Bash scripts, part 9: regular expressions
Bash scripts: start
Bash scripts, part 2: loops
Bash scripts, part 3: command line options and keys
Bash scripts, part 4: input and output
Bash Scripts, Part 5: Signals, Background Tasks, Script Management
Bash scripts, part 6: functions and library development
Bash scripts, part 7: sed and word processing
Bash scripts, part 8: awk data processing language
Bash scripts, part 9: regular expressions
Bash scripts, part 10: practical examples
Bash scripts, part 11: expect and automate interactive utilities
In order to fully process texts in bash scripts using sed and awk, you just need to deal with regular expressions. Implementations of this most useful tool can be found literally everywhere, and although all regular expressions are arranged in a similar way, they are based on the same ideas, working with them in different environments has certain features. Here we talk about regular expressions that are suitable for use in Linux command line scripts.

This material is intended as an introduction to regular expressions, designed for those who may be completely unaware of what it is. So let's start from the beginning.

What are regular expressions?
For many, when they first see regular expressions, the thought immediately arises that there is a senseless jumble of symbols in front of them. But this, of course, is far from the case. Take a look at this regular expression, for example.
')
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$ In our opinion, even an absolute newcomer will immediately understand how it is arranged and why it is necessary :) If you are not completely clear, just read on and everything will fall into place.
A regular expression is a pattern, using which programs like sed or awk filter texts. Templates use ordinary ASCII characters that represent themselves, and so-called metacharacters, which play a special role, for example, allowing you to refer to certain groups of characters.
Regular Expression Types
Implementations of regular expressions in various environments, for example, in programming languages like Java, Perl and Python, in Linux tools like sed, awk and grep, have certain features. These features depend on the so-called regular expression engines that interpret patterns.
Linux has two regular expression engines:
- Engine that supports the standard POSIX Basic Regular Expression (BRE).
- Engine that supports the standard POSIX Extended Regular Expression (ERE).
Most Linux utilities are at least compliant with the POSIX BRE standard, but some utilities (including sed) understand only a subset of the BRE standard. One of the reasons for this limitation is the desire to make such utilities as fast as possible in word processing.
The POSIX ERE standard is often implemented in programming languages. It allows you to use a large number of tools when developing regular expressions. For example, it can be special sequences of characters for frequently used patterns, such as searching individual words in a text or sets of numbers. Awk supports the ERE standard.
There are many ways to develop regular expressions that depend on the programmer’s opinion and on the features of the engine for which they are created. It’s not easy to write universal regular expressions that any engine can understand. Therefore, we will focus on the most commonly used regular expressions and consider the features of their implementation for sed and awk.
POSIX BRE Regular Expressions
Perhaps the simplest BRE pattern is a regular expression for finding the exact occurrence of a sequence of characters in a text. Here's what the search string looks for in sed and awk:
$ echo "This is a test" | sed -n '/test/p' $ echo "This is a test" | awk '/test/{print $0}' 
Find text by pattern in sed

Awk text search pattern
You may notice that the search for a given template is performed without taking into account the exact location of the text in the string. In addition, the number of entries does not matter. After the regular expression finds the specified text anywhere in the line, the line is considered suitable and passed for further processing.
When working with regular expressions, it is necessary to take into account that they are case sensitive:
$ echo "This is a test" | awk '/Test/{print $0}' $ echo "This is a test" | awk '/test/{print $0}' 
Regular expressions are case sensitive
The first regular expression of matches did not find, since the word "test", starting with a capital letter, is not found in the text. The second, configured to search for words written in capital letters, found in the stream a suitable line.
In regular expressions, you can use not only letters, but also spaces and numbers:
$ echo "This is a test 2 again" | awk '/test 2/{print $0}' 
Search for a piece of text containing spaces and numbers
Spaces are perceived by the regular expression engine as ordinary characters.
