From Oracle to PostgreSQL - a 4-year path, a report by Andrei Rynkevich
2017 was a significant event for PG Day - we transformed our event into the largest database conference.
We do not change our traditions and are preparing a rich and interesting program dedicated to the World. Nevertheless, communication with colleagues and feedback from the participants make it clear that a huge number of specialists are engaged in the operation of several data storage systems, either by force or by their own decision. We do not want to deprive colleagues of the opportunity to communicate with each other, share experiences and find ways to solve their problems. That is why, in 2017, PG Day is divided into 5 parallel threads in various areas: PostgreSQL , MySQL , Oracle , MS SQL Server , NoSQL solutions and other free and commercial DBMS.
Despite the fact that radical changes in the structure of the GHG of the Day began only this year, interest in our event from the workshops in the workshop began to appear much earlier. At one of the past PG Day, Andrei Rynkevich presented an interesting report from Oracle to PostgreSQL - a 4-year-long path based on the experience of migration at Phorm , the decoding of which we are pleased to present to Habr readers.
')
The report “From Oracle to PostgreSQL - a path that is 4 years long” about the biggest challenge in our project, which should be completed in the next month with the installation of products fully working on PostgreSQL on “production”.

At the very beginning we had Oracle and practically no user activity. In such conditions, it doesn’t matter what technology you use. No matter how well you write requests, everything works perfectly. But analysts come to your aid.
So a special kind of statistics appeared, the keys in which, even with our weak loads, completely hammered the disc to the eye: it was about 5 TB . Of course, we turned off the statistics, but for the first time we began to think about an additional database for expansion. The load grew, but our optimization capabilities were limited to the Oracle license. The current license allows you to use only 4 cores, with such a restriction we cannot even use standby for requests, we do not have partitioning - you cannot go far on such a train. Therefore, we began to look for options for expansion.

At the beginning we looked at the possibilities of Oracle. The current license cost us £ 15,000 per year (support plus upgrade for new versions). The removal of licensing restrictions on processors and documents for partitioning added quite a significant contribution to this amount, so we did not go this route, since there was not much money.
The first solution we looked at was MySQL. At that time, MySQL was already used in our projects, but after talking with people, we realized that it showed itself to be quite problematic and with limited functionality. Therefore, quite a bit of a look at the NoSQL solution. We did not have developers for NoSQL at that time, and this seemed to us a very radical change, so we also set it aside.
The most suitable solution for us was Greenplum - this is an MPP database built on the basis of PostgreSQL. Of course, the only negative is that it was also paid, but the amounts are no longer the same as those of Oracle, so we decided to stop at PostgreSQL with the goal of further migrating to Greenplum. According to the plan, such a migration should not be too difficult.

To begin with, we bought two hosts: master + standby (24 cores, 128 GB RAM), built a three-byte (3 TB) RAID10 - these are not SSD drives, because SSDs were very expensive at that time. And they thought about what to do next.
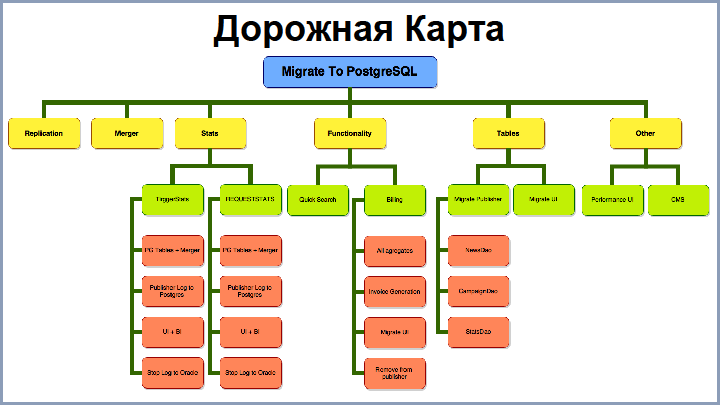
I confess that at the very beginning we did not have a clear, detailed understanding of all the steps of the migration. At some point, we still had to draw a road map of how we move. On the screen, you see a very curtailed version of this roadmap. From the stages we can distinguish the following:
Further - consistently about each stage.
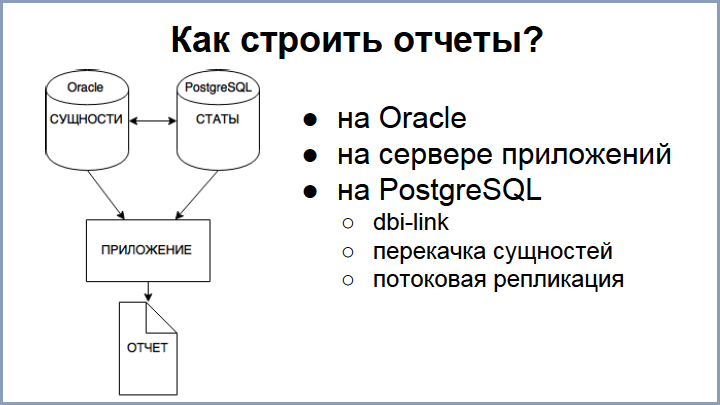
At the very beginning, we already understood that we would not have the opportunity to migrate in one sitting, so we decided to start with statistics. And there was such a moment that some statistics are partially located on PostgreSQL, and the rest is on Oracle (mostly entities). The problem is that reports require both. Question: how are we going to build reports?
We dismissed the option on Oracle right away, because we still have limited opportunities there. It is possible to set up an application service, extort entities from Oracle, and statistics from PostgreSQL, somehow connecting and filtering. Such an application does the work for the database. This approach seemed to us very difficult, so we further implemented three approaches, which we use in different degrees.
The first option is to extort necessary entities from Oracle using a DBI link when requesting a report in PostgreSQL, this approach is working and is well applicable for small samples, because when you need to pump large data with a large number of entities, everything slows down dramatically, plus requests is very complicated. This approach is relevant when the relevance of entities is needed: you go to the “edit” page, add a new element and, when saved, you should immediately display it with new statistics.
The next option is to completely transfer all entities from Oracle to PostgreSQL, periodically transfer all entities. We also use this approach, but the fact is that the number of entities occupies about 100 GB in us, therefore the actuality of the entity in the postgrese is lagging behind. But this option works well when you need to handle large reports that do not require data relevance. But, knowing our operators, who come to us in half an hour, as soon as some kind of statistics begins to fall behind, we decided to implement streaming replication : when updating to Oracle, the entity almost immediately falls into Postgres.
To address this issue, the following options were considered:
WisdomForce Database Sync is a commercial product that existed at the time. He was quite happy with us and the speed was about 5,000 updates per second, but at that moment when we decided to use it, another company bought it, and the project disappeared from the market, so we had to figure it out and build solutions ourselves.
The first option that was considered is Oracle DataChange Capture . These are Java processes that run in an Oracle database. They know how to catch changes to the plates and stuff them in the queue. Unfortunately, the speed of this decision was lost in history, but it was not very high.
The first replication option was built on the Materialized View Logs - these are special Oracle tablets that store all changes to the master tablets and are used for quick recalculation to the Materialized View.
This solution turned out to be quite simple to implement and gave a speed of about 500 updates per second, but the product grew and this was not enough. Then we switched to a special Oracle technology Stream , which is used to replicate data from Oracle to other sources. The current speed also allows you to pump and update entities at a speed of 5000 updates per second (up to 50,000 could be reached), while the average delay takes up to 30 seconds. And what is interesting is that even if you updated one record in Oracle, it gets into the Stream not immediately, but with some delay, because there is some latency in all these processes.
Oracle also has a continuation of stream technology - XStreams, which allows you to get better results, but this solution is paid for them, so we tested it, but did not use it.

