Segmentation of text lines of documents into characters using convolutional and recurrent neural networks
String segmentation into characters is one of the most important stages in the process of optical character recognition (OCR), in particular, in optical recognition of document images. Line segmentation is the decomposition of an image containing a sequence of characters into fragments containing individual characters.
The importance of segmentation is due to the fact that the basis of most modern OCR systems are classifiers (including neural network) of individual characters, and not words or text fragments. In such systems, errors of incorrect insertion of cuts between characters are usually the cause of the lion's share of final recognition errors.
The search for character boundaries is complicated due to printing artifacts and digitization (scanning) of a document, resulting in “spilling” and “gluing” characters. In the case of using stationary or mobile small-sized video cameras, the spectrum of digitization artifacts is significantly replenished: defocusing and blurring, projective distortions, deformation and bending of the document are possible. When shooting a camera in natural scenes on images often appear parasitic differences in brightness (shadows, reflections), as well as color distortion and digital noise as a result of low light. The figure below shows examples of complex cases in the segmentation of the fields of the RF passport.
')





In this article we will talk about the method of character string segmentation of text lines of documents developed by us in Smart Engines , based on the training of convolutional and recurrent neural networks. The main document considered in the work is the passport of the Russian Federation .
Machine learning methods are widely used in modern segmentation algorithms. However, their use is usually combined with additional algorithms, such as the generation of primary cuts for the learning model of character recognition, or dynamic programming on the output estimates of this model.
Of interest is the development of a segmentation algorithm that uses machine learning methods to analyze the image of a line with little or no additional preliminary and post-processing (end-to-end). Such approaches are distinguished by the fact that they do not require fine manual adjustments for a specific case (font, field type, document type), but rather representative, marked-up training samples of a sufficiently large size. This makes it possible to simplify and accelerate the creation of segmentation algorithms for new types of document fields, as well as to improve the accuracy and resistance to various distortions arising during the shooting.
When developing segmentation methods, as well as when developing any algorithms, it is required to fix a way to assess the quality of their work. It is highly desirable that this method allows the developed method to be compared with other algorithms. We describe the quality indicators used in this work to evaluate the methods of segmentation of the fields of the RF passport.
The purpose of segmentation of the text into symbols is its subsequent recognition, which determines the popularity of using the quality of the final recognition as an assessment of the quality of the segmentation algorithm. The evaluation of the quality of the recognition algorithm can be either the accuracy of recognition of individual characters or words, or the average Levenshtein distance. The quality indicators of the RF Passport Recognition System in this work put the accuracy of the full recognition of each of the document fields (name, surname, place of birth, etc.) accurate to the character due to the high cost of a single error in a single field - an error even in one The identity field symbol is critical.
However, in the case of assessing the quality of segmentation through the quality of recognition, the dependence of the estimates on the specific recognition model arises. This is a problem when developing an integrated system, since the interchangeability of various segmentation algorithms and recognition algorithms is lost. Therefore, the development used additional quality metrics based only on the analysis of the immediate boundaries between the symbols exposed by segmentation algorithms, such as accuracy, completeness, and F1-measure. This becomes possible if there is a “perfect” markup not only of characters in the fields, but also of cuts between them, prepared by people, which was prepared in this work, but not always available.
The training set contains images of selected fields of the RF passport, cut off along the base lines of the text, with marked positions of ideal cuts between the characters. The marking can be carried out both completely manually and semi-automatically - the existing segmentation algorithm inserts cuts, which are subsequently checked and, if necessary, adjusted by people.
Preparation of a sample of passports of the Russian Federation and its marking is an expensive operation, and not only because of the large amount of manual work. Identity documents contain personal information, the turnover of which is regulated by law, which is why open access to databases containing a large number of images of RF passports is not possible. Note that the creation of a fully artificial sample is also difficult due to the lack of open specifications of the background security elements of the RF passport, such as guilloche, holograms, etc.
Thus, it is problematic to draw a sample of sufficient volume for training a high precision approximator that is resistant to shooting conditions and field guidance errors. In order to increase stability, artificial expansion (augmentation) of a training sample using data transformation is used. Each sample is synthesized by applying a random set of transformations that simulate the transformation of a real field image.
To expand the training sample of RF passport fields, the following were applied: adding Gaussian noise distortion, projective distortion to simulate non-ideal finding of document boundaries in mobile shooting conditions and Gaussian blur for defocus modeling, stretching characters in height and width (these character parameters can differ greatly in passports from different regions), and vertical and horizontal shifts (the errors of the real field guidance system are modeled). Additional sampling extension methods were also used: letter shuffling and specular reflections, which is not found in natural conditions, but experiments have shown an increase in accuracy with the use of such an extension. The following are illustrations of the transformations described.