Special symbols
When using different characters in regular expressions, it is necessary to consider some features. So, there are some special characters, or metacharacters, the use of which in a template requires a special approach. Here they are:
.*[]^${}\+?|() If one of them is needed in the template, it will need to be escaped with a backslash (backslash) -
\ .For example, if you need to find a dollar sign in the text, it must be included in the template, preceded by the escape character. Let's say there is a file
myfile with the following text: There is 10$ on my pocket The dollar sign can be detected using this pattern:
$ awk '/\$/{print $0}' myfile 
Using a special character in a pattern
In addition, the backslash is also a special character, so if you need to use it in a template, it will also need to be escaped. It looks like two slashes coming one after the other:
$ echo "\ is a special character" | awk '/\\/{print $0}' 
Backslash Escaping
Although forward slash is not included in the above list of special characters, trying to use it in a regular expression written for sed or awk will result in an error:
$ echo "3 / 2" | awk '///{print $0}' 
Incorrect use of a forward slash in a pattern
If it is needed, it should also be screened:
$ echo "3 / 2" | awk '/\//{print $0}' 
Forward slash escaping
Anchor symbols
There are two special characters to bind a template to the beginning or end of a text line. The symbol “cover” -
^ allows you to describe sequences of characters that are at the beginning of text lines. If the pattern you are looking for appears elsewhere in the string, the regular expression will not respond to it. This symbol looks like this: $ echo "welcome to likegeeks website" | awk '/^likegeeks/{print $0}' $ echo "likegeeks website" | awk '/^likegeeks/{print $0}' 
Search for a template at the beginning of a line
The
^ symbol is designed to search for a pattern at the beginning of a line, while the case of characters is also taken into account. Let's see how this will affect the processing of a text file: $ awk '/^this/{print $0}' myfile 
Search for a template at the beginning of a line in the text from a file
When using sed, if you put a cap somewhere inside the pattern, it will be perceived as any other ordinary character:
$ echo "This ^ is a test" | sed -n '/s ^/p' 
A cap that is not at the beginning of the pattern in sed
In awk, when using the same pattern, this symbol must be escaped:
$ echo "This ^ is a test" | awk '/s \^/{print $0}' 
A cap that is not at the beginning of an awk pattern
With the search for fragments of text located at the beginning of the line we figured out. What if you need to find something located at the end of the line?
This will help us dollar sign -
$ , which is the anchor character of the end of the line: $ echo "This is a test" | awk '/test$/{print $0}' 
Search for text at the end of the line
In the same pattern, you can use both anchor symbols. Perform the processing of the file
myfile , the contents of which are shown in the figure below, using this regular expression: $ awk '/^this is a test$/{print $0}' myfile 
A pattern that uses special beginning and ending line characters.
As you can see, the template responded only to the line that fully corresponds to the specified sequence of characters and their location.
Here's how, using anchor characters, to filter empty lines:
$ awk '!/^$/{print $0}' myfile In this template used the symbol of negation, an exclamation mark -
! . Through the use of such a pattern, it searches for lines containing nothing between the beginning and end of the line, and thanks to the exclamation mark, only lines that do not match this pattern are printed.Dot symbol
The dot is used to search for any single character, except for the newline character. Pass the file
myfile this regular expression, the contents of which are shown below: $ awk '/.st/{print $0}' myfile 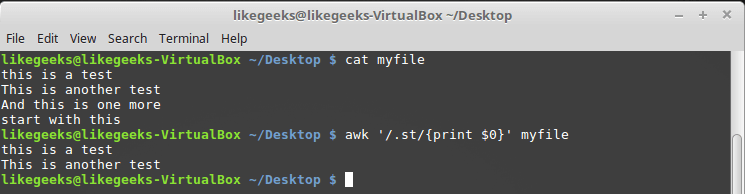
Using a point in regular expressions
As can be seen from the displayed data, only the first two lines from the file correspond to the pattern, since they contain the sequence of characters "st", preceded by another character, while the third line does not contain a suitable sequence, but in the fourth one it is, but is in the very beginning of the line.
