DevOps in Enterprise and Finance. Is there life on Mars

Artem Kalichkin (CFT)
My name is Artem Kalichkin, I work in the company "Center for Financial Technologies", which occupies a leading position in the production and development of software for the banking and financial sector. I hold the position of director of maintenance.
Is it possible to use the practices and approaches of DevOps, CD in a corporate environment? What are the features? SPARC + Unix (Solaris)? Vertical scaling and as a result - a different configuration in the battle and on Stage. About this and talk.
In principle, there are two parts to the company's production structure:
')
- On one side of the scale we have banking software development. It is an automation of the bank’s activities, account management, including client account management, core banking. This is a kind of box that is customized for a bank and installed on the bank’s facilities;
- On the other side of the scale we have a pool of so-called processing services. What it is? These are products developed by us for the end user, for physicists. What famous examples can be given here:
- We have a transport card in many regions, recently appeared in the Moscow region under the name "Strelka", we are the technical provider of this solution.
- The federal system "City" for receiving payments - from utility to loan repayment.
- “Invoice” remote banking service is a service I work on directly.
- “Golden Crown” - money transfers, the third largest service in the world in terms of turnover.
- Services that revolve around MasterCard products, which can be obtained from the trade network without opening a bank account. Probably the most famous of them is the Corn of the Euroset. This is also our product, our solution, and all that is spinning on it.
- We have a transport card in many regions, recently appeared in the Moscow region under the name "Strelka", we are the technical provider of this solution.
Why am I talking about all this? The meaning of these products, their features in terms of operation and maintenance is that we provide a complete cycle for these processing services. We are developing them - we come up with an idea, we are developing it, and we, at our facilities, place our own data centers at our data centers and, in fact, provide all the operational operation and maintenance.
What does this thing that I call exploitation and maintenance in such a financial sector look like? It looks like this in reality:

This is our reality. It is our life. What is specific here? This is a strict separation of the production segments from the production environment; this is the complete absence of any access, including logs, i.e. We specifically through some conditional DMZ transfer logs for developers (and then only for selected ones), i.e. Absolutely the production segment is closed for development.
What are the tactical and technical characteristics of this picture? The equipment that is located in our data centers uses Oracle's servers, servers on the SPARC architecture, i.e. not X86, this is a separate SPARC architecture, the Solaris operating system. Since this is a financial service, fortunately, physicists use these services 24x7, so similar requirements for uptime and system operation are 24x7, 4 nines, well, it would be cool if it were 5. Such requirements. At the same time, the feature is still something that is not relevant to the context of this conference - we have a lot, almost 90%, of business logic written in Oracle. When I say what is written in Oracle, it means that yes, these are packages on PL / SQL code that are contained in Oracle DBMS. Thus, approximately 90% of business logic is implemented. Accordingly, some delights are associated with simple scaling. In this case, we have all these huge servers - vertical, not horizontal in any way. This is all our feature.
As I said already, 24x7, 4 nines, the code on PL / SLQ ... And we have a very narrow link - we cannot update the system without doing downtime, i.e. we must lower the system, roll over the update, then raise it. In Russia, we work in all time zones and do this: we have chosen a window in which the minimum number of client transactions passes, and we downtime and an immature system go into this window. This window is from one o'clock to 2 o'clock at night, Novosibirsk time. At this time, we admins really go out on the night and roll the update to the battle.
How did they do it? This is a footcloth like that in a word document (then we switched to confluence, there were also some special features), in which the instructions say what needs to be done: backup, copy here, copy here, fill in, go to the config-file, set such then the parameters, roll to the base, check the invalidation of the packages, that there is none, that all is well. Those. This is a manual manual. Distributions are transmitted through the file ball, i.e. roughly speaking, we lay out “web_new_new”, so that there exactly new was taken, but the admin takes from the web “new_” in the middle of the night, which the developer forgot to delete when they extorted ... He had some problems with revision, with rolling out ... So, in As a result, some kind of wrong pre-intermediate version rolls out. Those. it is clear that with such a cycle of updating the combat system, the abyss of errors is inevitable.
It is clear that naturally, we have a duty key developer on these night vigils who insures the whole situation if something went wrong with the updates. In principle, before night work, such a conditional combat / manual dry run is performed on a certain reference complex that corresponds to the combat one, the admins perform all these actions according to the instructions during the day. Only this is not a production, but a completely similar complex to it.
Such a harsh, unsightly picture with which we dealt at the start. And at the same time, we are looking at the whole world around us, looking at startups, we are looking at DevOps mitaps, and this conditional of your world, for us looks from our environment something like this, like on the slide above. And a triumph in contrast. Those. our reality is your reality. And looking at this, you wonder: why, this is why? But the answer is not as obvious as we would like.
I allow myself a little experiment. Everyone must have “MasterCard”, “Visa”, etc. Imagine that you all have a card issued by GazMyasBank, you are a client of GazMyasBank. And, it means that you from the press and from the announcement, which arrives to you by mail, will find out that GazMyasBank was recently bought by a fairly young aggressive financial group “AydaParni”, and the bank was renamed “AyDaBank”. After that, somewhere in a month, you get such a hipsterly open friendly letter from the bank addressed to you. It says literally the following: “Hello, Serega! We know that you often play games at night and you like to make various payment transactions after 2 am. We understand how dumb it is to find yourself in a situation where you cannot make an urgent payment necessary, very tense or at a very piquant moment. Therefore, we decided to meet your wishes, to be in the spirit of the times, in short, we all of our processing servers, all servers with data about card products to the clouds at Amazon, to increase the availability of the operating system. Your actions the day after this letter? Who will not take their money from this bank? And who will take your money from this bank? I do not know why there are those who will not take. Apparently, as an experiment.
By the way, we posted open access videos from the operating conferences and devops RootConf 2015 and 2016 . Here are the relevant sheets in our account - 2015 and 2016 in our YouTube account .
The point is: we must not forget that working in finance, working in the enterprise, we are directly responsible for your personal data, for your banking secrecy, not just in front of you clients, which is certainly the most important, but we are responsible and in front of the Central Bank, and in front of regulators, in front of relevant international organizations. It’s not just our desire to be pleasing to you, it’s just a necessity. We are obliged to comply with certain norms and requirements, their non-compliance threatens to revoke a license. Conventionally, the Central Bank has the requirements of completeness of payment - if the client has given you money, you must fulfill his order to further process this amount of money.
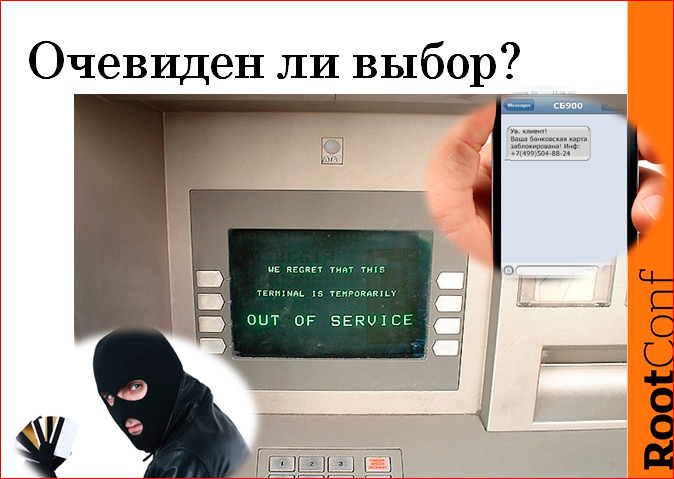
Accordingly, the answer to this question is not obvious, i.e. we cannot take it and just become like the guys from “IdBank”, our license will be revoked just immediately if we become like this:

But, nevertheless, faced with all these technologies, I was initially convinced that we can certainly get a useful profit for ourselves. Yes, we can’t do everything, we can’t do a full conveyor, ideally, we can’t become guys who experiment easily in battle, try something flexibly, dynamically. All the same, we will to some extent remain stagnant, fairly bureaucratic and consistently strict. But I was convinced that we could get a profit. And when I started to promote these ideas in my company, I faced resistance, as I called it, the “all or nothing” syndrome.
This syndrome lies in the fact that “we still can’t fully use DevOps, what should we try?” Or “well, what are we going to make one product differently, and what's the point, we’ll take out the rest all the same, roughly speaking, you cannot right now. ” Those. a huge number of objections from the principle of "all or nothing." It really reminded me very much of one of the teachings for Skrum, when almost any Skrum coach proves to the audience that you either completely follow Skrum, or you have Skrum - 0. But with respect to Skrum, this is at least it can be justified due to the deep determinism of this process, the strong interrelation of all elements. But in general, for the rest, I disagree with this approach. Nothing is true. Nothing is a 100% answer to our questions. From everything you need to isolate the nuggets of common sense and implement them. I came to this opinion, and I managed to convince my colleagues of him that a silver bullet exists.