The replication scheme is quite simple . Now, Oracle has processes that read redo logs - this is an analogue of WAL files in PostgreSQL. All labels that need to be replicated are recorded in a separate “Replication data” label. With the help of intermediate software, redo-logs are hung on each table. As a result, at the output, we get data that also forms our “Replication Data” label.
On the PostgreSQL side, we have built a replication application / utility in Java - it reads this data from Replication Data and writes it to PostgreSQL. The advantage is that, if it is possible to read and write data transactionally, there is no violation of integrity.
As for the speed of 5000 per second - basically, the narrow link in this place is the replication utility. Stream-processes, as I said, allow you to keep up to 50,000 sorts / updates. To speed up the utility, we split it into 3 threads :

Stream processes allow not only replicating data, but also DDL. We first rushed to solve this problem. Fortunately, the system is complex, and I wanted to minimize all manual twitching, but this was not easy, because the DDL language itself is diverse. Plus, there is a moment of ambiguity in translating DDL from Oracle to PostgreSQL. It happened so that often in our production we got out unregistered versions of this DDL. As a result, we decided that it would be easier for us to recreate them in the postgres and reload the data. As a result, we left one instruction that we support - this is TRUNCATE.

The speed of 5000 updates per second, in most cases, is acceptable, but there is one moment when it was not enough. This is exactly patching a large amount of data in Oracle. So, there were cases when the update affected tens of gigabytes. Stream processes are quite heavy, because to drive all these volumes through them is quite expensive for the server. Therefore, we came up with such a scheme.
If a database developer understands that his patch will affect a large number of changes, he sets a certain flag in the patch system that he needs to stop replication. By applying this patch, the patch system stopped streaming processes, did its own business with tablets, and at the very end wrote a marker on our replication table indicating that the patch was over and the flag that the tablets needed to be initialized. Further the system of a patch started postgres. She waited for this last marker, written in Oracle, already at Postgres, which passed through replication. He always came last. The system looked at the flag and, if it was necessary to recreate the labels, it recreated them and extorted all the entities from Oracle using a DBI link. And then she did the patching of the system itself. On it with replication everything.

The next step is to load data into the database itself. In fact, our project is divided into several: in fact, the database itself; UI, which fills in the base of the entity and issues reports; server logs, which daily pumps through the base 150 GB, using stored procedures.
Since database developers do not really control the log-server-database link, there are many problems. For example, statistics come from different countries, at different times and in different volumes, which periodically gives rise to load jumps. It is clear that this affects all users. The next problem, sometimes unexpected: the log server gives out too large data packets. Again, the processing of such packs takes up a lot of resources from the server and affects all other processes. In addition, there is still a difficulty in handling failed patches for statistics.
If something “zafeilosya”, these statistics remain on the log server. The database developer needs to somehow get there (and this is not always possible), convert the stored procedure (in plan, call, fix, re-fill). This is quite a difficult decision. Therefore, on the postgres side, we went a little differently, namely, we upload files, i.e. the log server no longer calls the stored procedure, but issues csv files.

There is a Merger program, which, according to certain rules, each type of statistics is uploaded to the database. All the files were located on the same host, it solved all previous problems, i.e. load jumps affected only the number of unprocessed files on the disk. The filed files could always be found, fixed right there with their hands, put back and loaded. Also, Merger broke large bundles apart, so there were no very long transactions.