Regardless of the type of universal approximator used, for its training and operation, it is necessary to determine the loss function (error), which will be minimized on the training set at the training stage of the model parameters.
Standard deviation (MSD) is a classical loss function that satisfies the requirements for continuity and differentiability. The final answers of the segmentation algorithm are a list of the positions of the cuts, therefore, theoretically, it would be possible to adapt the standard deviation (RMS) between the corresponding output cuts and the “ideal” ones as the average distance between them. Unfortunately, in the naive implementation of this approach leads to a problem, especially when using a neural network.
The number of cuts between characters, as well as the number of characters themselves, is not fixed and the segmentation algorithm does not know in advance how many cuts are required to be stamped. Then, in the case of the coincidence of the number of cuts in the markup and at the output of the segmentation algorithm, the error function through distance fits us. However, with a different number of cuts, the problem of counting losses for missing or excessive cuts arises, especially in the presence of reasonable requirements for the loss function. In addition, the number of outputs of the neural network is fixed within a single architecture and the support of a dynamic number of outputs requires an unnecessary complication and entanglement of the model.
Thus, such markup and network output formats are required which support the setting of any allowable number of cuts, while their corresponding loss function remains usable in the training of the neural network by gradient methods. It is proposed to use the following model: instead of the list of coordinates of the sections we will consider real probabilistic estimates of the location of the section in each of the columns of image pixels. The marking of the cuts will then look like this: zeros in all positions, except for the positions of the cuts in which there are ones. The standard deviation in this case is also suitable as a function of the loss, but is already calculated between the probability estimation vectors. The final positions of the cuts at the output of the algorithm are obtained by transforming the output probability estimates, which will be described in detail later.
Small fluctuations regarding cuts from the markup usually do not strongly affect the quality of recognition, especially if the segmentation algorithm places the cuts not directly on the character boundaries (so that there are two cuts between two characters), but in the middle area (there is one cut between the characters). The loss function proposed above in this case will equally penalize the output probabilities at positions that do not correspond to ideal cuts, regardless of their distance. Therefore, to mitigate the fine with small fluctuations in the output of the network, it is proposed to use a Gaussian markup blur with a radius proportional to the average width of the character in this image from the test set.
One of the most popular neural network architectures in image analysis tasks is the deep convolutional network architecture, which was chosen for the first substantial experiments in creating our segmented student method. The classical model of a convolutional network consists of several convolutional layers that make up feature maps by applying a convolution operation to a trained core, alternating with sub-sampling (max pooling) in order to reduce the dimension of the feature map. The last layers (ending with the output layer) have a fully connected architecture.
For neural networks used in the work, the input data (feature vectors) are half-tone raster images of RF passport fields, reduced to a fixed width and height, for example, 200x20 pixels. The size of the output layer, which returns probabilistic estimates of the presence of a cut in the image columns, respectively, is also fixed and is 200 pixels. The following is a diagram of the convolutional neural network used in the work.

The hidden part of the neural network consists of convolutional layers, followed by two fully connected layers. Each convolutional layer is followed by a downsampling layer. The hyperbolic tangent was used as activation functions. During the training, a technique of random selective zeroing of the activation functions (dropout) of hidden layers was used.
In order to increase the accuracy of the trained segmentation network of the described architecture, the method of post-processing the outputs of the convolutional network was applied by submitting them to the input of an additional two-way recurrent network.
Recurrent neural networks are designed specifically for working with sequences: besides the next element of the sequence, they take their own hidden state as input. Recurrent neural networks of the long short-term memory architecture (LSTM, Long Short-Term Memory) have been used in the work, which have proven themselves in a large number of applications of sequence analysis, such as recognition of printed and handwritten text, speech, and others. LSTM architecture networks are able to “memorize” the structure of a sequence; in the case of line segmentation, the structure can be understood, for example, the average width of characters in a line and the distance between them.
