Experience DataLine: the work of technical support service

On the calendar is May, which means “gray zone” of holidays. Anyone who has failed service during the holidays knows what two weeks are, in which there are more days off than working days. On this occasion, we tell you how our technical support is arranged and what happens with the bids that came in the night from Saturday to Sunday. At the end of the article - a small checklist for drafting a request for technical support. So that on the other end of the line they understand you correctly and quickly help you.
The structure of our technical support
All customer requests are first received by operators by phone or mail. They process and register them around the clock. The operator is a kind of “zero kilometer”, from where the application, depending on the profile, complexity and criticality, falls into the required level of technical support. There are three such levels in total.
First line support
Duty engineers. They assemble and dismantle equipment, pave the ACS, escort customers to the data center, monitor the monitoring system. Work in 24x7 mode.
Duty administrators. Understand the support of physical, virtual, network infrastructure, operating system and software, but can only solve typical tasks according to the instructions. They work 24x7.
')
Engineers of specialized groups: virtualization, network, hardware, operation of the data center engineering infrastructure, information security, DBMS, Microsoft, Linux / Unix, AIX, SAP basis, monitoring. Solve problems for the systems for which they are responsible, in 8x5 mode. Daily in each department appointed on duty. The profile group engineer is connected if the task is not trivial, and the knowledge of the administrator on duty is not enough. In critical situations, it can attract to the solution of the problem at night and on weekends.
Duty on engineering infrastructure. Respond to inquiries related to the main engineering systems (power supply, refrigeration, monitoring, etc.), during off-hours. At each site, one person on duty carries the watch around the clock. If complex incidents occur, the duty officer of the engineering infrastructure of the data center is attracted.
Second line of support
Senior engineers of specialized groups. More experienced engineers. Solve tasks that can not be performed according to the instructions.
Third line support
Leading engineers profile group. Responsible for the most difficult tasks.
Team leader. Controls critical messages (loss of network connectivity, equipment failure or service failure) and accidents at the level of the entire infrastructure.
It turns out such a scheme:

Circulation path in technical support
There are two sources of requests - clients and information about failures from the monitoring system. All customer requests are divided into regular requests and incidents - requests related to the unavailability of the service. Here is the path the application takes from the client:
Registration of the appeal. When registering a call in the ticket system, the operator does the following:
- describes the essence of the appeal;
- determines the type - request or incident;
- establishes priority and deadline;
- appoints a profile group or a specific artist;
- records customer contact details;
- informs the client's account manager about the incoming call.
The operator is given 5-15 minutes to register an appeal, depending on the priority of the request. A unique six-digit identifier is assigned to the application, according to which the client will be able to track the status of his application.
The appointment of the artist. If the appeal comes during working hours, the operator sends it to the duty engineer or engineer of the profile group. At non-working hours, the application is handled by the engineer on duty or the administrator on duty.
