About memory, tags and coherence

Tagged memory ( tagged architecture ) gives an exotic opportunity to separate data from metadata. The price for this is not so great (at first glance), and the potential opportunities are impressive. Under the cut try to figure it out.
Background
In a tagged architecture, each word of memory is accompanied by a tag — one or more bits describing the data in this word. By itself, this idea is very natural and originated at the very dawn of the computer industry.
Rice computer
Chronologically, apparently the first full-fledged computer with such an architecture was the R1 , which was developed from 1958 to 1961, began to give the first signs of life in 1959. Mostly Rice computer was remembered by the fact that its memory was collected on CRT handsets . The image of a piece of memory on such a tube is presented in the title illustration.
The hardware word (of which there were 32K, grouped by 64) had a size of 64 bits, of which:
')
- 1 bit was used to debug the work of the tubes themselves, which were very unreliable storage. In fact, every 64th handset was a CRT monitor, on which one could literally peep the contents of any of the adjacent handsets.

Debugging on R1. - 7 digits per Hamming code
- 54 bits of data itself
- 2 digits per tag. Tags extended to code words as well as to data.
The tags on the code were used for debugging, for example, an instruction with a “01” tag caused the registers to be printed.
For data, everything is more complicated. Tags marked arrays, for example, two-dimensional arrays had tags of the end of a line and the end of an array. Also, the tag could mean the end of the iterations (vector), when the instruction was cycled on the vector.
Burroughs Large Systems

Burroughs 5000 appeared in 1961. Each 48-bit word was accompanied by a tag from one digit that determined whether it was code or data.
Later on (1966, B6500), the use of tags was considered very successful, and the tag was extended to 3 bits. At the same time, the 48th digit was immutable and still separated the code from the data. Tags meant:
- 0 - any data except double precision
- 2 - double precision
- 4 - cycle index
- 6 - uninitialized data
- 1 - addresses on the stack
- 3 - common tag for code
- 5 - descriptors describing data not on the stack
- 7 - procedure handle
This series has been very successful and commercially in terms of technology development. The only serious drawback can be considered a strong focus on Algol . With obsolescence, Algola is gone and Burroughs.
Lisp are machines.
Actively developed in 1973 ... 1987 after and during the boom of artificial intelligence systems in Lisp.
Some of them had hardware tags, for example, the Symbolics 3600 (a 36-bit word containing 4–8 bit tags and 28–32 data bits).
And some used the technique of tagged pointers when the tag is written either to the unused bits of the pointer or to the memory preceding the one the pointer is looking at.
This technique is quite flourishing itself today, for example, in the form of NSNumber . From a close to the author, a similar lisp approach (together with the lisp core) was implemented first in Kubl and then in Openlink Virtuoso RDBMS.
Soviet Elbrus.
Was disassembled earlier in this article . The 64-bit word was accompanied by 8 digits of the tag and 8 - Hamming code. The developed tag system allowed dynamic typing. Those. there was a general addition instruction, the processor used the tags to determine the types of arguments, made the necessary casts, and started the summation of the desired type.
In this case, if the argument was a function descriptor, the function was started, and if an indirect word was used, an indirect call was made. And so on until it turned out exactly the value.
Along with addresslessness, this provided a high compactness of the code.
Current Elbrus (three stacks - Sic!)
Elbrus, as far as the author knows, is the only evolving architecture with tagged memory.
Each 4-byte word in memory, registers and tires is accompanied by a 2-bit tag. The word tag encodes the following features [4, p. 98]:
- 0 - the word contains numeric information either by itself or
being a format fragment - 1 - the word contains non-numeric information with the format of a single
the words - 2 - the word contains a fragment of non-numeric format information
double word - 3 - the word contains a fragment of non-numeric format information
quadro words
Neither the length nor the type of numerical data is architecturally indistinguishable. The semantic filling of a numeric variable is tracked by the compiler and manifests itself when it becomes the operand of an operation.
The register file contains [4, p. 127] 256 registers of 84 bits each, having three fields. The first two fields are for 32-bit storage.
words with 2-bit tags, double word F64, mantissa real
numbers, and the third field is reserved for storing a 16-bit order value. Those. 2 * (32 + 2) + 16.