The two-way recurrent LSTM network used accepts a sequence composed by applying a fixed-size sliding window (for example, 10) to the output vector of probability estimates of a convolutional network. Thus, the i position of the input vector of the recurrent network contains the last 10 outputs of the convolutional network. The bilateral orientation of the network consists in the creation of two one-way networks, one of which processes the sequence from left to right, and the other from right to left. Then, the output vectors of both networks, corresponding to the same positions of the original sequence, are concatenated and transmitted to the input to the fully connected layer, followed by the final layer, returning the same final probabilistic estimates. It is important to note that the outputs of the convolutional network, on which recurrent training is conducted, are calculated in advance, so the convolutional network does not change when training is recurrent, which greatly speeds up training. The figure below contains the scheme of the used architecture of the recurrent network at the outputs of the convolutional network.

After adding a recurrent network at the outputs of the convolutional network, the overall final recognition quality improved significantly, which will be shown in the table at the end of the article. The activation function in the LSTM network was also a hyperbolic tangent.
To obtain the final positions of the cuts at the output of the algorithm, it is necessary to perform a conversion of probability estimates. Simple threshold filtering will not work in this case, since the network’s output assessments are concentrated in large numbers around the proposed cuts. Since the neural network approximated the markup subjected to Gaussian blurring around the positions of the cuts, filtering can be a fairly stable and simple way to convert probabilities to cuts, leaving only local maximums of the estimates following the threshold cut with a low threshold. To eliminate noise positives, additional Gaussian blur is used, which does not change the position of strong maxima.
The method of filtering local maxima is simple and showed good results, but we decided to check whether it is possible to completely get rid of the “engineering” approach at the stage of probability conversion. For the purpose of the experiment, another network of a fully connected architecture with a small number of weights was trained, taking the final probabilistic outputs of the resulting network as input, and returning similar probabilistic estimates at the output. The difference is that it is trained on the original marks of the cuts, which were not subjected to Gaussian blurring. Probabilistic estimates at the output of the last network are already subjected to simple threshold filtering without additional processing to obtain the final positions of the cuts. The following figure shows examples of how the segmentation algorithm described by the student works with the output of intermediate results.






The probabilistic estimates at the outputs of the convolutional network are marked with a red background, and the yellow - following recurrent one. Green color indicates probabilistic estimates of the recurrent network, filtered by a fixed threshold, and finally, blue shows the remaining cuts — filtered estimates that are local maxima.
The main fields of the passport of the Russian Federation in the experiments were the fields of the last name, first name and patronymic. The size of the initial training sample was 6000 images, after its expansion with the help of data synthesis - 150,000 images. The size of the test sample for evaluating segmentation with auxiliary metrics without recognition is 630 images. The test sample for field recognition contained 1300 images of RF passports, one image of each field on the document.
When recognizing fields on the results of segmentation, the same RF passport recognition system was used, which was not changed. It is important to note that the neural network intended for field recognition was trained on symbols subjected to compression using the classic "engineering" segmentation methods, and the cuts exposed by the trained segmentation algorithm were transmitted without additional processing and compression to the recognition system. The following table contains the experimental results of the accuracy of the final recognition of the fields (the proportion of fully correctly recognized fields).
The table shows that the addition of a recurrent network at the outputs of a convolutional network in the segmentation subsystem greatly improves the accuracy of field recognition. Note that the process of processing includes finding the boundaries of a passport in natural conditions when shooting from mobile devices, which explains the imperfect recognition accuracy - the most unfavorable sample was chosen from the point of view of distortions arising from the survey, etc.
In the experiments with the trained segmentation methods, the implementation of neural networks from the Lasagne package in the Python language was used. The trained models were further converted into our internal format C ++ libraries of neural networks.
The article examined the method of segmentation of printed text fields and conducted its experimental analysis on the example of the segmentation module module of the passport recognition system of a citizen of the Russian Federation. The method uses machine learning approaches (artificial neural networks) at almost all stages of work, which makes the setup process for new types of fields and documents fully automatic, subject to the availability of a training set, which makes the method promising.
As a further study of the segmentation method based on machine learning approaches, it is planned to conduct experiments on other types of fields and documents, analyze and classify errors in order to form new ways to expand the training set, as well as profiling and optimizing the performance of the method on mobile devices, for example, reducing the number of trained parameters. Also, of interest is the study of methods for the complete recognition of whole words or fields without segmentation using recurrent neural networks.
The importance of segmentation is due to the fact that the basis of most modern OCR systems are classifiers (including neural network) of individual characters, and not words or text fragments. In such systems, errors of incorrect insertion of cuts between characters are usually the cause of the lion's share of final recognition errors.
