Recovering data from damaged RAID 5 to Linux NAS
A regular weekday in one organization ceased to be normal after several dozens of people could not continue their activities, since all the usual processes stopped. CRM stopped its work, the base of managers ceased to respond, a similar picture was with the accounting bases. A squall of calls from users with reports of problems and urgent intervention requirements hit the system administrator. The system administrator, who recently started a career with this company, tried to connect to the NAS and found that the device did not respond. After the power was turned off and the NAS was re-enabled, it returned to life, but the launch of the virtual machines did not occur. For users, only shared file storage was available. Problem analysis by the system administrator showed that one of the two RAID arrays does not contain volumes and is a pure unpartitioned space. What were the further actions of the system administrator, history is silent, but quickly he realized that he did not have a clear plan of action to restore the data and working environment of the company. At this stage, six hard disk drives (2 HDD - 3 TB HDS5C3030ALA630, 4 HDD - 4 TB WD4000FYYZ-01UL1B1) from this NAS come to us. In the technical task we are offered to “restore the partition table”.

Of course, with such volumes of disks, there can be no talk of any classical partition table. For safe work, we need to evaluate the state of each of the drives in order to select the best methods for creating sector-specific copies. To do this, we analyze the readings of SMART , we also check the state of BMG by reading small sections of each head in areas of different density. In our case, all drives turned out to be serviceable.
To optimize the execution time we will create copies of 100,000,000 sectors from the beginning of the disk. We will need these 50-gigabyte images for analysis at the same time as sector-specific copies of the drives will be created (creating full copies is compulsory insurance, although sometimes it seems not to be such an important event that only delays the data recovery procedure).
')
You need to understand how the NAS works with disks, and what logical markup tools are used. To do this, look at LBA 0 and 1 of each of the disks.
rice 2
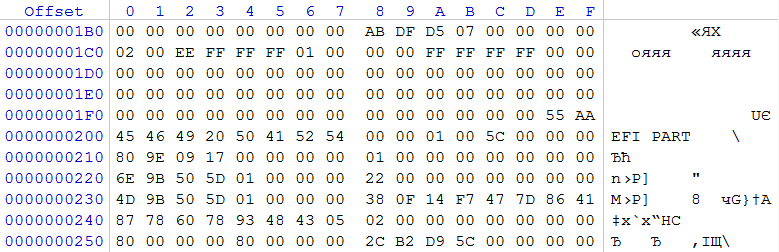
On two 3TB drives at offset 0x01C2, the partition type 0xEE is recorded, starting from LBA 0x00000001 and its size is 0xFFFFFFFF sectors. This entry is a typical security entry for drives using GPT . Assuming that GPT was used, we estimate the contents of sector 1, which in the image originates from 0x200. The regular expression 0x45 0x46 0x49 0x20 0x50 0x41 0x52 0x54 (in text form: EFI PART) informs us that we have a GPT header.
In sector 2 we find GPT partition records.

rice 3
The first entry describes a section from 0x0000000000000022 sectors to 0x0000000000040021 sectors, which has a non-standard GUID. It contains an exclamation from the developer, which in a slightly compressed form broadcasts “Hah! I don't need an EFI “. Label volume “BIOS boot partition“.
The second entry describes a section with 0x0000000000040022 sectors of 0x0000000000140021, the identifier of this section is A19D880F-05FC-4D3B-A006-743F0F84911E. Label volume “Linux RAID”.
The third entry describes the section with 0x0000000000140022sektora 0x000000015D509B4D sector, which also has a GUID A19D880F-05FC-4D3B-A006-743F0F84911E. Label volume “Linux RAID”.