According to [5, p. 9], [6, p. 10] tags are -
- array handle
- object handle
- is empty
- numeric data
Apparently, this is deciphering the value of the tag, “in the process of the path the dog could grow up”.
The tag mechanism is used for hardware control of the correctness of the program, the costs are 25-30% (forum.ixbt). Costs, apparently, are caused by the fact that the pointer can reach 256 bits.
Swapping data comes with tags. Physically tags are located in the memory allocated for ECC.
So, they refused from the dynamic typing in the spirit of the Soviet Elbrus, but applied a modified object model, which, apart from the performance costs, greatly complicated the C / C ++ compiler, making it impossible to integrate into the LLVM, for example.
So.
We see that the tagged memory was used for the following purposes:
- debugging
- performance control
- data driven programming
Without diminishing the importance of all of the above, it would be useful to introduce another class of information for tags — hints to the processor, the presence of which can improve performance.
Current Element Base, ESS
In practice, DDR * SDRAM ECC-memory is widely used for servers with the SECDED class code (single-patch correction and double-error detection). On memory modules, for every 8 chips, one more chip is added, which stores ECC codes of 8 bits for every 64 bits of main memory.
What if:
Suppose we are dealing with 64-bit words. On the existing element base, we have an additional 8 digits for each word. At the same time, we adhere to static typing quite in the spirit of C / C ++. And do without the object model, which for the most part is needed when debugging, and you always have to pay for it.
How can you use the discharges of 8 discharges? For example, enter the following fields in the tag:
- Null Signals whether underlying data is initialized. Used to control the correctness of the program. Existing software traps are quite expensive, which is why they are mainly used for debugging. The presence of hardware control would bring many benefits. 1 rank
- Exec . Distinguishes executable code from data. Used to avoid execution of the unenforceable. 1 rank
- Type metadata . Sets the fact whether we are dealing with a chunk of data or a pointer. 1 rank One could have done without it, since we have static typing. On the other hand, hardware control of this kind would be very useful. The use of this field entails the need for a tag modification instruction.
- Attributes of type instance . For numeric data, this field contains information similar to the contents of the flags register at the time of the operation to calculate this data.
In x86, for example, the following FLAGS register fields are responsible for this.- CF - carry flag - overflow in unsigned integer arithmetic
PF - parity bit, not neededAF - for BCD, not needed- ZF - the result is 0
- SF - less than 0 result
- OF - overflow occurred
In the superscalar core, the register of flags is also to be renamed , with various flags being renamed independently. This creates certain difficulties and delays in reading the contents of the flags register.
And we have the opportunity to place the flags of the result of a specific operation in its tag. If the task is to squeeze into 3 bits, you can simply donate OF or set the NULL flag if the compiler considers it necessary.
With regard to the work with a floating point, ZF & SF will be useful, NAN can also be duplicated here.
Pointers. For them it would be useful to leave the CF flag, enter another one - the constancy of the data. Data constancy does not mean that the data cannot be changed; it simply cannot be done through this pointer. It also requires support (tag modification instructions) to remove / establish constancy.
The presence of attributes of an instance of a type allows part of the comparison operations to be performed without recourse to an ALU. And the separation of the comparison operation and the conditional transition slightly simplifies the life of the predictor of transitions. - Attributes of the place . This part of the tag refers not to the data, but to the place where they are located. Data may be
- in the program body as constants or as global variables, in this case the metadata of the place is provided by the compiler
- in the swap file
- in RAM
- in cache
- in the register
Everywhere along with the data is present and their tag.
When copying data to a register, their place attributes are lost.
When copying from a register, place attributes are taken from a destination.- Constancy The presence of this flag guarantees the hardware protection of a specific word against changes. In C / C ++, constants are placed in a special write-protected segment. Using the operating system, you can create a data segment and prohibit the change of its content by hardware, but this is expensive. Having cheap word level hardware protection might be helpful. Traps . At the debug level, it is sometimes useful to catch changes in a particular word; this can be implemented in such a relatively cheap way.
- Globality Perhaps the most important. This flag determines whether the given word participates in the cache coherence support mechanism.
Cache coherence support.