The search for character boundaries is complicated due to printing artifacts and digitization (scanning) of a document, resulting in “spilling” and “gluing” characters. In the case of using stationary or mobile small-sized video cameras, the spectrum of digitization artifacts is significantly replenished: defocusing and blurring, projective distortions, deformation and bending of the document are possible. When shooting a camera in natural scenes on images often appear parasitic differences in brightness (shadows, reflections), as well as color distortion and digital noise as a result of low light. The figure below shows examples of complex cases in the segmentation of the fields of the RF passport.
')
In this article we will talk about the method of character string segmentation of text lines of documents developed by us in Smart Engines , based on the training of convolutional and recurrent neural networks. The main document considered in the work is the passport of the Russian Federation .
"End-to-end" segmentation using machine learning methods
Machine learning methods are widely used in modern segmentation algorithms. However, their use is usually combined with additional algorithms, such as the generation of primary cuts for the learning model of character recognition, or dynamic programming on the output estimates of this model.
Of interest is the development of a segmentation algorithm that uses machine learning methods to analyze the image of a line with little or no additional preliminary and post-processing (end-to-end). Such approaches are distinguished by the fact that they do not require fine manual adjustments for a specific case (font, field type, document type), but rather representative, marked-up training samples of a sufficiently large size. This makes it possible to simplify and accelerate the creation of segmentation algorithms for new types of document fields, as well as to improve the accuracy and resistance to various distortions arising during the shooting.
Quality assessment of segmentation methods
When developing segmentation methods, as well as when developing any algorithms, it is required to fix a way to assess the quality of their work. It is highly desirable that this method allows the developed method to be compared with other algorithms. We describe the quality indicators used in this work to evaluate the methods of segmentation of the fields of the RF passport.
The purpose of segmentation of the text into symbols is its subsequent recognition, which determines the popularity of using the quality of the final recognition as an assessment of the quality of the segmentation algorithm. The evaluation of the quality of the recognition algorithm can be either the accuracy of recognition of individual characters or words, or the average Levenshtein distance. The quality indicators of the RF Passport Recognition System in this work put the accuracy of the full recognition of each of the document fields (name, surname, place of birth, etc.) accurate to the character due to the high cost of a single error in a single field - an error even in one The identity field symbol is critical.
However, in the case of assessing the quality of segmentation through the quality of recognition, the dependence of the estimates on the specific recognition model arises. This is a problem when developing an integrated system, since the interchangeability of various segmentation algorithms and recognition algorithms is lost. Therefore, the development used additional quality metrics based only on the analysis of the immediate boundaries between the symbols exposed by segmentation algorithms, such as accuracy, completeness, and F1-measure. This becomes possible if there is a “perfect” markup not only of characters in the fields, but also of cuts between them, prepared by people, which was prepared in this work, but not always available.
Preparation and artificial expansion of the training sample
The training set contains images of selected fields of the RF passport, cut off along the base lines of the text, with marked positions of ideal cuts between the characters. The marking can be carried out both completely manually and semi-automatically - the existing segmentation algorithm inserts cuts, which are subsequently checked and, if necessary, adjusted by people.
Preparation of a sample of passports of the Russian Federation and its marking is an expensive operation, and not only because of the large amount of manual work. Identity documents contain personal information, the turnover of which is regulated by law, which is why open access to databases containing a large number of images of RF passports is not possible. Note that the creation of a fully artificial sample is also difficult due to the lack of open specifications of the background security elements of the RF passport, such as guilloche, holograms, etc.
Thus, it is problematic to draw a sample of sufficient volume for training a high precision approximator that is resistant to shooting conditions and field guidance errors. In order to increase stability, artificial expansion (augmentation) of a training sample using data transformation is used. Each sample is synthesized by applying a random set of transformations that simulate the transformation of a real field image.
To expand the training sample of RF passport fields, the following were applied: adding Gaussian noise distortion, projective distortion to simulate non-ideal finding of document boundaries in mobile shooting conditions and Gaussian blur for defocus modeling, stretching characters in height and width (these character parameters can differ greatly in passports from different regions), and vertical and horizontal shifts (the errors of the real field guidance system are modeled). Additional sampling extension methods were also used: letter shuffling and specular reflections, which is not found in natural conditions, but experiments have shown an increase in accuracy with the use of such an extension. The following are illustrations of the transformations described.
| Transformation | Illustration |
|---|---|
| Original image |  |
| Gaussian noise |  |
| Projective distortion |  |
| Gaussian blur |  |
| Shifts |  |
| Letter shuffle |  |
| Reflections | 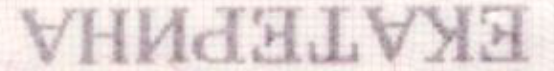 |
| Stretching |  |
| Transformation Combination |  |
Layout layout and output network vectors
Regardless of the type of universal approximator used, for its training and operation, it is necessary to determine the loss function (error), which will be minimized on the training set at the training stage of the model parameters.
