Introduction to cryptography and encryption, part two. Lecture in Yandex
We return to the most brief introduction to cryptographic theory from Vladimir ivlad Ivanov. This is the second half of the lecture - we published the first part a few days ago. To her you can even send pullrequests on a githaba.
Under the cut - decoding and part of the slide.
- The real situation is as follows: a collision between two random samples of 256 bits in length will reach a probability of ½ at about 4 billion samples. So, if we consider a stream of blocks with a length of 64 random bits, then with probability ½ among 2 32 such blocks there will be two identical ones.
')
What is the practical value of this scientific fact? The output of the encryption function can be viewed as a random number, and the ideal encryption function is indistinguishable from a random number. So, if we consider blocks encrypted, for example, by DES or GOST-28147, then taking 2 32 such blocks, we will, with probability ½, find out that two of them are encrypted in the same way.
Let's think someone counts: 2 32 blocks of 64 bits or 8 bytes - how much? 32 gigabytes? It looks like the truth. Now we divide 32 gigabytes into 10 gigabits. If we have an encryption algorithm with 64-bit blocks, then a little later than after 32 seconds, we will see a collision. We will see two blocks that are encrypted in the same way. As found out in the SVS, these two blocks do not have to be with the same plaintext. Plain text may be different.
What will it mean? If we have some C i block, then what was encrypted in CBC mode?
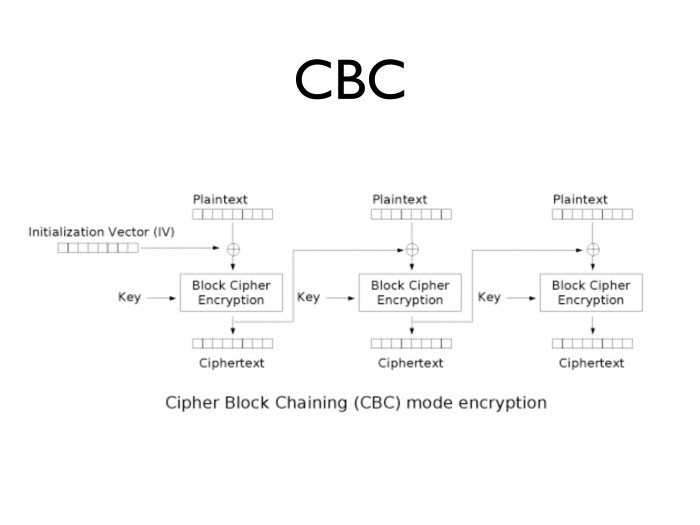
Let's say we watched a collision after 30 seconds. The two parts are equal. Encryption is one-to-one. Thus, since the encryption functions are equal, then the encoding is also equal.
C j-1 and C i-1 - we saw them, because they had just been transmitted in the communication channel.
In other words, if we have such a small block size, then even with absolutely strong encryption, after some time we will begin to get differences between some two random open texts. This property is not necessarily transformed into a real attack, but in practice it is not very good. Because of him, the CBC mode is the cause of many ills.
The last of these troubles is the attack (indiscernible - ed.), Published just a couple of weeks ago. It is extreme, but, I think, not the last in this series. And all because of the unfortunate properties of the CBC, which I described.
However, CBC is still a widespread encryption mode. It can be found anywhere.
- If you need to take the last 10 bits, we will have to count sequentially ...
- Yes, of course, the CBC has a problem: to decrypt 1 gigabyte and read the last 10 bytes in it, you must first generate it all.
Despite all the difficulties with CBC, it is still the most common encryption mode: TLS is accurate, but I think that in IPsec, that is, in real-life protocols.
How to deal with this in real life? First and foremost, Triple DES is no longer widely used. Further, if you look at AES with a block size of 128 bits, then the probability of a ½ collision occurs after about 2 64 blocks, and this is a lot of traffic. Therefore, in real life, the likelihood that we stumble upon a collision is low. So do not use Triple DES and GOST-28147, if you are not a government organization and do not have to use them.
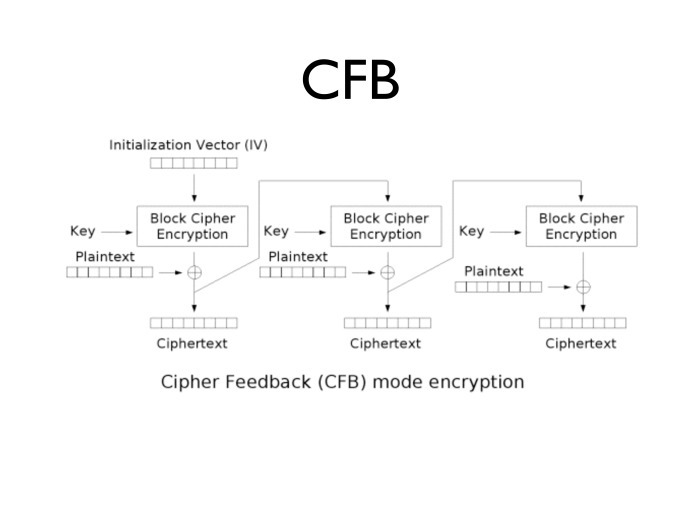
CBC is not the only encryption mode. There are still CFB. He, if you look closely, is very different from the CBC. We take the initialization vector, copy the plaintext with it and get the ciphertext. We encrypt the result again, we repeat the plaintext with it, we get the second block of text, etc.
