Bash scripts, part 8: awk data processing language
Bash scripts: start
Bash scripts, part 2: loops
Bash scripts, part 3: command line options and keys
Bash scripts, part 4: input and output
Bash Scripts, Part 5: Signals, Background Tasks, Script Management
Bash scripts, part 6: functions and library development
Bash scripts, part 7: sed and word processing
Bash scripts, part 8: awk data processing language
Bash scripts, part 9: regular expressions
Bash scripts, part 10: practical examples
Bash scripts, part 11: expect and automate interactive utilities

Last time, we talked about the sed streaming editor and looked at a lot of text processing examples using it. Sed is capable of solving many problems, but it also has limitations. Sometimes you need a more advanced data processing tool, something like a programming language. In fact, such a tool is awk.

The awk utility, or more precisely GNU awk, compared to sed, takes data stream processing to a higher level. Thanks to awk, we have a programming language at our disposal, rather than a rather modest set of commands given to the editor. Using the awk programming language, you can do the following:
')
- Declare variables for data storage.
- Use arithmetic and string operators to work with data.
- Use structural elements and control constructs of the language, such as the if-then operator and cycles, which allows for the implementation of complex data processing algorithms.
- Create formatted reports.
If we talk only about the ability to create formatted reports that are easy to read and analyze, this is very useful when working with log files that may contain millions of records. But awk is much more than a reporting tool.
Awk call features
The awk call scheme looks like this:
$ awk options program file Awk treats incoming data as a set of records. Entries are sets of fields. Simplified, if you do not take into account the possibility of setting up awk and talk about some quite plain text, the lines of which are separated by newline characters, the entry is a string. A field is a word in a string.
Consider the most commonly used awk command line switches:
-F fs- allows you to specify a delimiter character for fields in the record.-f file- specifies the name of the file from which to read the awk script.-v var=value —allows you to declare a variable and set its default value, which will be used by awk.-mf N- sets the maximum number of fields to be processed in the data file.-mr N —sets the maximum record size in the data file.-W keyword- allows you to set the compatibility mode or awk alert level.
The real power of awk is hidden in the part of the call command that is marked above as
program . It points to an awk-script file written by a programmer and intended for reading data, processing it and outputting results.Reading awk scripts from the command line
The awk scripts that can be written directly on the command line are in the form of command texts enclosed in curly braces. In addition, since awk assumes that the script is a text string, it must be enclosed in single quotes:
$ awk '{print "Welcome to awk command tutorial"}' Let's run this command ... And nothing will happen. The point here is that we did not specify the data file when we called awk. In this situation, awk waits for data from STDIN . Therefore, the execution of such a command does not lead to immediately observed effects, but this does not mean that awk does not work - it is waiting for input data from
STDIN .If you now type something into the console and press
Enter , awk will process the entered data using the script specified when it was started. Awk processes the text from the input stream line by line; in this way it looks like sed. In our case, awk does nothing with the data, it only, in response to each new line it receives, displays the text specified in the print command.
The first start of awk, displaying the specified text
Whatever we enter, the result in this case will be the same - the text output.
In order to complete awk, you must pass it the end-of-file (EOF, end-of-file) character. You can do this by using the keyboard shortcut
CTRL + DIt is not surprising if this first example seemed to you not particularly impressive. However, the most interesting is ahead.
Positional variables that store field data
One of the main functions of awk is the ability to manipulate data in text files. This is done by automatically assigning a variable to each element in the line. By default, awk assigns the following variables to each data field it finds in the record:
$0 —represents the entire line of text (write).$1 —first field.$2 —second field.$n —n-th field.
Fields are extracted from text using the delimiter character. By default, these are whitespace characters like spaces or tabs.