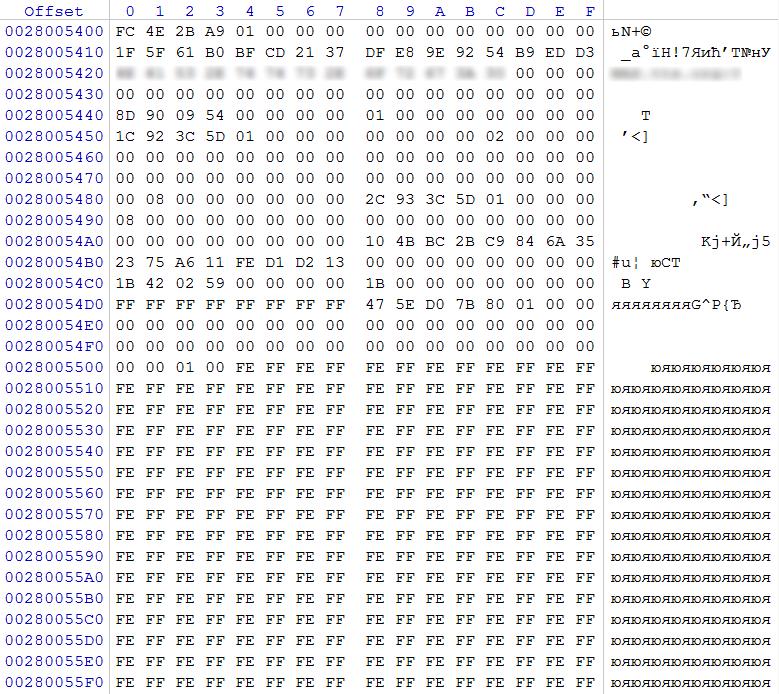
Based on the size of the sections, we can neglect the first and second, since it is obvious that these sections are created for the needs of the NAS. The third section is what interests us at the moment. According to the identifier, it has the sign of a member of a RAID array created by Linux. Based on this, we need to find the RAID superblock configuration. The expected location of its location through 8 sectors from the beginning of the section.
rice four
In our case, at the offset 0x0, the regular expression 0xFC 0x4E 0x2B 0xA9 was detected, which is a marker for the superblock of the RAID configuration. At offset 0x48, we see the value 0x00000001, which means that this block describes the RAID 1 array (mirror), the value 0x00000002 at offset 0x5C tells us that there are 2 participants in this array. At offset 0x80 it is reported that the data area of the array will begin after 0x00000800 (2048) sectors (counting is from the beginning of the partition with the superblock). By offset 0x88 in QWORD, the number of sectors 0x000000015D3C932C (5,859,218,220) is recorded, which in this section takes part in the RAID array.
Turning to the data start area, we find the LVM sign
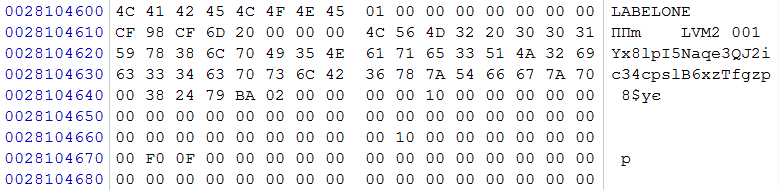
rice five
go to the latest version of the configuration.
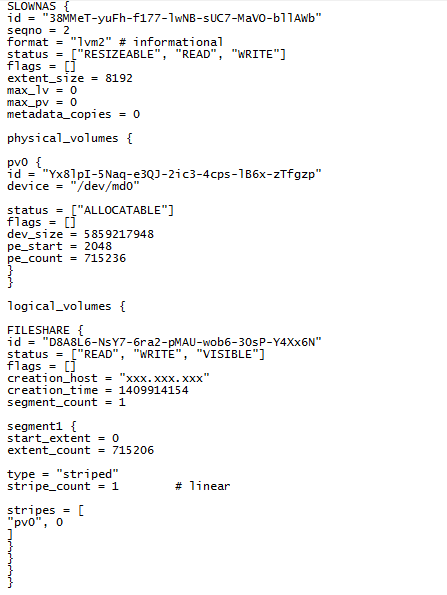
rice 6
In the configuration, we see that on this array one volume consisting of one segment, named “FILESHARE”, which occupies practically the entire capacity of the array (number of extents * extent size = capacity in sectors 715,206 * 8,192 = 5,858,967,552. Having checked The section described in this volume finds the Ext4 file system, the entries in which clearly indicate that the section name matches the content.
Analyzing the contents of the second drive with a capacity of 3TB, we find the presence of identical structures and full correspondence in the data area for RAID 1, which confirms that this disk was also part of this array. Knowing that the file sharing service called FILESHARE was available to users, we exclude these two disks from further consideration.
We turn to the analysis of drives with a capacity of 4TB. To do this, consider the contents of the zero sector of each of the drives for the presence of a protective partition table.