Why did I even talk about CFB? Because, unlike CBC, the CFB variant is standardized for GOST. If you look closely, in this sense it is no better than CBC - it has the same problem. In closed systems, you can meet with the specified implementation, with it, in principle, some problems arise.
What other problems do these algorithms have? To decrypt every next block, we need encrypted plaintext. Without an accessible plaintext block, we cannot generate the next encryption block. In order to get rid of this problem, OFB mode was invented, which is arranged like this: an initialized vector is given, it is encrypted with a key, the result is encrypted with a key again, again ... In fact, we take and encrypt the initialization vector many times - as many blocks as we need.
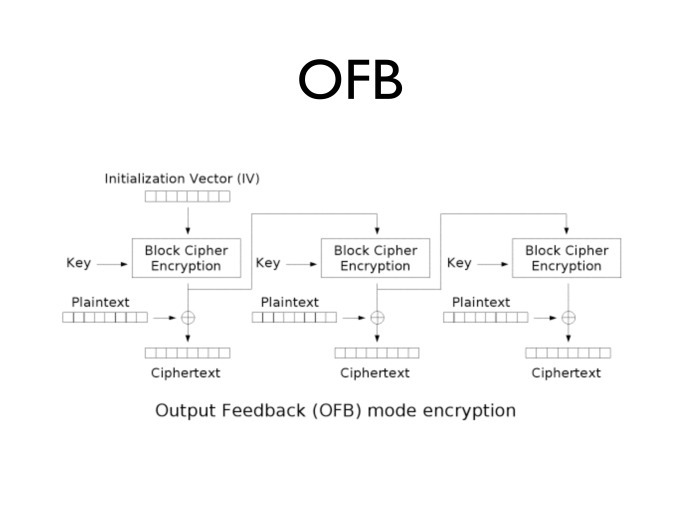
We add the blocks with clear text. Why is this convenient? If you look closely, block encryption mode becomes streaming. If there is little traffic now and the processor is free, we can generate several blocks ahead of time and then use them up with a possible surge in traffic. Very comfortably. And we do not need the knowledge of plaintext to encrypt the next block. You can type and keep a few gigabytes in memory - in case you need it.
All the flaws of stream ciphers are also present here.
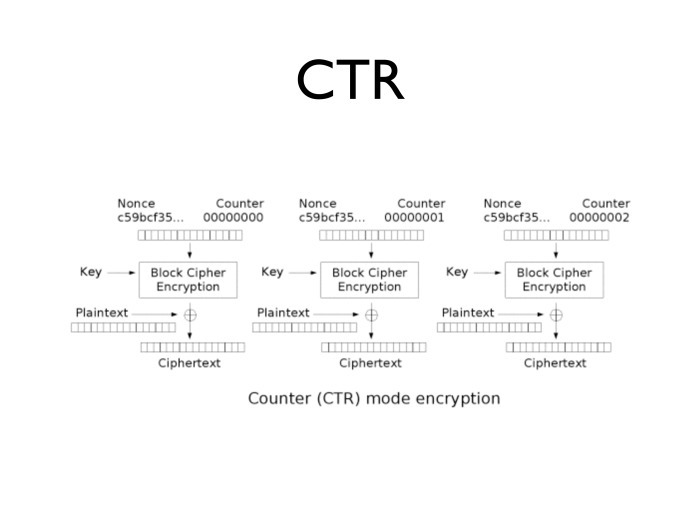
A slightly different encryption method is the so-called counter mode or CTR. It is arranged simply: we take a certain random number, we place it at the beginning of the block, and at the end we simply put the counter from zero to as many as you like. For example, up to 64 bits. We take and divide in half: we give the left 64 bits to a random number, and the right 64 bits to the counter.
Encrypt each such number and reduce the result with clear text.
What is convenient CTR? It allows us to encrypt the 125th block without encrypting the previous 124 blocks, that is, solves the problem of decrypting the last 16 bytes from a 10-gigabyte file. It is quite convenient in all other senses. If we talk about a surge in traffic, you can generate blocks for encryption ahead of time.
This is the case with messages longer than one block. And what if they are shorter than one block? In other words, we want to encrypt not 16, but 8 bytes.
- Finish to 16.
- But as? Suppose we deciphered a block, at the end of which has four zeros. How do we know that these four zeros are finished by us, and not a fragment of our blocks?
- Before transmitting the encrypted message, report the length in bytes.
- A convenient way, but it is inconvenient because you don’t always know the size before the transfer. If email - you know, and if not?
After the transfer? Okay, maybe you can. And where is there to look for differences? It is necessary to store in a separate place. The question is which one?
- Not within the scope of encryption.
- If not within the scope of encryption to transmit the length of the message, you will disclose it. I think we were hiding her.
Welcome to my personal hell, namely to the system with padding. The idea that you need to write at the end of the message how long it is is not very bad. It is only important to think of a way to complement the block, which will uniquely establish that this piece at the end is an addition, not part of the data.
There are several modes of padding, and unfortunately, the most common of them has several unpleasant properties.
We take and at the end of the last block we add each free byte to the number of free bytes. If at the end there are 3 bytes left - we take and write them: 3, 3, 3.
