Failover Evolution in PostgreSQL: Time Travel
Friends, today we bring to your attention the translation of the third part of a series of articles by one of the reporters of PG Day'17 Russia Gulcin Yildirim on PostgreSQL resiliency .
PostgreSQL is a terrific project that is evolving with amazing speed. In this series of articles, we will focus on the evolution of fault tolerance capabilities in PostgreSQL throughout its versions. This is the third article in the series, and we’ll talk about the timelines problems and their impact on the resiliency and reliability of PostgreSQL.

If you want to trace the evolution of Postgres from the very beginning, read the first two articles in this series:
')
Timelines
The ability to roll back the database to any of the previous states creates certain difficulties. We will examine some of them by examining failover situations (Fig. 1), switchover (Fig. 2), and pg_rewind (Fig. 3).
For example, suppose that in the original database history you deleted a critical table at 5:15 pm on Tuesday evening, but realized your mistake only at noon on Wednesday. Without batting an eye, you get a backup copy and roll back to the state at 5:14 pm Tuesday, and everything works again. In the history of this database universe, you have never deleted a table. But suppose you later realized that the idea was not so good, and you would like to return to the state on Wednesday morning from the original story. It won't work for you if, after the database started working again, it rewrote some of the WAL segments that led to the point in time you would like to return to.
Thus, to avoid this, you need to separate the series of WAL records generated after you performed a point-in-time recovery from those made in the original database history.
To solve this problem in PostgreSQL, there is the concept of timeline. Whenever an archive restore is completed, a new timeline is created to identify the series of WAL records generated after this recovery. The timeline identification number is part of the file names of the WAL segments, so the new timeline does not overwrite the WAL data generated by the previous timeline. That is, you can archive many different timelines.
