the request options, we put a maximum of 5 redirects, a user-agent as a yandex bot, and a timeout of 2 seconds.
To download html use the library needle . To simplify the formation of queries to the database, we use the templayed template engine .
Queries to the database:
resetSelectorsStatus.sql
UPDATE competitors_selector SET use_status = 'unuse' WHERE 1; selectcSelectors.sql
SELECT * FROM competitors_selector selectcURLs.sql
SELECT * FROM competitors_data updateCompetitorData.sql
UPDATE competitors_data SET competitor_price = '{{price}}' ,competitor_response_ms = {{response_ms}} ,last_update_unixtime = {{response_time}} ,competitor_price_status = '{{status}}' WHERE id = {{id}} The parsing algorithm is as follows:
- Reset selector.
- We form object from DOM selectors.
{:['selector1','selector2']} - Download HTML.
- Analyzing microdata.
- If the microdata does not have the necessary data, then analyze the selectors.
- If the data is not defined, then set it to null.
The Scraping class code is shown below. The code uses a bicycle to simultaneously analyze the url asynchronously. Initially, the idea was:
- Aggregate competitors from competitors_data.
- Set the number of simultaneous asynchronous requests.
- We interrogate each competitor through timeout.
But for now the implementation is as follows:
Full code
var needle = require('needle'); var mysql = require('mysql'); var templayed = require('templayed'); var fs = require('fs'); var schema = require("semantic-schema-parser"); var Scraping = new function(){ //1. _this = this; _this.DB = mysql.createConnection({ host : 'localhost', user : '******************', password : '******************', database : 'panda' }); _this.querys = {}; _this.selectors = {};//dom Scraping'a _this.rows = null;// url _this.workers = 5;// _this.needleOptions = { follow_max : 5 // 5 ,headers:{'User-Agent': 'Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) '} ,open_timeout: 2000 // if we don't get our response headers in 5 seconds, boom. } this.run = function(){ _this.DB.connect(); _this.queryLoad(); _this.resetSelectorsStatus(); } //--------------------// // { ()} this.queryLoad = function(){ _this.querys['selectcSelectors'] = fs.readFileSync('sql/selectcSelectors.sql', 'utf8'); _this.querys['resetSelectorsStatus'] = fs.readFileSync('sql/resetSelectorsStatus.sql', 'utf8'); _this.querys['selectcURLs'] = fs.readFileSync('sql/selectcURLs.sql', 'utf8'); _this.querys['updateCompetitorData'] = fs.readFileSync('sql/updateCompetitorData.sql', 'utf8'); }; //--------------------// // this.resetSelectorsStatus = function(callback){ _this.DB.query( _this.querys['resetSelectorsStatus'], function(err, rows) { _this.selectcSelectors(); }); } //--------------------// //---- DOM this.selectcSelectors = function(callback){ _this.DB.query( _this.querys['selectcSelectors'] , function(err, rows) { if (!err){ rows.forEach(function(item, i, arr) { if (!_this.selectors[item.competitor_id]){_this.selectors[item.competitor_id]=[];} _this.selectors[item.competitor_id].push({id:item.id,selector:item.selector}); }); _this.selectcURLs(); } }); } //--------------------// this.selectcURLs = function(callback){ _this.DB.query( _this.querys['selectcURLs'] , function(err, rows) { if (!err){ _this.rows = rows; _this.workersTask(); } }); } //--------------------// this.workersTask = function(){ __this = this; __this.worker = []; for (var i = 0; i < _this.workers; i++) { __this.worker[i] = { id:i ,status: 'run' ,allTask : function(){ var status = {}; status['run'] = 0; status['iddle'] = 0; __this.worker.forEach(function(item){ if(item.status==='run'){status['run']++;} else{status['iddle']++;} }); return status; } ,timeStart : new Date().valueOf() ,func: function(){ _this.parseData(__this.worker[this.id]) } } __this.worker[i].func(); } } //--------------------// this.parseData = function(worker){ __this = this; var count = _this.rows.length; var startTime = new Date().valueOf(); if(count > 0 ){ var row = _this.rows.shift();// rows var URL = row.competitor_url; needle.get(URL, _this.needleOptions, function(err, res){ if (err) {worker.func(); return;} var timeRequest = ( new Date().valueOf() ) - startTime; schema.parseContent(res.body, function(schemaObject, $){ price = _this.parseBody(schemaObject,$,row); status = ( price!='NULL' ) ? 'active' : 'error'; //console.log(res.statusCode, 'timeout:'+timeRequest, 'price:'+price, worker.id, URL, row.id); _this.updateCompetitorData({ id : row.id ,status:status ,response_time:( new Date().valueOf() ) ,response_ms:timeRequest ,price:price }); worker.func(); }); }); }else{ worker.status = 'idle'; if(worker.allTask().run===0){ console.log(' , '); _this.DB.end();// ; } } } _this.parseBody = function(schemaObject,$,row){ var price; schemaObject.elems.forEach(function(elemsItem, i) { if(!elemsItem.product)return; elemsItem.product.forEach(function(productItem, i) { if(!productItem.price)return; price = ( productItem.price['content'] ) ? productItem.price['content'] : ( productItem.price['text'] ) ? productItem.price['text'] : null; price = price.replace(/[^.\d]+/g,"").replace( /^([^\.]*\.)|\./g, '$1' ); price = Math.floor(price); }); }); if( (!price) && (_this.selectors[row.competitor_id]) ){ _this.selectors[row.competitor_id].forEach(function(selector){ price_text = $(selector.selector).text(); if (price_text){ price = price_text.replace(/[^.\d]+/g,"").replace( /^([^\.]*\.)|\./g, '$1' ); price = Math.floor(price); // selector //-------------------------------------------------// return; } }); } if(!price){price = 'NULL'}; return price; } //--------------------// _this.updateCompetitorData = function(data){ query = templayed( _this.querys['updateCompetitorData'] )(data); _this.DB.query( query , function(err, rows) {}); } //--------------------// _this.run(); } As a result, we obtain the following data:
The image shows that you can track the most expensive and cheapest price of a competitor, the server response time. Now you can send it into pricing, for revising the pricing policy.
Summing up, I would like to say that with the use of microdata the parsing of the names of goods, prices and categories is greatly simplified. But there is still a big fly in the ointment:
- Not all online stores use microdata.
- Not all microdata are valid (a vivid example is ozone).
- Not all online stores use data on price, name, category in microdata.
- Some stores in microdata use the text field instead of content, or vice versa.
Those stores that do not use microdata use not class id as selectors, which is correct from the layout point of view, but complicates parsing (for example, in the document we can have 7 elements with price = class, and prices will only be in 4, 5, 6, 10). Also, the price does not always exist in a convenient format:
<div class="price price_break"><ins class="num">2980</ins><ins class="rub"> .</ins></div> At the moment, with the advent of microdata, parsing has become much easier.
In the next article I will try to show how the algorithm of automatic matching of the competitor's url card and the card in the online store is implemented.
Source: https://habr.com/ru/post/328734/
All Articles