At the moment, the whole (with rare exceptions - non-cached ranges) memory is covered by the mechanism of cache coherence support. Although, for example, stack memory is used only by a specific thread, and it is unnecessary to share it with others (this may be required in exceptional cases under the responsibility of the programmer).
This problem could be solved using the attributes of memory segments, but this is too expensive. CRT , for example, allocates segments as it pleases and the programmer has no way to influence this.
On the other hand, the amount of user data for which coherence support is required is not that large. If it were possible to clearly indicate a sign of data coherence, this would markedly reduce the load on the bus. Most system data, for example, TLB is not concerned, they should be global.
Consider an example, the multiplication of matrices. This refers to the matrix of large size, which are certainly not located on the stack.
The Strassen algorithm recursively splits 2X2 matrices, then multiplies them using 7 multiplications instead of 8. The division continues until the submatrices become small (<32 ... 128), then they are multiplied in a naive way. Has difficulty
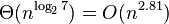 and suffers from instability.
and suffers from instability.At first glance, it seems that in the process of computing all the used memory should be coherent. But,
- when naively multiplying small submatrices, no coherence is required at all
- when working with 2X2 matrices, all the work inside the submatrices has already been completed and all data is used within one thread
- in fact, memory coherence is not needed for this task
The same is true of the most well-parallelized algorithms - the interaction between the threads occurs only when merging partially calculated results. And the interaction between threads is reduced to the barriers of computation.
The reason is that synchronization of threads is expensive, incompatible with efficient calculations.
What can be a living example of mass use of shared memory?
Parallel work with the graph, where the mask of attendance of the ribs is divided. It was possible to have a separate mask for each thread, but this is less effective in terms of using the cache. As a result, masks are changed by interlocked operations. But interlocked operations are a clear indication of the mechanism for supporting coherence.
Suppose we have a mechanism that allows a programmer to explicitly tell the compiler what data he wants to see in a coherent state, and what data he doesn't want. In C / C ++, this could be a volatile modifier. At the moment, this modifier is used to remove a variable from under optimization, the compiler avoids its placement in registers.
In what situation can there be problems with incoherent data?
- The T1 stream runs on the P1 processor, calculates something, adds to the M1 array
- M1 is a stack; no outsider knows about it.
- Some part of M1 is located in the P1 cache.
- T1 is superseded by the scheduler and after some time it resumes at P2.
- P2 cache has no M1 content, it is read from memory - data is not relevant
It seems that it will not be possible to completely isolate local data from the coherence support protocol. Let's see what can be done here.
There are two “orthogonal” variants - the evolution of the coherence support protocol and the local cache with “relocation”.
Local cache with “relocation”.
Appeals to local data take up to 95% [19]. Since they are not needed by anyone outside the kernel, it is logical to start their own cache for them without the support of coherence. Problems begin when thread loses context because at this moment we still do not know on which core our thread will resume.
- because It is likely that this will be a different core, it's time to reset all the untouched data, merge all changes into memory
- but if it’s the same core, you’ll have to read it all over again.
- besides, transfer from kernel to kernel is faster than reading from memory
- if you postpone the “move” at the time of renewal, there will be an undesirable delay
- the time estimate for “relocation” is as follows: let the transfer occur at a clock frequency of 32 bytes per clock, this gives 100GB / s, 2MB transmission will take 20 microseconds, not so little.
- transferring thread to another kernel is a very frequent case and blocking the bus for tens of microseconds every time is very wasteful
- besides operating system support is required
The result is this - at least when transferring a thread inside a single processor, the option of “moving” the local cache is inappropriate.
Coherence Support Protocol.
The basis (for simplicity) is MESI (Intel: Pentium, Core; PowerPc 604 [16]), which, although considered obsolete, is the basis for other protocols and is not as specific as MESIF (Intel Nehalem) or MOESI ( AMD Opteron).
How it works physically is shown in the following illustrations.

Example SandyBridge (MESIF). There are 4 buses in each direction: requests, acknowledgments, snoops (to support coherence) and data itself (32 bytes wide)

Elbrus ‑ 8C topological plan ( MOSI for E-4C + ): Core 0–7 - processor cores; L3 B0–7 - banks of the third level cache; SIC - system exchange controller; DIR0,1 - global reference; DDR3 PHY0–3 - blocks of the physical memory level; IP PHY1, 2, 3 - blocks of the physical layer of interprocessor exchange channels; IO PHY - block of the physical level of the I / O channel [13].