Merger also went a long way.
The first version was made on the knee and looks like this green line. This is his decision. That is, for each type of statistics, the “staging” label and the procedure that placed these labels in the database were created. But this option is not suitable for all solutions, so we wanted to come to something simpler, more universal. So we have the second option.
On the screen you see the very first and simplest rule for processing statistics. The program by the name of the file understood which rule to take, the same rule corresponded to a label in the database. Primary keys were selected from this label, and already for these primary keys for each row it was already possible to understand whether INSERT or UPDATE should be done.
Such rules describe most types of statistics, but there are still many options. Therefore, the Merger syntax is growing and growing. So, there are rules for INSERT, UPDATE, setting conditions, when you need to do this or another partitioning, flooding with any other perverted ways. But it’s possible to single out the following. It so happens that statistics comes earlier than entities in PostgreSQL. This happens, for example, when the replication itself “fell” or did not work for some time.

To solve this problem, we also created a cunning scheme. In Oracle, there is a label , HEART_BEAT is called, and the job, which inserts a timestamp into it every 30 seconds. This label is replicated to the PostgreSQL database, and Merger can already understand what is required. He watches the last heartbeat arriving and processes only those files that are younger than this heartbeat, otherwise we may lose some data. It is clear that if there is no entity, but it is already in the statistics, then it will disappear when merj.

Having replication and Merger, we could go on to transfer statistics. On the slide you can see a slightly modified and truncated version of this process. From the stages we can distinguish the following:
For some reason, we had a fear to move everything else at once. Therefore, at each stage we tried to somehow keep with the possibility of going back if something goes wrong. If double logging remained on the production for some time, then we started translating both the UI and the reports.
Here we also realized our fear of transition, and therefore there could be two identical reports in the system at once, one of which worked on Oracle and the other on PostgreSQL. This turned out to be quite convenient for both developers and testers: you could always run the same queries, see the results and visually compare them, solve the problems found.

The more statistics appeared in PostgreSQL, the more often new cases appeared. So, for example, according to statistics in PostgreSQL, at some point we needed to update the entities already in Oracle. For example, when passing certain threshold values, it was necessary to change the status. In this case, on the postgres side, we got some job that maximally aggregated the necessary statistics and stuffed it into Oracle via dbi link. There - already through a stored procedure or in a separate table, which was processed by the corresponding job in Oracle. Then the data, statuses and entities changed in Oracle and through replication came to PostgreSQL.

Guess what it is? This is a collection of entities . I drove all entities into Modeler, and he built all the connections between them. As you can see, the grid is quite dense, not everything even got into the screen. Therefore, the same trick with the statistics: we didn’t manage to transfer everything in parts, because the connections are rather dense. In addition, in the UI, the ORM system works with us, and it is quite difficult to break the links there. In fact, you have to implement two-phase commit to different databases. Running two variants into the same ORM was also problematic for the model. Therefore, we decided to postpone the entire migration of the entities to the last spurt, while at the same time preparing all the necessary moments.
For one of the plates, we still had to implement the transfer, break the connection, it took quite a long time. The reason is that this tablet is very large and it has changed intensively. It was expensive for initialization in the postgrese (the need to pump all the entities) and for the replication process.
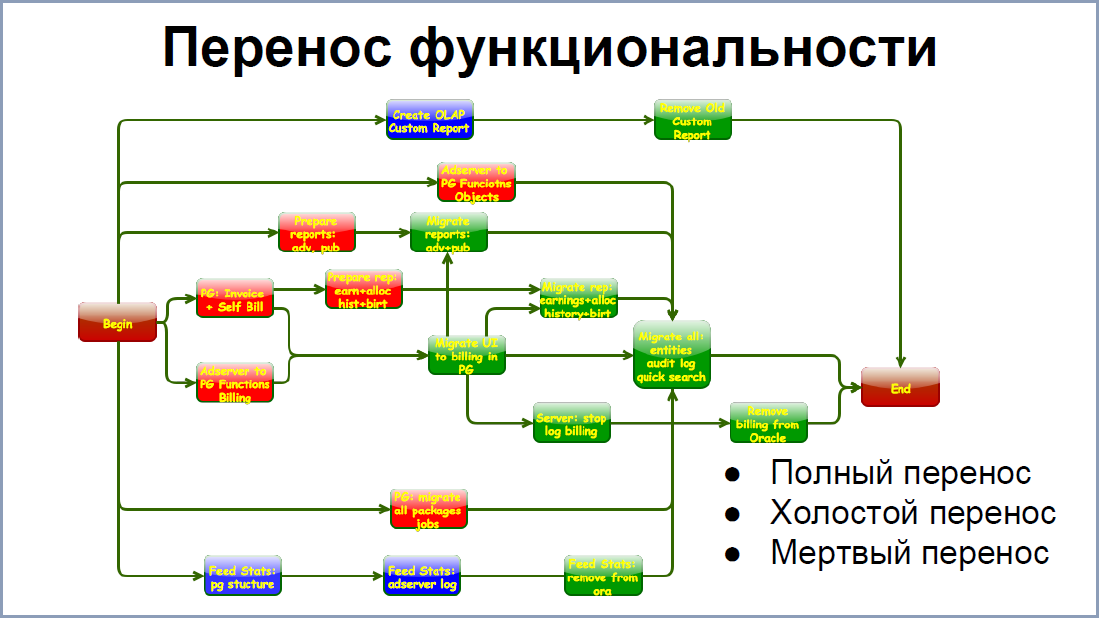
With the transfer of functionality was a little easier. On the screen, you can see some interrelation of the stages of transition of some part of the system from Oracle to PostgreSQL. There are, of course, fewer connections, but each square consists of small squares, which has its own connections. Therefore, in order to facilitate the last spurt, we have maximally simplified everything we can. You can select three options .
Full transfer of functionality when we completely removed it from Oracle and started on postgrese. In some cases this was possible.
In most cases, we transferred the functionality and ran it idle . For example, billing has worked in this mode for about a year, allowing us to find many performance problems and a number of critical bugs.But the results of such a billing, of course, were thrown into the trash.
Dead transfer is a transfer of the stored procedures, rewriting them from Oracle to postgres. These procedures might not even work. And, often, they did not work, they were not called. But this allowed us to create a set of "blanks" to the next step.