rice 7
But instead we find some garbage content that can not claim to be the partition table. A similar picture from 1 to 33 sectors. The attributes of the partition table (protective MBR ) and GPT are absent on all disks. When analyzing RAID 1, described above, we obtained information which areas this NAS allocates for service purposes, based on this we assume from what offset the partition can start with an area participating in another array with user data.
Let's search for the RAID configuration superblocks (by the regular expression 0xFC 0x4E 0x2B 0xA9) on these drives in the vicinity of the offset 0x28000000. Each disk has a superblock at offset 0x28101000 (the address is slightly different from the one on the first pair of disks, probably due to the fact that in this case it was taken into account that 4TB data disks with a physical sector of 4096 bytes with 512 byte sector emulation) .
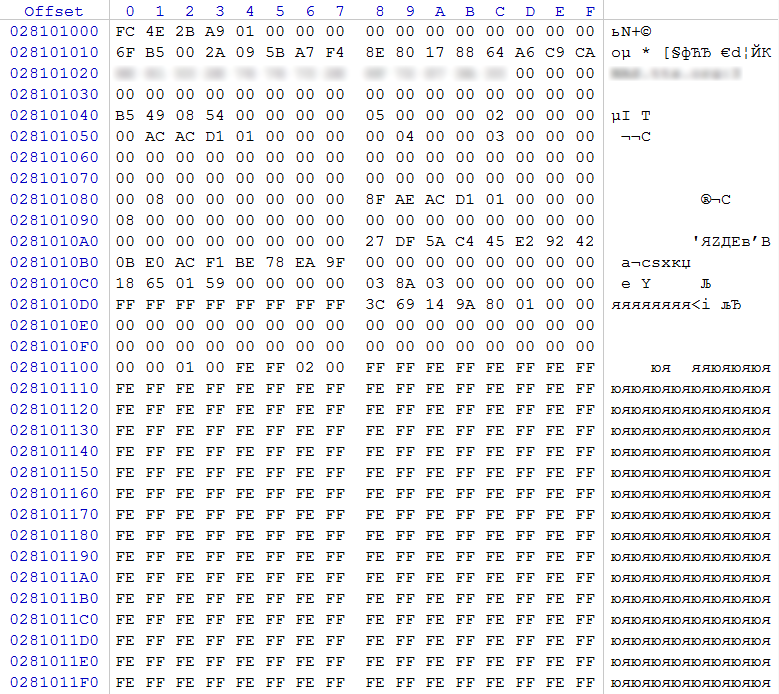
rice eight
At offset 0x48 value 0x00000005 (RAID5)
At offset 0x58 value 0x00000400 (1024) - block size of alternation 1024 sectors (512KB)
At offset 0x5C, the value 0x00000003 is the number of participants in the array. Given that there are 4 disks with identical superblocks, and, according to the record, 3 disks are involved, it can be concluded that one of the disks has the role of a hot spare disk. We also clarify that this array was a RAID 5E.
At offset 0x80, the value 0x0000000000000800 (2048) is the number of sectors from the beginning of the section to the area taking part in the array.
At offset 0x88, the value 0x00000001D1ACAE8F (7,812,722,319) of sectors is the size of the area participating in the array.
If the drive used as a hot-swap drive did not go into operation, and the rebuild operation was not performed, then its contents will be very different from the contents of the other three drives. In our case, when scrolling through the disks in the hex editor, an almost empty drive is easily detected. It also exclude their consideration.
Assuming that the RAID configuration superblock is at the standard offset from the beginning of the partition, we can get the address of the beginning of the partition 0x28101000-0x1000 = 0x208100000. Accordingly, the data start area, taking into account the content by offset:
0x208100000 + (0x0000000000000800 * 0x200) = 0x208200000.
Turning on this offset, we see that for 1024 (0x800) sectors on each of the disks nothing similar to LVM or some other variant of logical partitioning is detected. When performing the test of correctness of data from offset 0x208200000 by means of XOR operation on the contents of three drives, we consistently get 0, which indicates the integrity of RAID 5 and confirms that no drive was excluded from the array (and the Rebuild operation was not performed). Based on the contents of the RAID 1 array, we assume that in the RAID 5 array, the 0x100000 area at the beginning, which is currently filled with garbage data, was intended to accommodate LVM.