If the length of the message falls exactly on the border, we supplement it with another block, where we write, I think, four zeros. Not fundamentally. This encoding method is always unambiguous. We open, find out the last byte and, if it is not zero, we understand - it is necessary to count how many bytes. In fact, this is a cleverly coded message length. If the last byte is zero, we can discard the entire block. And we know that a full block can never end with zero: then we would complement it with another completely zero block.
If the last block ends with a unit, then it is complete and we will definitely supplement it with one more block.
It would seem normal. Before us is the working mechanism of padding.
Suppose we are attacking. We have an Oracle system - it is so called in cryptography. This is not the Oracle that makes the database. This is a box whose device you do not know, but in this case it is an encryption or decryption algorithm. You do not know which key is inside, although it gives you some kind of answer. However, it will definitely not give you an answer on whether the line you put in it was correctly or incorrectly deciphered.
So, you have the specified box. In this case, you saw one message and know for sure that it was decoded normally. Oddly enough, in real systems such a message is easy to get.
Then you take the message and send it to the box, changing in it one last byte. A box can return two states to you. Either you learn that your construction was somehow well deciphered, or - that it was not deciphered due to a padding error.
How does everything work? Your program code is trying to decrypt something, decrypts and further checks the padding at the end. If the padding does not meet the standard, you see "333" or something is wrong, not the entire last block is zero, then it will tell you: "padding error". At the expense of such a scheme you can sort out the last bytes of the last block in a rather simple way. For example, if you use the unfortunate mode of CBC, then, having disassembled a piece of plain-text, you can understand what was there.
It would seem that everything looks pretty harmless. But in practice, the problem with padding oracle attacks, for example, led to the remote execution of malicious code in Windows 2003 sometime in 2008.
Why it happens? We are trying to decipher something without verifying that the incoming message was really sent by the one from whom we are waiting for something.
Welcome to authentication. Everything we talked about just ensured the confidentiality of the message. Using encryption, we send the message and we can be sure that no one except the recipient will read it. But when the recipient receives the message, how can he verify that the message was actually received from the sender? For such a test, there is a separate set of message authentication protocols. In English, this is called a MAC - message authentication code.

What are the problems here? There is a problem with streaming encryption algorithms. Suppose there is a message about which we know nothing. There is a gamma that is somehow generated. Ciphertext is obtained. Suppose the cipher is absolutely strong and everything is fine with it. But imagine that the attacker took and changed some bit in the message that we receive. Will we detect an error? Obviously not.
If he changed the zero bit to one, he unpredictably changed the plaintext. If he changed the unit to zero in the ciphertext and in the original message there was also zero in this place, it will change to one. If we "flip" a bit in ciphertext, it flips in cleartext. And this problem cannot be detected by means of a single encryption algorithm.
It is clear that in the block cipher there will be more problems, that they will accumulate and that you will surely encounter the problem of padding, but in general, this problem is still there. Encryption alone does not provide message authentication. Need a separate mechanism.
The mechanism is called MAS. How does he work?
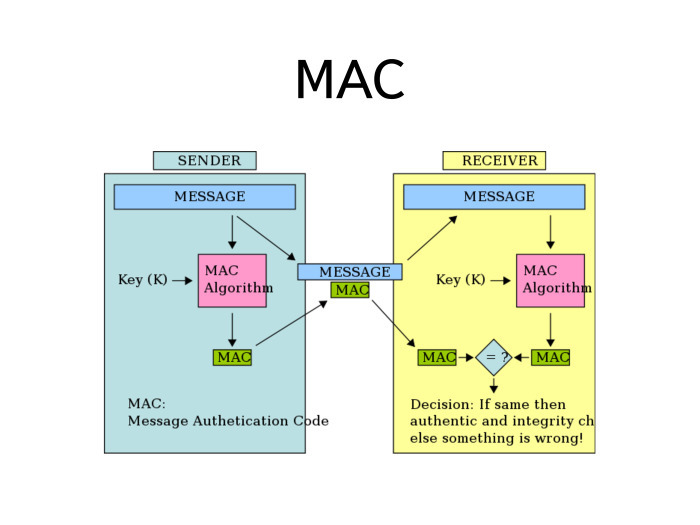
We take the message and pass through a special function called the MAC algorithm. At the input, the MAC algorithm receives not only a message, but also a key that is different from the encryption key.
When we want to send a message, we attach the result of the algorithm to it. The recipient takes the message, performs the same operation and compares the MAS, which he calculated, with the MAS, which he received. If they match, then the message has not been changed in the process. And if the two IASs did not match, then a problem happened along the way.
What can be used as a MAC function? You can use the number of units, but it seems that such a scheme is easily forged.
The hash function is the obvious answer. And more?
For a long time, SAF MAS were distributed. We take a construction in which there is no initialization vector, and everything else is the same. We take a ciphertext - we encrypt, we “crawl”, we cipher, we “crawl” ... It turns out the last block, where all the information about our text is accumulated. Very comfortably.
But it is also quite true that you can use any cryptographic hash as an element of the MAS. There are several cryptographic hashes, the most common of which is MD5, the SHA family, GOST 34.11 ... and the competition for SHA-3 recently ended, in which Keccak won.
Hashs are more complex than encryption algorithms, but in its principle the idea of building a hash function is similar to the block encryption algorithm. In other words, we take some kind of data block and consistently, several times apply to it a set of fairly primitive operations. If you look at MD5, then there is only addition modulo 2 and cyclic shifts. We use them many times - as a rule, much more than in the case of block encryption algorithms. If there is a text along the way, from which we need to take a function longer than one block, then we follow them using a method a little bit similar to CBC. We add these fragments to our calculated function.