Standard deviation (MSD) is a classical loss function that satisfies the requirements for continuity and differentiability. The final answers of the segmentation algorithm are a list of the positions of the cuts, therefore, theoretically, it would be possible to adapt the standard deviation (RMS) between the corresponding output cuts and the “ideal” ones as the average distance between them. Unfortunately, in the naive implementation of this approach leads to a problem, especially when using a neural network.
The number of cuts between characters, as well as the number of characters themselves, is not fixed and the segmentation algorithm does not know in advance how many cuts are required to be stamped. Then, in the case of the coincidence of the number of cuts in the markup and at the output of the segmentation algorithm, the error function through distance fits us. However, with a different number of cuts, the problem of counting losses for missing or excessive cuts arises, especially in the presence of reasonable requirements for the loss function. In addition, the number of outputs of the neural network is fixed within a single architecture and the support of a dynamic number of outputs requires an unnecessary complication and entanglement of the model.
Thus, such markup and network output formats are required which support the setting of any allowable number of cuts, while their corresponding loss function remains usable in the training of the neural network by gradient methods. It is proposed to use the following model: instead of the list of coordinates of the sections we will consider real probabilistic estimates of the location of the section in each of the columns of image pixels. The marking of the cuts will then look like this: zeros in all positions, except for the positions of the cuts in which there are ones. The standard deviation in this case is also suitable as a function of the loss, but is already calculated between the probability estimation vectors. The final positions of the cuts at the output of the algorithm are obtained by transforming the output probability estimates, which will be described in detail later.
Small fluctuations regarding cuts from the markup usually do not strongly affect the quality of recognition, especially if the segmentation algorithm places the cuts not directly on the character boundaries (so that there are two cuts between two characters), but in the middle area (there is one cut between the characters). The loss function proposed above in this case will equally penalize the output probabilities at positions that do not correspond to ideal cuts, regardless of their distance. Therefore, to mitigate the fine with small fluctuations in the output of the network, it is proposed to use a Gaussian markup blur with a radius proportional to the average width of the character in this image from the test set.
Segmentation using convolutional neural networks
One of the most popular neural network architectures in image analysis tasks is the deep convolutional network architecture, which was chosen for the first substantial experiments in creating our segmented student method. The classical model of a convolutional network consists of several convolutional layers that make up feature maps by applying a convolution operation to a trained core, alternating with sub-sampling (max pooling) in order to reduce the dimension of the feature map. The last layers (ending with the output layer) have a fully connected architecture.
For neural networks used in the work, the input data (feature vectors) are half-tone raster images of RF passport fields, reduced to a fixed width and height, for example, 200x20 pixels. The size of the output layer, which returns probabilistic estimates of the presence of a cut in the image columns, respectively, is also fixed and is 200 pixels. The following is a diagram of the convolutional neural network used in the work.
The hidden part of the neural network consists of convolutional layers, followed by two fully connected layers. Each convolutional layer is followed by a downsampling layer. The hyperbolic tangent was used as activation functions. During the training, a technique of random selective zeroing of the activation functions (dropout) of hidden layers was used.
Additional segmentation using recurrent neural LSTM networks
In order to increase the accuracy of the trained segmentation network of the described architecture, the method of post-processing the outputs of the convolutional network was applied by submitting them to the input of an additional two-way recurrent network.
Recurrent neural networks are designed specifically for working with sequences: besides the next element of the sequence, they take their own hidden state as input. Recurrent neural networks of the long short-term memory architecture (LSTM, Long Short-Term Memory) have been used in the work, which have proven themselves in a large number of applications of sequence analysis, such as recognition of printed and handwritten text, speech, and others. LSTM architecture networks are able to “memorize” the structure of a sequence; in the case of line segmentation, the structure can be understood, for example, the average width of characters in a line and the distance between them.