So, MESI.
Requests from the kernel to the cache are:
- PrRd : The kernel asks to read the cache line.
- PrWr : The kernel asks to write a cache line.
Requests from the bus are:
- BusRd : Snoop occurs when there is a request to read this cache line from another kernel
- BusRdX : Snoop saying that there is a request to read this cache line from another kernel, and on the other side of this line is no longer
- BusUpgr : Some kernel asks for a (more recent) cache line despite the fact that its old version is there
- Flush : A signal that a cache line was unloaded by someone.
- FlushOpt : Passing a string from the cache to the cache.
Cache line states:
- Modified (M) A string is only present in the cache of the kernel, but its contents are different from what is in memory. One day this line will have to be written back into memory, with the state going to S.
- Exclusive (E) The unchanged line is present only in the cache of this kernel.
- Shared (S) This line can also be in the caches of other cores, while its contents are the same as in memory and can be safely reset at any time.
- Invalid (I) in the kernel cache is not a given line.
The machine for these states looks like this:

But all this concerns only those data that are marked in the tag as global. What to do with local? For them we will create new states:
- Local Modified (LM) string is present only in the cache of the kernel, but its contents are different from what is in memory. One day, this line will have to be written back into memory, with the state going to L
- PrRd does not cause changes in the state
- PrWr does not cause state changes.
- BusRdX puts the string in state I, the content is sent to the requester
- BusRd, BusUpgr, Flush suggest that the requested copy has something that cannot be
- Local (L) Unchanged local string.
- PrRd does not cause changes in the state
- PrWr puts the string in the LM state.
- BusRdX puts the string in state I, the content is sent to the requester
- BusRd, BusUpgr, Flush suggest that the requested copy has something that cannot be
Now, if we go back to the example, after T1 has resumed on the P2 core, an attempt to read M1 will lead to the migration of the cache contents from the P1 core to P2.
In the cache of all cores, there is no more than one instance of any local data cache line. At the same time, after the data migration has been completed, no read / write operations on the local data (except reading / writing the actual memory) do not lead to bus delays.
It is worth noting the following nuances:
- Initially, when requesting PrRd, it is not yet known what type the cache line will be. Therefore, the decision about which state to assign to this line (L or E) is made after reading it.
- The cache line is larger than a word, for example, 64 bytes. The globality flag is assigned to the entire string, the compiler must take care of proper alignment. This is quite a serious problem. If we want local and global data not to be mixed within the same cache line, the compiler must take this into account when aligning. Moreover, the size of the cache line may depend on the processor model. Although, on the other hand, if, along with global data, a piece of local will also come under the distribution, there should be no particular problems.
- Since caching is done in physical addresses, some effort must be made before forcing a page out of memory. Namely, in all caches, the changed data of this page should be stored in memory, after which all of the lines on this page are invalid. This also applies to local data.
- Any close coherence support algorithm is easily modified to work with local data in a similar way.
- Separate words deserve a dynamic change of the flag globality. Suppose we allocate a memory block with malloc and make it global. Since the memory block could be allocated from the CRT cache and was previously in circulation, it is likely that its residues are still in the kernel cache as local. Therefore, before cocking globalization in the tag, it is necessary to clear this line from the caches of all cores. The same applies to the reverse situation - the localization of global data.
An attentive reader can exclaim - let me, but in fact it happens in life. States E and M are read and written without additional bus operations! If the data is actually local and without any tags, working with them is quite local.
There is a difference. A BusRd request puts M and E into state S and the string continues to occupy the resource for a while. In addition, we have considered only a relatively simple case - a single multicore processor.
SMP
Here we are dealing with multiple processors, the means of communication between them, and the total equally-accessible memory. Such a scheme has a growth limit. Either processors are connected to the click , or work through a common bus. The first version is quadratic in complexity by the number of processors, the second one divides its bandwidth into all. Combined methods collect not only advantages, but also disadvantages of both options.