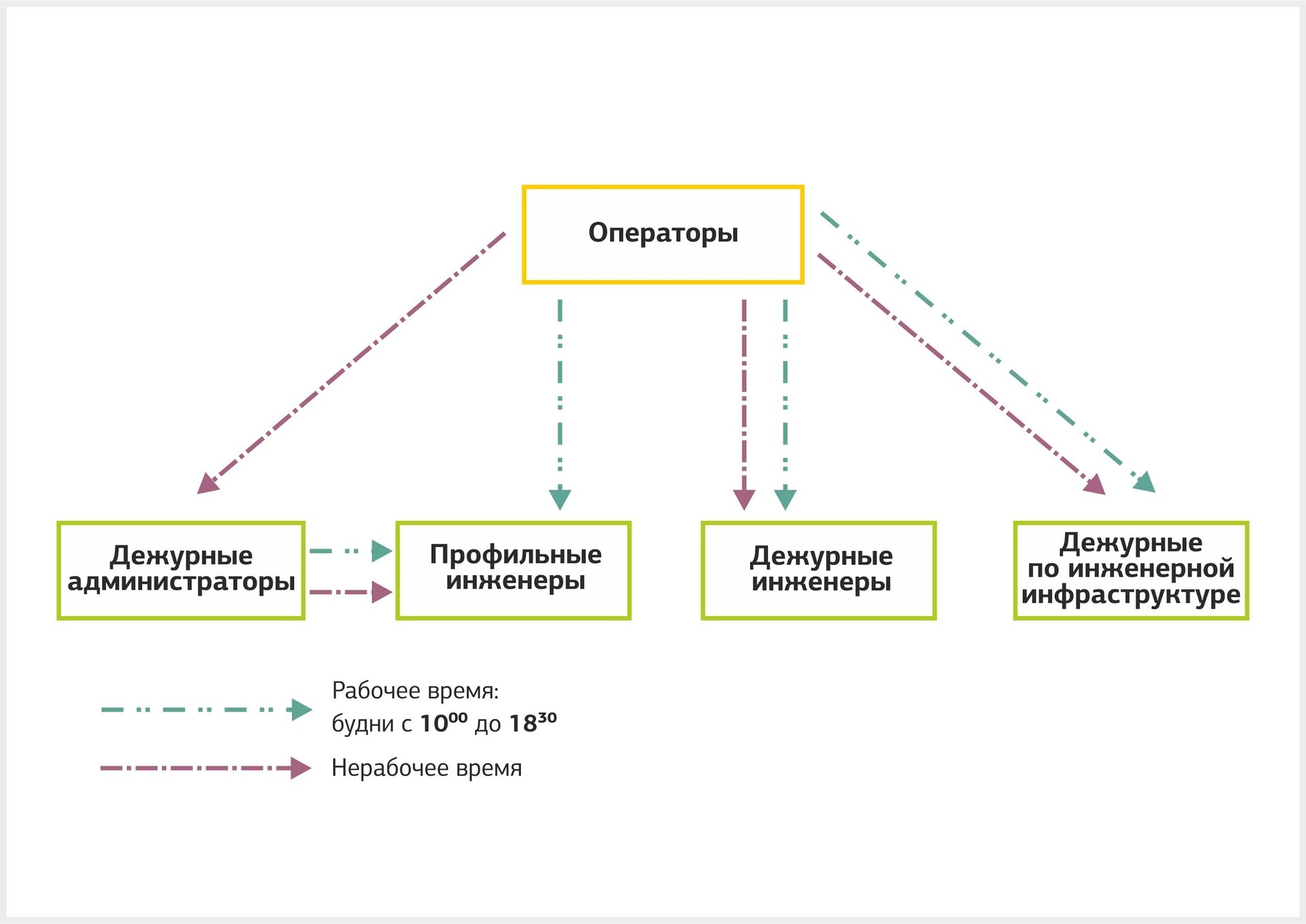
Scheme of appointment of the performer, depending on when the appeal was received.
Permission treatment. Duty administrators handle customer requests according to the instructions. If it does not have a typical solution, the administrator sends it to the second support line. There are situations when an appeal is assigned to one profile group, but for the solution it is necessary to involve engineers responsible for other systems. Information about this is sent to the operator and account manager, and the application is transferred to the appropriate group.
If the incident cannot be closed within the time set by the SLA, it is escalated to the second and third support lines. In the event of an accident, the directorate is connected to analyze the incident. When it is impossible to fix the problem on our own, we attract contractors.
Closing appeal. After the request is completed or the incident is resolved, the executor prepares a report and sends the request to the account manager. He receives a confirmation from the client about the permission of the application, the appeal is closed and transferred to the “Resolved” status.
