Services on Go in Badoo: how we write and support them

Writing a network service on Go is very simple: there are a lot of tools in the standard library, and if something is missing, then Github has a lot of fancy libraries to meet most needs.
But what if you need to write about ten different services working in the same infrastructure?
If each demon will use all the fresh various "smoothies" technologies, it will turn out to be a "zoo", which is difficult and expensive to maintain, not to mention adding new functionality to them.
In Badoo, we have over 30 self-written demons written in different languages, and about 10 of them are on Go. All these daemons run on about 300 servers. How we came to this, without getting a “zoo” as a result, as the monitoring administrators manage to sleep peacefully, without restricting anyone to a smoothie, while developers, QA and releasers live together and have not quarreled so far - read under the cut.
In Badoo Go, it first appeared around 2014, when we were faced with the task of quickly writing a demon that was looking for intersections between user coordinates. Then the latest version of Go was 1.3, and therefore we struggled for a long time with GC-pauses, which was even reported on at the Go-metap in our office.
Since then, we have more and more demons written in Go. Basically, this is what would have been written in C before, but sometimes it is something that does not fit so well on PHP (for example, our asynchronous proxy or our “cloud” resource scheduler ).
All requests from client applications are served by PHP, which goes to our various self-written and non-self-written services. Simplified it looks like this:
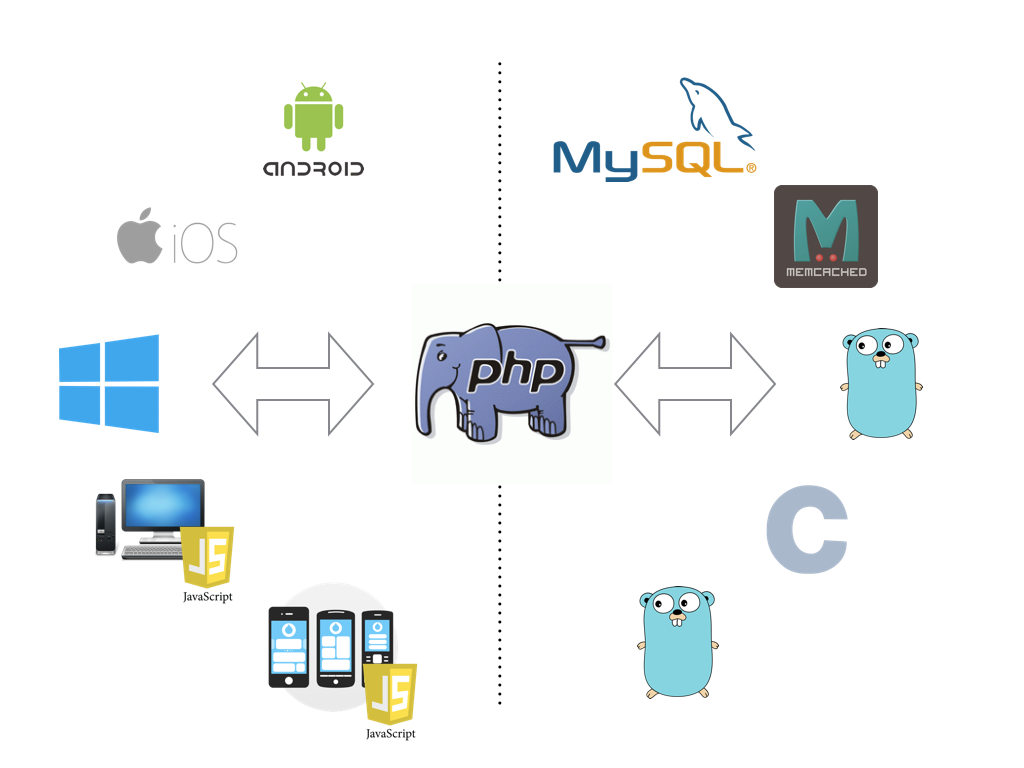
Although there are some exceptions to this rule, the following is generally true for all of our demons on Go:
- They do not "stick out" on the Internet.
- The main “user” of the daemon is a PHP code.
All of our demons, regardless of the language of their writing, look the same "from the outside" in terms of protocol, logs, statistics, deployment and so on. This makes life easier for admins, release engineers, QA and PHP developers.
Therefore, on the one hand, many approaches that we use for demons on Go were dictated by already existing approaches to writing demons in C / C ++, and on the other hand, much of this article is valid not only for Go, but also for any of our demons. .
