Implementing a NetFlow sensor on an FPGA + CPU - flexibly and quickly
Good day!
As you understood from the title, another article about NetFlow awaits you, but this time from an unusual side - from the implementation of the NetFlow sensor on the FPGA.
Introduction
Yes, there are many articles on the topic of NetFlow on Habré: starting with a detailed analysis and a HOWTO on tuning , to an applied application in catching a virus attack and traffic metering .
But this article is not about how to use NetFlow, it is about how to implement it.
The task of creating a NetFlow sensor is interesting in that you need flexibility at the same time to support NetFlow templates that can be changed in real time and at the same time very high performance in order to efficiently handle traffic and work with memory.
Where I work (I am an FPGA programmer at the STC Metrotek), we use platforms that allow us to choose between software and hardware implementations.
But for the most part of our tasks, the software part deals mainly with management, and the FPGA assumes the main work. That is why the creation of NetFlow sensor, as something more interesting in terms of Software Hardware Co-design, seemed to us a good reason to share our work with you by writing this article.
About NetFlow
In order not to lose the thread of the story and decide on the terms, I’ll tell you about NetFlow, albeit very briefly, because this information is everywhere.
NetFlow is a protocol that Cisco Systems has come up with.

What for? To be able to remotely monitor the traffic on the network.
That is, in the local network there is some L3-switch with the function of the NetFlow sensor and somewhere else a collector who knows everything about what is happening in the network.
In this case, there should not be an extra load on the network with data that we send to the collector, that is, simple traffic mirroring to the analyzer is not suitable.
Items in NetFlow:
Sensor (aka Exporter) - a device that collects information about streams in the network.
This is usually an L3 switch or router that rarely (usually once per second) sends stream information to the collector.- The collector is (usually) a remote server that collects the information sent by the sensor and stores it.
What else you need to know about NetFlow:
Export packages are those packages that the sensor sends to the collector.
They have the whole essence of NetFlow. You have probably heard about the fact that NetFlow comes in different versions - and so, the format of these export packages is the main difference between the versions.NetFlow versions: v1 , v5 , v8 , v9 . v9 - the most common, the rest either provide limited functionality ( v1 , v5 ), or unnecessarily complex ( v8 ).
In the v9 version, the sensor determines what information it can give, and the collector adjusts for it. The sensor, along with the data, sends a template by which it is clear how to work with this data. Templates are very flexible. Read more about the NetFlow v9 recommendation in RFC 3954 .
There are IPFIX - at the moment, the same NetFlow v9 is functionally available.
Only NetFlow is managed by Cisco, and IPFIX is standardized by RFC.- Flow - as they say in RFC 3917 p.2.1 , this is when packets have something in common.
For NetFlow v9, it is customary to use a stricter definition:
Packets are assigned to the same stream, with the following characteristics:- Source IP address;
- Recipient's IP address;
- TCP / UDP source port;
- TCP / UDP receiver port;
- ICMP code;
- ICMP type;
- L4 protocol (IP Protocol Number field);
- IP ToS;
- Input interface
From these fields we conclude:
- NetFlow considers only IP packets (in IPFIX, this is even in the name rendered);
- ICMP packets are also considered (in the case of ICMP, the port fields of L4 are assumed to be 0);
- A stream is only in one direction (that is, if there is a client and a server, then it is one stream from client to server, back to the other);
And do not forget - this flow definition is not strictly defined by the standard. As far as our needs are concerned, we can change the concept of flow, for example, by aggregating flows by directions.
Design and survey work
Now that everything is known about NetFlow, we formulate the statement of work:
You need a NetFlow sensor, such that:
- He was ready for a large number of streams (tens, hundreds of thousands);
- I was ready for a heavy load, ideally the line rate on my platform (2G / 100G);
- Worked without sampling (when some traffic is not included in the statistics).
- The main development platform is smart probes, for example, the M716 , which can be put into a network break and collect statistics in this way. But in the design process, it is worth considering the possibility of using B100 in our 100G switch;
Target platforms are both heterogeneous: CPU + FPGA.
Probes are based on the Altera SoC (Cyclone V) ARM processor + small FPGA. All this on one crystal.
The B100 is a powerful processor (Intel Core I7) + a large FPGA (Stratix V). Between them, PCIe.
Therefore, we have a lot of freedom in terms of Hardware / Software Co-design.
