Practical MySQL optimization: measure to speed

Petr Zaitsev (Percona)
Today we talk about performance.
We will look at how to approach MySQL correctly, as well as look at some practical approaches to this matter. Why do I think this is important? The fact is that when you have a specific problem, you want, for example, to ask: "And what should I set the cache size in MySQL?". Such a question can always be entered into Google or Yandex, and get a reasonable answer to it. But how to get an answer about general, about the analysis and optimization scheme of MySQL? It is much more difficult.
')

The first thing you need to know about is that the performance of MySQL itself is not really important. And here I look, the young man from behind smiles: “How is that? Important, sort of. What are we talking about if it is not important? "

In fact, your users, your boss is important, first of all, the performance of your application, which uses MySQL, and may use some other system. And this is something that makes sense to focus on, because if you look at the problem from the point of view of the application, then some other, broader approaches open up. Maybe MySQL does not use in some cases, or use it wrong.

It is also important that application performance is always important. In some cases, I speak with people, and they tell me: “Here, you know, this is our report. Its performance is not important to us, it takes us a minute, two or three - everything will suit us. ” But if you ask them: “Guys, and if this report takes you a month, will that suit you?”. They say: "No, of course, not satisfied." So, performance is important, just in the minds of some people, important performance means that we can execute any request in milliseconds or in seconds. People often do not think that even those processes that take minutes and hours can also be performance critical. And why is this important? Because often, when we do some database algorithms, write some queries, their complexity can return non-linearly with respect to the amount of data. Those. it may be that our data volume has increased only 10 times, and the speed of the query has increased 100 times. Creating a surprise and surprise that we did not expect such brakes at all.

What else is important? That performance and applications may not necessarily be related to MySQL. With this, I also have an interesting case. I remember coming to the client, looking at their MySQL server. And, it seems, everything is fine with them, there are no long queries, the server load is less than 10%, and I ask them: “Guys, why do you think that this is MySQL in general?” - “Well, this is how old we are we are engaged, always all the problems of performance - it is always with MySQL, so we go there and dig. " Sometimes yes, but in some cases not.
It is also important that even if there are problems with MySQL, often the solutions may not be related to MySQL. For example, many of you know Andrei Aksenov from Sphinx. Most of his business, especially in the early years, is to save MySQL-users who tried to use MySQL full text search for a long time and persistently. But this little elephant does not fly, how not to try with it, not to try to make it work, it will not scale. In this case, for such tasks as full-text search, using Sphinx is a more reasonable solution.

And there are actually a lot of such tools now that allow solving various tasks that MySQL does not solve very well. Those. Full text search, there is Sphinx elastic Search - another option. For some tasks, Redis or Tarantool is much better suited. If we are talking about data analytics, then Hadoop or Vertica solution, or some systems that normally process data in parallel, is often appropriate. Because MySQL performs any query only in one thread on one server, which, of course, does not scale to large volumes at all.

When we talk about performance, what are we thinking about? First of all, we think about response time. Why? Because if you look at your selfish user, this is what he thinks about first of all. Those. if I go to the website or work with the application, and this application answers me quickly, then that's all that worries me. Your every queries per second, the number of requests per second and other user's garbage are of little interest.