Consider the use of these variables in a simple example. Namely, we will process a file containing several lines (this file is shown in the figure below) using the following command:
$ awk '{print $1}' myfile 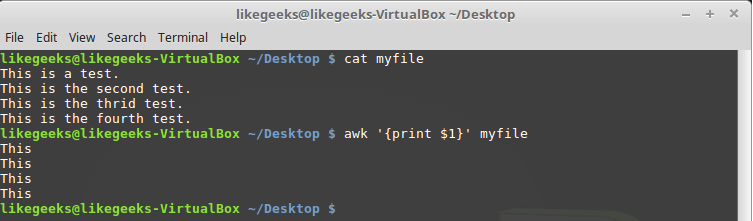
Output to the console the first field of each line
The variable used here is
$1 , which allows you to access the first field of each line and display it on the screen.Sometimes, some files use something other than spaces or tabs as field separators. We mentioned above the awk
-F key, which allows you to specify the separator required for processing a specific file: $ awk -F: '{print $1}' /etc/passwd 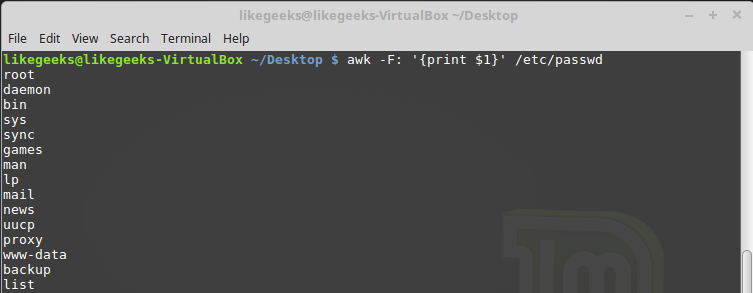
Specifying the delimiter character when calling awk
This command prints the first line elements contained in the
/etc/passwd . Since colons are used as delimiters in this file, this particular character was passed to awk after the -F key.Using multiple commands
An awk call with one word processing command is a very limited approach. Awk allows you to process data using multi-line scripts. In order to send an awk multi-line command when calling it from the console, you need to separate its parts with a semicolon:
$ echo "My name is Tom" | awk '{$4="Adam"; print $0}' 
Calling awk from the command line passing a multi-line script to it
In this example, the first command writes the new value to the variable
$4 , and the second displays the entire line.Reading the awk script from a file
Awk allows you to store scripts in files and reference them using the
-f . Prepare a file testfile , in which we write the following: {print $1 " has a home directory at " $6} Call awk, specifying this file as a command source:
$ awk -F: -f testfile /etc/passwd 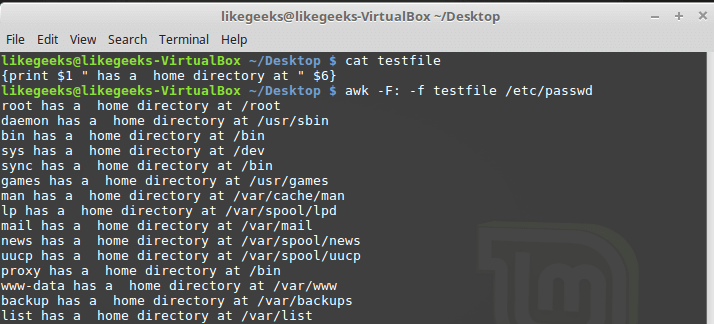
Calling awk with a script file
Here we derive from the
/etc/passwd names of users who fall into the $1 variable, and their home directories, which fall into $6 . Notice that the script file is set with the -f key, and the field separator, a colon in our case, with the -F key.The script file may contain many commands, while each of them is enough to write a new line, put a semicolon after each is not required.
Here is what it might look like:
{ text = " has a home directory at " print $1 text $6 } Here we store the text used when outputting the data received from each line of the file being processed in a variable, and use this variable in the
print command. If you reproduce the previous example, writing this code to the file testfile will testfile the same thing.Execution of commands before data processing begins.
Sometimes you need to perform some actions before the script starts processing records from the input stream. For example, create a report header or something similar.