I believe that the silver bullet is that the silver bullet needs to be cast all the time. You yourself, your experience, your common sense, your brains are a silver bullet. Those. in fact, oh great Edward Deming, the process of continuous improvement is the only existing at the moment, an effective, proven silver bullet.
Ok, I passed this stage of resistance, managed to convince both the IT department and our colleagues that we can go this way. But the next question arises: why? We have been living this way for 20 years, we occupy leading positions in the market, everything works and so, clients use services, why do we need your changes? Why do we need to change something in our lives? Here I will allow personal reflections on a fairly global topic. I agree on tomatoes and everything else. But I, analyzing our various cases, came to this vision.
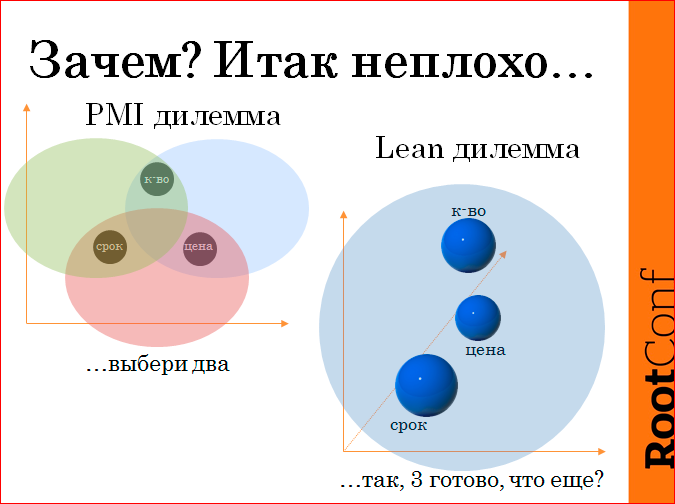
We have a classic situation in project management. You have quality, time, price. And the classic project management tells you: “Friend, it’s impossible to provide all three, choose two, and we’ll provide them due to the fact that the third element suffers”. And so it was until recently.
It was, I believe, as long as the spirit of startups did not prevail in software development, but the spirit of lean manufacturing did not prevail. Because lean manufacturing techniques and approaches allow us to translate this issue, this dilemma into another plane, adding one dimension. What is this measurement? This is the fullness of the features of your product. And, in fact, allow you to speak in another language.
If we are talking about lean manufacturing, about a lean approach to product launch, about startups, then there is no question of choosing two out of three. They take, do all three and ask: “What else should be done? Come on, our hands are burning, we still want. What else?".
Due to what? Of course, due to the fact that the software is not an airplane, it is not heavy engineering. When producing software, we can and must fly into the air unfinished planes, we must raise MVP. Today, colleagues have returned from the conference from New York, they say, there is a new trend - do MVP from MVP. In principle, it is also a reasonable approach. And all this allows us to get away from this dilemma. And this means that if we do not leave it, our competitors will leave it, and it will be completely easy for us. We are still sitting, cleverly we take out the old-fashioned way and say: “Well, normally, it works.” There are young companies that do not know that there is such a dilemma, they act in the spirit of a Lean Startup and do all three conditions and bypass us in some segment. But not at all. But gradually bypass at all. What we cannot do today, tomorrow our competitors will do. This, from my point of view, is the main answer to the question, why should we change? We simply have no right, if we want to stay on the market and continue to offer quality time-tested financial services, we are obliged to change towards lean manufacturing technologies, towards DevOps technologies, and I don’t speak about Agile at all.
"Neo, choose the blue, red pill." We chose a red pill, drank it. And we were not in that rainbow world when we decided to move in the direction of the DevOps we dreamed of. And the pink ponies we thought about turned out to be bloodthirsty monsters who attacked us, and we tried to fight them off for a very long time.
In short, I will go over a small set of problems that we have encountered.