Given that this RAID is an alternating array with a parity block, then retreating to 0x100000 from the beginning of the array, we need to move to 0x208280000 on each disk, presumably, the data area in LVM will start from this address. We verify this assumption by analyzing the data at this offset. If this is not a volume used for a swap, then there must be signs of either some kind of logical markup within the partition described in LVM, or signs of some file system.
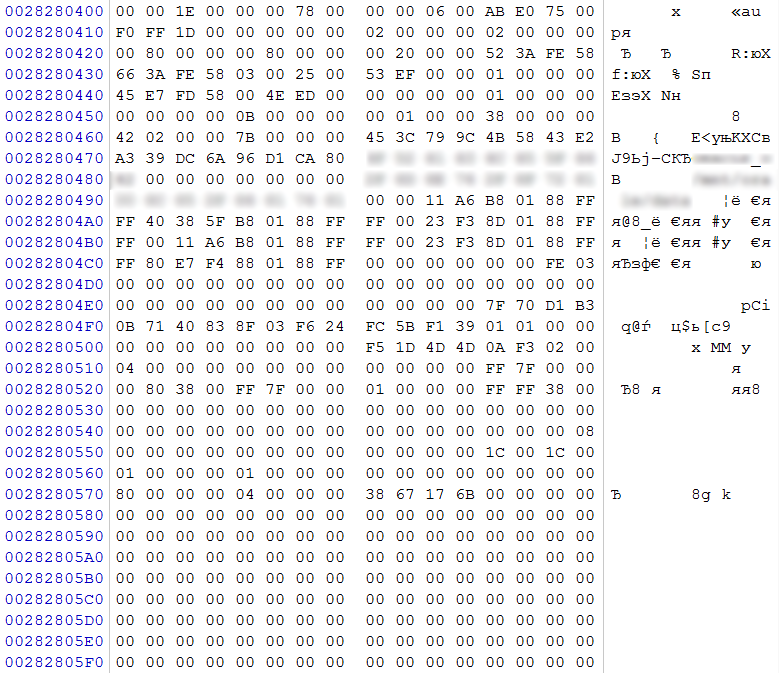
rice 9
By the characteristic offset 0x0400 on one of the disks (according to customer numbering - No. 2), we find the Ext4 superblock. It by offset 0x04 DWORD - the number of blocks in this file system, by offset 0x18 implicitly indicates the size of the block (to calculate the block size, you must raise 2 to the power (10 + X), where X is the value by offset 0x18). Based on these values, we will calculate the size of the partition with which this file system is operating 0x00780000 * 0x1000 = 0x780000000 bytes (30GB). We see that the size of the partition is substantially less than the capacity of the array. We believe that this is only one of the sections, which was described in LVM, and, based on the offset relative to the beginning of the array, we can assume that it began with a zero extent.
Although the initial assumptions about the location of the data turned out to be true, we will not use the information from the RAID configuration superblock, but we will analyze the data inside the partition and, based on this, set the array parameters. This method will allow us to confirm the correctness of the parameters in the superblock of the RAID configuration applied to this array or to refute and set the correct ones.
It is convenient to use monotonically increasing sequences to determine the block size and parity parameters of the parity block. On the sections Ext2, Ext 3, Ext 4 they can be found in Group Descriptors (not in all cases). Take a convenient area for each of the disks:

rice 10 (HDD 2)

rice 11 (HDD 1)

rice 12 (HDD 0)
Scrolling through the hex editor in increments of 0x1000 each of the disks, we note that the increase in numbers by intrasectional offsets 0x00, 0x04, 0x08, etc. goes over 1024 sectors or 0x80000 bytes (valid only for data blocks, but not for blocks with XOR operation results), which quite clearly confirms the block size described in the RAID configuration superblock.
Looking at pic. 10, fig. 11, fig. 12, it is easy to determine the role of disks in a given place and the order of their use. To build a full matrix, we will scroll through the images of all disks in increments of 0x80000 and enter values from offsets 0x00 into the table. To fill the disk usage table, we will enter the disk names according to the increase in the values we entered in the first table.