But let's start by explaining why obvious implementation options are not appropriate.
SW Only
We do not use FPGA at all. We use software solution for NetFlow.
We get a lot of flexibility, but what about performance?
- Reception and processing of the input packet. It will be very difficult to achieve the processing of userspace traffic line rate by the utility. Even if we had achieved the FPGA functionality corresponding to the cards from Intel and used the DPDK libraries, it would be almost impossible to achieve the speed of the network stack, which would receive lossless packets at a line rate of 100G of 64 bytes, at least in real time. Even on the 1G link on ARM, there are very serious questions about how long it will take to optimize the stack.
- CPU load. With the B100 platform, we can assume that having solved the problem of the network stack, we will have enough CPU time to do something other than receiving packets, but on a small ARM there are concerns about whether the system will pull out a constant check of flows in memory, even without receiving packets.
Thus, we can conclude - yes, such an implementation is possible, but:
- If we are talking about real terms of development - sampling of input packets is inevitable.
- On the SoC platform, there is a very serious question about the maximum number of threads that we can store in memory, because all these threads will need to be constantly checked.
- We can in FPGA. Even if we consider that software implementation is possible, it is quite obvious that many things on the FPGA will be implemented many times more efficiently.
But we nevertheless learned something useful from consideration of the software implementation - projects in which you can peep at the nuances of the implementation of the NetFlow sensor:
FPGA only
Now let's go to the other extreme - all on FPGA:
- Reception and processing of the input packet. Maximum speed, line rate on B100 and on SoCs. Price is development time, but we will not write this from scratch - we already have a lot of groundwork in this area.
- CPU usage is not relevant, and the number of threads is limited only by memory size. With adequate numbers (1-2 million threads), we do not rest on the number of readings that will occur when checking threads. The interface problem remains - the bandwidth that we will divide between adding threads and checking them, but we can always say that checking is a less priority task and do it only when we don’t add a new packet.
But there is a very important question about the flexibility of creating NetFlow packages.
Option 1 - we refuse to modify the templates NetFlow v9. We are writing a generator to an FPGA that can only send data using one template.
If we want to change the template, we will have to rewrite this FPGA module. This approach does not suit us, because different collectors may work differently with NetFlow and sometimes do not quite understand different fields: for example, some NetFlow v9 package fields have a size that can be redefined by the template, but not all collectors are ready for this, they waiting for this field to be a constant size.
Option 2 - we implement dynamic template changes in FPGA. This is possible, but such a module will take up a lot of resources. In addition, its development will take a very long time both on the module itself and on its debugging.
And one more minus of such an implementation: the standard says that not only UDP can be used for transport of NetFlow export packets, but SCTP. This means that if we want to support such functionality, we will have to implement half the network stack on the FPGA.
SW + HW
Now, when we are convinced that only FPGA or only software implementations for this task are not suitable, we will move on to a joint solution.
Functional blocks
To make it easier to find a solution, we will do the following:
- We break prospective functionality into functional blocks;
- We form requirements for these blocks;
- We distribute, depending on requirements, these blocks on hardware and software implementations.
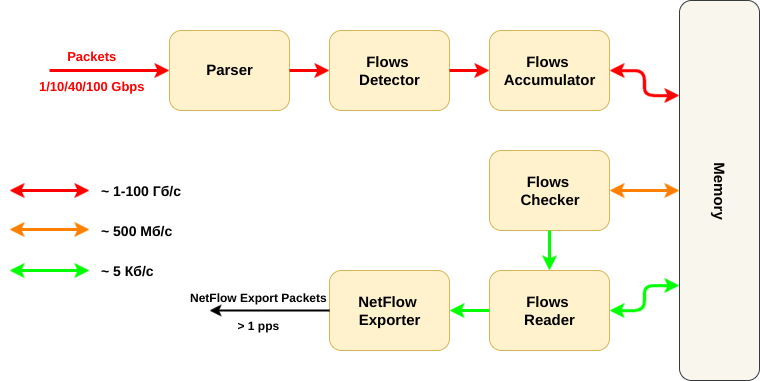
This diagram shows the main functional blocks of the NetFlow sensor:
- First you need to accept the package and parse (pull out the necessary header fields) ( Parser );
- Then you need to understand to which flow the packet belonged ( Flow Detector );
- Next you need to get from the memory information on this flow, update it and write back ( Flow Accumulator );
- The memory stores the packet header fields + additional information (byte counters and stream packets, start and end timers);
- At the same time, the second part of NetFlow works - the one that checks that the flow in memory is long enough and it is time to read it. That is, flows from memory are regularly read and checked ( Flow Checker );
- If it is time to export the flow, it must be deleted from memory and prepared for sending ( Flow Reader );
- Finally, you need to create a NetFlow Export package for the collector;
What gave us such a partition:
- In the entire scheme of the NetFlow sensor, one block is responsible for the “NetFlow” itself - the formation of the package.