Those. First of all, we look at the application and want it to respond to the user with a response time, which can be different for different applications for different tasks. There is no definite figure that the response time in half a second is good, and anything more is bad.
But if we are talking about real-world applications, then often we consider not only the response time, but also other things. The first question is that we want this response time to be stable. Those. I encounter very many cases that the problem is not that the response time is always bad, but that sometimes something happens to the system or outwardly that worsens it. For example, people often complain that everything works well for me, but when I run a backup, everything starts to be bad for me. It is necessary to follow such things. Or it is often associated with some things like a download spike, i.e., maybe the website was shown on some well-known television program, or someone else mentioned it, traffic rushed, the system fails.
The next question we often ask about performance is scalability. Many, many applications start with fairly small systems. A small amount of data, a small amount of users, they have plans to grow. It is important for us that those algorithms, those requests, those designs, schemes that we use, not only work now, but also work on the application of the future. And some of the approaches that are most optimal today, on the current volume of data, may be good, but do not scale.
And the third point is efficiency, which is also important. Efficiency, both in terms of resource use and in terms of the people who are required to create this architecture. For example, an interesting option with Hadoop. Now Hadoop is already better, but traditionally, when Hadoop was just beginning, it skated to thousands and thousands of nodes. But if we compare the efficiency, for example, MySQL with Hadoop, then MySQL on one node could do the same thing as Hadoop by ten. And it is clear that if the data volume is small enough, then using MySQL would be much more efficient. But if we need something that does not fit onto one server, then from the Hadoop point of view, we can run 1000 or 10 000 nodes. We can't do that with MySQL.
In terms of our scalability, we have already talked about the load, about the size of the data, and even more important is scalability in terms of infrastructure. What is there to say? That depending on what mode you are in, this or that infrastructure may be available to you. For example, in many cloud networks we cannot scale up so easily. It’s hard to say: “I want to put a server in which we will have 64 cores, 1 TB of memory, 4 very-very fast flash cards, so that I can receive 10 TB of local fast flash”. If you work in your data center, and you have a choice of infrastructure, you can get it, you can connect such a server with 40 GB Ethernet, or even not one. If you are working in the cloud, then you may have completely different restrictions with which you have to work.

The next point we often face. When we develop real-world applications, we often have performance - this is an important thing, but it is not the only thing that we have to take care of. For example, security. Security, traffic encryption usually does not improve performance, but, on the contrary, these are things that can degrade performance that you have to put up with.
Handling is another moment. Those. often the most optimized code and structures - you will understand its figs later. In many cases, we find that people do not want to super optimize performance if this makes the code too complicated. And there are other different things to be reckoned with. For example, there may often be some audit needs, in connection with which any changes to the data must be logged, which adds additional features that cost us something in terms of performance.

The next point is worth mentioning. This is what performance is the one thing that can be improved endlessly. There is no system that is maximally optimized, and in which, having spent a lot of money and time, it is still impossible to improve performance by at least a few percent. This means that we need to always know when to stop, otherwise we will simply waste resources completely useless. This means that we need to somehow determine what efficiency we need, system performance, etc. And when it is reached, we can stop.
Next moment. Moving on to MySQL. We said that the response time of the system is important. Now let's see what MySQL, in general, does for its users. And it makes it very simple - we execute queries on MySQL, selects, updates, inserts, and it responds to us after some time. And everything related to the performance of MySQL can be characterized by this response to queries.
It is clear, at different loads, with different data volumes, etc. But if we look at these requests and look at their response time and focus on this in terms of optimization, we will get the results that can be obtained.
When do we talk about MySQL optimization? Probably worth saying one thing that is not on this slide. This is about the fact that the best question to optimize something is not to do it. Obviously, you heard a lot from anyone, but what is interesting from the point of view of MySQL is that if I come to most people, we will take the application to turn on the MySQL-log and load the page. In most cases, I will find several requests that will be repeated. You know that they can be easily removed because the second query is useless. Often I will see that the data is requested from the database and the application is not used. But why? “Well, here, I have this class initialized there, it raises everything from the database, just in case, but in fact we don’t use it.” Very often in applications a heap-heap of garbage is made that nobody needs. But what about when we focus on optimization, what do we often work on? The first, very simple point is that we want our questions to run faster, another thing is we want them to use less resources, for example, less memory, or with the help of compression we can optimize the system so that it uses less disk space. Or better scalability in terms of iron, in terms of data size, etc.