Below, I will describe how our basic infrastructure parts are arranged and how they are reflected in the Go code.
Protocol
When it comes to client-server communication, the question arises about the protocol. We are based on Google Protobuf . Our protocol is similar to the simplified version of gRPC, so we were repeatedly asked questions from the category “why did we need to reinvent the wheel?”. Most likely, today we would really use gRPC, but at that time (2008) it did not exist yet, and now there is no point in changing one for the other.
Protobuf wraps only the message body into a binary representation and does not preserve its type. Therefore, each time a client requests a server, the server must understand what kind of protobuf message it is and what method needs to be executed. To do this, before the protobuf message, we add a message type identifier and message length. The identifier makes it clear which GPB-message came in, and the length allows you to immediately allocate a buffer of the desired size.
As a result, one call in terms of the protocol looks like this:
- 4 bytes - the length of the message N (the number in the network byte order );
- 4 bytes - the message type identifier (also);
- N bytes - the message body.
In order for both the client and server to have the same information about message identifiers, we also store them in a proto-file in the form of enums with the special names request_msgid and response_msgid . For example:
enum request_msgid { REQUEST_RUN = 1; REQUEST_STATS = 2; } // request response, enum response_msgid { RESPONSE_GENERIC = 1; // , response , RESPONSE_RUN = 2; RESPONSE_STATS = 3; } message request_run { // ... } message response_run { // ... } message request_stats { // ... } // ... Our entire library, which we call gpbrpc, is responsible for this protocol part. It can be roughly divided into two parts:
- one part is the code generator , which, on the basis of
request_msgidandresponse_msgidgenerates maps of correspondences id => message, templates of handler methods, maps of their calls with type conversion, and some other necessary code; - The second part deals with the analysis of all these data that came through the network, and the call to their corresponding handler methods.
The code generator from the first part is implemented as a plug-in to Google Protobuf.
This is how the automatically generated handler looks for the above proto-file:
// , , proto- type GpbrpcInterface interface { RequestRun(rctx gpbrpc.RequestT, request *RequestRun) gpbrpc.ResultT RequestStats(rctx gpbrpc.RequestT, request *RequestStats) gpbrpc.ResultT } func (GpbrpcType) Dispatch(rctx gpbrpc.RequestT, s interface{}) gpbrpc.ResultT { service := s.(GpbrpcInterface) switch RequestMsgid(rctx.MessageId) { case RequestMsgid_REQUEST_RUN: r := rctx.Message.(*RequestRun) return service.RequestRun(rctx, r) case RequestMsgid_REQUEST_STATS: r := rctx.Message.(*RequestStats) return service.RequestStats(rctx, r) } } // - /* func ($receiver$) RequestRun(rctx gpbrpc.RequestT, request *$proto$.RequestRun) gpbrpc.ResultT { // ... } func ($receiver$) RequestStats(rctx gpbrpc.RequestT, request *$proto$.RequestStats) gpbrpc.ResultT { // ... } */ gogo / protobuf
In the Protobuf documentation, Google recommends using this library for Go. But, unfortunately, it generates a bad GC-code. Example from documentation :
message Test { required string label = 1; optional int32 type = 2 [default=77]; } turns into
type Test struct { Label *string `protobuf:"bytes,1,req,name=label" json:"label,omitempty"` Type *int32 `protobuf:"varint,2,opt,name=type,def=77" json:"type,omitempty"` } Each field structure has become a pointer. This is necessary for optional fields: they need to distinguish between the case of the absence of a field and the case when the field contains a zero value.
Even if you do not need it, the library does not allow you to control the presence of pointers in the generated code. But not everything is so bad: it has fork gogoprotobuf , in which it is supported. To do this, you must specify the appropriate options in the proto-file:
message Test { required string label = 1 [(gogoproto.nullable) = false]; optional int32 type = 2 [(gogoproto.nullable) = false]; } Getting rid of pointers was especially important for Go to version 1.5, when the GC pauses were much longer. But even now it can give a significant increase (sometimes several times) to the performance of loaded services.
In addition to nullable , the library allows you to add a large number of other generation options that affect both the performance and the convenience of the resulting code. For example, a gostring saves the current structure with values in the Go syntax, which can be convenient for debugging or writing tests.