That is, if this block is flexible, we can use any version of NetFlow or even IPFIX; - The color on the diagram indicates the approximate load on the interfaces - our main selection criterion SW vs HW;
Now, keeping in mind this schema, let's move on to the options:
Option 1
For now we know the following exactly:
- We want to accept packets, parse them and add them to memory on FPGA;
- We want to create export packages programmatically.
All part of the accumulation from receiving a packet to writing to memory should occur on the FPGA.
Suppose this is where all the work of the FPGA ends: the memory where the streams are stored is shared. It has access to soft and he himself checks the threads in the memory and their subtraction.
In this case, we still have a problem of a large load on the CPU with a large number of threads, but in addition to this, a new problem appears - memory access collisions: FPGAs may want to update information about the stream that soft was about to read, in this case it will be very simple lose some flow information.
This problem has solutions, but they will require additional complexity of the architecture.
Option 2
Then we go a little further - the memory remains common, but the FPGA (regularly reads and checks the timers of the threads) checks the threads. As soon as the stream needs to be exported, the FPGA reports a soft pointer to this stream. We removed the load from the CPU, but the collision problem did not dare.
Option 3
We go even further - when the FPGA read the stream from the memory and realized that it was the stream for export - it itself removes the stream from the memory and sends it to soft (using any available interface).
In this case, the memory should no longer be shared, we can solve conflicts inside the FPGA at the stage of memory access resolution.
And the software part, which can be changed to work with any protocol, is engaged in the formation of export NetFlow packages.
The latest version of us gave us. You can proceed to creating a proof of concept based on the SoC platform.
Implementation
Before implementation, we will present some requirements to it:
- It should be IP-core (standard interfaces, reusability through parameters, etc.);
- The functionality should be expandable - now it is PoC, but you don’t want to spend a lot of time on something that will not be used later.
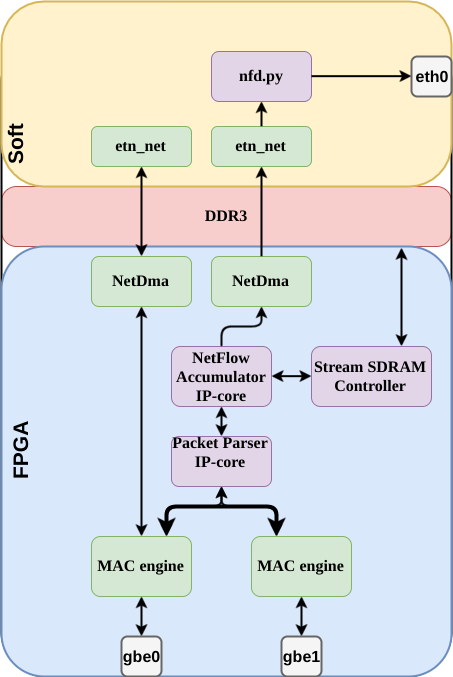
All this led us to the following implementation:
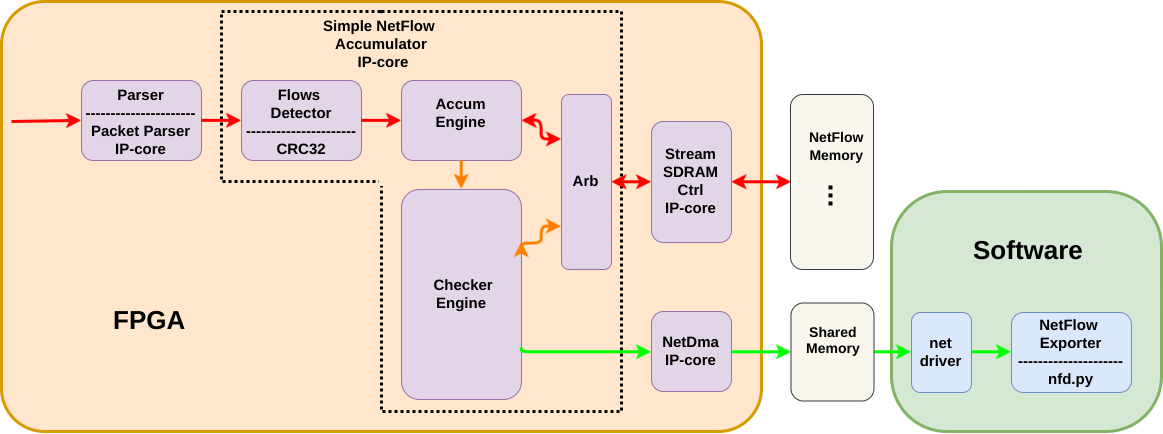
')
- Parser is our IP-core taken from another project. It accepts the Avalon-ST packet interface and takes the necessary header fields from the packet.