Consider a situation where you are not sure at what point in time you need to recover, and you have to do several restorations in order by trial and error to find the best place to branch from the old story. Without timelines, this process would soon create an uncontrollable mess. And with them you can recover to any previous state, including the states in the timelines branches that you previously abandoned.
Each time a new timeline is created, PostgreSQL creates a “timeline history” file, which shows from which timeline it originated and when. These history files are required to enable the system to select the correct WAL segment files when restoring from an archive containing several timelines. That is, they are stored in the WAL archive as well as the WAL segment files. History files are just small text files, so they are cheap and expedient to store for an indefinite time (unlike large segment files). If you want, you can add comments to the history file to record your own notes on how and why this particular timeline was created. Such comments are especially valuable when, as a result of experiments, you have a tangle of different timelines.
By default, recovery occurs at the same timeline, which was current at the time of creating the basic backup. If you want to recover in some child timeline (that is, you want to return to the state that was generated after the recovery attempt), you need to specify the timeline ID in recovery.conf. You cannot restore to timelines that branched out before the basic backup was created.
To simplify the timelines concept in PostgreSQL, related issues in the failover , switchover, and pg_rewind cases are summarized and explained in Figures 1, 2, and 3.
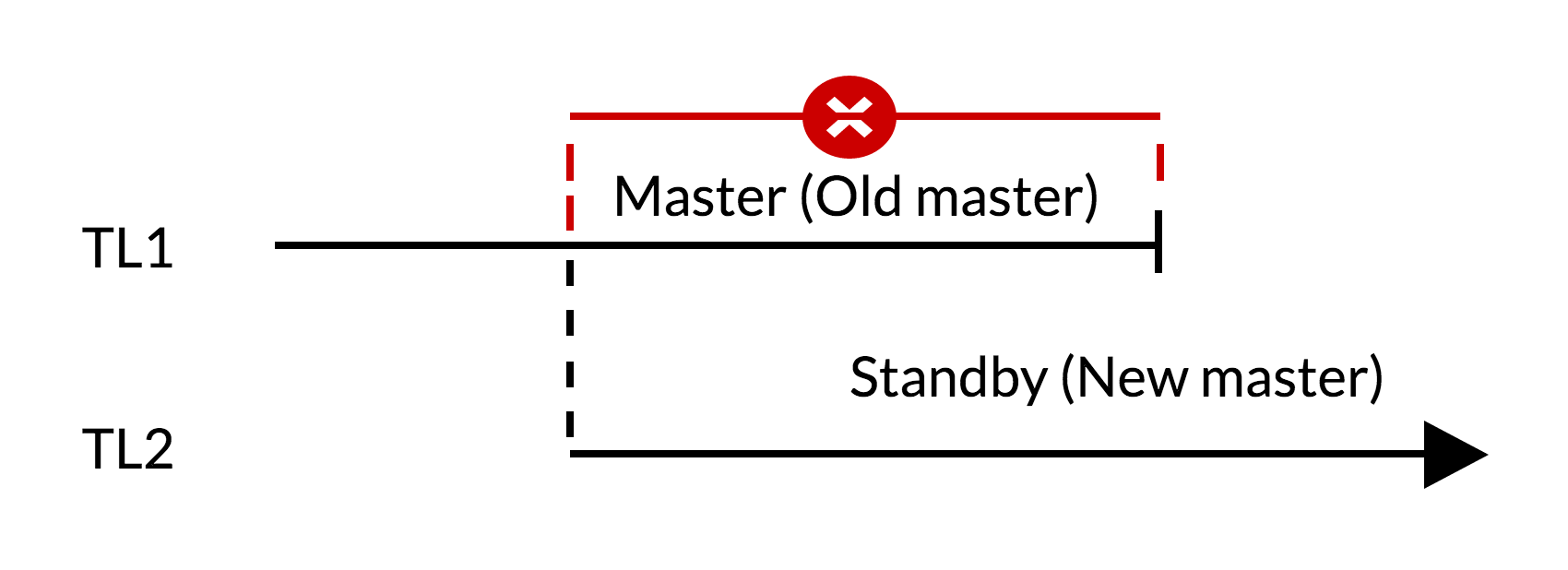
Failover script :
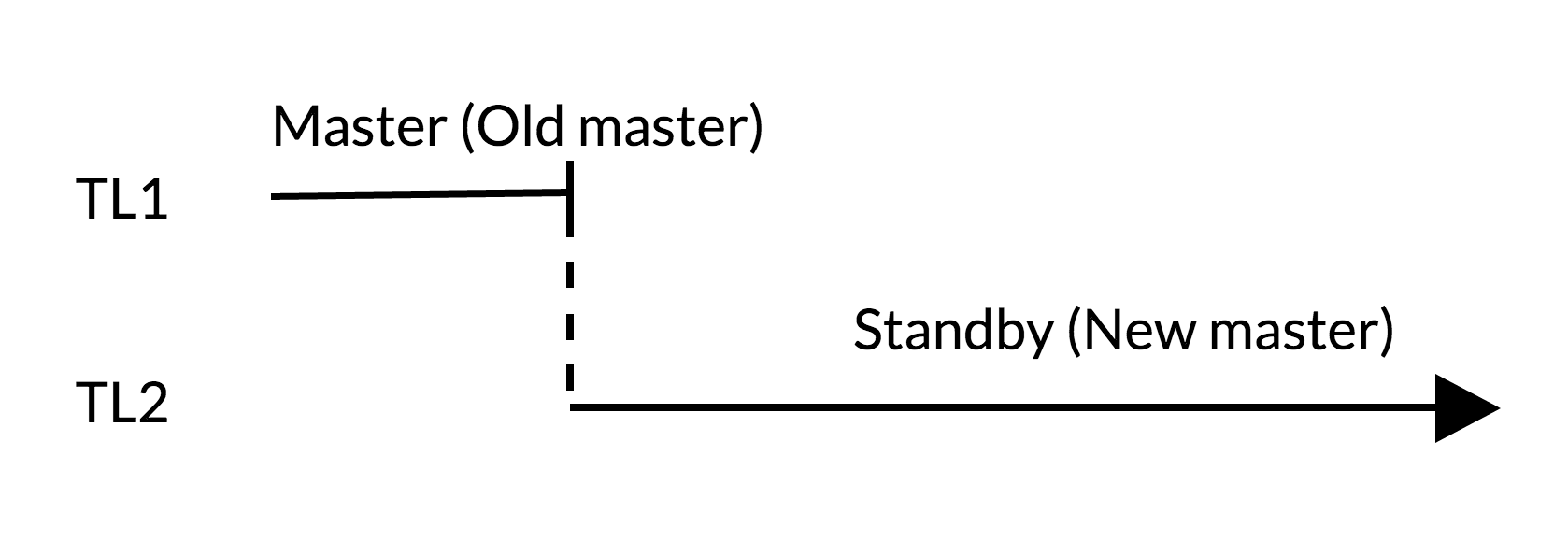
Switchover script :
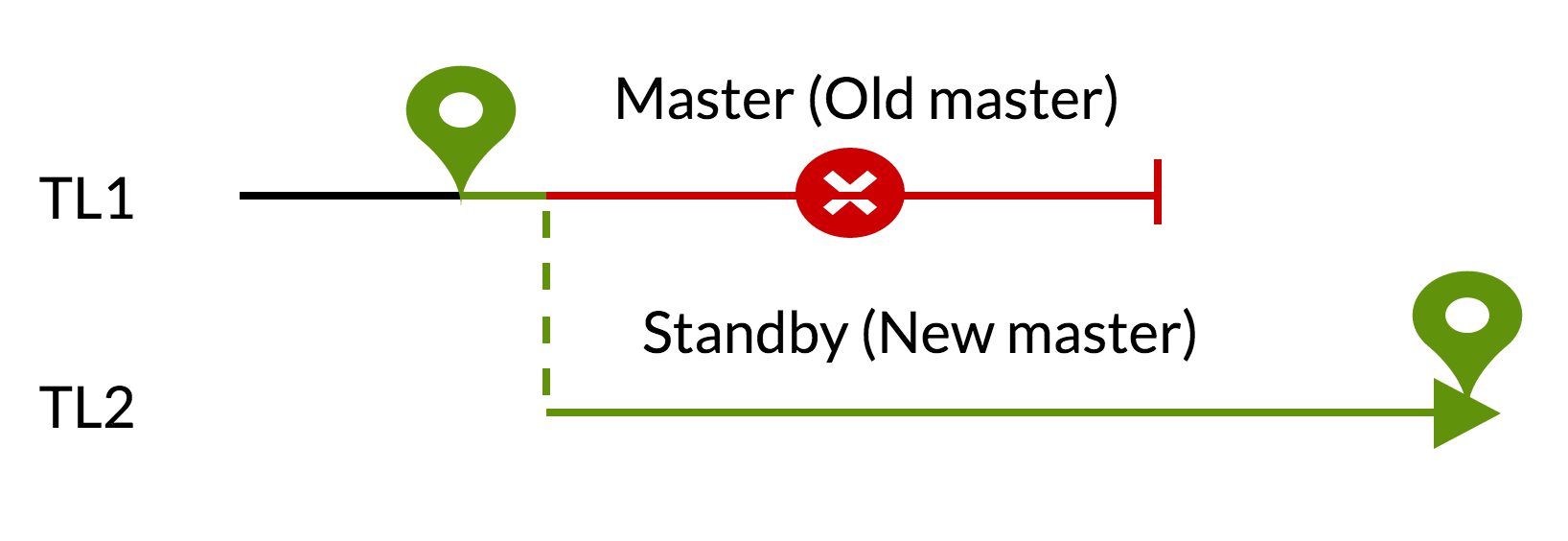
Script pg_rewind :
pg_rewind
pg_rewind is a tool to synchronize a PostgreSQL cluster with another copy of the same cluster after the timelines of the clusters have diverged. A typical scenario: after a failover, the old primary server again rises as standby to the new primary.