Up to a certain size can manage so-called. directory based scheme. In its purest form, a directory assumes a handle to each potential cache line. Those. if the line size is 64 bytes, then for every 64 bytes of main memory there should be a descriptor, telling which processors / cores / nodes have copies of this line.
It is clear that this requires a large amount of additional memory, which because of this cannot be done quickly. Therefore, this scheme greatly slows down the work with memory.
On the other hand, directory is very sparse. cache size is much smaller than main memory. Therefore, attempts have been made (for example, [24]) to store information in a compressed form and still squeeze it into fast memory. Here, the problem is quite simple - the amount of memory per directory is fixed, and the degree of compression is not constant. Ensuring that it is possible to fit in a fixed volume is not so easy.
There is a variant of the hybrid scheme, when the directory is used as a cache, and everything that does not fit into this cache is processed via the snoop protocol. The disadvantage of this option is that you have to store along with the mask part of the cache line address, so that the efficiency of using fast and expensive memory decreases, but everything works on any directory volume.
Example, Opteron from AMD: one of the banks of the L3 cache [28] is allocated to the directory - 1MB out of 6 on the processor, this covers 256K lines, 32 bits per line. Those. The directory serves approximately three times the cache size of its processor.
Example, Nehalem from Intel. Inclusive L3 cache with a total volume of 2 MB per core. There is no dedicated directory, but each L3 line contains a usage mask - one for each core of its processor and one for each foreign processor, for example 10 + 7 = 17 (10 - by the number of cores, needed for intra-processor MESIF, 7 - allowed up to 8 processors, this is just part of the directory) additional bits. In fact, this is a L3-sized directory that is synchronous with L3.
And we will tell about the already mentioned Elbrus-4C + [19] separately, it deserves it.
- 8 cores
- inclusive L3 cache with a total volume of 16MB
- SIC system exchange controller with four memory channels and input / output interfaces
- Four processors can be combined using three interprocessor links into a system consisting of 32 cores.
- each processor has two pipelines for memory access
- each pipeline is connected to two memory controllers
- each pipeline requires its own directory of 512Kb, which works taking into account interleaving to addresses (8th of the physical address)
- each directory entry (32 bits) is responsible for 2 cache lines (64 bytes each), i.e. Totally 256K elements of each processor cover 32Mb L3 cache (out of 48 required - the processor's own cache is not taken into account, the directory is used only for searching in neighboring processors)
- The state of one cache line is described by 6 bits (valid, linkA, linkB, linkC, modified (2)), which is enough to implement MOESI protocol on 4 processors, MOSI actually works. If we take into account that a directory item has 2 cache lines, there are 16 bits per line.
What can the proposed method of local data give in the case of SMP? Recall, here we analyze the case of thread moving to another processor, since we have already analyzed the movements inside one processor and decided that they do not require special actions.
It is also worth noting that context switching is a rather expensive operation, just saving / restoring registers takes hundreds or even thousands of cycles. The contribution of the losses associated with the loss of the cache is estimated [34] in a wide range from units to thousands of microseconds, depending on the task. We also point out that the duration of the quantum of time allocated by the system to a thread before it is forcedly displaced is measured in tens or even hundreds of milliseconds.
As we noted earlier, two “orthogonal” variants are possible:
- Cache Evolution We do not make any additional efforts; cache lines with L and LM states are gradually reset at the old place and appear on the new one. The difference with existing systems is that the local cache at the old place is deleted after reading, and does not remain in the S state.
- Cache with “relocation”. Suppose we have some way to guarantee thread that its local data can only be in the memory or cache of its processor. In this case, local data does not participate in interprocessor snoop distribution and is not represented in the directory, if it exists. The efficiency of the directory (which now serves only global data) increases at the same size.
How can you arrange it?- , , .
- thread' L I , .
- LM , , . .
- . thread' , thread' .
, “” “”. - , N- FlushOpt . L ( ) .
, , . , , thread. thread, , . , — , , , - ( ). , SMP, .
cc-NUMA
Since centralized ownership of resources (eg, memory) has natural size limits, building larger systems requires fragmentation. The system consists of the so-called. nodes, each of which is usually arranged in the spirit of SMP. For communication between the nodes, there are special tools, the principal difference is the fact that memory access is now not uniform - the memory on its node is at least tens of percent faster [31.32].