To do this, you can use the keyword
BEGIN . The commands that follow BEGIN will be executed before data processing begins. In its simplest form, it looks like this: $ awk 'BEGIN {print "Hello World!"}' And here is a slightly more complicated example:
$ awk 'BEGIN {print "The File Contents:"} {print $0}' myfile 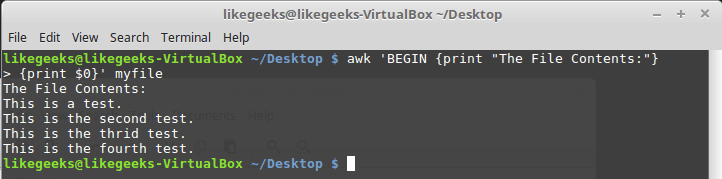
Execution of commands before data processing begins.
At first awk executes the
BEGIN block, after which the data is processed. Be careful with single quotes using similar constructs on the command line. Notice that both the BEGIN block and the thread processing commands are one line in the awk view. The first single quote delimiting this string is before BEGIN . The second is after the closing brace of the data processing command.Execution of commands after the end of data processing
The
END keyword allows you to specify the commands to be executed after the end of data processing: $ awk 'BEGIN {print "The File Contents:"} {print $0} END {print "End of File"}' myfile 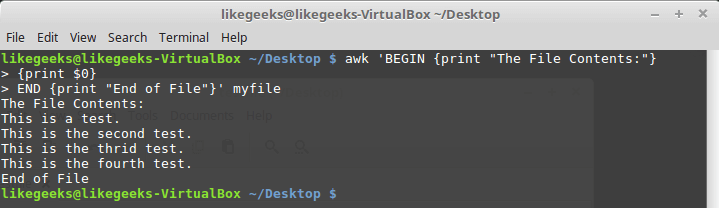
The results of the script, in which there are blocks BEGIN and END
After completing the output of the file contents, awk executes the
END block commands. This is a useful feature, with its help, for example, you can create a basement report. Now we will write a script with the following content and save it in a myscript file: BEGIN { print "The latest list of users and shells" print " UserName \t HomePath" print "-------- \t -------" FS=":" } { print $1 " \t " $6 } END { print "The end" } Here, in the
BEGIN block, the heading of the tabular report is created. In the same section, we specify the delimiter character. After the end of the file processing, thanks to the END block, the system will inform us that the work is finished.Run the script:
$ awk -f myscript /etc/passwd 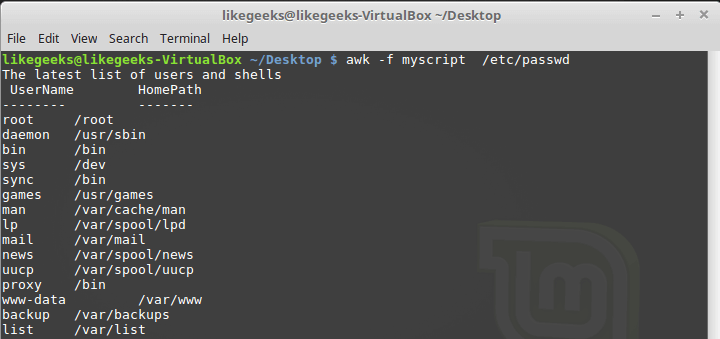
Processing the / etc / passwd file with an awk script
All that we talked about above is only a small part of the awk capabilities. We continue the development of this useful tool.
Built-in variables: setting data processing
The awk utility uses built-in variables that allow you to customize the data processing process and give access to both the processed data and some information about it.
We have already considered positional variables -
$1 , $2 , $3 , which allow us to extract field values; we worked with some other variables. In fact, they are quite a lot. Here are some of the most commonly used:FIELDWIDTHS —spaceFIELDWIDTHS —separated list of numbers that defines the exact width of each data field, taking into account field separators.FSis a variable you already know that allows you to specify a field separator character.RS —variable that allows you to specify a record separator character.OFS —a field separator in the output of an awk script.ORS —separator records on the output of the awk-script.
