PostgreSQL indexes - 3
In the first article, we looked at the PostgreSQL indexing mechanism , in the second, the access methods interface , and now we are ready to talk about specific types of indexes. Let's start with the hash index.
Hash
Device
General theory
Many modern programming languages include hash tables as the base data type. Outwardly, it looks like a regular array, but the index is not an integer, but any data type (for example, a string). PostgreSQL hash index is similar. How it works?
As a rule, data types have very large ranges of allowable values: how many different rows can theoretically be represented in a text type column? At the same time, how many different values are actually stored in a text column of a table? Usually not much.
')
The idea of hashing is to match a value of any data type to a small number (from 0 to N −1, total N values). This mapping is called a hash function. The resulting number can be used as an index of a regular array, where and add links to table rows (TID). Elements of such an array are called hash-table baskets - several TIDs can be in one basket if the same indexed value is found in different rows.
The hash function is the better, the more evenly it distributes the initial values to the baskets. But even a good function will sometimes give the same result for different input values - this is called a collision. So, TIDs corresponding to different keys can appear in one basket, and therefore TIDs obtained from the index should be rechecked.
Just as an example: what hash function can you think of for strings? Let the number of baskets be 256. Then, as the basket number, you can take the code of the first character (say, we have one-byte encoding). Is this a good hash function? Obviously not: if all the lines start with the same character, they all fall into the same basket; there is no talk of uniformity, you have to recheck all the values and the whole point of hashing is lost. What if we add up the codes of all characters modulo 256? It will be much better, although also far from perfect. If you're wondering how this hash function actually works in PostgreSQL, see the definition of hash_any () in hashfunc.c .
Index device
Let's go back to the hash index. Our task is to quickly find the corresponding TID by the value of a certain data type (index key).
When inserted into the index, we calculate the hash function for the key. Hash functions in PostgreSQL always return an integer type, which corresponds to the range of 2 32 ≈ 4 billion values. The number of baskets is initially equal to two and increases dynamically, adjusting to the amount of data; basket number can be calculated by hash code using bit arithmetic. In this basket and put our TID.
But this is not enough, because TIDs that correspond to different keys can get into one basket. How to be? It would be possible to write to the basket along with the TID also the initial value of the key, but this would greatly increase the size of the index. So, to save space in the basket, it is not the key itself that is saved, but its hash code.
When searching in the index, we calculate the hash function for the key and get the number of the basket. It remains to iterate over the entire contents of the basket and return only suitable TIDs with the necessary hash codes. This is done efficiently, since the hash-TID pairs are stored in an orderly manner.
But it may happen that two different keys will not just fall into the same basket, but will have the same 4-byte hash codes - no one has canceled collisions. Therefore, the access method asks the general indexing mechanism to control each TID, re-checking the condition on the table row (the mechanism can do this at the same time with a visibility check).
Page organization
If you look at the index not from the point of view of planning and executing the query, but through the eyes of the buffer cache manager, it turns out that all information, all index records should be packed into pages. Such index pages are placed in the buffer cache and pushed out from there in the same way as tabular pages.
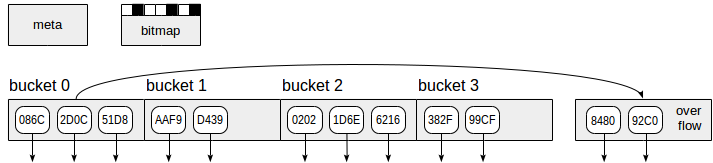
The hash index, as seen in the picture, uses four types of pages (gray rectangles):
- Metapast (meta page) - zero page, contains information about what is inside the index;
- Basket pages (bucket page) - main index pages, store data in the form of “hash code - TID” pairs;
- Overflow pages (overflow page) - arranged in the same way as the pages of baskets, and are used in the case when one page for a basket is not enough;
- Bitmap pages - they mark the released overflow pages that can be used for other baskets.
The down arrows from the index page elements symbolize TIDs — links to table rows.
With the next increase in the index, two times more baskets (and, correspondingly, pages) are created at the same time than the last time. In order not to allocate at once such, potentially large, number of pages, in version 10 they made a smoother increase in size. Well, overflow pages are allocated just as needed and are tracked in the bitmap pages, which are also highlighted as needed.