The result is equivalent to replacing the target data directory with the original one. All files are copied, including configuration. The advantage of pg_rewind over the removal of a new basic backup or with tools like rsync is that pg_rewind does not require reading all the unchanged files in the cluster. Therefore, this method is much faster, especially in cases where the database is large, and only small parts of it differ between clusters.
How it works?
The basic idea is to copy everything from the new cluster to the old one, except for the blocks that are known to have not changed.
Note : The wal_log_hints parameter must be configured in postgresql.conf for pg_rewind to work. This parameter can only be configured at server startup. The default is off .
Conclusion
In this article, we discussed the timelines in Postgrese and how we handle failover and switchover situations . We also talked about how pg_rewind works and its contribution to the resiliency and reliability of Postgres. In the next article, we will continue the discussion of synchronous commits.

Gulcin will arrive at PG Day'17 and personally answer the questions of the participants, as well as tell in more detail about the automation of Postgres upgrades in the cloud . How to solve the problem of upgrading to major versions using the logic decoding functionality available in versions 9.4+? The answer lies in the use of pglogical . And, as a bonus, automate the proposed solution with Ansible . Register and prepare your questions!
PostgreSQL is a terrific project that is evolving with amazing speed. In this series of articles, we will focus on the evolution of fault tolerance capabilities in PostgreSQL throughout its versions. This is the third article in the series, and we’ll talk about the timelines problems and their impact on the resiliency and reliability of PostgreSQL.
If you want to trace the evolution of Postgres from the very beginning, read the first two articles in this series:
')
Timelines
The ability to roll back the database to any of the previous states creates certain difficulties. We will examine some of them by examining failover situations (Fig. 1), switchover (Fig. 2), and pg_rewind (Fig. 3).