The result of the hash calculation is numbers. The length of the number is always fixed. Typical hash output sizes for MD5 are 128 bits, for SHA-1 - 168 bits, for SHA-256 - 256 bits, for SHA-384 - 384 bits, and for SHA-512 - 512 bits.
What else is important to say about hashes? With small changes in the input, the hash is required to provide large changes in the output. So, if we changed one bit in the plaintext at the input, then ideally the hash, the result of the calculation of the hash function, should change exactly by half.
Now in actual practice it is recommended to use SHA-2, and specifically SHA-256 or SHA-384 - depending on your needs. MD4 is broken for a long time, MD5 - in principle, also broken: just yesterday, a new attack on MD5 was published, where the guys use Sony PlayStation to generate collisions coolly. We can assume that the use of MD5 is no longer necessary. In real life, always use SHA-2.
Where else besides authentication, hash functions are used? In the key generation protocol, for example in PBKDF2. Suppose you need to encrypt a file. You take the user and, as a rule, ask for the password with which you need to encrypt the file. In a real-life situation, the user enters something like a sequence from 1 to 5 as a password, and his work will be completed.
On the one hand, you want your encryption key to be not as predictable as “12345”, and that the distribution of bits is more uniform. On the other hand, if an attacker begins to sort through all possible passwords, each brute-force attack should take as much time as possible. The indicated class of KDF-functions is aimed at exactly that.
PBKDF2 is a specific function from the class of key generation functions. It is arranged very simply. It only does that it applies a hash algorithm several tens of thousands of times. And along the way - at each stage - it mixes up additional data so that it is rather difficult to calculate it in advance.
Since the hash function has been running for quite a long time, performing hash functions several thousand times takes even longer. In other words, we are protected in a convenient way from an attacker who tries to sort out several common passwords.
In real life, when the KDF function is used, it is recommended to choose the number of iterations so that it is, on the one hand, acceptable to an impatient user, and on the other, unacceptable to an attacker who wants to pick up several million keys. In real life, select such a number of iterations in KDF, so that, for example, it is executed in one second. For an attacker, one second is an absolutely indecent time, while the user, pressing the button and waiting for the password to be verified, is quite capable of waiting for one second.
Storing passwords is the same use of hashes. Anton in the story about UNIX will definitely tell about it.
Since we have padding oracle and similar attacks, when we generate a message, there are two options.
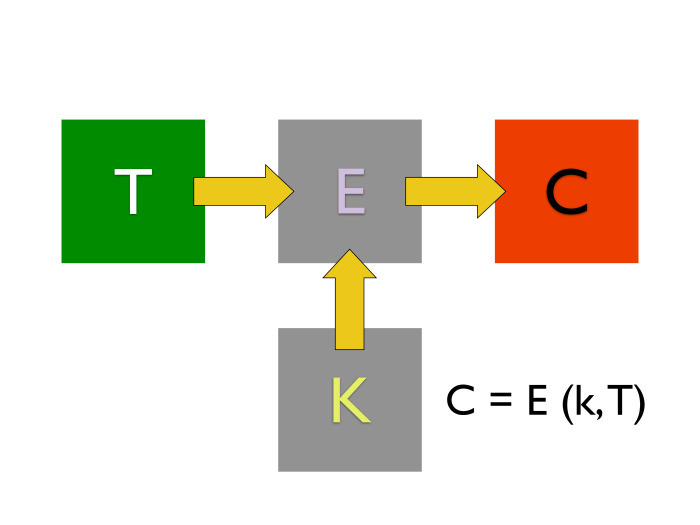
There is a crypto-primitive type of MAS, and there is a crypto-primitive for encryption. We want to send a message and authenticate it. There are two ways. We can encrypt the message, then take the MAC from this thing and attach it to the message. Entirely it will look like this: E (T) || MAC (E (T)).
The second way is the following: we take the message, encrypt it and take the MAC from the plaintext. Because why do we need an extra operation?
In fact, one is called MAC before encrypt, and the second is encrypt before MAC.
The question is - which is better? Equally? Okay, more versions?
There is another great way - they say, let's encrypt the MAS so that no knowledge about the plaintext is leaking.
Indeed, there is a problem with this method: if you encrypt a message with it, there will be a risk of encountering a padding oracle attack. Padding oracle doesn't care if you have MAC at the end or some other data. You will have a box that first tries to decrypt the message. If due to improper padding, it does not decrypt, the box will not even check the MAC, and will immediately respond to the attacker or someone else that "I could not decipher this thing." Enough unpleasant. Therefore, here is a general recommendation for the design of such systems - if you do not know what you are doing, it is better to use such a thing, and if you know, this one: E (T) || MAC (E (T)).
Just six months ago, Anton and I discussed about one place, and I insisted on using the second design. I thought I knew what I was doing. And I still think that I knew what I was doing, because there was no padding oracle.
We are able to encrypt our message, we are able to verify that the received message really came from the sender. : A B , .
, , , , , . - KDF- : , . .
? — . — . — . 100 , . , 100 , — .
, , , .
— .
?
k 1 k 2 , . k 1 , k 2 . , .
: k 1 k 2 , , , . , .