Note that the hash index does not know how to decrease in size. If you delete part of the indexed rows, once selected pages are no longer returned to the operating system, they are only reused for new data after cleaning (VACUUM). The only way to reduce the physical size of the index is to rebuild it from scratch with the REINDEX or VACUUM FULL command.
Example
Here is an example of creating a hash index. In order not to invent our tables, we will continue to use the air traffic demonstration database , and this time we will take a table of flights.
demo=# create index on flights using hash (flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
An unpleasant feature of the current implementation of the hash index is that actions with it do not fall into the log of proactive recording (which PostgreSQL warns us about when creating the index). As a result, hash indexes cannot be restored after a failure and do not participate in replication. In addition, the hash index is significantly inferior to the B-tree in its universal application, and its effectiveness also raises questions. That is, to use such indexes now has no practical meaning.
However, the situation will change this fall with the release of the tenth version of PostgreSQL. In it, the hash index finally provided support for the journal and further optimized the memory allocation and efficiency of simultaneous work.
Hash Semantics
Why has the hash index existed almost from the very birth of PostgreSQL to the present day in a state in which it cannot be used? The fact is that the hashing algorithm is used in the DBMS very widely (in particular, for hash connections and groupings), and the system needs to know which hash function to apply to which data types. But this correspondence is not static, it cannot be set once and for all - PostgreSQL allows you to add new types on the fly. Here in the method of accessing the hash, such a correspondence is contained, and it is presented as a binding of auxiliary functions to operator families:
demo=# select opf.opfname as opfamily_name,
amproc.amproc::regproc AS opfamily_procedure
from pg_am am,
pg_opfamily opf,
pg_amproc amproc
where opf.opfmethod = am.oid
and amproc.amprocfamily = opf.oid
and am.amname = 'hash'
order by opfamily_name,
opfamily_procedure;
opfamily_name | opfamily_procedure
--------------------+--------------------
abstime_ops | hashint4
aclitem_ops | hash_aclitem
array_ops | hash_array
bool_ops | hashchar
...
Although these functions are not documented, they can be used to calculate the hash code values of the corresponding type. For example, for the text_ops family, the hashtext function is used:
demo=# select hashtext('');
hashtext
-----------
127722028
(1 row)
demo=# select hashtext('');
hashtext
-----------
345620034
(1 row)
Properties
Let's look at the properties of the hash index that this access method reports about itself to the system. We quoted the last time ; now we confine ourselves to the results:
name | pg_indexam_has_property
---------------+-------------------------
can_order | f
can_unique | f
can_multi_col | f
can_exclude | t
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | t
bitmap_scan | t
backward_scan | t
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | f
search_array | f
search_nulls | f
The hash function does not preserve the order relation: from the fact that the value of the hash function of one key is less than the value of the function of another key, no conclusions can be drawn about how the keys themselves are ordered. Therefore, the hash index in principle can support a single operation “equal”:
demo=# select opf.opfname AS opfamily_name,
amop.amopopr::regoperator AS opfamily_operator
from pg_am am,
pg_opfamily opf,
pg_amop amop
where opf.opfmethod = am.oid
and amop.amopfamily = opf.oid
and am.amname = 'hash'
order by opfamily_name,
opfamily_operator;
opfamily_name | opfamily_operator
---------------+----------------------
abstime_ops | =(abstime,abstime)
aclitem_ops | =(aclitem,aclitem)
array_ops | =(anyarray,anyarray)
bool_ops | =(boolean,boolean)
...
Accordingly, the hash index can not produce ordered data (can_order, orderable). For the same reason, the hash index does not work with undefined values: the operation "equal" does not make sense for null (search_nulls).
Since keys are not stored in the hash index (but only key hashes), it cannot be used for index access exclusively (returnable).
Multi-column indexes (can_multi_col) this access method does not support.
Insides
Starting from version 10, the internal structure of the hash index can be viewed through the pageinspect extension. Here is what it will look like:
demo=# create extension pageinspect;
CREATE EXTENSION
Metastpage (we get the number of rows in the index and the maximum number of the used cart):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx', 0 ));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx', 0 ));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
Basket page (we get the number of current lines and lines that can be cleared):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx', 1 ));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx', 1 ));
live_items | dead_items
------------+------------
407 | 0
(1 row)
And so on. But to understand the meaning of all available fields is unlikely to work without examining the source code. With such a desire, it’s worth starting with the README .
Continued .
Source: https://habr.com/ru/post/328280/
All Articles