By default, the
OFS variable is configured to use a space. It can be installed as needed for data output purposes: $ awk 'BEGIN{FS=":"; OFS="-"} {print $1,$6,$7}' /etc/passwd 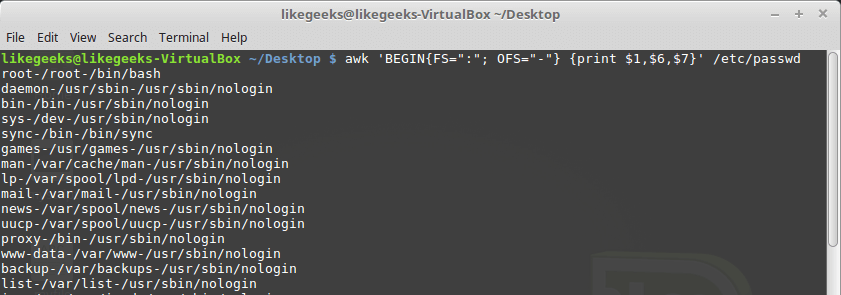
Setting the output field separator
The
FIELDWIDTHS variable allows FIELDWIDTHS to read records without using the field separator character.In some cases, instead of using a field delimiter, the data within the records is located in columns of constant width. In such cases, it is necessary to set the
FIELDWIDTHS variable so that its contents correspond to the data presentation features.When the
FIELDWIDTHS variable is FIELDWIDTHS awk will ignore the FS variable and find the data fields according to the width information specified in FIELDWIDTHS .Suppose there is a
testfile file containing such data: 1235.9652147.91 927-8.365217.27 36257.8157492.5 It is known that the internal organization of this data corresponds to the 3-5-2-5 pattern, that is, the first field is 3 characters wide, the second is 5, and so on. Here is a script that allows you to parse such records:
$ awk 'BEGIN{FIELDWIDTHS="3 5 2 5"}{print $1,$2,$3,$4}' testfile 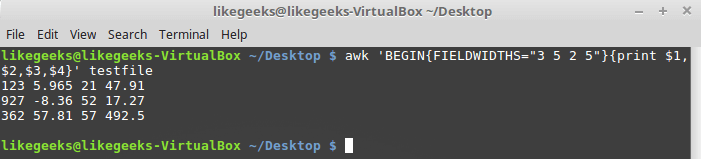
Using the FIELDWIDTHS variable
Let's look at what the script displays. The data is parsed taking into account the value of the variable
FIELDWIDTHS , as a result, the numbers and other characters in the lines are broken according to the specified width of the fields.The variables
RS and ORS define the order in which records are processed. By default, RS and ORS set to a newline character. This means that awk takes each new line of text as a new record and displays each record from a new line.Sometimes it happens that the fields in the data stream are distributed over several lines. For example, suppose there is such a file named
addresses : Person Name 123 High Street (222) 466-1234 Another person 487 High Street (523) 643-8754 If you try to read this data, provided that
FS and RS set to default values, awk will consider each new line as a separate entry and highlight the fields based on spaces. This is not what we need in this case.In order to solve this problem, you need to write a newline character in
FS . This will indicate to awk that each line in the data stream is a separate field.In addition, in this example, you need to write an empty string in the
RS variable. Notice that in the file, data blocks for different people are separated by a blank line. As a result, awk will treat blank lines as record delimiters. Here's how to do it all: $ awk 'BEGIN{FS="\n"; RS=""} {print $1,$3}' addresses 
The results of setting variables RS and FS
As you can see, awk, thanks to these variable settings, treats lines from a file as fields, and empty lines become separators of records.
Built-in variables: information about the environment
In addition to the built-in variables that we already talked about, there are others that provide information about the data and the environment in which awk works:
ARGCis the number of command line arguments.ARGVis an array with command line arguments.ARGIND- the index of the current file being processed in the arrayARGV.ENVIRONis an associative array with environment variables and their values.ERRNOis a system error code that may occur when reading or closing input files.FILENAMEis the name of the input data file.FNRis the current record number in the data file.IGNORECASE- if this variable is set to a non-zero value, the case is ignored during processing.NFis the total number of data fields in the current record.NRis the total number of records processed.