Character classes
A dot matches any single character, but what if you need to flex more flexibly the set of desired characters? In this situation, you can use classes of characters.
With this approach, you can organize the search for any character from a given set. To describe a class of characters, square brackets are used -
[] : $ awk '/[oi]th/{print $0}' myfile 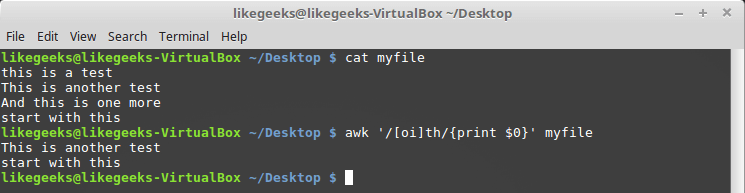
Character Class Description in Regular Expression
Here we are looking for a sequence of characters "th", in front of which there is a character "o" or a character "i".
Classes are very helpful if you search for words that can begin with both uppercase and lowercase letters:
$ echo "this is a test" | awk '/[Tt]his is a test/{print $0}' $ echo "This is a test" | awk '/[Tt]his is a test/{print $0}' 
Search for words that may begin with a lowercase or uppercase letter
Character classes are not limited to letters. Other symbols can be used here. It is impossible to say in advance in what situation classes will be needed - it all depends on the problem to be solved.
Negation of character classes
Character classes can also be used to solve the inverse problem described above. Namely, instead of searching for characters included in a class, you can organize a search for everything that is not included in the class. In order to achieve this behavior of a regular expression, in front of the list of class symbols you need to put a
^ . It looks like this: $ awk '/[^oi]th/{print $0}' myfile 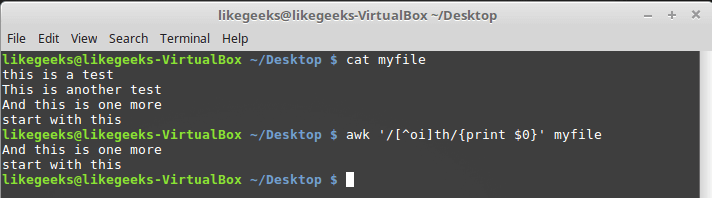
Search for non-class characters
In this case, the sequences of characters "th" will be found, before which there is neither "o" nor "i".
Character ranges
In character classes, you can describe character ranges using a dash:
$ awk '/[ep]st/{print $0}' myfile 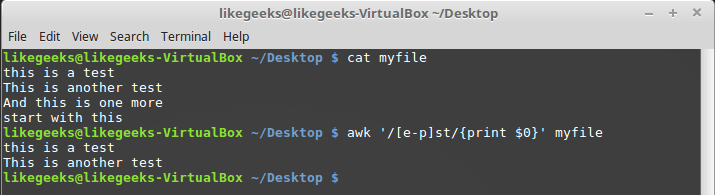
Description of character range in character class
In this example, the regular expression responds to a sequence of characters "st", in front of which is any character located, in alphabetical order, between the characters "e" and "p".
Ranges can be created from numbers as well:
$ echo "123" | awk '/[0-9][0-9][0-9]/' $ echo "12a" | awk '/[0-9][0-9][0-9]/' 
Regular expression to search for any three numbers
There may be several ranges in the character class:
$ awk '/[a-fm-z]st/{print $0}' myfile 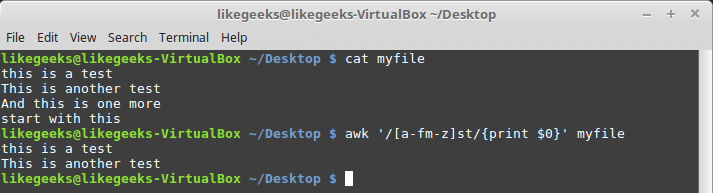
A multi-range character class.