, , . , , - .
, , , , P = NP. . RSA, , . .
, , . - (DH). , , .
. P G. .
a . .
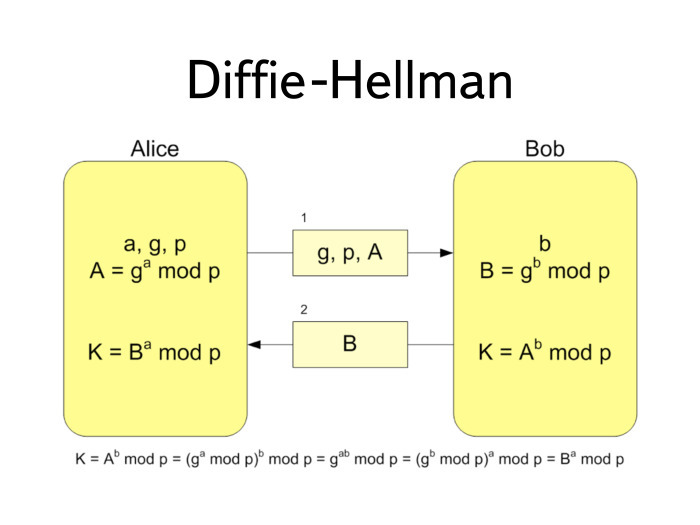
- , B . G P . , G P . .
What happens next? . , , , b. : a = A b . .
, , , . It turned out very convenient.
, , , , — 0.
, , — RSA.

. — 1024 . 2048, 4096 8192: , .
— .
(n-1)(p-1). — , .
, : , . - . .

— . , .
, d — . . , , . RSA.

, , . , k, , k — .


, - , - , n. . , , .
-, d.
de = 1 n, , M ed mod n, , M 1 n. . M 1 = M.
RSA, ? , k 1 k 2 , , — . — , d — . , , , , , . : M e , d, M d , .
RSA, ?
, - . XOR , . , , . . — , , .
. , , . RSA , — . . : - , - , , -.
RSA 1024, 2048, 4096 — . AES, DES Salsa : 256, 128 64 DES.
, — RSA-2048 AES-256? RSA , , AES 2 256 , RSA — . , . 2 2048 .
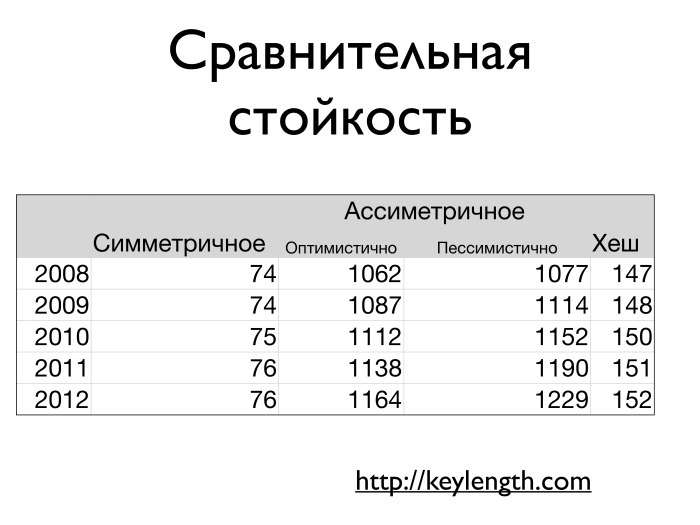
, , - - . , . , , . , .
- , . , 2014 AES 78-80 . , RSA, 1300-1400 . keylength.com , . — 160-170 . SHA1 2014 , — 168 .
- , , .
. , , , .
. : . : . , .
. , email. , ?
— , 128 . ? , . .
, .
, , , .
.
. . , , - . , .
.
128- , . 128- , , . , . . .
? , . , . , , … - ?
, . . ?
, , … , . padding oracle, , , .
? , , , . , . , , — , .
, , . : , , . -, — . -, , .
? , , .
. , , S/MIME PGP. , , , .
, . , . , , . , . ? What is the difference?
: , DH , , . .
, DH, , , .
DH (. man-in-the-middle MITM — . .). , , , . , , - , , , , - . DH- — . , , .
What to do? , .
— , — …
— ? ?
— …
— ? .
— , .
— . , ?
— … .
— ? , DH : , , .
— DH- MITM?
- Not. , DH-? , DH- . MITM , ? I do not believe.
, ? Signature. , A . Everything. .
? , . , . — , -, , , -, , .
: , , , . . DH.
, . , -. , , .
, . . - DH-, , ?
? , . . ? . - ? , . .
, - . . . : , , , , — . . , , MD5 SHA, . , - . HMAC. , .
, , . , , . C 1 . , C 2 , , .
. , . DH, DH . , - KDF-, : . , . — : , . — KDF-.
, , , , .
, , . , . , . HTTPS , , .
. . , . . , . , . — .
, ?
Under the cut - decoding and part of the slide.
- The real situation is as follows: a collision between two random samples of 256 bits in length will reach a probability of ½ at about 4 billion samples. So, if we consider a stream of blocks with a length of 64 random bits, then with probability ½ among 2 32 such blocks there will be two identical ones.
')
What is the practical value of this scientific fact? The output of the encryption function can be viewed as a random number, and the ideal encryption function is indistinguishable from a random number. So, if we consider blocks encrypted, for example, by DES or GOST-28147, then taking 2 32 such blocks, we will, with probability ½, find out that two of them are encrypted in the same way.