The shared cache has now become a three-level - on its processor - on its node - on a foreign node. Accordingly, the cost has increased. Snoop protocols for the entire system are no longer possible, in one form or another, a directory is required.
From the point of view of the directory, this situation is fundamentally different from the SMP in that the directory itself has become two-level. Those.Now the line can be shared not only with a different processor, but also with a different node. This division is necessary due to the fact that there can be a lot of processors - hundreds or thousands, it is impossible to reserve a discharge for each of them in the descriptor of each cache line. In addition, the cost of access in these situations is also different.
Therefore, it is necessary to clearly separate other people's nodes from their processors. For example, in the E-4C + directory there are three digits for specifying with which foreign processors we divide the line, i.e. the maximum number of cores in the system is 8x4. And if we reserve 6 bits - 3 for processors of our node and 3 for other nodes, we get 4x4x8 cores. Now, when receiving data from a remote node, there is no need to make a broadcast, you can refer to a specific node, and then it will figure out on which processor and in the cache of which kernel the line we need is located.
From the point of view of the coherence protocol, the MESI variants are mainly used, taking into account the fact that line splitting can occur at three levels - (core-processor-node). It should be said that there are not so many players in the NUMA-systems market and they are leading a positional war in the patent minefield.
What can be said about the proposed method of local data on the background of ccNUMA? Those factors that spoke in favor of “moving” the cache became even more significant.
- Since it so happens that the OS has transferred a thread to a non-native node, we cannot do anything about it, it is worth trying to minimize losses. You can, of course, try to set affiniti for the thread ( 1 or 2 ), but this is more a hint to the scheduler.
- — migrate_pages , , .
- , , . “” , (.. ) , , , , . “” , .
- , , . , “ , ”.
findings
Here is an unexpected application of the now-forgotten idea of tagged memory. As it turned out, it can be useful in SMP & NUMA systems. For this, however, synchronous actions are required in three areas:
- It is the responsibility of the programmer to select a class of data. True, if he does not do anything, everything will just remain as it is now.
- Processor developers should “stretch” tags through the entire system. Nothing is impossible in this - the developers of the current “Elbrus” in the 00s, the Soviet “Elbrus” in the 70s, the non-Soviet “Barrows” in the 60s could do it ... Plus, changes in the coherence support protocol.
- The operating system should make some effort when forcing / restarting threads. And “stretch” the tags through the system, which was also successfully succeeded.
Synergy from all this will reduce the exponential level and delay the communication storm. Perhaps the game is worth the candle.
Sources
[1] B5000
[2] Wiki Burroughs_large_systems
[3] The Architecture of the Burroughs B5000; Alastair JW Mayer
[4] «»
[5] « „“ ; .., .., .., .., .., .., ..
[6] ; ..
[7] ENERGY-EFFICIENT LATENCY TOLERANCE FOR 1000-CORE DATA
PARALLEL PROCESSORS WITH DECOUPLED STRANDS; NEAL CLAYTON CRAGO
[8] A Task-centric Memory Model for Scalable Accelerator Architectures
John H. Kelm, Daniel R. Johnson, Steven S. Lumetta, Matthew I. Frank∗
, and Sanjay J. Patel
[9] In MIPS, what are load linked and store conditional instructions?
[10] An Evaluation of Snoop-Based Cache Coherence Protocols;
Linda Bigelow Veynu Narasiman Aater Suleman
[11] Intel Sandy Bridge —
[12] Interactive Reversible E-Learning Animations: MESI Cache Coherency Protocol
[13] «‑8C» ; .. , .. -, ..
[14] ; .. , ..
[15] A Brief History of the Rice Computer
[16] Optimizing the MESI Cache Coherence Protocol for Multithreaded Applications on Small Symmetric Multiprocessor Systems; Robert Slater & Neal Tibrewala
[17] Cache Coherence Protocols: Evaluation Using a Multiprocessor Simulation Model; JAMES ARCHIBALD and JEAN-LOUP BAER
[18]
«-4+»; .. , .. , .. , ..