If we are talking about optimization and a general approach, we often look at two things. The first is transaction optimization. For example, you have an application, and someone says: “You know, we have such a search function or an archive that slows down, works slower than we would like.” We can look specifically at this function, what it does queries on MySQL, and optimize them. Another option is to say, but let's, we will optimize the application in general. Then we can take a look at all the queries that come to MySQL, see which ones are the slowest, which use the most resources, and when we optimize them, it is obvious that our system will work faster in general. But at the same time, if we use the second approach, we have no guarantees how optimized our braking process will be, because maybe it doesn’t create much pressure, maybe it’s some kind of analytics that the big boss looks at. once a day, and it is 0.01% of the load, but, nevertheless, it is very important.

And it is clear that from the point of view of overall optimization, we look at requests, we prioritize them and further optimize them.

In terms of requests. As I already said, the first question from the point of view of requests: can we avoid these requests? Because often some requests are useless. The second question: can we change these requests so that they do less work? What does less work mean? This means that they scan fewer lines, read less data from disk, etc. - we call all this the simple word “work”.
What example can we have? We have a query that runs without an index, it does a lot of work. The index we added - the query does less work. When it really is that simple, add an index or change MySQL settings. In other cases, it may be something more complicated, for example, we may have a bad data scheme that does not allow us to add an index so that the query is executed quickly. Then we have to change the data schema, not just the query indexes. Sometimes we have to use some other approach, for example, caching. We can cache data, we can make some kind of summary table, a table into which we have progressed all our results, instead of bluffing the data many, many times every second.

The next optimization question is: what is important? The first is that you should not look only at the average query time. Because the average execution time of any query is rarely a problem, first of all, the problem begins with some, I do not want to say extreme conditions, but close to that. For example, I remember the guys from Flickr (a relatively old, but large hosting for pictures) told me that they had problems when a friend sent them 1 million pictures through the API. It is clear that what worked for normal users is normal, in the category of 1 thousand, 100 pictures, with 1 million pictures not working anymore. From the point of view of the average request, the average user, it would not seem.
The next point is that we also want to look at trends over time, because some problems occur cyclically, maybe this is due to monthly billing, maybe this is due to the fact that you delete old data once a week, and it can show Problems.
Again, when we look at requests, we should think about the future. Especially in development systems. I very often encounter the fact that developers test queries on some small databases in their test configuration and do not read the explain in MySQL well. In this case, when their requests are laid out on the production or a little later, when the data starts to grow sharply, it all breaks down. It is necessary to learn to read explain and think, and how these requests will work in the future.
Next moment. It is clear that we want to use fewer requests. Even if we analyze the same number of rows, the fewer queries we can use, the better. Because with each request we add network response time, we add an additional overhead to parsing requests, to check privileges and so on. We also want to read and modify as little data as possible. Those. If we can fulfill the request of limit 10, for example, then this is much better than reading all the data, just read the first few lines in the application, and throw out the rest.
The same goes for the fact that it is better to read only those columns in the database, those columns that the application actually uses. Because MySQL can use other advanced optimizations in these cases and execute queries more efficiently.
Farther. The less we can process data during the execution of queries, the better. Again, heavy queries that make some complex aggregations for each user every time are not very good for large aggregations, it’s better to see how we can create them like cache tables, etc.
What can you look at? What interesting metrics we have? The first is that we can see how much data MySQL analyzed regarding how much it sent them to the client. This metric is easy to get from MySQL. There is for each query, for example, in the slow query log data Rows_sent and Rows_examined. The relationship between them is what we want to look at. If we have an attitude anywhere from 1 to 10, the application as a whole is usually well optimized. If we process 100, or even 1 thousand, for each line we send from MySQL, then most likely we have many opportunities for optimization.
The next point is to see how much data we actually had sent from MySQL regarding how much was used by the application. Here, unfortunately, there are no metrics that MySQL gives, because MySQL gave the data, and it no longer knows how you use them. But often you can look at it yourself, at least for the most heavy queries that return a lot of data. Those. If you counted 1 million lines per application, you should think well, and do you all use them there? It is unlikely that one million elements are shown on one page. Maybe they are somehow aggregated and in this case it is often better to do this work on a database.