A suitable set of options depends on the specific situation. We almost always use at least nullable , sizer_all, unsafe_marshaler_all , unsafe_unmarshaler_all . By the way, the options that have the option with the _all suffix can be applied directly to the entire file, without duplicating them on each field:
option (gogoproto.sizer_all) = true; message Test { required string label = 1; optional int32 type = 2; } Json
In Google Protobuf, almost everything is fine, but since this is a binary protocol, it is difficult to debug it.
If you need to find problems at the level of interaction between a ready-made client and server, then you can, for example, use the gpbs-dissector for Wireshark . But this is not suitable in the case of the development of new functionality, for which there is still no client or server.
In fact, to write a test request to the service, you need a client who can wrap it in a binary message. Writing such a test client for each daemon is not very difficult, but inconvenient and routine. Therefore, our gpbrpc can handle the JSON-like presentation of the protocol on a different port other than the gpb interface. All binding for this is generated automatically (similarly, as described above for protobuf).
As a result, in the console, you can write a request in text form and immediately get an answer. This is useful for debugging.
pmurzakov@shell1.mlan:~> echo 'run {"url":"https://graph.facebook.com/?id=http%3A%2F%2Fhabrahabr.ru","task_hash":"a"}' | netcat xtc1.mlan 9531 run { "task_hash": "a", "task_status": 2, "response": { "http_status": 200, "body": "{\"og_object\":{\"id\":\"627594553918401\",\"description\":\" – , . , , – IT- .\",\"title\":\" / \",\"share\":{\"comment_count\":0,\"share_count\":2456},\"id\":\"http:\\/\\/habrahabr.ru\"}", "response_time_ms": 179 } } If the answer is voluminous, and from it you need to select some part or simply need to somehow convert it, you can use the console utility jq .
Configs
Generally to configs usually have two basic requirements:
- readability;
- opportunity to describe the structure.
In order not to introduce new entities for this, we used the fact that there is already: protobuf - structure, readability - its JSON representation.
We already have all the binding for protobuf and parser generators of its JSON representation for debug (see previous section). It remains only to add a proto-file for the config and “feed” it to this parser.
In fact, everything is a bit more complicated: since it is important for us to standardize as many different demons as possible, there is a part in the config that is the same for all demons. It is described by a generic protobuf message. The final config is a collection of the standardized part and what is specific for a particular daemon.
This approach fits well on embedding :
type FullConfig struct { badoo.ServiceConfig yourdaemon.Config } An example for clarity. A common part:
message service_config { message daemon_config_t { message listen_t { required string proto = 1; required string address = 2; optional bool pinba_enabled = 4; } repeated listen_t listen = 1; required string service_name = 2; required string service_instance_name = 3; optional bool daemonize = 4; optional string pid_file = 5; optional string log_file = 6; optional string http_pprof_addr = 7; // net/http/pprof + expvar address optional string pinba_address = 8; // ... } } Part for a specific demon:
message config { optional uint32 workers_count = 1 [default = 4000]; optional uint32 max_queue_length = 2 [default = 50000]; optional uint32 max_idle_conns_per_host = 4 [default = 1000]; optional uint32 connect_timeout_ms = 5 [default = 2000]; optional uint32 request_timeout_ms = 7 [default = 10000]; optional uint32 keep_alive_ms = 8 [default = 30000]; } As a result, JSON-config looks like this:
{ "daemon_config": { "listen": [ { "proto": "xtc-gpb", "address": "0.0.0.0:9530" }, { "proto": "xtc-gpb/json", "address": "0.0.0.0:9531" }, { "proto": "service-stats-gpb", "address": "0.0.0.0:9532" }, { "proto": "service-stats-gpb/json", "address": "0.0.0.0:9533" }, ], "service_name": "xtc", "service_instance_name": "1.mlan", "daemonize": false, "pinba_address": "pinbaxtc1.mlan:30002", "http_pprof_addr": "0.0.0.0:9534", "pid_file": "/local/xtc/run/xtc.pid", "log_file": "/local/xtc/logs/xtc.log", }, // "workers_count": 4000, "max_queue_length": 50000, "max_idle_conns_per_host": 1000, "connect_timeout_ms": 2000, "handshake_timeout_ms": 2000, "request_timeout_ms": 10000, "keep_alive_ms": 30000, } In listen , all ports that the daemon will listen to are listed. The first two elements with the xtc-gpb and xtc-gpb/json types are for the ports of the very gpbrpc and its JSON representation, which I wrote about above. And with service-stats-gpb and service-stats-gpb/json we collect statistics, which will be discussed later.