This regular expression will find all the st strings in front of which there are characters from the ranges
af and mz .Special character classes
In BRE there are special classes of characters that can be used when writing regular expressions:
[[:alpha:]]- matches any alphabetic character written in upper or lower case.[[:alnum:]]- matches any alphanumeric character, namely, characters in the ranges0-9,AZ,az.[[:blank:]]- matches the space and tab.[[:digit:]]- any numeric character from0to9.[[:upper:]]- uppercase alphabetic characters -AZ.[[:lower:]]- lowercase alphabetic characters -az.[[:print:]]- matches any printable character.[[:punct:]]- matches punctuation.[[:space:]]- whitespace characters, in particular - space, tab,NL,FF,VT,CRcharacters.
You can use special classes in templates like this:
$ echo "abc" | awk '/[[:alpha:]]/{print $0}' $ echo "abc" | awk '/[[:digit:]]/{print $0}' $ echo "abc123" | awk '/[[:digit:]]/{print $0}' 
Special classes of characters in regular expressions
Star symbol
If you put an asterisk in the template after the character, it will mean that the regular expression will work if the character appears in the string any number of times - including the situation when the character in the string is missing.
$ echo "test" | awk '/tes*t/{print $0}' $ echo "tessst" | awk '/tes*t/{print $0}' 
Using the * symbol in regular expressions
This template character is usually used to work with words that constantly contain typos, or for words that allow different variants of correct spelling:
$ echo "I like green color" | awk '/colou*r/{print $0}' $ echo "I like green colour " | awk '/colou*r/{print $0}' 
Search for a word with different spellings
In this example, the same regular expression responds to both the word “color” and the word “color”. This is due to the fact that the symbol “u”, after which the asterisk stands, may either be absent or occur several times in a row.
Another useful feature arising from the features of the asterisk symbol is to combine it with a dot. This combination allows the regular expression to respond to any number of any characters:
$ awk '/this.*test/{print $0}' myfile 
A pattern that responds to any number of any characters.
In this case, no matter how many and what characters are between the words "this" and "test".
The asterisk can be used with character classes:
$ echo "st" | awk '/s[ae]*t/{print $0}' $ echo "sat" | awk '/s[ae]*t/{print $0}' $ echo "set" | awk '/s[ae]*t/{print $0}' 
Using asterisks with character classes
In all three examples, the regular expression works, because the asterisk after the character class means that if any number of characters “a” or “e” is found, and also if they cannot be found, the string will match the specified pattern.
POSIX ERE Regular Expressions
POSIX ERE templates that support some Linux utilities may contain additional characters. As already mentioned, awk supports this standard, but sed does not.
Here we look at the symbols most frequently used in ERE-templates, which will be useful to you when creating your own regular expressions.
▍ Question mark
The question mark indicates that the preceding character may occur in the text once or not at all. This character is one of the metacharacters of repetitions. Here are some examples:
$ echo "tet" | awk '/tes?t/{print $0}' $ echo "test" | awk '/tes?t/{print $0}' $ echo "tesst" | awk '/tes?t/{print $0}' 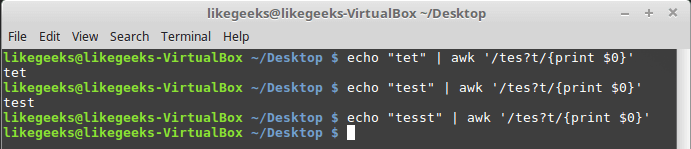
Question mark in regular expressions
As you can see, in the third case, the letter “s” occurs twice, so the regular expression does not respond to the word “tesst”.