The
ARGC and ARGV variables allow you to work with command line arguments. In this case, the script passed by awk does not fall into the array of arguments ARGV . Let's write this script: $ awk 'BEGIN{print ARGC,ARGV[1]}' myfile After its launch, you can find out that the total number of command line arguments is 2, and under the index 1 in the array
ARGV recorded the name of the file being processed. In the array element with index 0 in this case will be “awk”.
Work with command line parameters
The variable
ENVIRON is an associative array with environment variables. Let's try it out: $ awk ' BEGIN{ print ENVIRON["HOME"] print ENVIRON["PATH"] }' 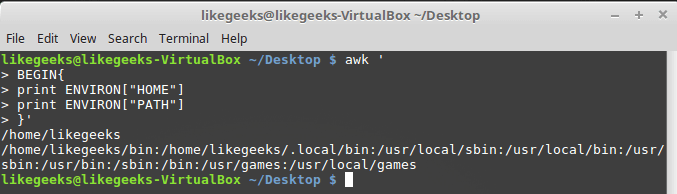
Work with environment variables
Environment variables can be used without reference to
ENVIRON . You can do this, for example, as follows: $ echo | awk -v home=$HOME '{print "My home is " home}' 
Working with environment variables without using ENVIRON
The variable
NF allows you to access the last data field in the record without knowing its exact position: $ awk 'BEGIN{FS=":"; OFS=":"} {print $1,$NF}' /etc/passwd 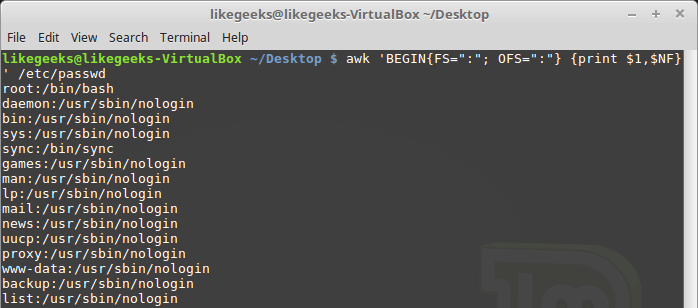
An example of using the variable NF
This variable contains the numeric index of the last data field in the record. You can access this field by placing a
$ sign in front of the NF .The variables
FNR and NR , although they may seem similar, are actually different. Thus, the FNR variable stores the number of records processed in the current file. The variable NR stores the total number of records processed. Consider a couple of examples, passing the same file to awk twice: $ awk 'BEGIN{FS=","}{print $1,"FNR="FNR}' myfile myfile 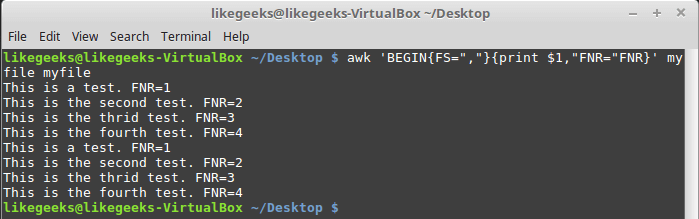
FNR variable investigation
Transferring the same file twice is equivalent to transferring two different files. Note that
FNR reset at the beginning of processing each file.Now let's look at how the
NR variable behaves in this situation: $ awk ' BEGIN {FS=","} {print $1,"FNR="FNR,"NR="NR} END{print "There were",NR,"records processed"}' myfile myfile 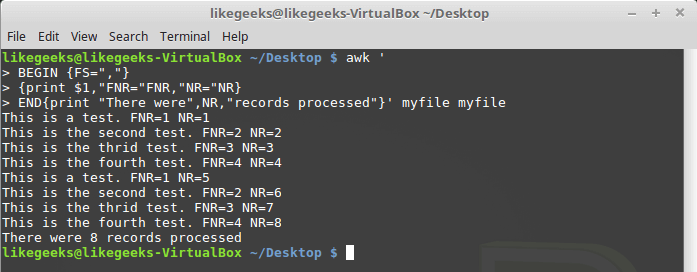
Difference of NR and FNR Variables
As you can see,
FNR , as in the previous example, is reset at the beginning of processing each file, but NR , when moving to the next file, saves the value.Custom variables
Like any other programming language, awk allows a programmer to declare variables. Variable names can include letters, numbers, underscores. However, they cannot begin with a digit. You can declare a variable, assign a value to it and use it in the code like this:
$ awk ' BEGIN{ test="This is a test" print test }' 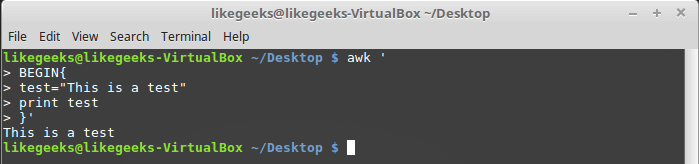
Work with user variable
Conditional operator
Awk supports the standard
if-then-else format in many programming languages. A single-line version of the operator is an if keyword followed by, in parentheses, the checked expression, and then the command to be executed if the expression is true.For example, there is such a file named
testfile : 10 15 6 33 45 Let's write a script that prints numbers from this file greater than 20:
$ awk '{if ($1 > 20) print $1}' testfile 
Single line if statement
If you need to execute several statements in the
if block, you need to enclose them in braces: $ awk '{ if ($1 > 20) { x = $1 * 2 print x } }' testfile 
Execution of several commands in the if block
As already mentioned, the awk conditional operator can contain an
else block: $ awk '{ if ($1 > 20) { x = $1 * 2 print x } else { x = $1 / 2 print x }}' testfile 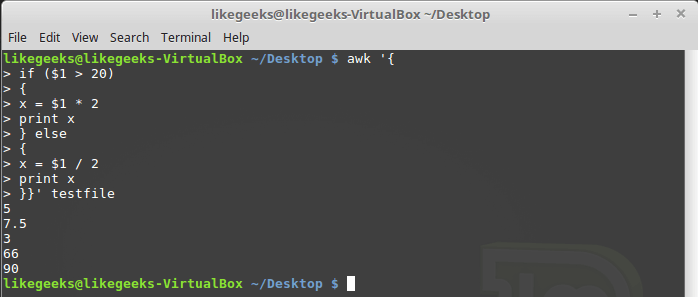
Conditional statement with an else block
The
else branch can be part of a single-line record of a conditional statement, including only one line with the command. In this case, after the if branch, immediately before the else , you need to put a semicolon: $ awk '{if ($1 > 20) print $1 * 2; else print $1 / 2}' testfile 
Conditional statement containing if and else branches written in one line
While loop
The
while allows you to iterate over the data sets by checking the condition that stops the loop.Here is the file
myfile , the processing of which we want to organize using a loop: 124 127 130 112 142 135 175 158 245 Let's write this script:
$ awk '{ total = 0 i = 1 while (i < 4) { total += $i i++ } avg = total / 3 print "Average:",avg }' testfile 
Data processing in a while loop
The
while enumerates the fields of each record, accumulating their sum in the variable total and increasing each variable by 1 counter variable i . When i reaches 4, the condition at the entrance to the cycle will be false and the cycle will end, after which the remaining commands will be executed - the calculation of the average value for the numeric fields of the current record and the output of the found value.In
while loops, you can use the break and continue commands. The first allows you to complete the cycle ahead of time and proceed to the execution of commands located after it. The second allows, without completing the end of the current iteration, to the next.Here’s how the
break command works: $ awk '{ total = 0 i = 1 while (i < 4) { total += $i if (i == 2) break i++ } avg = total / 2 print "The average of the first two elements is:",avg }' testfile 