Avalon Streaming Interface - an interface for transferring data streams inside an FPGA. Used in Altera's IP-core. It can be used in the continuous data stream or packet data transfer (the beginning / end of the packet signals are used). You can read more here: Avalon Interface Specifications.pdf
NetDMA is also our IP-core DMA controller, which receives Avalon-ST packets and writes them to memory using handles. In order to supply this DMA with handles, we already have a driver. Now this DMA and driver are used in our network stack.
Simple NetFlow Accumulator is the same IP-core NetFlow sensor. She is engaged in flow detection. Reading and updating information in memory for each received packet, constant memory checking for the presence of streams for export and arbitration of requests to the memory when adding and checking.
- Stream SDRAM Ctrl is a small IP-core that serves for easier access to memory. She can read and write to memory on an arbitrary shift. For reading, it takes a shift and the number of bytes and after some time Avalon-ST sends a stream with data. For the record, we specify the shift and the number of bytes, and by Avalon-ST we send the data to be recorded.
Stream data storage structure
The simplest structure for data storage is the hash table without a collision resolution mechanism.
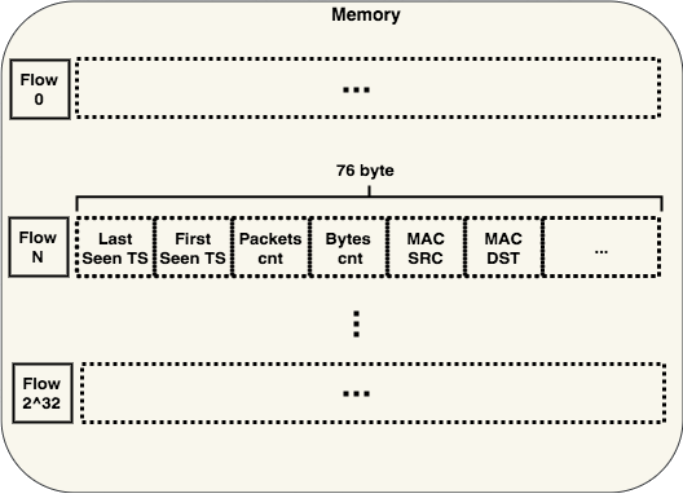
The result of the calculation of the hash function of the stream, we consider as a shift in memory, on which it is necessary to arrange the relevant information.
When adding a new stream, we consider a hash from it, read from the memory by the required index and check that it is really it. If we make a mistake (a hash collision has occurred), then we force the NetFlow scan engine to subtract this stream from memory. Yes, his timers have not expired yet and he should still be stored in memory, but this is our easiest method of dealing with collisions. Cons of this approach:
- We generate a greater load on the interface between NetFlow and the CPU;
- We are a little dishonest about what the collector expects of us.
The first problem is solved: the lower the probability of collisions, the smaller the possible surge in load.
The second problem can be solved in the program part, if there is implemented its own small buffer for storing such premature shipments.
We select a hash
As a hash function is currently used CRC32 from the polynomial 0x04C11DB7 (this is the one used in Ethernet). Of course, we had an idea to choose a more interesting hash function that would give less collisions. But the simulations showed that CRC32 was fine.
For modeling, we made a simple python hash table that contains positions (this size seemed to be the most suitable for the first implementation, therefore we test hash functions on it). That is, from the resulting hash value, only 20 bits are used to determine the position in the table.