Let's think someone counts: 2 32 blocks of 64 bits or 8 bytes - how much? 32 gigabytes? It looks like the truth. Now we divide 32 gigabytes into 10 gigabits. If we have an encryption algorithm with 64-bit blocks, then a little later than after 32 seconds, we will see a collision. We will see two blocks that are encrypted in the same way. As found out in the SVS, these two blocks do not have to be with the same plaintext. Plain text may be different.
What will it mean? If we have some C i block, then what was encrypted in CBC mode?
Let's say we watched a collision after 30 seconds. The two parts are equal. Encryption is one-to-one. Thus, since the encryption functions are equal, then the encoding is also equal.
C j-1 and C i-1 - we saw them, because they had just been transmitted in the communication channel.
In other words, if we have such a small block size, then even with absolutely strong encryption, after some time we will begin to get differences between some two random open texts. This property is not necessarily transformed into a real attack, but in practice it is not very good. Because of him, the CBC mode is the cause of many ills.
The last of these troubles is the attack (indiscernible - ed.), Published just a couple of weeks ago. It is extreme, but, I think, not the last in this series. And all because of the unfortunate properties of the CBC, which I described.
However, CBC is still a widespread encryption mode. It can be found anywhere.
- If you need to take the last 10 bits, we will have to count sequentially ...
- Yes, of course, the CBC has a problem: to decrypt 1 gigabyte and read the last 10 bytes in it, you must first generate it all.
Despite all the difficulties with CBC, it is still the most common encryption mode: TLS is accurate, but I think that in IPsec, that is, in real-life protocols.
How to deal with this in real life? First and foremost, Triple DES is no longer widely used. Further, if you look at AES with a block size of 128 bits, then the probability of a ½ collision occurs after about 2 64 blocks, and this is a lot of traffic. Therefore, in real life, the likelihood that we stumble upon a collision is low. So do not use Triple DES and GOST-28147, if you are not a government organization and do not have to use them.
CBC is not the only encryption mode. There are still CFB. He, if you look closely, is very different from the CBC. We take the initialization vector, copy the plaintext with it and get the ciphertext. We encrypt the result again, we repeat the plaintext with it, we get the second block of text, etc.
Why did I even talk about CFB? Because, unlike CBC, the CFB variant is standardized for GOST. If you look closely, in this sense it is no better than CBC - it has the same problem. In closed systems, you can meet with the specified implementation, with it, in principle, some problems arise.
What other problems do these algorithms have? To decrypt every next block, we need encrypted plaintext. Without an accessible plaintext block, we cannot generate the next encryption block. In order to get rid of this problem, OFB mode was invented, which is arranged like this: an initialized vector is given, it is encrypted with a key, the result is encrypted with a key again, again ... In fact, we take and encrypt the initialization vector many times - as many blocks as we need.
We add the blocks with clear text. Why is this convenient? If you look closely, block encryption mode becomes streaming. If there is little traffic now and the processor is free, we can generate several blocks ahead of time and then use them up with a possible surge in traffic. Very comfortably. And we do not need the knowledge of plaintext to encrypt the next block. You can type and keep a few gigabytes in memory - in case you need it.
All the flaws of stream ciphers are also present here.
A slightly different encryption method is the so-called counter mode or CTR. It is arranged simply: we take a certain random number, we place it at the beginning of the block, and at the end we simply put the counter from zero to as many as you like. For example, up to 64 bits. We take and divide in half: we give the left 64 bits to a random number, and the right 64 bits to the counter.
Encrypt each such number and reduce the result with clear text.
What is convenient CTR? It allows us to encrypt the 125th block without encrypting the previous 124 blocks, that is, solves the problem of decrypting the last 16 bytes from a 10-gigabyte file. It is quite convenient in all other senses. If we talk about a surge in traffic, you can generate blocks for encryption ahead of time.
This is the case with messages longer than one block. And what if they are shorter than one block? In other words, we want to encrypt not 16, but 8 bytes.
- Finish to 16.
- But as? Suppose we deciphered a block, at the end of which has four zeros. How do we know that these four zeros are finished by us, and not a fragment of our blocks?
- Before transmitting the encrypted message, report the length in bytes.
- A convenient way, but it is inconvenient because you don’t always know the size before the transfer. If email - you know, and if not?
After the transfer? Okay, maybe you can. And where is there to look for differences? It is necessary to store in a separate place. The question is which one?
- Not within the scope of encryption.
- If not within the scope of encryption to transmit the length of the message, you will disclose it. I think we were hiding her.
Welcome to my personal hell, namely to the system with padding. The idea that you need to write at the end of the message how long it is is not very bad. It is only important to think of a way to complement the block, which will uniquely establish that this piece at the end is an addition, not part of the data.
There are several modes of padding, and unfortunately, the most common of them has several unpleasant properties.
We take and at the end of the last block we add each free byte to the number of free bytes. If at the end there are 3 bytes left - we take and write them: 3, 3, 3.
If the length of the message falls exactly on the border, we supplement it with another block, where we write, I think, four zeros. Not fundamentally. This encoding method is always unambiguous. We open, find out the last byte and, if it is not zero, we understand - it is necessary to count how many bytes. In fact, this is a cleverly coded message length. If the last byte is zero, we can discard the entire block. And we know that a full block can never end with zero: then we would complement it with another completely zero block.