The question mark can also be used with character classes:
$ echo "tst" | awk '/t[ae]?st/{print $0}' $ echo "test" | awk '/t[ae]?st/{print $0}' $ echo "tast" | awk '/t[ae]?st/{print $0}' $ echo "taest" | awk '/t[ae]?st/{print $0}' $ echo "teest" | awk '/t[ae]?st/{print $0}' 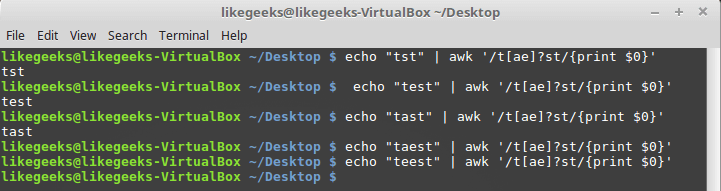
Question Mark and Character Classes
If there are no characters from the class in the string, or one of them occurs once, the regular expression is triggered, however, if two characters appear in the word, the system no longer finds a pattern match in the text.
▍Symbol "plus"
The plus symbol in the pattern indicates that the regular expression will find the search term if the preceding symbol is encountered in the text one or more times. At the same time, such a construction will not react to the absence of a symbol:
$ echo "test" | awk '/te+st/{print $0}' $ echo "teest" | awk '/te+st/{print $0}' $ echo "tst" | awk '/te+st/{print $0}' 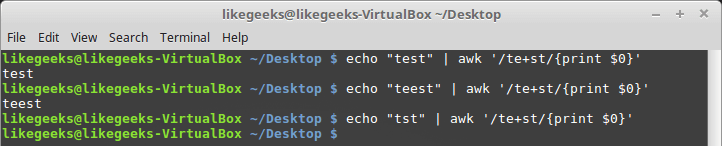
The plus symbol in regular expressions
In this example, if the “e” character is not in the word, the regular expression engine will not find any matching pattern in the text. The plus symbol also works with character classes - in this way it looks like an asterisk and a question mark:
$ echo "tst" | awk '/t[ae]+st/{print $0}' $ echo "test" | awk '/t[ae]+st/{print $0}' $ echo "teast" | awk '/t[ae]+st/{print $0}' $ echo "teeast" | awk '/t[ae]+st/{print $0}' 
The plus sign and character classes
In this case, if the string contains any character from the class, the text will be considered corresponding to the pattern.
▍Pair brackets
The curly braces that can be used in ERE patterns are similar to the characters discussed above, but they allow you to more accurately specify the required number of occurrences of the preceding character. You can specify a restriction in two formats:
n —number specifying the exact number of the desired occurrencesn, m —two numbers that are interpreted as: "at least n times, but not more than m".
Here are examples of the first option:
$ echo "tst" | awk '/te{1}st/{print $0}' $ echo "test" | awk '/te{1}st/{print $0}' 
Curly brackets in patterns, finding the exact number of occurrences
In older versions of awk, you had to use the
--re-interval command line --re-interval in order for the program to recognize intervals in regular expressions, but you don’t need to do this in newer versions. $ echo "tst" | awk '/te{1,2}st/{print $0}' $ echo "test" | awk '/te{1,2}st/{print $0}' $ echo "teest" | awk '/te{1,2}st/{print $0}' $ echo "teeest" | awk '/te{1,2}st/{print $0}' 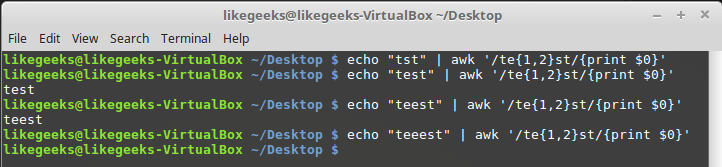
The interval specified in braces
In this example, the character "e" should occur in the string 1 or 2 times, then the regular expression will respond to the text.
Braces can also be used with character classes. There are already familiar to you principles:
$ echo "tst" | awk '/t[ae]{1,2}st/{print $0}' $ echo "test" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teest" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teeast" | awk '/t[ae]{1,2}st/{print $0}' 
Braces and character classes
The template will react to the text in the event that in it one or two times the symbol “a” or the symbol “e” occurs.