Actually, having prepared everything to go to the last spurt, we overcame it with this last spurt. In fact, we moved all the statistics, included the functionality that was idling and which was lying dead weight. The release itself took place with a rather large “downtime”, since you need to transfer a fairly large amount of relevant data and perform some migrations point by point. It is interesting that, despite the fact that we did a lot of things, we found that we forgot to transfer certain modules, so we had to postpone the release for about a week. And even after that, somewhere in a week or two, we found another module that had not been migrated, and we already had to finish it live.

So 4 years- this is quite a long time. To understand whether this value is justified or not, we wrote out a number of metrics, some of which you see on the slide. Probably, each of you was mistaken in the initial assessment of the volume of this or that work. This mistake was made by us. Initially, our assessment was a year and a half. And even now, when everything is completed, few people call the number for more than two years, because it all merged into a continuous stream.
As you can see, the base is not very big, but not very small either. If you take the code, to write a number with 0, you need to write about 80 lines per day . It’s not so much even for a small team.
The greatest time was taken to study and compare different solutions. Of the other points that are not technical, there are several. As you can see, the transfer involved about 30 people who worked in different teams, in different places. And the coordination of such a national team has required quite a long time.
One of the moments was the loss of focus.. I thought for a long time what it was until I encountered this with my own eyes. The fact is that we acted proactively and we didn’t have such big problems on Oracle in most cases, so all the migration tasks went a bit in the background. And, since there were quite a lot of short-term tasks, this strategic direction was slightly moved to the background. There were cases when we forgot about migration for a week or two.

Despite the fact that PostgreSQL is a pretty cool database and with each release we like it more and more, we still lacked some moments during the migration.
Joba , in Oracle, they exist in the database itself and it was unusual to go beyond the framework, run some crontab. In addition, you need to monitor all this, that it all starts and runs well.
Resource management : sometimes it is good to divide resources between processes, for example, between user requests and statistics.
The coolest thing in Oracle, in my opinion, because it saved me several times, is flashback. This is an opportunity to restore some version in a short period of time. We are thinking of something like this, we are thinking of realizing it as a postgres, since there were moments when we had to restore large chunks of entities due to incidents.
Also OEM (Oracle Enterprise Management)- this is a web application. When we have these or other problems, DBA climbs into this OEM, sees all the activities there are. You can go through the stories, see what happened, compare the interaction of various aspects and do all your admins. In PostgreSQL, of course, DBA has skill at the tips of the fingers, so it can issue all requests with the same speed as through this application, but the convenience suffers for people who are not DBA. Therefore, we still wrote our own version of the OEM, it was important to preserve the entire history of requests for tables and queries. In the end, we could go in and see what was slowing down there, see all the interrelations and make changes in our code.

Greenplumwe still did not buy, the crisis, but the volumes are growing, so we are faced with the same problems that we already had Oracle, on PostgreSQL, but on a larger scale. So, the first of the problems we have encountered is disk restriction . At some point, we even had to do an un-raid operation on several sections. Having thus turned RAID-10 into RAID-5, it seems.
The main problem of this operation is that the data stored on these sections are lost, so we had to play the tags on the disk to fit everything. Upon request, we also have problems, we stick to some of the limitations in processing, to the extent that we even have to disable some of the functionality. And some volumetric statistics that require a lot of space and processing, we even carried out the postgres to a separate place and develop all this direction in a special way, because the further, the worse.
New version watched? We watched and watched, but we transferred the main statistics to Hadoop, for short. On hadupe we are faced Impala, such a column, in fact, a database that is responsible for our data. And we even have a strategic task to bring all the volume statistics that are not needed for billing, or for the work of momentary jobs, in the Hadoop cluster and, if we need something, then return it once.
So, our operators love to watch hourly statistics. The volume of keys in the main event table is very large and it is expensive for the server, so we have already taken out the hourly statistics to Hadoop .