Next moment. As we have said, it is not always possible to optimize queries, simply by adding an index, we often have to change the circuit more dramatically, so it often makes sense to look at the optimization of the schema and query optimization together. And there are two things here:
- these are small schema optimizations - add an index, maybe change a column type or something else, change storage enigne in MySQL;
- a strong change in the design and the whole architecture, which is also sometimes necessary, but it usually requires much more serious planning. Those. if you do a complete reengineering of your circuit, then it takes considerable time.
In terms of database schema. You need to know how indexes work. I give a link to my presentation about this.
Next moment.When you are developing a scheme, think about what requests you will have to be executed. Very often, I see what people do, in the code they use IR tools, which makes it completely abstract and “academically” correct database structure, which, unfortunately, does not work. You can start with this, but it is rarely possible to finish it. We need to look at how your requests work on this, and think further. And you can see different techniques, Partitioning & Sharding, normalization, data denormalization, etc. These things need to enter into Google and read about them.

Other things that we also have important - of course, infrastructure, OS, MySQL version, MySQL configuration. And we will talk about this in a bit more detail.
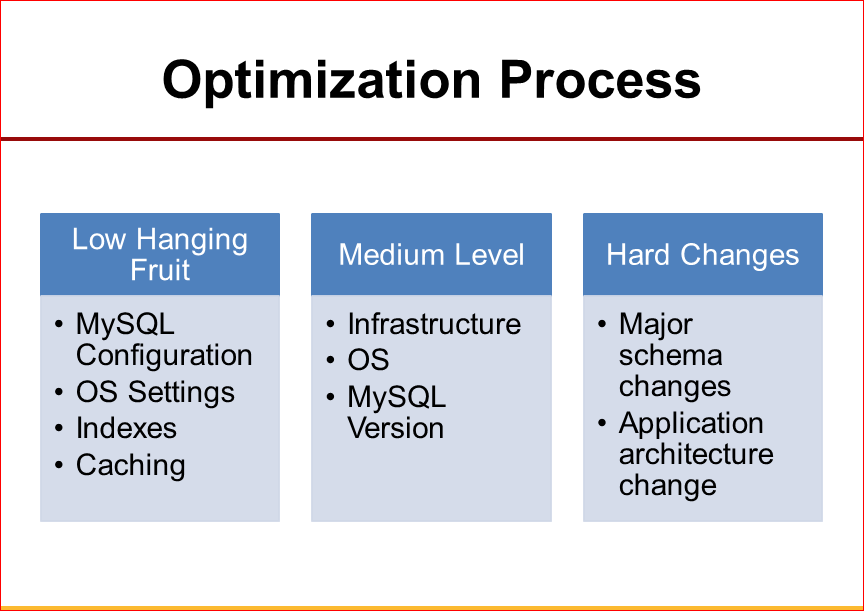
If we have a system that needs to be optimized, how do we approach this when we are often called in terms of consulting? Firstly, there are simple things that can be changed very quickly, and this is often enough. Change the MySQL settings, maybe the OS, add some indexes, maybe turn on some caching - and these are things that can often be done in just a matter of hours.
The next question, which is more complicated, if we need to buy a new hardware or do some reconfiguration of the network, change the OS to a newer one, or upgrade MySQL. These are more complex things that take days.
And, finally, there are times when things are so bad, when even this is not enough. Then we need to go to the heavy artillery, we may have to completely redo the database schemas, or we have to change the architecture of the application, to say that “you know, we now do sharding, for this we decide not to use MySQL” and that .d
If you look at the many applications that have grown, they often go through such steps.
About the infrastructure. Here you need to understand what options you have, whether you can scale with one node for a while, or you need to switch to an architecture that can run on many small machines, such as, for example, often in cloud structures.
What we have in terms of iron? These components are important to us:

From the point of view of the processor. It is clear that now server processors are Intel. C MySQL, we see that the most commonly used system with two sockets for processors. What else is important? Since MySQL can use only one processor core for a single query, often for us fast processors are more important than processors with many, but slow, cores. Often this is forgotten. And also look at such a thing as turboboost, because modern processors, if not all of them are used for bark, but only one or two, then they can often work at a much higher clock frequency. And often it’s not the processor’s nominal frequency that is important for us, but to what extent they will do turboboost, because if we fulfill heavy requests, but who use only one bark, this will limit the performance.
Memory.When we use database memory, we use it for cache. Therefore, if you have a lot of data, then we want a lot of memory too. Here it makes sense to think about - what is the ratio between the size of the database and memory. Do we have all of it or some part of it? It also makes sense to look at what part of the actively used data you have in memory. It is clear that often we have a large database, but its serious part is used very rarely, it is expensive to keep it in memory, so when I look at how well the database is stored in memory, I don’t really look at the ratio of database size in memory, but, rather, on how many I / O operations occur. Especially for reading, because if we have all the actively used database in memory, then read operations,which in the disk subsystem, we practically will not.
The following graph is interesting for you:
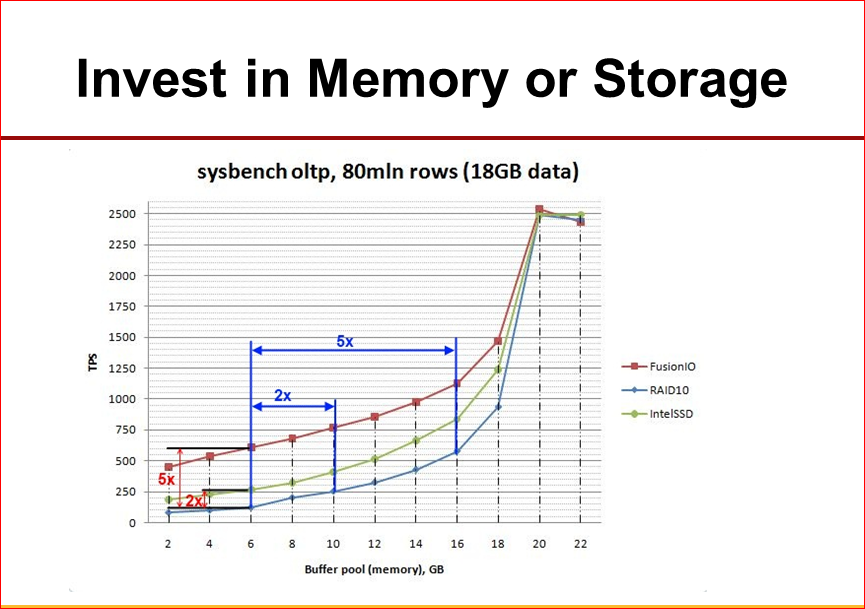
Here we looked at the behavior of a certain synthetic benchmark with different amounts of memory and different configurations of the drive system. Those.we have blue - this is RAID, the slowest, red is the fastest FusionIO. What we see interesting? If the database is bad in memory, then a quick stack will give us a very big advantage, that is, we see that the difference is 5 times below. But when our data gets better and better in memory, then the difference between fast and slow storage is reduced. From this conclusion: if we have a chance to drive our working set into memory, then it is better to invest in memory. Have some flush, but maybe not the fastest. But if your data volume is already such that it is still not possible to drive into memory, then in this case it often makes sense to have some less memory, but to have a faster stack.
What should I say about storadzh? It is clear that now there are many different solutions. Probably, I will say only one important thing, that now, if you are using MySQL or other OLT databases, does it make sense to use Flash? about the wheels that are spinning, forgot.
From the point of view of the network, the performance of the MySQL server is most often limited by the response time, and not by the throughput, especially given the fact that people often make quite a few queries in MySQL for each page. Often there are hundreds of requests, and in some cases I have even seen tens of thousands. From this conclusion that we want the best possible response time at our best, which means that we want our MySQL server and application server to speak as much as possible directly. The less network hops, the better. Placing, for example, an application server in one place, and a database in another, in different cities, on different continents, is a very bad idea, even if you are told that “we have our own optical fiber between them”. then Gbit. Because the speed of light is finite, and when we speak of microns or fractions of ms,she is already beginning to influence correctly.
The choice of operating system. MySQL is most successfully used on Linux. Does anyone use MySQL on anything else? FreeBSD, Windows server. But most major projects use MySQL after all on Linux. In this case, it makes sense to use the server version of this OS, which is optimized for this, and which will not change every three months, and which must be constantly upgraded. And quite new, especially if you use new hardware, because everything related to flash, as far as support for the functionality of new processors is all supported in newer kernels, new distributions are much better than in old ones.