Statistics
When collecting statistics (as is the case with the standardized part of the config), it is important for each daemon to write at least the basic metrics: the number of requests served, CPU and memory consumption, network traffic, etc. This typical statistics is collected from the service-stats-gpb port service-stats-gpb , it is the same for all demons.
Requesting statistics, in fact, is no different from the usual request to the daemon, so we use all the same approaches: the statistics are described in terms of gpbrpc, as well as the usual requests. Handlers of this “standardized” statistics are already in our framework, so they do not need to be written every time for the next daemon.
By analogy with configs, except for the same statistics for all daemons, each daemon can give more specifically for it.
Once a minute, the PHP client-collector of statistics connects to the daemon, requests values and stores them in a time-series-storage. Based on this data, we build the following graphs:
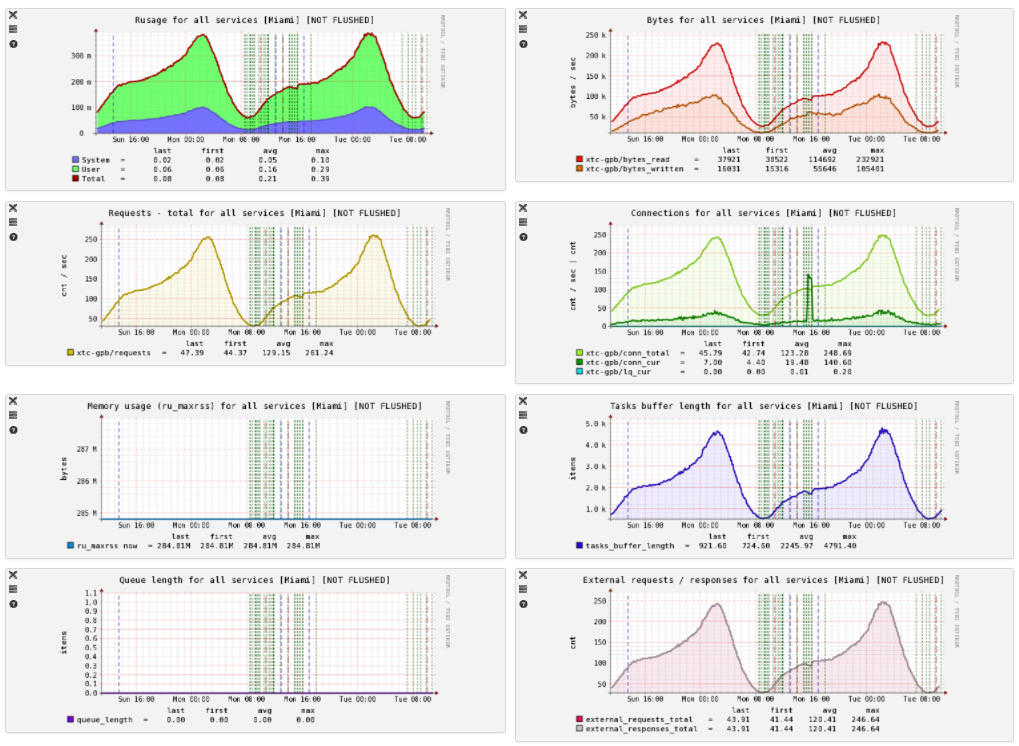
The values for the first five graphs are collected automatically from all daemons, while the others represent values specific to a particular daemon.
We have assumed that statistics does not happen much, and we try to get the maximum amount of data, so that it will be easier to deal with the problems and changes in them. Therefore, in the config you can see the parameter pinba_address , this is the address of the Pinba server, to which the daemon also sends statistics.
From Pinba, we build graphs for the response time distribution:
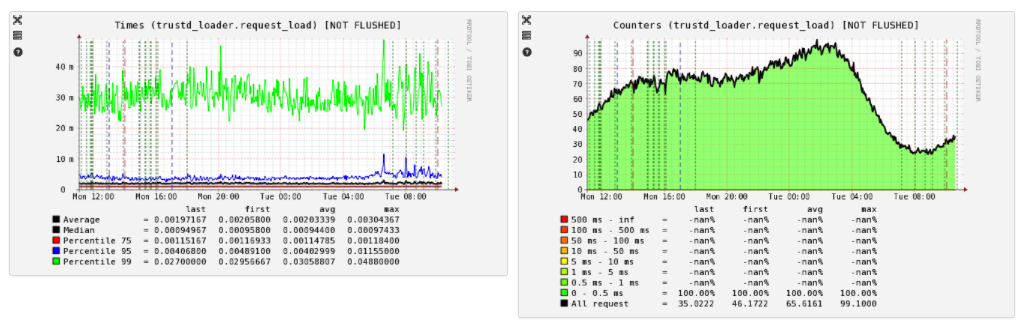
Debag and profiling
Also in the config you can see the parameter http_pprof_addr . This is the net / http / pprof port — a tool built into Go that makes it easy to profile code. Many articles have been written about him (for example, this and this ), so I will not dwell on the details of his work.