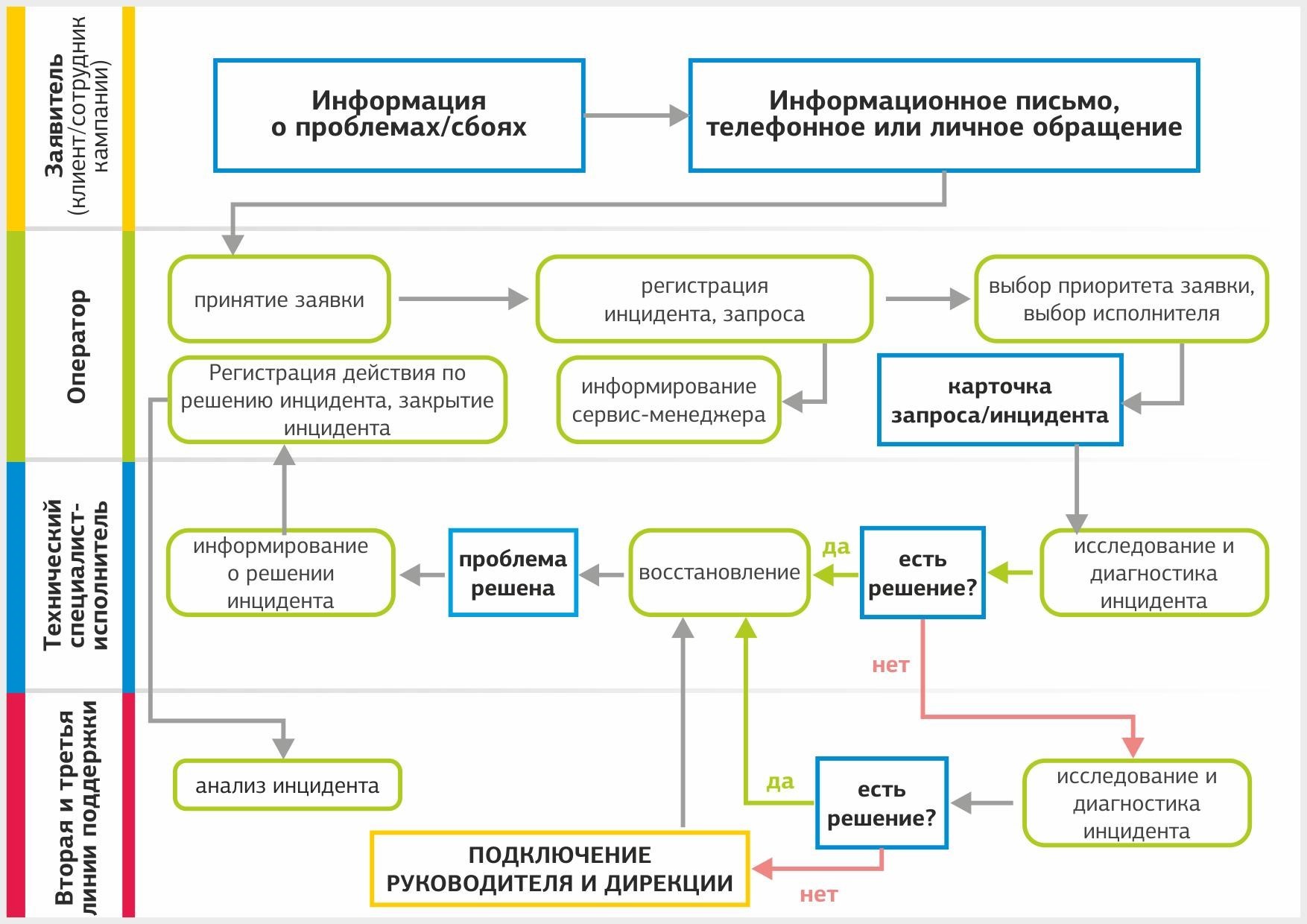
The incident management process looks like this.
Appeals and notifications from the monitoring system pass this way. Now let's see how the regular query and incident are resolved with examples.
Practicing a regular request
Suppose a client on Saturday wants to deploy a virtual infrastructure with two MS SQL servers.