The two-way recurrent LSTM network used accepts a sequence composed by applying a fixed-size sliding window (for example, 10) to the output vector of probability estimates of a convolutional network. Thus, the i position of the input vector of the recurrent network contains the last 10 outputs of the convolutional network. The bilateral orientation of the network consists in the creation of two one-way networks, one of which processes the sequence from left to right, and the other from right to left. Then, the output vectors of both networks, corresponding to the same positions of the original sequence, are concatenated and transmitted to the input to the fully connected layer, followed by the final layer, returning the same final probabilistic estimates. It is important to note that the outputs of the convolutional network, on which recurrent training is conducted, are calculated in advance, so the convolutional network does not change when training is recurrent, which greatly speeds up training. The figure below contains the scheme of the used architecture of the recurrent network at the outputs of the convolutional network.
After adding a recurrent network at the outputs of the convolutional network, the overall final recognition quality improved significantly, which will be shown in the table at the end of the article. The activation function in the LSTM network was also a hyperbolic tangent.
Transformation of probability estimates into final cuts
To obtain the final positions of the cuts at the output of the algorithm, it is necessary to perform a conversion of probability estimates. Simple threshold filtering will not work in this case, since the network’s output assessments are concentrated in large numbers around the proposed cuts. Since the neural network approximated the markup subjected to Gaussian blurring around the positions of the cuts, filtering can be a fairly stable and simple way to convert probabilities to cuts, leaving only local maximums of the estimates following the threshold cut with a low threshold. To eliminate noise positives, additional Gaussian blur is used, which does not change the position of strong maxima.
The method of filtering local maxima is simple and showed good results, but we decided to check whether it is possible to completely get rid of the “engineering” approach at the stage of probability conversion. For the purpose of the experiment, another network of a fully connected architecture with a small number of weights was trained, taking the final probabilistic outputs of the resulting network as input, and returning similar probabilistic estimates at the output. The difference is that it is trained on the original marks of the cuts, which were not subjected to Gaussian blurring. Probabilistic estimates at the output of the last network are already subjected to simple threshold filtering without additional processing to obtain the final positions of the cuts. The following figure shows examples of how the segmentation algorithm described by the student works with the output of intermediate results.
The probabilistic estimates at the outputs of the convolutional network are marked with a red background, and the yellow - following recurrent one. Green color indicates probabilistic estimates of the recurrent network, filtered by a fixed threshold, and finally, blue shows the remaining cuts — filtered estimates that are local maxima.
Experiments and Results
The main fields of the passport of the Russian Federation in the experiments were the fields of the last name, first name and patronymic. The size of the initial training sample was 6000 images, after its expansion with the help of data synthesis - 150,000 images. The size of the test sample for evaluating segmentation with auxiliary metrics without recognition is 630 images. The test sample for field recognition contained 1300 images of RF passports, one image of each field on the document.
When recognizing fields on the results of segmentation, the same RF passport recognition system was used, which was not changed. It is important to note that the neural network intended for field recognition was trained on symbols subjected to compression using the classic "engineering" segmentation methods, and the cuts exposed by the trained segmentation algorithm were transmitted without additional processing and compression to the recognition system. The following table contains the experimental results of the accuracy of the final recognition of the fields (the proportion of fully correctly recognized fields).
| Segmentation algorithm | Surname,% | Name% | Middle name, % |
|---|---|---|---|
| Convolution network | 68.53 | 76.00 | 78.30 |
| Recurrent network at the outputs of the convolution network | 86.23 | 90.69 | 91.38 |
The table shows that the addition of a recurrent network at the outputs of a convolutional network in the segmentation subsystem greatly improves the accuracy of field recognition. Note that the process of processing includes finding the boundaries of a passport in natural conditions when shooting from mobile devices, which explains the imperfect recognition accuracy - the most unfavorable sample was chosen from the point of view of distortions arising from the survey, etc.
In the experiments with the trained segmentation methods, the implementation of neural networks from the Lasagne package in the Python language was used. The trained models were further converted into our internal format C ++ libraries of neural networks.
Conclusion
The article examined the method of segmentation of printed text fields and conducted its experimental analysis on the example of the segmentation module module of the passport recognition system of a citizen of the Russian Federation. The method uses machine learning approaches (artificial neural networks) at almost all stages of work, which makes the setup process for new types of fields and documents fully automatic, subject to the availability of a training set, which makes the method promising.
As a further study of the segmentation method based on machine learning approaches, it is planned to conduct experiments on other types of fields and documents, analyze and classify errors in order to form new ways to expand the training set, as well as profiling and optimizing the performance of the method on mobile devices, for example, reducing the number of trained parameters. Also, of interest is the study of methods for the complete recognition of whole words or fields without segmentation using recurrent neural networks.
Source: https://habr.com/ru/post/328000/
All Articles