Break command in a while loop
Cycle for
For loops are used in many programming languages. Supports them and awk. We solve the problem of calculating the average value of numeric fields using this cycle:
$ awk '{ total = 0 for (i = 1; i < 4; i++) { total += $i } avg = total / 3 print "Average:",avg }' testfile 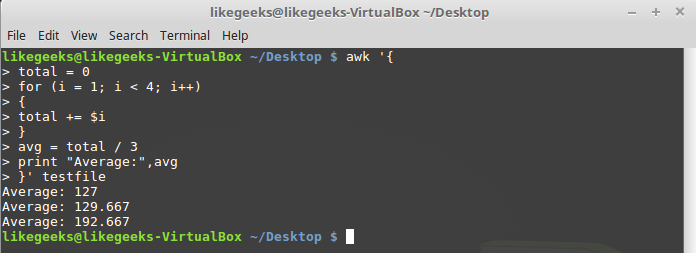
Cycle for
The initial value of the counter variable and the rule for its change in each iteration, as well as the condition for loop termination, are specified at the beginning of the loop, in parentheses. As a result, we do not need, in contrast to the case with the
while , to increment the counter ourselves.Formatted data output
The
printf command in awk allows you to output formatted data. It allows you to customize the appearance of the output data through the use of templates, which may contain text data and format specifiers.The format specifier is a special character that specifies the type of output and how it should be output. Awk uses format specifiers as pointers to insert data from variables passed to
printf .The first specifier corresponds to the first variable, the second specifier corresponds to the second, and so on.
Format specifiers are written as:
%[modifier]control-letter Here are some of them:
c- perceives the number passed to it as an ASCII character code and outputs this character.d- displays a decimal integer.iis the same asd.e- displays a number in exponential form.f- displays a floating point number.g- displays the number either in exponential notation or in floating point format, depending on how it is shorter.o- displays the octal number representation.s- displays a text string.
Here's how to format the output using
printf : $ awk 'BEGIN{ x = 100 * 100 printf "The result is: %e\n", x }' 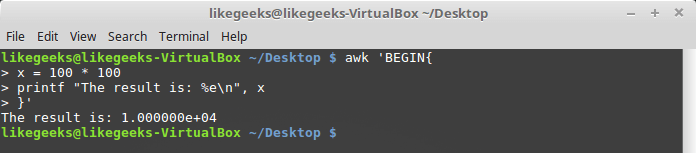
Formatting output with printf
Here, as an example, we display a number in an exponential notation. , , ,
printf .awk . , , . , , , awk-:
cos(x)—x(x).sin(x)—x.exp(x)— .int(x)— .log(x)— .rand()— 0 — 1.sqrt(x)—x.
:
$ awk 'BEGIN{x=exp(5); print x}' 
Awk . . , ,
toupper : $ awk 'BEGIN{x = "likegeeks"; print toupper(x)}' 
toupper
, , .
awk. , :
$ awk ' function myprint() { printf "The user %s has home path at %s\n", $1,$6 } BEGIN{FS=":"} { myprint() }' /etc/passwd 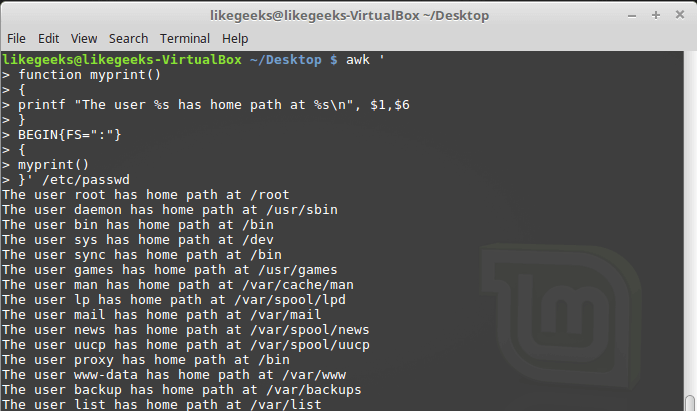
myprint , .Results
awk. , .
, , , , , - , , … , , The GNU Awk User's Guide . , 1989- ( awk, , 1977-). , awk , , . , , . bash- sed awk.
Dear readers! , awk. , ?
Source: https://habr.com/ru/post/327754/
All Articles