What is interesting from the point of view of Linux. In fact, its default settings for many MySQL loads are quite adequate. It is clear that if we go to some sort of Google, Facebook - the last 3-5% of performance is important for them, they invest a lot in tuning the kernel too, or often even compile it on purpose, or patch it, but for most people it is not so important. The file system - most often, we see, is used either EXT4 or XFS. At different loads, either one or the other may
show better performance, but these two file systems. And the link I talked about this in more detail.

The next point is the MySQL version. What you need to know?That newer versions of MySQL usually improve performance. There are exceptions, i.e. if we use a single client thread and use very simple queries, in fact, since MySQL is getting thicker, trying to do more query optimization, the performance on such queries may not be significant, but it will be slower in new versions of MySQL. Last week MySQL 5.7 was released, which is very cool. There are a lot of improvements, both related to the optimizer, and with general scalability, i.e. if you want maximum MySQL performance, it makes sense to look at it, but when you upgrade, you can wait for Percona Server 5.7, which will also be released after a certain number of months.

MySQL configuration. It is important here that the defaults in the MySQL configuration are bad. Those.it is impossible to work with defaults for MySQL. But at the same time, do not look at him: “Fir-sticks! There are 400 different settings here. ” You will most likely need to fix 5-10-20 in order to get adequate
performance. Again, you can watch my slides or webinar with more details on this.

If you are too lazy to look there, you can take these settings, enter them into Google, and you will easily find the answers to what you need to put in your configuration.

The next point is in terms of the process.
There are two important things:
- First, developers need to be fed, because developers often make bad requests, which, when we post the code for production, create problems. Those. , , -, , , , . .
- , , , , , , - . , - . , - , , MySQL , , , . - , , , , , , , , , - , , Linux - . , , .

Next moment.Interestingly, with all these settings we have, no matter what we change - hardware, OS, MySQL settings - it always somehow affects query performance. Therefore, if you have some kind of monitoring, that you are looking at the performance of your requests regarding time, then you will always easily catch if something suddenly becomes bad.

So these are the tools that can be used for this.