Symbol of the logical "or"
Symbol
| - vertical bar, means in regular expressions the logical "or". When processing a regular expression containing several fragments separated by such a sign, the engine will consider the analyzed text to be suitable if it matches any of the fragments. Here is an example: $ echo "This is a test" | awk '/test|exam/{print $0}' $ echo "This is an exam" | awk '/test|exam/{print $0}' $ echo "This is something else" | awk '/test|exam/{print $0}' 
Logical "or" in regular expressions
In this example, the regular expression is configured to search for the text “test” or “exam” in the text. Note that between the fragments of the template and the symbol separating them
| There should be no spaces.Regular Expression Fragment Grouping
Regular expression fragments can be grouped using parentheses. If you group a certain sequence of characters, it will be perceived by the system as a normal character. That is, for example, it will be possible to apply repetition metacharacters to it. Here's what it looks like:
$ echo "Like" | awk '/Like(Geeks)?/{print $0}' $ echo "LikeGeeks" | awk '/Like(Geeks)?/{print $0}' 
Regular Expression Fragment Grouping
In these examples, the word "Geeks" is enclosed in parentheses, after this construction comes a question mark. Recall that the question mark means “0 or 1 repetition”, as a result, the regular expression will respond to the “Like” line and to the “LikeGeeks” line.
Practical examples
After we took apart the basics of regular expressions, it's time to do something useful with their help.
▍Counting the number of files
Let's write a bash script that counts the files in directories that are written to the PATH environment variable. In order to do this, you will need, first, to create a list of paths to directories. We do this with sed, replacing colons with spaces:
$ echo $PATH | sed 's/:/ /g' The replace command supports regular expressions as patterns for text search. In this case, everything is extremely simple, we are looking for the colon symbol, but no one bothers to use here and anything else - it all depends on the specific task.
Now you have to go through the list in a loop and perform the necessary actions there to calculate the number of files. The general scheme of the script will be as follows:
mypath=$(echo $PATH | sed 's/:/ /g') for directory in $mypath do done Now we will write the full text of the script, using the
ls to get information about the number of files in each of the directories: #!/bin/bash mypath=$(echo $PATH | sed 's/:/ /g') count=0 for directory in $mypath do check=$(ls $directory) for item in $check do count=$[ $count + 1 ] done echo "$directory - $count" count=0 done When you run the script, it may turn out that some directories from the
PATH do not exist, however, this will not prevent it from counting files in existing directories.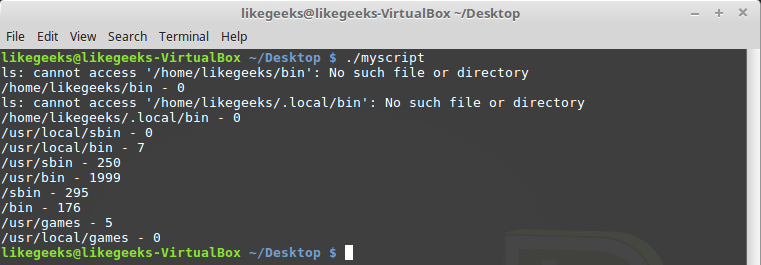
File counting
The main value of this example lies in the fact that using the same approach, one can solve much more complicated problems. — .
▍
- , , , . , — , — - . . . , , :
username@hostname.com ,
username , - . , , , , «». @., , . :
^([a-zA-Z0-9_\-\.\+]+)@ : « , , , @».
— —
hostname . , , : ([a-zA-Z0-9_\-\.]+) . , (, ), . , :
\.([a-zA-Z]{2,5})$ : « , — 2 5 , ».
, :
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$ , :
$ echo "name@host.com" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}' $ echo "name@host.com.us" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}' 
, awk , , .
Results
, , , , . — . , — , , , , , .
bash-, . - .
Dear readers! ?
Source: https://habr.com/ru/post/327896/
All Articles