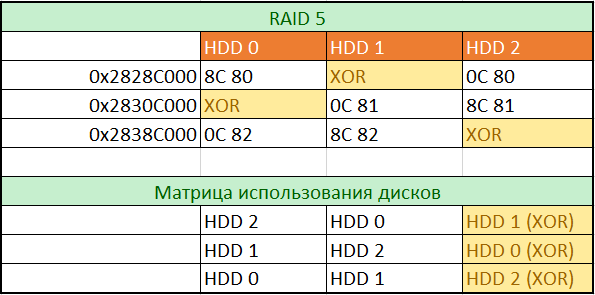
rice 13
According to the disk usage matrix, we will collect a RAID 5 array with 0x28280000 in the first 30 GB. This address was chosen based on the absence of LVM and the fact that the beginning of the EXT4 section we detected falls on this offset. In the resulting image, we will be able to completely check the file system and the correspondence of the file types described in it to the actually placed data. In our case, this check did not reveal any flaws, which confirms the correctness of all previous conclusions. Now you can proceed to the complete collection of the array.
Due to the lack of LVM, we have to search for sections in the assembled array. For partitions consisting of one segment, this procedure will be no different from searching partitions on a conventional drive with a cleaned partition table (MBR) or GPT. It all comes down to finding signs of the beginning of partitions of various file systems and partition tables.
In the case of volumes that belonged to a lost LVM, and consisting of 2 or more fragments, an additional set of measures will be required:
- mapping of logical volumes consisting of one segment by recording the range of sectors occupied by the volume on the partition;
- mapping of sections of the first segments of fragmented volumes. It is necessary to accurately determine the place of the section break. This procedure is much simpler if you know the exact extent size used in a lost LVM. The order of extent size can be assumed based on the location of the beginning of the volumes. Unfortunately, this technique is not always applicable.
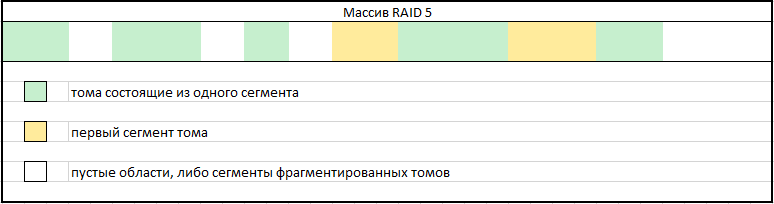
Fig. 14
In the empty parts of the map, there will be a search for segments that need to be incremented to the first segment of any of the fragmented volumes. It should be noted that such fragments of volumes can be quite a lot. You can check the correctness of increments by analyzing the file records in the file system of the volume with a comparison of the actual data.
After completing the full range of activities, we get all the images of the logical volumes that were in the RAID array.
I also draw your attention to the fact that this publication intentionally does not mention professional data recovery systems that simplify some stages of work.
Next post: A bit of reverse engineering USB flash on the SK6211 controller
Previous publication: Recovering files after a cryptographer
Of course, with such volumes of disks, there can be no talk of any classical partition table. For safe work, we need to evaluate the state of each of the drives in order to select the best methods for creating sector-specific copies. To do this, we analyze the readings of SMART , we also check the state of BMG by reading small sections of each head in areas of different density. In our case, all drives turned out to be serviceable.
To optimize the execution time we will create copies of 100,000,000 sectors from the beginning of the disk. We will need these 50-gigabyte images for analysis at the same time as sector-specific copies of the drives will be created (creating full copies is compulsory insurance, although sometimes it seems not to be such an important event that only delays the data recovery procedure).
')
You need to understand how the NAS works with disks, and what logical markup tools are used. To do this, look at LBA 0 and 1 of each of the disks.
rice 2
On two 3TB drives at offset 0x01C2, the partition type 0xEE is recorded, starting from LBA 0x00000001 and its size is 0xFFFFFFFF sectors. This entry is a typical security entry for drives using GPT . Assuming that GPT was used, we estimate the contents of sector 1, which in the image originates from 0x200. The regular expression 0x45 0x46 0x49 0x20 0x50 0x41 0x52 0x54 (in text form: EFI PART) informs us that we have a GPT header.
In sector 2 we find GPT partition records.
rice 3
The first entry describes a section from 0x0000000000000022 sectors to 0x0000000000040021 sectors, which has a non-standard GUID. It contains an exclamation from the developer, which in a slightly compressed form broadcasts “Hah! I don't need an EFI “. Label volume “BIOS boot partition“.
The second entry describes a section with 0x0000000000040022 sectors of 0x0000000000140021, the identifier of this section is A19D880F-05FC-4D3B-A006-743F0F84911E. Label volume “Linux RAID”.
