Training with reinforcements on the example of the game "tic-tac-toe"
Tic-tac-toe is a game studied far and wide, and the development of AI for it can be reduced to organizing the decision tree described in Wikipedia . This article will consider the solution of the game through training with reinforcement and approximation of the value functions.
We accept the following rules:
The next step is to prepare the value function for the agent. In our case, the value function will be the state table of the game, in which a value from 0 to 1 will indicate that a particular state is “better” than another. Initially, we set in our table that all winning combinations (three crosses in a row, column or diagonally) give a probability equal to 1. Similarly, all the states with three zeros are 0. For all other states, the probability is 0.5.
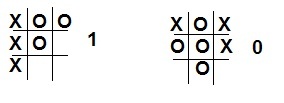
In order to simplify the compilation of a probability table, we assume that
')
Opponent will be a person who accordingly will play for zeroes and periodically succumb. During the game, there will be a change in the value of its states. In order to properly evaluate the actions of the agent, it is necessary to record the sequence of those states that he chose and at the end of the game to recalculate them. The formula for calculating the value of V (s) will be as follows:
,
where A is the size of the step affecting the speed of learning. V (s') - the value of the action at the end of the game (1 - if won, 0 - otherwise).
The size of the step affects whether the opponent’s strategy changes or not. If you need to take into account the variability of the strategy, then you need to leave the step size constant. Otherwise, if the step is reduced to zero, the agent will stop his training.
The use of probing moves (having no high value) allows you to check conditions that, because of the high value of other moves, would never have been fulfilled, which gives a small chance of changing the strategy to a winning side.
In the above located code, possible moves are selected (states in which elements are identical to the current state of the field, and there is one more cross). Then, either an arbitrary move (with a probability of 5%) or a “greedy” move (with maximum value) is selected from the obtained states. At the end of the selection, this move is recorded in a separate array of moves made.
At the end of the game, there is a recalculation of the value of the moves made, as already mentioned.
→ Program and project in C ++ Builder 6
In this example, one aspect of reinforcement learning was briefly reviewed. If the agent usually contacts the environment, then in this example the training was carried out with the opponent player. Although this example is quite simple, it may seem that this method in other examples will be very limited than it really is.
Training with reinforcements / R.S.Sutton, E.G. Barto - Moscow: BINOM. Laboratory of knowledge, 2014
Prep
We accept the following rules:
- The agent goes first and plays "crosses".
- The agent will only make decisions with maximum value.
- With a 5% chance the agent will make probing decisions.
- Only if the agent wins, he gets a reward.
The next step is to prepare the value function for the agent. In our case, the value function will be the state table of the game, in which a value from 0 to 1 will indicate that a particular state is “better” than another. Initially, we set in our table that all winning combinations (three crosses in a row, column or diagonally) give a probability equal to 1. Similarly, all the states with three zeros are 0. For all other states, the probability is 0.5.
In order to simplify the compilation of a probability table, we assume that
states. Of course, half of these combinations is impossible, but the code was not optimized for the purpose.
')
Probability table initialization code
float V[19683]; //------- void setV(int a1,int a2,int a3,int b1,int b2,int b3,int c1,int c2,int c3,float v) { int num; num = ((((((((a1*3)+a2)*3+a3)*3+b1)*3+b2)*3+b3)*3+c1)*3+c2)*3+c3; V[num] = v; } //------- for (int i1=0;i1<3;i1++) for (int i2=0;i2<3;i2++) for (int i3=0;i3<3;i3++) for (int i4=0;i4<3;i4++) for (int i5=0;i5<3;i5++) for (int i6=0;i6<3;i6++) for (int i7=0;i7<3;i7++) for (int i8=0;i8<3;i8++) for (int i9=0;i9<3;i9++) { setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0.5); if (i1==i2 && i2==i3 && i3==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i4==i5 && i5==i6 && i6==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i7==i8 && i8==i9 && i9==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i1==i5 && i5==i9 && i9==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i7==i5 && i5==i3 && i3==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i1==i4 && i4==i7 && i7==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i2==i5 && i5==i8 && i8==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i3==i6 && i6==i9 && i9==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i1==i2 && i2==i3 && i3==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); if (i4==i5 && i5==i6 && i6==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); if (i7==i8 && i8==i9 && i9==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); if (i1==i5 && i5==i9 && i9==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); if (i7==i5 && i5==i3 && i3==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); if (i1==i4 && i4==i7 && i7==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); if (i2==i5 && i5==i8 && i8==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); if (i3==i6 && i6==i9 && i9==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); } Course of the game
Opponent will be a person who accordingly will play for zeroes and periodically succumb. During the game, there will be a change in the value of its states. In order to properly evaluate the actions of the agent, it is necessary to record the sequence of those states that he chose and at the end of the game to recalculate them. The formula for calculating the value of V (s) will be as follows:
,
where A is the size of the step affecting the speed of learning. V (s') - the value of the action at the end of the game (1 - if won, 0 - otherwise).
The size of the step affects whether the opponent’s strategy changes or not. If you need to take into account the variability of the strategy, then you need to leave the step size constant. Otherwise, if the step is reduced to zero, the agent will stop his training.
The use of probing moves (having no high value) allows you to check conditions that, because of the high value of other moves, would never have been fulfilled, which gives a small chance of changing the strategy to a winning side.
Agent Selection Code
void stepAI(void) { int flag; c_var=0; for (int i=0;i<19683;i++) { flag=0; readMap(i); for (int j=1; j<10;j++) if (rm[j]!=m[j]) if ((m[j]==0) && (rm[j]==1)) flag++; else flag+=2; if (flag==1) { var[c_var]=i; c_var++; } } float v_max; int v_num_max; if (random(100)<5) v_num_max=random(c_var); else { v_max = V[var[0]]; v_num_max = 0; if (c_var>1) for (int i=1;i<c_var;i++) if (V[var[i]]>v_max) v_num_max = i; } steps++; steps_m[steps]=var[v_num_max]; readMap(var[v_num_max]); for (int i=1;i<10;i++) m[i]=rm[i]; paintMap(); } In the above located code, possible moves are selected (states in which elements are identical to the current state of the field, and there is one more cross). Then, either an arbitrary move (with a probability of 5%) or a “greedy” move (with maximum value) is selected from the obtained states. At the end of the selection, this move is recorded in a separate array of moves made.
At the end of the game, there is a recalculation of the value of the moves made, as already mentioned.
Value Recalculation
void learnAI(int res) { for (int i=0;i<steps;i++) V[steps_m[i]] += A * (res - V[steps_m[i]]); A -= 0.01; } Total
→ Program and project in C ++ Builder 6
In this example, one aspect of reinforcement learning was briefly reviewed. If the agent usually contacts the environment, then in this example the training was carried out with the opponent player. Although this example is quite simple, it may seem that this method in other examples will be very limited than it really is.
Used Books
Training with reinforcements / R.S.Sutton, E.G. Barto - Moscow: BINOM. Laboratory of knowledge, 2014
Source: https://habr.com/ru/post/327714/
All Articles