The thematic expansion of PG Day'17 increased the interest of our listeners and speakers in the subject of migrations from one data warehouse to another. Migration issues will be considered in almost every section.so no questions will be left! Especially for you we are preparing to present some interesting reports.
Vasily Sozykin from Yandex.Money tells you about the migration of a loaded service from Oracle to PotgreSQL , a fascinating story about how Yandex specialists migrated a truly huge base without downtime. Alexander Korotkov from Postgres Professional in his report “ Our Response to Uber ” will analyze the sensational story about the relocation of the popular Taxi service from PostgreSQL back to MySQL. Kristina Kucherova from Distillery will tell you how she and her colleagues came to a decision aboutOLTP migration of a part of their system from MS SQL to PostgreSQL , and how it turned out for them.
Well, the fourth, no less intriguing, report on online data replication in Greenplum of 25 DBMSs running Oracle is prepared for you by Dmitry Pavlov , the head of the Date Warehouse administration team at Tinkoff Bank. Dmitry is not the first time speaking at PG Day. His previous reports were a resounding success and were packed to capacity.
At the very last moment, when we were preparing this issue for publication and were already ready to press the “ Publish ”button, colleagues from the research institute “Voskhod” applied for a report. Dmitry Pogibenko will tell aboutsuccessful migration of the state system Mir database (more than 10 TB of data!) from DB2 to PostgreSQL with minimal downtime.
Preparing for your own migration? Have you had a successful transition from one repository to another and are you eager to share your experience? Be sure to come to us at PG Day, buy tickets at spring prices, apply for reports, deadline soon!
See you in summer in St. Petersburg!
We do not change our traditions and are preparing a rich and interesting program dedicated to the World. Nevertheless, communication with colleagues and feedback from the participants make it clear that a huge number of specialists are engaged in the operation of several data storage systems, either by force or by their own decision. We do not want to deprive colleagues of the opportunity to communicate with each other, share experiences and find ways to solve their problems. That is why, in 2017, PG Day is divided into 5 parallel threads in various areas: PostgreSQL , MySQL , Oracle , MS SQL Server , NoSQL solutions and other free and commercial DBMS.
Despite the fact that radical changes in the structure of the GHG of the Day began only this year, interest in our event from the workshops in the workshop began to appear much earlier. At one of the past PG Day, Andrei Rynkevich presented an interesting report from Oracle to PostgreSQL - a 4-year-long path based on the experience of migration at Phorm , the decoding of which we are pleased to present to Habr readers.
')
The report “From Oracle to PostgreSQL - a path that is 4 years long” about the biggest challenge in our project, which should be completed in the next month with the installation of products fully working on PostgreSQL on “production”.
At the very beginning we had Oracle and practically no user activity. In such conditions, it doesn’t matter what technology you use. No matter how well you write requests, everything works perfectly. But analysts come to your aid.
So a special kind of statistics appeared, the keys in which, even with our weak loads, completely hammered the disc to the eye: it was about 5 TB . Of course, we turned off the statistics, but for the first time we began to think about an additional database for expansion. The load grew, but our optimization capabilities were limited to the Oracle license. The current license allows you to use only 4 cores, with such a restriction we cannot even use standby for requests, we do not have partitioning - you cannot go far on such a train. Therefore, we began to look for options for expansion.
At the beginning we looked at the possibilities of Oracle. The current license cost us £ 15,000 per year (support plus upgrade for new versions). The removal of licensing restrictions on processors and documents for partitioning added quite a significant contribution to this amount, so we did not go this route, since there was not much money.
The first solution we looked at was MySQL. At that time, MySQL was already used in our projects, but after talking with people, we realized that it showed itself to be quite problematic and with limited functionality. Therefore, quite a bit of a look at the NoSQL solution. We did not have developers for NoSQL at that time, and this seemed to us a very radical change, so we also set it aside.
The most suitable solution for us was Greenplum - this is an MPP database built on the basis of PostgreSQL. Of course, the only negative is that it was also paid, but the amounts are no longer the same as those of Oracle, so we decided to stop at PostgreSQL with the goal of further migrating to Greenplum. According to the plan, such a migration should not be too difficult.
To begin with, we bought two hosts: master + standby (24 cores, 128 GB RAM), built a three-byte (3 TB) RAID10 - these are not SSD drives, because SSDs were very expensive at that time. And they thought about what to do next.
I confess that at the very beginning we did not have a clear, detailed understanding of all the steps of the migration. At some point, we still had to draw a road map of how we move. On the screen, you see a very curtailed version of this roadmap. From the stages we can distinguish the following:
- replication of data from the Oracle database to the PostgreSQL database;
- Merger - as a way to fill "raw" blocks in the database itself;
- transfer statistics from Oracle to Postgres;
- transfer of functionality;
- transfer tables and related projects.
Further - consistently about each stage.
At the very beginning, we already understood that we would not have the opportunity to migrate in one sitting, so we decided to start with statistics. And there was such a moment that some statistics are partially located on PostgreSQL, and the rest is on Oracle (mostly entities). The problem is that reports require both. Question: how are we going to build reports?
We dismissed the option on Oracle right away, because we still have limited opportunities there. It is possible to set up an application service, extort entities from Oracle, and statistics from PostgreSQL, somehow connecting and filtering. Such an application does the work for the database. This approach seemed to us very difficult, so we further implemented three approaches, which we use in different degrees.