The third entry describes the section with 0x0000000000140022sektora 0x000000015D509B4D sector, which also has a GUID A19D880F-05FC-4D3B-A006-743F0F84911E. Label volume “Linux RAID”.
Based on the size of the sections, we can neglect the first and second, since it is obvious that these sections are created for the needs of the NAS. The third section is what interests us at the moment. According to the identifier, it has the sign of a member of a RAID array created by Linux. Based on this, we need to find the RAID superblock configuration. The expected location of its location through 8 sectors from the beginning of the section.
rice four
In our case, at the offset 0x0, the regular expression 0xFC 0x4E 0x2B 0xA9 was detected, which is a marker for the superblock of the RAID configuration. At offset 0x48, we see the value 0x00000001, which means that this block describes the RAID 1 array (mirror), the value 0x00000002 at offset 0x5C tells us that there are 2 participants in this array. At offset 0x80 it is reported that the data area of the array will begin after 0x00000800 (2048) sectors (counting is from the beginning of the partition with the superblock). By offset 0x88 in QWORD, the number of sectors 0x000000015D3C932C (5,859,218,220) is recorded, which in this section takes part in the RAID array.
Turning to the data start area, we find the LVM sign
rice five
go to the latest version of the configuration.
rice 6
In the configuration, we see that on this array one volume consisting of one segment, named “FILESHARE”, which occupies practically the entire capacity of the array (number of extents * extent size = capacity in sectors 715,206 * 8,192 = 5,858,967,552. Having checked The section described in this volume finds the Ext4 file system, the entries in which clearly indicate that the section name matches the content.
Analyzing the contents of the second drive with a capacity of 3TB, we find the presence of identical structures and full correspondence in the data area for RAID 1, which confirms that this disk was also part of this array. Knowing that the file sharing service called FILESHARE was available to users, we exclude these two disks from further consideration.
We turn to the analysis of drives with a capacity of 4TB. To do this, consider the contents of the zero sector of each of the drives for the presence of a protective partition table.
rice 7
But instead we find some garbage content that can not claim to be the partition table. A similar picture from 1 to 33 sectors. The attributes of the partition table (protective MBR ) and GPT are absent on all disks. When analyzing RAID 1, described above, we obtained information which areas this NAS allocates for service purposes, based on this we assume from what offset the partition can start with an area participating in another array with user data.
Let's search for the RAID configuration superblocks (by the regular expression 0xFC 0x4E 0x2B 0xA9) on these drives in the vicinity of the offset 0x28000000. Each disk has a superblock at offset 0x28101000 (the address is slightly different from the one on the first pair of disks, probably due to the fact that in this case it was taken into account that 4TB data disks with a physical sector of 4096 bytes with 512 byte sector emulation) .
rice eight
At offset 0x48 value 0x00000005 (RAID5)
At offset 0x58 value 0x00000400 (1024) - block size of alternation 1024 sectors (512KB)
At offset 0x5C, the value 0x00000003 is the number of participants in the array. Given that there are 4 disks with identical superblocks, and, according to the record, 3 disks are involved, it can be concluded that one of the disks has the role of a hot spare disk. We also clarify that this array was a RAID 5E.
At offset 0x80, the value 0x0000000000000800 (2048) is the number of sectors from the beginning of the section to the area taking part in the array.
At offset 0x88, the value 0x00000001D1ACAE8F (7,812,722,319) of sectors is the size of the area participating in the array.
If the drive used as a hot-swap drive did not go into operation, and the rebuild operation was not performed, then its contents will be very different from the contents of the other three drives. In our case, when scrolling through the disks in the hex editor, an almost empty drive is easily detected. It also exclude their consideration.
Assuming that the RAID configuration superblock is at the standard offset from the beginning of the partition, we can get the address of the beginning of the partition 0x28101000-0x1000 = 0x208100000. Accordingly, the data start area, taking into account the content by offset:
0x208100000 + (0x0000000000000800 * 0x200) = 0x208200000.
Turning on this offset, we see that for 1024 (0x800) sectors on each of the disks nothing similar to LVM or some other variant of logical partitioning is detected. When performing the test of correctness of data from offset 0x208200000 by means of XOR operation on the contents of three drives, we consistently get 0, which indicates the integrity of RAID 5 and confirms that no drive was excluded from the array (and the Rebuild operation was not performed). Based on the contents of the RAID 1 array, we assume that in the RAID 5 array, the 0x100000 area at the beginning, which is currently filled with garbage data, was intended to accommodate LVM.