Here, three sharp - is crossed out the Russian word of three letters. Due to the very specifics of the hard separation, we never dreamed of root and never dream, i.e. we will never get it in my life. We fought through this for a very long time, it was proved that we don’t need him, he needs a puppet, but we won’t do anything ourselves. But this is final and not negotiable.
Accordingly, further Solaris, and not just Solaris, but Solaris 10th, i.e. The current version is 11.2, the latest, and we have Solaris 10th. Under it, collecting products is a separate hell and pain, i.e. all these dependencies, all this is to be downloaded, to compile and compile from binaries. I do not know, in my opinion, the month chef was compiled under Solaris. It was a very long time.
Third question. We had a long question about binarism, i.e. there was a very important task - we had to get away from the distribution of the distribution via the file file, because this is a bottomless source of errors. Someone always misplaced some artifacts from this sphere, somewhere he jerked, incorrectly named the directory, whatever convention could be accepted, there would be shoals. Therefore, it was fundamentally necessary for me that we leave the file balls. We chose a package manager as a solution. The package manager we took IPS fork, the IPS version. He, however, in the 11th Solaris is, in the 10th we did. They have a cross-platform IPS project, we made a fork from it and collected it under the 10th Solaris. There was also a separate whistle dance. But, nevertheless, we distribute distributions via IPS, through a package manager. We have traveled this path, and we are pleased with it.
No offense, but as wildness I perceive an attempt to store a binary in the repository, in Git, this is very strange for me. About Maven the idea sounded, after all it not for this purpose. In the package manager, all the same, there is more functionality; it solves more questions from the point of view of the same recipes and challenges. Those. This is a broader solution. I believe that we have gone the right way here.
Noticed such a feature - Ruby is slowly working on the SPARC architecture. Those. what we did not do with it, as we did not twist it, compared to x86 ... In principle, this information is confirmed in the sacred Internet. Indeed, it turns out that due to the architectural peculiarity ... In the same place, there are a large number of weak processors, but there are a lot of them. And on this story, the code runs much slower than under the x86 platform.
Updates without stopping at the moment we have achieved. I think that in many ways we have a very big progress, but not in everything. I will tell you more about it. If we need a new apache on the server, we create a request that “deploy us a new apache”. We ourselves can easily enter and deploy, but not. We create a request: "Deploy us a new apache instance." We are waiting a week for admins to have time, then they come in and give us apache, another week they get users there, because they forgot to start them at the moment when apache was raised, and, oh, about happiness, we get apache. Recently, the guys in Tomsk sat and raged: "Why? ...". We cannot explain logically why apache was raised to us for two weeks, we cannot explain it to you either. And, unfortunately, this is still a pain for me. From this, too, I would like to leave in the future, but for now the environment is being prepared manually. But the point is that we have a vertical scaling, there is no horizontal, as such, we are just approaching. And therefore we do not breed nodes every day, we do not have a task for 50 new nodes to roll a typical environment, it simply does not exist, so it’s not so painful for us so far.
Of course, I’ll stop later when I consider the issue of the team, personal wars. They began: "This is mine, this is yours."We at some point in time of the project stage came to two, as I call them, two brothers of twin freaks - Div DevOps and Ops DevOps. We have created two parallel pipelines, parallel stacks, parallel solutions. Ops, offended at all, wrote his Ops DevOps. Dev said: "Yes, why wait for them, we ourselves wrote our Dev DevOps". Such a picture.
I had to somehow intercept, settle. As we decided, I will tell later. At the conference I didn’t hear any obvious clear toolchain from beginning to end, what to use. Probably not this answer. We have not yet decided for ourselves, i.e. we really have some questions, because chef is not suitable for us, puppet, as an option. We have some products on puppet, we will deploy puppet. Some products on the chef. In general, it’s part of the trash we’ve come across, and we’ve come across, not expecting it, so when confronted with it, we don’t know what to do, and it’s useless to ask the respected community, because the answer will be one: “Do not be morons , go with Solaris to something normal. " This solution does not suit ustherefore, in this sense, we were in some kind of isolation and “wept, injected, but continued to eat the cactus”. This is a picture of the world.