If the last block ends with a unit, then it is complete and we will definitely supplement it with one more block.
It would seem normal. Before us is the working mechanism of padding.
Suppose we are attacking. We have an Oracle system - it is so called in cryptography. This is not the Oracle that makes the database. This is a box whose device you do not know, but in this case it is an encryption or decryption algorithm. You do not know which key is inside, although it gives you some kind of answer. However, it will definitely not give you an answer on whether the line you put in it was correctly or incorrectly deciphered.
So, you have the specified box. In this case, you saw one message and know for sure that it was decoded normally. Oddly enough, in real systems such a message is easy to get.
Then you take the message and send it to the box, changing in it one last byte. A box can return two states to you. Either you learn that your construction was somehow well deciphered, or - that it was not deciphered due to a padding error.
How does everything work? Your program code is trying to decrypt something, decrypts and further checks the padding at the end. If the padding does not meet the standard, you see "333" or something is wrong, not the entire last block is zero, then it will tell you: "padding error". At the expense of such a scheme you can sort out the last bytes of the last block in a rather simple way. For example, if you use the unfortunate mode of CBC, then, having disassembled a piece of plain-text, you can understand what was there.
It would seem that everything looks pretty harmless. But in practice, the problem with padding oracle attacks, for example, led to the remote execution of malicious code in Windows 2003 sometime in 2008.
Why it happens? We are trying to decipher something without verifying that the incoming message was really sent by the one from whom we are waiting for something.
Welcome to authentication. Everything we talked about just ensured the confidentiality of the message. Using encryption, we send the message and we can be sure that no one except the recipient will read it. But when the recipient receives the message, how can he verify that the message was actually received from the sender? For such a test, there is a separate set of message authentication protocols. In English, this is called a MAC - message authentication code.
What are the problems here? There is a problem with streaming encryption algorithms. Suppose there is a message about which we know nothing. There is a gamma that is somehow generated. Ciphertext is obtained. Suppose the cipher is absolutely strong and everything is fine with it. But imagine that the attacker took and changed some bit in the message that we receive. Will we detect an error? Obviously not.
If he changed the zero bit to one, he unpredictably changed the plaintext. If he changed the unit to zero in the ciphertext and in the original message there was also zero in this place, it will change to one. If we "flip" a bit in ciphertext, it flips in cleartext. And this problem cannot be detected by means of a single encryption algorithm.
It is clear that in the block cipher there will be more problems, that they will accumulate and that you will surely encounter the problem of padding, but in general, this problem is still there. Encryption alone does not provide message authentication. Need a separate mechanism.
The mechanism is called MAS. How does he work?
We take the message and pass through a special function called the MAC algorithm. At the input, the MAC algorithm receives not only a message, but also a key that is different from the encryption key.
When we want to send a message, we attach the result of the algorithm to it. The recipient takes the message, performs the same operation and compares the MAS, which he calculated, with the MAS, which he received. If they match, then the message has not been changed in the process. And if the two IASs did not match, then a problem happened along the way.
What can be used as a MAC function? You can use the number of units, but it seems that such a scheme is easily forged.
The hash function is the obvious answer. And more?
For a long time, SAF MAS were distributed. We take a construction in which there is no initialization vector, and everything else is the same. We take a ciphertext - we encrypt, we “crawl”, we cipher, we “crawl” ... It turns out the last block, where all the information about our text is accumulated. Very comfortably.
But it is also quite true that you can use any cryptographic hash as an element of the MAS. There are several cryptographic hashes, the most common of which is MD5, the SHA family, GOST 34.11 ... and the competition for SHA-3 recently ended, in which Keccak won.
Hashs are more complex than encryption algorithms, but in its principle the idea of building a hash function is similar to the block encryption algorithm. In other words, we take some kind of data block and consistently, several times apply to it a set of fairly primitive operations. If you look at MD5, then there is only addition modulo 2 and cyclic shifts. We use them many times - as a rule, much more than in the case of block encryption algorithms. If there is a text along the way, from which we need to take a function longer than one block, then we follow them using a method a little bit similar to CBC. We add these fragments to our calculated function.
The result of the hash calculation is numbers. The length of the number is always fixed. Typical hash output sizes for MD5 are 128 bits, for SHA-1 - 168 bits, for SHA-256 - 256 bits, for SHA-384 - 384 bits, and for SHA-512 - 512 bits.
What else is important to say about hashes? With small changes in the input, the hash is required to provide large changes in the output. So, if we changed one bit in the plaintext at the input, then ideally the hash, the result of the calculation of the hash function, should change exactly by half.
Now in actual practice it is recommended to use SHA-2, and specifically SHA-256 or SHA-384 - depending on your needs. MD4 is broken for a long time, MD5 - in principle, also broken: just yesterday, a new attack on MD5 was published, where the guys use Sony PlayStation to generate collisions coolly. We can assume that the use of MD5 is no longer necessary. In real life, always use SHA-2.
Where else besides authentication, hash functions are used? In the key generation protocol, for example in PBKDF2. Suppose you need to encrypt a file. You take the user and, as a rule, ask for the password with which you need to encrypt the file. In a real-life situation, the user enters something like a sequence from 1 to 5 as a password, and his work will be completed.