Given that this RAID is an alternating array with a parity block, then retreating to 0x100000 from the beginning of the array, we need to move to 0x208280000 on each disk, presumably, the data area in LVM will start from this address. We verify this assumption by analyzing the data at this offset. If this is not a volume used for a swap, then there must be signs of either some kind of logical markup within the partition described in LVM, or signs of some file system.
rice 9
By the characteristic offset 0x0400 on one of the disks (according to customer numbering - No. 2), we find the Ext4 superblock. It by offset 0x04 DWORD - the number of blocks in this file system, by offset 0x18 implicitly indicates the size of the block (to calculate the block size, you must raise 2 to the power (10 + X), where X is the value by offset 0x18). Based on these values, we will calculate the size of the partition with which this file system is operating 0x00780000 * 0x1000 = 0x780000000 bytes (30GB). We see that the size of the partition is substantially less than the capacity of the array. We believe that this is only one of the sections, which was described in LVM, and, based on the offset relative to the beginning of the array, we can assume that it began with a zero extent.
Although the initial assumptions about the location of the data turned out to be true, we will not use the information from the RAID configuration superblock, but we will analyze the data inside the partition and, based on this, set the array parameters. This method will allow us to confirm the correctness of the parameters in the superblock of the RAID configuration applied to this array or to refute and set the correct ones.
It is convenient to use monotonically increasing sequences to determine the block size and parity parameters of the parity block. On the sections Ext2, Ext 3, Ext 4 they can be found in Group Descriptors (not in all cases). Take a convenient area for each of the disks:
rice 10 (HDD 2)
rice 11 (HDD 1)
rice 12 (HDD 0)
Scrolling through the hex editor in increments of 0x1000 each of the disks, we note that the increase in numbers by intrasectional offsets 0x00, 0x04, 0x08, etc. goes over 1024 sectors or 0x80000 bytes (valid only for data blocks, but not for blocks with XOR operation results), which quite clearly confirms the block size described in the RAID configuration superblock.
Looking at pic. 10, fig. 11, fig. 12, it is easy to determine the role of disks in a given place and the order of their use. To build a full matrix, we will scroll through the images of all disks in increments of 0x80000 and enter values from offsets 0x00 into the table. To fill the disk usage table, we will enter the disk names according to the increase in the values we entered in the first table.
rice 13
According to the disk usage matrix, we will collect a RAID 5 array with 0x28280000 in the first 30 GB. This address was chosen based on the absence of LVM and the fact that the beginning of the EXT4 section we detected falls on this offset. In the resulting image, we will be able to completely check the file system and the correspondence of the file types described in it to the actually placed data. In our case, this check did not reveal any flaws, which confirms the correctness of all previous conclusions. Now you can proceed to the complete collection of the array.
Due to the lack of LVM, we have to search for sections in the assembled array. For partitions consisting of one segment, this procedure will be no different from searching partitions on a conventional drive with a cleaned partition table (MBR) or GPT. It all comes down to finding signs of the beginning of partitions of various file systems and partition tables.
In the case of volumes that belonged to a lost LVM, and consisting of 2 or more fragments, an additional set of measures will be required:
- mapping of logical volumes consisting of one segment by recording the range of sectors occupied by the volume on the partition;
- mapping of sections of the first segments of fragmented volumes. It is necessary to accurately determine the place of the section break. This procedure is much simpler if you know the exact extent size used in a lost LVM. The order of extent size can be assumed based on the location of the beginning of the volumes. Unfortunately, this technique is not always applicable.
Fig. 14
In the empty parts of the map, there will be a search for segments that need to be incremented to the first segment of any of the fragmented volumes. It should be noted that such fragments of volumes can be quite a lot. You can check the correctness of increments by analyzing the file records in the file system of the volume with a comparison of the actual data.
After completing the full range of activities, we get all the images of the logical volumes that were in the RAID array.
I also draw your attention to the fact that this publication intentionally does not mention professional data recovery systems that simplify some stages of work.
Next post: A bit of reverse engineering USB flash on the SK6211 controller
Previous publication: Recovering files after a cryptographer
Source: https://habr.com/ru/post/328134/
All Articles