How did this happen? In general, we officially started the project in 2013. We set for ourselves the following key tasks, goals. For us it was important to learn how to update during the day everything that can be updated during the day. Those.update without idle, update without downtime. Because nightly updates are a torment, these are big social problems in the team, because the people are overheating. When you need the admin to patch the patch during the day due to the fact that the developer kosyachnik has nakosyachil something is half the trouble, and when the admin needs to go out again at night and roll this patch, then this bickering, DevOps'kovskie throwing up poo towards each other some ultra-scale hatred, just black hatred. Accordingly, to minimize nightly updates - this was one of the very important tasks.
The next task was to approach night work (still day work, but first of all night work, because not everyone is available there), fully understanding what we are going to do, what we have in the release, in the set release work. And why?Because there were not rare cases when, the first stage, even before DevOps, I implemented ITIL, it was in the part of release management. I say: “Guys, let the developers and the operation get together before the night work and discuss what they will do at night, and not just the developers silently handed over the instructions to all the questions - everything is written there, are you morons, are you? And those - well, they don't know how to write instructions, they understand everything, we don’t understand anything at all. ” And went in different directions.
For a start, we learned to get together and discuss what will happen at night. Why is it important?Because everything is so likely to never go. Most likely, something at night will go wrong. And in order to understand what is the limit of admissibility, when we still decide to roll back all the work, are these errors acceptable that fell in the logs after the run-up. They can be valid, they can - no, for this you need to understand what we are rolling. Therefore, it was critically important to me.
And ideally know the combat situation. Rather extensive, complicated at the logic level, the combat deployment scheme ... A large number of transport services (I call them transport), our specific java module specificity, a huge number of people responsible for different nuances and questions ... And constantly making some changes, adjustments, parameter edits, and far from always we have at the time of the incident a clear understanding that this whole of our huge military infrastructure now represents itself. This was necessary to ensure. And before DevOps, I really attempted to implement ITL's CMDB, but we successfully implemented the configuration management process and, in principle, reduced to zero the number of incidents related to incorrect changes, and not verified later, CMDB was not needed.
This, of course, is bureaucratic murk, when you have to do the work, then run off somewhere and still reflect what parameters you have configured on apache. Here it is necessary from the reverse. I, in general, because of this, for DevOps at one time and caught. A colleague from HighLoad came to me and said: “Listen, they tell me about the configuration management system, it’s not like your DevOps, no?”. I read about Chef and I think: this is something wrong, I need to control my infrastructure, and they change it with recipes. But then the understanding came that I do not want to control, I want to manage the infrastructure, this is my task. Accordingly, I want to perfectly know the combat situation.

And we set ourselves such primary tasks within the framework of high-level goals. Those.the same deployment pattern in combat and design. We had different, i.e. if in battle we had, roughly speaking, 30 java modules responsible for one or another interaction logic, then in the battle it was all in one module. And many other such differences that caused conflicts, including during the removal of the battle, because what the developers invented in their version of reality did not correspond to the combat scheme.
We have set ourselves the task that we, at a minimum, do not prepare the environment until we manage the configuration, but let us deploy not with a footcloth, let us deploy with recipes, let’s dismiss it humanly.
As I have already said, the transfer of distributions, updates without downtime of everything that is possible, because it was necessary to get away from these nightly work, and to remove this hatred, this inability of people to communicate with each other, i.e. physically people cannot communicate with each other. We forcibly put them together on the same floor - the developers and the operation. It was a terrible stage, we prepared for it for a long time, decided and decided. It was also a whole song.

What do we have today? What have we accomplished during this time?
- We did ensure 100% uniformity of deployment patterns in the development environment and production, and since we are now changing this recipe deployment pattern, it is automatically supported. Those. , , , .
- Java- — .
- - , , , . , , , , , . .
- chef puppet , , - , , , , puppet.
- Zabbix? , , , Zabbix'. , , , , , , .. , — .
… 60%, , , 90% 2 100%. Those. , , , , stdout , . , , 90%, . « 60%», — - 90%. , , . , , . Zabbix' . - .NET. .NET , . Visual Studio Release Management. : «, , , », , , . , , , puppet , , , , , . Those. , … , .
- 100% . , , , .. apache , , , , , . .
- Oracle. , - PL/SQL . , Oracle, . ? Oracle , Edition-Based Redefinition. What does it mean? — , PL/SQL , . , , , , , 2 . , , . , , , .. . . Why? , , , , ALTER TABLE , , . , - , , -, .
- . — . -, . Those. . . Those. - , , , , . Those. . . ,
. , , 100% DevOps , , , , , . — , , DevOps — , , . . — , . , , -, . , , : «, ?», : «, - , ». , , .
We have plans for the near future, where we want to go next:

What do I want to say?I understand perfectly well that perhaps for your world, what I am saying is a small step for a person, that these are some minor things, but for the financial sector, for such an enterprise of the financial sector, I am convinced this is a very big leap forward .

We are still in flight. The flight is normal, it's great.

— devops RootConf .
, , — RootConf 2017 — 5 6 .
, " ", , …
Kubernetes
Kubernetes production . «» Kubernetes , . , , : , Docker , «» (Marathon, Rancher, Kubernetes)… - !
Kubernetes ( 50 ), :
- , Kubernetes ;
- , ;
- , CI/CD ( GitLab dapp) ;
- We will try to answer the question of why Kubernetes may be needed by your project, by systematizing and sorting out all the pros and cons that are known to us;
- Finally, we will share information about the location and size of the pitfalls.
These are the articles that are waiting for you in our blog in six months :) Well, or in a month at the RootConf conference , if you like its program :)
Source: https://habr.com/ru/post/328256/
All Articles