13:00 The client sends a request to the support service and after 4 hours plans to start working with new servers.
13:05 The operator registers the request in the system and sends it to the first line of support - the profile engineer of the virtualization group.
13:30 The client has been allocated virtual resources, and he can already work with them. To create SQL servers, the virtualization engineer moves the query further to the Microsoft group.
15:30 The Microsoft team engineer deployed MS SQL virtual machines and prepared the servers for work: updated software versions, expanded disks, and tested services. Creating and setting up the VM took about 2 hours.
15:35 . Account Manager confirmed the execution of the request from the client.
The client can start working on new virtual servers.
So regular requests are fulfilled. There is no hurry, although there is also a time limit. But what to do if there is a service failure and the bill goes on for minutes. On this subject, we have a real story that happened not so long ago.
Incident handling
We have our own fiber-optic backbone in Moscow connecting our data centers and client sites. In mid-March, an accident occurred between the OST and NORD data centers. Here is a chronology of events and actions of our technical support.
March 15, 2017
02:00 The monitoring system recorded a loss of OST - NORD connectivity. The administrator on duty registered the incident and assigned it to the network team. Since the communication breakdown affected our and client routes, the incident was immediately escalated to the FOCL leading engineer and network team leader.
02:15 The duty engineer of the network team contacted the contractor serving the fiber optic line.
04:00 Lead engineer of the network department identified the alleged location of the cliff from the data center OST. The attendant of the service company went to the site for inspection.
Also, engineers found that as a result of the accident, clients who rent dark optics suffered. Lists of affected clients were transferred to account managers so that they would notify clients of the accident and collect information about communication breaks.
04:35 . Network engineers, together with the contractor’s on-duty engineer, determined that the break occurred at the site of the Krasnoselsky collector and contacted the Moskollektor state unitary enterprise. The dispatcher reported a fire on PK-42 of the Krasnoselsky collector and accepted an application for the admission of a repair brigade, but warned that access to the collector was closed until the circumstances were clarified.
08:00 A telephone message was sent to the State Unitary Enterprise “Moskollektor” with a repeated request for the emergency admission of the repair team of the contractor to the territory of the collector.
08:15 SUE "Moskollektor" reported disconnecting the power cables and localize the fire. But access to the collector for telecom operators was still closed until 03/16/2017, before the restoration of city-wide communications, engineering networks and identifying the causes of the accident from the RF IC and employees of the State Unitary Enterprise Mosklectorker.
09:00 Engineers began to switch affected customers to backup routes. Some customers had their own backup optical paths, and they were able to switch quickly. Clients who do not have a reserve were switched to their own backup routes.
3:00 pm All affected customers are transferred to backup routes.
March 16, 2017
09:00 The repair team of the contractor was finally able to get into the collector and determine the amount of restoration work.

10:30 Found that as a result of fire damaged 144 fibers. It was decided to organize the cable insert.

11:00 We started laying the cable in the collector.
4pm Restored working fibers on the highway.
20:40 . Installation work is completed, the trunk cable is fully restored. All customers are transferred to the main routes.
As a result, the elimination of the accident took 40 hours.
How to write in technical support
Much depends on the reaction speed and competence of technical support. But the one who writes also affects the speed of the solution. Remember: the exactly described query is useful for administrators health and helps to solve the problem faster.
We have compiled a pre-holiday memo on how to write to tech support:
- Try to uniquely identify the object of service. Specify the number of the rack unit, the name of the VM, the system or application to which the request relates.
- Specify what does not work or what kind of administrative work is required.
- If any actions were performed before an error occurred, report them. Have the system settings been changed, have external failures (disconnected Internet connection or power supply).
- Was there an unexpected high system load?
- Whether system diagnostics were performed, what diagnostic tools were used, and what results the diagnostics showed.
- Have adjacent systems been tested?
- What else has been verified?
Today it is all waiting for your questions in the comments.
Source: https://habr.com/ru/post/327962/
All Articles