For example, suppose that in the original database history you deleted a critical table at 5:15 pm on Tuesday evening, but realized your mistake only at noon on Wednesday. Without batting an eye, you get a backup copy and roll back to the state at 5:14 pm Tuesday, and everything works again. In the history of this database universe, you have never deleted a table. But suppose you later realized that the idea was not so good, and you would like to return to the state on Wednesday morning from the original story. It won't work for you if, after the database started working again, it rewrote some of the WAL segments that led to the point in time you would like to return to.
Thus, to avoid this, you need to separate the series of WAL records generated after you performed a point-in-time recovery from those made in the original database history.
To solve this problem in PostgreSQL, there is the concept of timeline. Whenever an archive restore is completed, a new timeline is created to identify the series of WAL records generated after this recovery. The timeline identification number is part of the file names of the WAL segments, so the new timeline does not overwrite the WAL data generated by the previous timeline. That is, you can archive many different timelines.
Consider a situation where you are not sure at what point in time you need to recover, and you have to do several restorations in order by trial and error to find the best place to branch from the old story. Without timelines, this process would soon create an uncontrollable mess. And with them you can recover to any previous state, including the states in the timelines branches that you previously abandoned.
Each time a new timeline is created, PostgreSQL creates a “timeline history” file, which shows from which timeline it originated and when. These history files are required to enable the system to select the correct WAL segment files when restoring from an archive containing several timelines. That is, they are stored in the WAL archive as well as the WAL segment files. History files are just small text files, so they are cheap and expedient to store for an indefinite time (unlike large segment files). If you want, you can add comments to the history file to record your own notes on how and why this particular timeline was created. Such comments are especially valuable when, as a result of experiments, you have a tangle of different timelines.
By default, recovery occurs at the same timeline, which was current at the time of creating the basic backup. If you want to recover in some child timeline (that is, you want to return to the state that was generated after the recovery attempt), you need to specify the timeline ID in recovery.conf. You cannot restore to timelines that branched out before the basic backup was created.
To simplify the timelines concept in PostgreSQL, related issues in the failover , switchover, and pg_rewind cases are summarized and explained in Figures 1, 2, and 3.
Failover script :
- on the old master there are changes not applied to standby (TL1);
- growth timelin reflects a new change history (TL2);
- changes from the old timeline cannot be reproduced on servers that have switched to the new timeline;
- The old master cannot become a replica of the new.
Switchover script :
- in the old master there are no changes that are not applied to standby (TL1);
- the growth timeline reflects the new change history (TL2);
- the old master can standby for the new.
Script pg_rewind :
- uncommitted changes will be deleted using data from the new master (TL1);
- The old master can become standby for the new (TL2).
pg_rewind
pg_rewind is a tool to synchronize a PostgreSQL cluster with another copy of the same cluster after the timelines of the clusters have diverged. A typical scenario: after a failover, the old primary server again rises as standby to the new primary.
The result is equivalent to replacing the target data directory with the original one. All files are copied, including configuration. The advantage of pg_rewind over the removal of a new basic backup or with tools like rsync is that pg_rewind does not require reading all the unchanged files in the cluster. Therefore, this method is much faster, especially in cases where the database is large, and only small parts of it differ between clusters.
How it works?
The basic idea is to copy everything from the new cluster to the old one, except for the blocks that are known to have not changed.
- The WAL list of the old cluster is scanned, starting with the last checkpoint before the moment when the timeline history of the new cluster was branched off from the old one. For each WAL entry, a note is made about which data blocks have been affected. This creates a list of all the data blocks that were changed in the old cluster after the new cluster branched off.
- All these modified blocks are copied from the new cluster to the old one.
- All other files, such as clog and configuration files, are copied from the new cluster to the old one. Everything except the relation files.
- WALs from the new cluster are applied, starting at the checkpoint created at the time of the failover. (Strictly speaking, pg_rewind does not apply WAL, but simply creates a backup shortcut file, indicating that when you start PostgreSQL it will start playing from this point of reference and will apply all the required WALs.)
Note : The wal_log_hints parameter must be configured in postgresql.conf for pg_rewind to work. This parameter can only be configured at server startup. The default is off .
Conclusion
In this article, we discussed the timelines in Postgrese and how we handle failover and switchover situations . We also talked about how pg_rewind works and its contribution to the resiliency and reliability of Postgres. In the next article, we will continue the discussion of synchronous commits.
Gulcin will arrive at PG Day'17 and personally answer the questions of the participants, as well as tell in more detail about the automation of Postgres upgrades in the cloud . How to solve the problem of upgrading to major versions using the logic decoding functionality available in versions 9.4+? The answer lies in the use of pglogical . And, as a bonus, automate the proposed solution with Ansible . Register and prepare your questions!
Source: https://habr.com/ru/post/327750/
All Articles