We also wrote a script generator that creates unique words of 17 bytes each (this is how much data is obtained from fields unique to the stream).
We add this data to our table, with different hash functions:
- CRC32 with polynomial 0x04C11DB7
- CRC32 with polynomial 0xEDB88321
- CRC32 with polynomial 0x82608EDB
- LookUp3
- MurMurHash3
The CRC32 polynomials 0xEDB88321 and 0x82608EDB are transformations of the polynomial 0x04C11DB7. In one of the past projects, we used such CRC functions to quickly generate a large number of different hashes. We decided to check them at the same time here.
LookUp3 was chosen because this function was specially created for hash tables and contains in itself quite tolerable for FPGA operations - addition and shift.
MurMurHash3 was chosen not only because of its cool name, but also as an example of a multiplicative function, which would be quite expensive to implement in FPGA, but which should, in theory, give a better filling of the table.
After adding each new word to each of the tables, we kept the table full in order to build such a graph:

As you can see from the graph, there are no significant differences on our data.
So CRC32 is quite suitable for us until we decide to change the size of the data from which we consider the hash, or until we want to protect ourselves from an intentional attack on filling our table.
For the test platform was chosen one of the platforms with SoC'om on board and two network interfaces, looking in FPGA.
Packets that fall into NetFlow are taken from transit — when a packet is sent from one port to another via FPGA. Turning on and off the transfer has already been implemented on this platform.
Thus, you can create a load of up to 2 Gb / s and at the same time control the number of packets sent to NetFlow.
On the selected platform, the FPGA and CPU share memory. To separate the memory with which only FPGA will work (for storing packets), the Linux kernel is limited to the visible memory when loading, so that we have enough ~ 150 MB of storage remaining for 1 million threads.
To create the export packages themselves, they wrote their simple python utility, which with the help of the scapy library listens to the network interface on which the stream data comes. Using the same library, it forms NetFlow Export packages and sends them.
Conclusion
Performance
This NetFlow implementation, in theory, "rests" only on the memory bandwidth (in one of the articles, my colleague Des333 made a practical calculation of this bandwidth on the SoC platform and got the figures at 20 Gb / s, you can read more in his article here )
Do we have enough 20 GB / s?
Adding each packet to us is reading 45 bytes from memory and writing 76.
In the worst case, Ethernet traffic on the 1G interface can create a load of 1488095 packets per second (packets of 64 bytes per line rate).
Thus, we will create a load on the memory of 1.44 Gb / s. The rest of the bandwidth can be given to check the flow.
But in the current implementation, the performance is much lower: in practice, we are not coping with the worst case line rate (packets of 64 bytes) and some of the packets are not included in the statistics. You can estimate the problem in numbers in a simulation, where the target, with the current memory settings, is a lossless load of ~ 1420000 packets per second. This corresponds to the line rate in the case of 69-byte packets.
This is due to the fact that the battery works consistently - it first processes each packet completely, and only then takes on the next one.
In addition, the DDR3 memory delay was quite large (interconnect automatically generated by the development environment + using IP-core Stream SDRAM Ctrl gave ~ 15 latencies
between the request to read and receive data at a frequency of 62.5 MHz).
The solution to this problem is to use a pipeline when adding data to the memory. That is, we request data for reading, and while waiting for a response, we request a read for the next stream (and so up to 15 times).
You can also increase the frequency at which Simple NetFlow IP-core works and all memory access.
Known issues
This is only PoC and therefore there are a number of limitations, such as:
We do not follow the end of the stream by IP flags (only by timers), although NetFlow implies that this is our task;
- Performance sags very much with a large number of hash table collisions: we run into the performance of the network stack between the FPGA and the CPU, because processing the new packet is blocked if we don’t have enough space to subtract the packet from the memory and send it to the CPU. A possible solution is to implement baskets for storing streams in memory (one index will contain several threads);
- The previously mentioned performance problem that requires the implementation of a pipeline when adding new data to memory;
On this, in general, that's all. Thank you for reading to the end.
I will be glad to answer your questions in the comments.
PS
By the way, my colleagues from the system group managed to convert those sketches from python utilities for testing into a decent driver for Linux and a daemon on Rust, which builds packages for NetFlow.
Maybe sometime they will write something about it. But while they are resting after the article about our other collaboration, acceleration of AES encryption. If interested, you can read here .
Source: https://habr.com/ru/post/327894/
All Articles