The first option is to extort necessary entities from Oracle using a DBI link when requesting a report in PostgreSQL, this approach is working and is well applicable for small samples, because when you need to pump large data with a large number of entities, everything slows down dramatically, plus requests is very complicated. This approach is relevant when the relevance of entities is needed: you go to the “edit” page, add a new element and, when saved, you should immediately display it with new statistics.
The next option is to completely transfer all entities from Oracle to PostgreSQL, periodically transfer all entities. We also use this approach, but the fact is that the number of entities occupies about 100 GB in us, therefore the actuality of the entity in the postgrese is lagging behind. But this option works well when you need to handle large reports that do not require data relevance. But, knowing our operators, who come to us in half an hour, as soon as some kind of statistics begins to fall behind, we decided to implement streaming replication : when updating to Oracle, the entity almost immediately falls into Postgres.
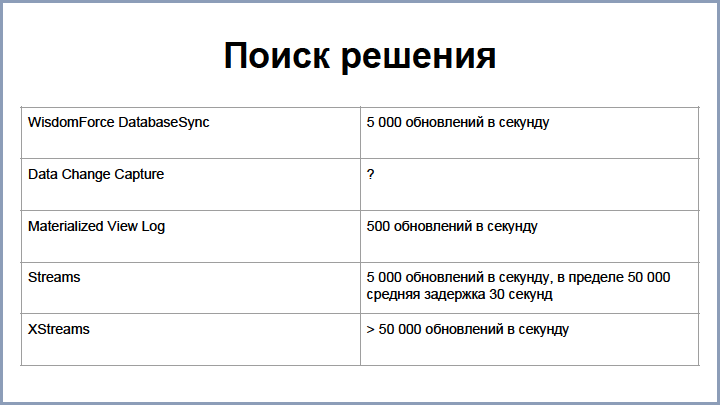
To address this issue, the following options were considered:
WisdomForce Database Sync is a commercial product that existed at the time. He was quite happy with us and the speed was about 5,000 updates per second, but at that moment when we decided to use it, another company bought it, and the project disappeared from the market, so we had to figure it out and build solutions ourselves.
The first option that was considered is Oracle DataChange Capture . These are Java processes that run in an Oracle database. They know how to catch changes to the plates and stuff them in the queue. Unfortunately, the speed of this decision was lost in history, but it was not very high.
The first replication option was built on the Materialized View Logs - these are special Oracle tablets that store all changes to the master tablets and are used for quick recalculation to the Materialized View.
This solution turned out to be quite simple to implement and gave a speed of about 500 updates per second, but the product grew and this was not enough. Then we switched to a special Oracle technology Stream , which is used to replicate data from Oracle to other sources. The current speed also allows you to pump and update entities at a speed of 5000 updates per second (up to 50,000 could be reached), while the average delay takes up to 30 seconds. And what is interesting is that even if you updated one record in Oracle, it gets into the Stream not immediately, but with some delay, because there is some latency in all these processes.
Oracle also has a continuation of stream technology - XStreams, which allows you to get better results, but this solution is paid for them, so we tested it, but did not use it.
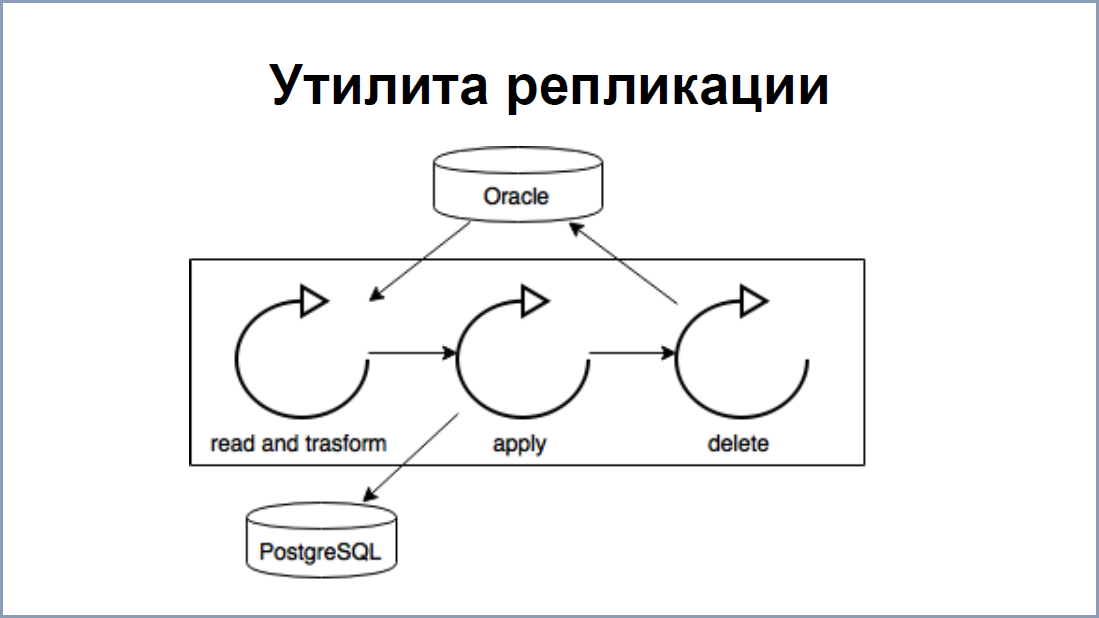
The replication scheme is quite simple . Now, Oracle has processes that read redo logs - this is an analogue of WAL files in PostgreSQL. All labels that need to be replicated are recorded in a separate “Replication data” label. With the help of intermediate software, redo-logs are hung on each table. As a result, at the output, we get data that also forms our “Replication Data” label.
On the PostgreSQL side, we have built a replication application / utility in Java - it reads this data from Replication Data and writes it to PostgreSQL. The advantage is that, if it is possible to read and write data transactionally, there is no violation of integrity.
As for the speed of 5000 per second - basically, the narrow link in this place is the replication utility. Stream-processes, as I said, allow you to keep up to 50,000 sorts / updates. To speed up the utility, we split it into 3 threads :
- The first stream read data from replication data and transformed it into queries that could be applied already on PostgreSQL.
- The second applied these changes.
- The third one cleared the processed data from the replication data table.
Stream processes allow not only replicating data, but also DDL. We first rushed to solve this problem. Fortunately, the system is complex, and I wanted to minimize all manual twitching, but this was not easy, because the DDL language itself is diverse. Plus, there is a moment of ambiguity in translating DDL from Oracle to PostgreSQL. It happened so that often in our production we got out unregistered versions of this DDL. As a result, we decided that it would be easier for us to recreate them in the postgres and reload the data. As a result, we left one instruction that we support - this is TRUNCATE.
The speed of 5000 updates per second, in most cases, is acceptable, but there is one moment when it was not enough. This is exactly patching a large amount of data in Oracle. So, there were cases when the update affected tens of gigabytes. Stream processes are quite heavy, because to drive all these volumes through them is quite expensive for the server. Therefore, we came up with such a scheme.
If a database developer understands that his patch will affect a large number of changes, he sets a certain flag in the patch system that he needs to stop replication. By applying this patch, the patch system stopped streaming processes, did its own business with tablets, and at the very end wrote a marker on our replication table indicating that the patch was over and the flag that the tablets needed to be initialized. Further the system of a patch started postgres. She waited for this last marker, written in Oracle, already at Postgres, which passed through replication. He always came last. The system looked at the flag and, if it was necessary to recreate the labels, it recreated them and extorted all the entities from Oracle using a DBI link. And then she did the patching of the system itself. On it with replication everything.
The next step is to load data into the database itself. In fact, our project is divided into several: in fact, the database itself; UI, which fills in the base of the entity and issues reports; server logs, which daily pumps through the base 150 GB, using stored procedures.
Since database developers do not really control the log-server-database link, there are many problems. For example, statistics come from different countries, at different times and in different volumes, which periodically gives rise to load jumps. It is clear that this affects all users. The next problem, sometimes unexpected: the log server gives out too large data packets. Again, the processing of such packs takes up a lot of resources from the server and affects all other processes. In addition, there is still a difficulty in handling failed patches for statistics.