We leave pprof even in production assemblies of demons. It does not give almost any overhead projector until it is used, but adds flexibility: at any time you can connect and understand what is happening and what exactly the resources are spent on.
In addition, we use expvar , it allows one line of code to make available the values of any daemon variables via HTTP in JSON format:
expvar.Publish("varname", expvar.Func(func() interface{} { return somevariable })) By default, the expvar HTTP handler expvar added to DefaultServeMux and is available at http: // yourhost / debug / vars . The package when connected has a side effect. It automatically publishes with all parameters the command line with which the binary was launched, as well as the result of runtime.ReadMemStats() .
Caution! ReadMemStats () can now result in a stop-the-world for a long time, if a lot of memory is allocated. My colleague Marco Kevac created a ticket on this topic, and in version 1.9 this should be fixed.
In addition to the standard values, all our demons also publish a lot of debugging information, the most important is:
- config with which the daemon is running;
- the values of all statistics counters about which I wrote above;
- data on how the binary was collected.
With the first two points, I think everything is clear. The latter gives information about the Go version, under which the demon was collected, the git commit hash, the build time, and other useful information about the build.
Example:

We do this by generating a version.go file in which all this information is recorded. But a similar effect can be achieved with ldflags -X .
Logs
As a logger, we use logrus with our custom formatter. Log files using Rsyslog and Logstash are collected in Elasticsearch and subsequently displayed in a Kibana dashboard (ELK).
About why we chose these solutions, and about other details of the assembly of logs, we have already written in this article , so I will not repeat.
Workflow, tests and more
All work is done in JIRA. Each ticket is a separate branch. For each branch of the tickets TeamCity collects a binary. We use GNU Make to build, since, apart from compiling directly, we need to generate version.go and code for gpbrpc from proto-files, as well as perform a number of tasks.
We use Go 1.5 Vendor Experiment to be able to put the dependency code in the vendor directory. But, unfortunately, for now we are doing this by simply adding all the dependency files to our repository. The plans have the use of any utility for vendoring. It looks like perspective dep , it remains only to wait for its stabilization.
After the ticket passes the review, the guys from the QA-team take it. They write functional tests on new features of the daemon and check the regression. Tests are written in PHP, because in most cases it is he who is the client of the daemon in production. Thus, we guarantee that if something works in tests, it will work on production.
As for the Go tests, they are optional and are written as needed. But we are working on it and we plan to write more tests on Go (see postscript).
From tickets checked by QA and ready for release, TeamCity builds a build branch. When it is ready for display, the developer enters a special interface and finishes it. At the same time, the build branch is migrated to the master, and in the JIRA-project of administrators a ticket for a display is created.

Daemon pattern
Writing a new daemon in our conditions is simple, but nevertheless it requires some template actions: you need to create a directory structure, make a proto-file for the client-server protocol, configure and proto-file to it, write the server start code based on gpbrpc and so on . In order not to bother with this every time, we created a repository with a template daemon, in which there is a small bash script that makes a new full-fledged daemon based on this template.
Conclusion
As a result, we received the fact that, even when a new code has not yet written a single line of code, it is already ready for our infrastructure:
- configured in the same way;
- writes statistics and logs;
- communicates in the same productive (protobuf) and easily readable (JSON) protocol, as well as other demons (including those written in other languages);
- equally maintained and monitored.
This allows us not to waste developer resources and at the same time receive predictable and easily supported services.
That's all. How do you write demons on Go? Welcome to the comments!
PS Taking this opportunity, I want to say that we are looking for talents.
Much has already been written on Go, but more needs to be written, since we want to develop this area. And we are looking for an intelligent person who can help us with this.
If you are a Go-developer and know some C / C ++, write mkevac in a personal or email: m.kevac@corp.badoo.com (we look after a colleague in his team).
')
Source: https://habr.com/ru/post/328062/
All Articles