[19] «-4+»; V.N. , .. , ..., . ..
[20] MIPS64 Architecture For Programmers Volume III: The MIPS64 Privileged Resource
Architecture
[21] Memory Barriers: a Hardware View for Software Hackers; Paul E. McKenney
[22] MIPS
[23] « » ?
[24] CMP Directory Coherence: One Granularity Does Not Fit All; Arkaprava Basu, Bradford M. Beckmann* Mark D. Hill, Steven K. Reinhardt
[25] ; Mikhail Isaev.
[26] POWER7: IBM's Next Generation Server Processor
[27] CACHE COHERENCE DIRECTORIES FOR SCALABLE MULTIPROCESSORS; Richard Simoni
[28] Pat Conway, Nathan Kalyanasundharam, Gregg Donley, Kevin Lepak, Bill Hughes. Cache Hierarchy and Memory Subsystem of the AMD Opteron Processor.
[29] Design of Parallel and High-Performance Computing: Torsten Hoefler & Markus Püschel
[30] Nehalem-EX CPU Architecture Sailesh Kottapalli, Jeff Baxter
[31] NUMA- Linux
[32] NUM, NUM NUMA
[33] What Every Programmer Should Know About Memory
[34] Quantifying The Cost of Context Switch; Chuanpeng Li,Chen Ding, Kai Shen
[2] Wiki Burroughs_large_systems
[3] The Architecture of the Burroughs B5000; Alastair JW Mayer
[4] «»
[5] « „“ ; .., .., .., .., .., .., ..
[6] ; ..
[7] ENERGY-EFFICIENT LATENCY TOLERANCE FOR 1000-CORE DATA
PARALLEL PROCESSORS WITH DECOUPLED STRANDS; NEAL CLAYTON CRAGO
[8] A Task-centric Memory Model for Scalable Accelerator Architectures
John H. Kelm, Daniel R. Johnson, Steven S. Lumetta, Matthew I. Frank∗
, and Sanjay J. Patel
[9] In MIPS, what are load linked and store conditional instructions?
[10] An Evaluation of Snoop-Based Cache Coherence Protocols;
Linda Bigelow Veynu Narasiman Aater Suleman
[11] Intel Sandy Bridge —
[12] Interactive Reversible E-Learning Animations: MESI Cache Coherency Protocol
[13] «‑8C» ; .. , .. -, ..
[14] ; .. , ..
[15] A Brief History of the Rice Computer
[16] Optimizing the MESI Cache Coherence Protocol for Multithreaded Applications on Small Symmetric Multiprocessor Systems; Robert Slater & Neal Tibrewala
[17] Cache Coherence Protocols: Evaluation Using a Multiprocessor Simulation Model; JAMES ARCHIBALD and JEAN-LOUP BAER
[18]
«-4+»; .. , .. , .. , ..
[19] «-4+»; V.N. , .. , ..., . ..
[20] MIPS64 Architecture For Programmers Volume III: The MIPS64 Privileged Resource
Architecture
[21] Memory Barriers: a Hardware View for Software Hackers; Paul E. McKenney
[22] MIPS
[23] « » ?
[24] CMP Directory Coherence: One Granularity Does Not Fit All; Arkaprava Basu, Bradford M. Beckmann* Mark D. Hill, Steven K. Reinhardt
[25] ; Mikhail Isaev.
[26] POWER7: IBM's Next Generation Server Processor
[27] CACHE COHERENCE DIRECTORIES FOR SCALABLE MULTIPROCESSORS; Richard Simoni
[28] Pat Conway, Nathan Kalyanasundharam, Gregg Donley, Kevin Lepak, Bill Hughes. Cache Hierarchy and Memory Subsystem of the AMD Opteron Processor.
[29] Design of Parallel and High-Performance Computing: Torsten Hoefler & Markus Püschel
[30] Nehalem-EX CPU Architecture Sailesh Kottapalli, Jeff Baxter
[31] NUMA- Linux
[32] NUM, NUM NUMA
[33] What Every Programmer Should Know About Memory
[34] Quantifying The Cost of Context Switch; Chuanpeng Li,Chen Ding, Kai Shen
Source: https://habr.com/ru/post/328542/
All Articles