If something “zafeilosya”, these statistics remain on the log server. The database developer needs to somehow get there (and this is not always possible), convert the stored procedure (in plan, call, fix, re-fill). This is quite a difficult decision. Therefore, on the postgres side, we went a little differently, namely, we upload files, i.e. the log server no longer calls the stored procedure, but issues csv files.
There is a Merger program, which, according to certain rules, each type of statistics is uploaded to the database. All the files were located on the same host, it solved all previous problems, i.e. load jumps affected only the number of unprocessed files on the disk. The filed files could always be found, fixed right there with their hands, put back and loaded. Also, Merger broke large bundles apart, so there were no very long transactions.
Merger also went a long way.
The first version was made on the knee and looks like this green line. This is his decision. That is, for each type of statistics, the “staging” label and the procedure that placed these labels in the database were created. But this option is not suitable for all solutions, so we wanted to come to something simpler, more universal. So we have the second option.
On the screen you see the very first and simplest rule for processing statistics. The program by the name of the file understood which rule to take, the same rule corresponded to a label in the database. Primary keys were selected from this label, and already for these primary keys for each row it was already possible to understand whether INSERT or UPDATE should be done.
Such rules describe most types of statistics, but there are still many options. Therefore, the Merger syntax is growing and growing. So, there are rules for INSERT, UPDATE, setting conditions, when you need to do this or another partitioning, flooding with any other perverted ways. But it’s possible to single out the following. It so happens that statistics comes earlier than entities in PostgreSQL. This happens, for example, when the replication itself “fell” or did not work for some time.
To solve this problem, we also created a cunning scheme. In Oracle, there is a label , HEART_BEAT is called, and the job, which inserts a timestamp into it every 30 seconds. This label is replicated to the PostgreSQL database, and Merger can already understand what is required. He watches the last heartbeat arriving and processes only those files that are younger than this heartbeat, otherwise we may lose some data. It is clear that if there is no entity, but it is already in the statistics, then it will disappear when merj.
Having replication and Merger, we could go on to transfer statistics. On the slide you can see a slightly modified and truncated version of this process. From the stages we can distinguish the following:
- creating labels and rules for Merger;
- transfer server logs to logging in both Oracle and PostgreSQL via csv files.
For some reason, we had a fear to move everything else at once. Therefore, at each stage we tried to somehow keep with the possibility of going back if something goes wrong. If double logging remained on the production for some time, then we started translating both the UI and the reports.
Here we also realized our fear of transition, and therefore there could be two identical reports in the system at once, one of which worked on Oracle and the other on PostgreSQL. This turned out to be quite convenient for both developers and testers: you could always run the same queries, see the results and visually compare them, solve the problems found.
The more statistics appeared in PostgreSQL, the more often new cases appeared. So, for example, according to statistics in PostgreSQL, at some point we needed to update the entities already in Oracle. For example, when passing certain threshold values, it was necessary to change the status. In this case, on the postgres side, we got some job that maximally aggregated the necessary statistics and stuffed it into Oracle via dbi link. There - already through a stored procedure or in a separate table, which was processed by the corresponding job in Oracle. Then the data, statuses and entities changed in Oracle and through replication came to PostgreSQL.
Guess what it is? This is a collection of entities . I drove all entities into Modeler, and he built all the connections between them. As you can see, the grid is quite dense, not everything even got into the screen. Therefore, the same trick with the statistics: we didn’t manage to transfer everything in parts, because the connections are rather dense. In addition, in the UI, the ORM system works with us, and it is quite difficult to break the links there. In fact, you have to implement two-phase commit to different databases. Running two variants into the same ORM was also problematic for the model. Therefore, we decided to postpone the entire migration of the entities to the last spurt, while at the same time preparing all the necessary moments.
For one of the plates, we still had to implement the transfer, break the connection, it took quite a long time. The reason is that this tablet is very large and it has changed intensively. It was expensive for initialization in the postgrese (the need to pump all the entities) and for the replication process.
With the transfer of functionality was a little easier. On the screen, you can see some interrelation of the stages of transition of some part of the system from Oracle to PostgreSQL. There are, of course, fewer connections, but each square consists of small squares, which has its own connections. Therefore, in order to facilitate the last spurt, we have maximally simplified everything we can. You can select three options .
Full transfer of functionality when we completely removed it from Oracle and started on postgrese. In some cases this was possible.
In most cases, we transferred the functionality and ran it idle . For example, billing has worked in this mode for about a year, allowing us to find many performance problems and a number of critical bugs.But the results of such a billing, of course, were thrown into the trash.
Dead transfer is a transfer of the stored procedures, rewriting them from Oracle to postgres. These procedures might not even work. And, often, they did not work, they were not called. But this allowed us to create a set of "blanks" to the next step.
Actually, having prepared everything to go to the last spurt, we overcame it with this last spurt. In fact, we moved all the statistics, included the functionality that was idling and which was lying dead weight. The release itself took place with a rather large “downtime”, since you need to transfer a fairly large amount of relevant data and perform some migrations point by point. It is interesting that, despite the fact that we did a lot of things, we found that we forgot to transfer certain modules, so we had to postpone the release for about a week. And even after that, somewhere in a week or two, we found another module that had not been migrated, and we already had to finish it live.