On the one hand, you want your encryption key to be not as predictable as “12345”, and that the distribution of bits is more uniform. On the other hand, if an attacker begins to sort through all possible passwords, each brute-force attack should take as much time as possible. The indicated class of KDF-functions is aimed at exactly that.
PBKDF2 is a specific function from the class of key generation functions. It is arranged very simply. It only does that it applies a hash algorithm several tens of thousands of times. And along the way - at each stage - it mixes up additional data so that it is rather difficult to calculate it in advance.
Since the hash function has been running for quite a long time, performing hash functions several thousand times takes even longer. In other words, we are protected in a convenient way from an attacker who tries to sort out several common passwords.
In real life, when the KDF function is used, it is recommended to choose the number of iterations so that it is, on the one hand, acceptable to an impatient user, and on the other, unacceptable to an attacker who wants to pick up several million keys. In real life, select such a number of iterations in KDF, so that, for example, it is executed in one second. For an attacker, one second is an absolutely indecent time, while the user, pressing the button and waiting for the password to be verified, is quite capable of waiting for one second.
Storing passwords is the same use of hashes. Anton in the story about UNIX will definitely tell about it.
Since we have padding oracle and similar attacks, when we generate a message, there are two options.
There is a crypto-primitive type of MAS, and there is a crypto-primitive for encryption. We want to send a message and authenticate it. There are two ways. We can encrypt the message, then take the MAC from this thing and attach it to the message. Entirely it will look like this: E (T) || MAC (E (T)).
The second way is the following: we take the message, encrypt it and take the MAC from the plaintext. Because why do we need an extra operation?
In fact, one is called MAC before encrypt, and the second is encrypt before MAC.
The question is - which is better? Equally? Okay, more versions?
There is another great way - they say, let's encrypt the MAS so that no knowledge about the plaintext is leaking.
Indeed, there is a problem with this method: if you encrypt a message with it, there will be a risk of encountering a padding oracle attack. Padding oracle doesn't care if you have MAC at the end or some other data. You will have a box that first tries to decrypt the message. If due to improper padding, it does not decrypt, the box will not even check the MAC, and will immediately respond to the attacker or someone else that "I could not decipher this thing." Enough unpleasant. Therefore, here is a general recommendation for the design of such systems - if you do not know what you are doing, it is better to use such a thing, and if you know, this one: E (T) || MAC (E (T)).
Just six months ago, Anton and I discussed about one place, and I insisted on using the second design. I thought I knew what I was doing. And I still think that I knew what I was doing, because there was no padding oracle.
We are able to encrypt our message, we are able to verify that the received message really came from the sender. : A B , .
, , , , , . - KDF- : , . .
? — . — . — . 100 , . , 100 , — .
, , , .
— .
?
k 1 k 2 , . k 1 , k 2 . , .
: k 1 k 2 , , , . , .
, , . , , - .
, , , , P = NP. . RSA, , . .
, , . - (DH). , , .
. P G. .
a . .
- , B . G P . , G P . .
What happens next? . , , , b. : a = A b . .
, , , . It turned out very convenient.
, , , , — 0.
, , — RSA.
. — 1024 . 2048, 4096 8192: , .
— .
(n-1)(p-1). — , .
, : , . - . .
— . , .
, d — . . , , . RSA.
, , . , k, , k — .
, - , - , n. . , , .
-, d.
de = 1 n, , M ed mod n, , M 1 n. . M 1 = M.
RSA, ? , k 1 k 2 , , — . — , d — . , , , , , . : M e , d, M d , .
RSA, ?
, - . XOR , . , , . . — , , .
. , , . RSA , — . . : - , - , , -.
RSA 1024, 2048, 4096 — . AES, DES Salsa : 256, 128 64 DES.
, — RSA-2048 AES-256? RSA , , AES 2 256 , RSA — . , . 2 2048 .
, , - - . , . , , . , .
- , . , 2014 AES 78-80 . , RSA, 1300-1400 . keylength.com , . — 160-170 . SHA1 2014 , — 168 .
- , , .
. , , , .
. : . : . , .
. , email. , ?
— , 128 . ? , . .
, .
, , , .
.
. . , , - . , .
.
128- , . 128- , , . , . . .
? , . , . , , … - ?
, . . ?
, , … , . padding oracle, , , .
? , , , . , . , , — , .
, , . : , , . -, — . -, , .
? , , .
. , , S/MIME PGP. , , , .
, . , . , , . , . ? What is the difference?
: , DH , , . .
, DH, , , .
DH (. man-in-the-middle MITM — . .). , , , . , , - , , , , - . DH- — . , , .
What to do? , .
— , — …
— ? ?
— …
— ? .
— , .
— . , ?
— … .
— ? , DH : , , .
— DH- MITM?
- Not. , DH-? , DH- . MITM , ? I do not believe.
, ? Signature. , A . Everything. .
? , . , . — , -, , , -, , .
: , , , . . DH.
, . , -. , , .
, . . - DH-, , ?
? , . . ? . - ? , . .
, - . . . : , , , , — . . , , MD5 SHA, . , - . HMAC. , .
, , . , , . C 1 . , C 2 , , .
. , . DH, DH . , - KDF-, : . , . — : , . — KDF-.
, , , , .
, , . , . , . HTTPS , , .
. . , . . , . , . — .
, ?
Source: https://habr.com/ru/post/327636/
All Articles