I will show one option that we did recently. This is an integration from MySQL performance Schema with Graphite.
Link - http://bit.ly/1KQSNWC
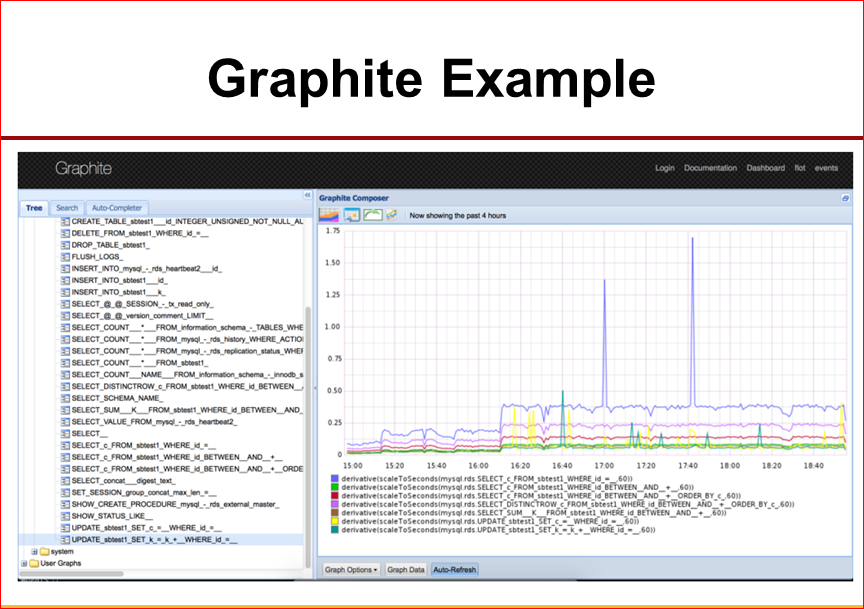
Here, you see, you can see the total response time for any MySQL query, which is very useful, because if something starts to be bad for us, we will see that this query has moved, for example, a plan, now it takes us abruptly, 10 times the total execution time.
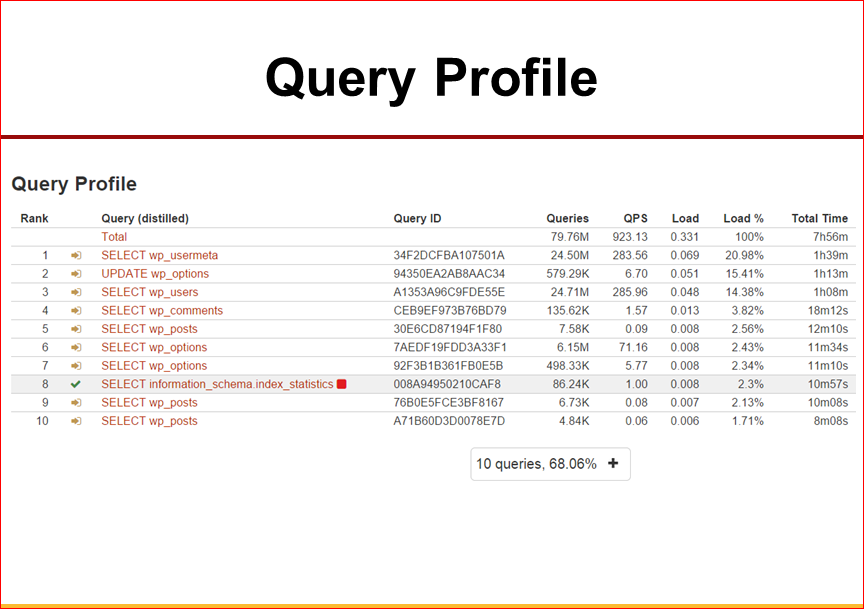
This is about our importance. Look at the speed of application performance. And here are some hints how you can optimize them.


Link - http://www.meetup.com/moscowmysql/

Link - http://bit.ly/PL16Call
Contacts
» Pz@percona.com
This report is a transcript of one of the best speeches at the conference of developers of high-loaded HighLoad ++ systems.
Within the framework of the professional festival " Russian Internet Technologies " we conduct a whole section on databases. Now there are 16 reports in it, from which we need to choose 9. Here is what we have already chosen:
- Postgres vs Mongo / Oleg Bartunov (PostgreSQL Professional);
- Cards, money, two backups: data reliability / Nikolay Ikhalainen (Percona);
- Monitoring and debugging MySQL: maximum information with minimal losses / Light Smirnova (Percona);
- Overview of promising databases for highload / Yuri Nasretdinov.
Join us!
Source: https://habr.com/ru/post/328458/
All Articles