So 4 years- this is quite a long time. To understand whether this value is justified or not, we wrote out a number of metrics, some of which you see on the slide. Probably, each of you was mistaken in the initial assessment of the volume of this or that work. This mistake was made by us. Initially, our assessment was a year and a half. And even now, when everything is completed, few people call the number for more than two years, because it all merged into a continuous stream.
As you can see, the base is not very big, but not very small either. If you take the code, to write a number with 0, you need to write about 80 lines per day . It’s not so much even for a small team.
The greatest time was taken to study and compare different solutions. Of the other points that are not technical, there are several. As you can see, the transfer involved about 30 people who worked in different teams, in different places. And the coordination of such a national team has required quite a long time.
One of the moments was the loss of focus.. I thought for a long time what it was until I encountered this with my own eyes. The fact is that we acted proactively and we didn’t have such big problems on Oracle in most cases, so all the migration tasks went a bit in the background. And, since there were quite a lot of short-term tasks, this strategic direction was slightly moved to the background. There were cases when we forgot about migration for a week or two.
Despite the fact that PostgreSQL is a pretty cool database and with each release we like it more and more, we still lacked some moments during the migration.
Joba , in Oracle, they exist in the database itself and it was unusual to go beyond the framework, run some crontab. In addition, you need to monitor all this, that it all starts and runs well.
Resource management : sometimes it is good to divide resources between processes, for example, between user requests and statistics.
The coolest thing in Oracle, in my opinion, because it saved me several times, is flashback. This is an opportunity to restore some version in a short period of time. We are thinking of something like this, we are thinking of realizing it as a postgres, since there were moments when we had to restore large chunks of entities due to incidents.
Also OEM (Oracle Enterprise Management)- this is a web application. When we have these or other problems, DBA climbs into this OEM, sees all the activities there are. You can go through the stories, see what happened, compare the interaction of various aspects and do all your admins. In PostgreSQL, of course, DBA has skill at the tips of the fingers, so it can issue all requests with the same speed as through this application, but the convenience suffers for people who are not DBA. Therefore, we still wrote our own version of the OEM, it was important to preserve the entire history of requests for tables and queries. In the end, we could go in and see what was slowing down there, see all the interrelations and make changes in our code.
Greenplumwe still did not buy, the crisis, but the volumes are growing, so we are faced with the same problems that we already had Oracle, on PostgreSQL, but on a larger scale. So, the first of the problems we have encountered is disk restriction . At some point, we even had to do an un-raid operation on several sections. Having thus turned RAID-10 into RAID-5, it seems.
The main problem of this operation is that the data stored on these sections are lost, so we had to play the tags on the disk to fit everything. Upon request, we also have problems, we stick to some of the limitations in processing, to the extent that we even have to disable some of the functionality. And some volumetric statistics that require a lot of space and processing, we even carried out the postgres to a separate place and develop all this direction in a special way, because the further, the worse.
New version watched? We watched and watched, but we transferred the main statistics to Hadoop, for short. On hadupe we are faced Impala, such a column, in fact, a database that is responsible for our data. And we even have a strategic task to bring all the volume statistics that are not needed for billing, or for the work of momentary jobs, in the Hadoop cluster and, if we need something, then return it once.
So, our operators love to watch hourly statistics. The volume of keys in the main event table is very large and it is expensive for the server, so we have already taken out the hourly statistics to Hadoop .
The thematic expansion of PG Day'17 increased the interest of our listeners and speakers in the subject of migrations from one data warehouse to another. Migration issues will be considered in almost every section.so no questions will be left! Especially for you we are preparing to present some interesting reports.
Vasily Sozykin from Yandex.Money tells you about the migration of a loaded service from Oracle to PotgreSQL , a fascinating story about how Yandex specialists migrated a truly huge base without downtime. Alexander Korotkov from Postgres Professional in his report “ Our Response to Uber ” will analyze the sensational story about the relocation of the popular Taxi service from PostgreSQL back to MySQL. Kristina Kucherova from Distillery will tell you how she and her colleagues came to a decision aboutOLTP migration of a part of their system from MS SQL to PostgreSQL , and how it turned out for them.
Well, the fourth, no less intriguing, report on online data replication in Greenplum of 25 DBMSs running Oracle is prepared for you by Dmitry Pavlov , the head of the Date Warehouse administration team at Tinkoff Bank. Dmitry is not the first time speaking at PG Day. His previous reports were a resounding success and were packed to capacity.
At the very last moment, when we were preparing this issue for publication and were already ready to press the “ Publish ”button, colleagues from the research institute “Voskhod” applied for a report. Dmitry Pogibenko will tell aboutsuccessful migration of the state system Mir database (more than 10 TB of data!) from DB2 to PostgreSQL with minimal downtime.
Preparing for your own migration? Have you had a successful transition from one repository to another and are you eager to share your experience? Be sure to come to us at PG Day, buy tickets at spring prices, apply for reports, deadline soon!
See you in summer in St. Petersburg!
Source: https://habr.com/ru/post/327418/
All Articles