Restore 1C Enterprise (DBF) after formatting
People in pursuit of comfortable working conditions often do not think about the safety and security of their data and sooner or later face the issue of their loss. Consider the client's appeal with USB Flash 2Gb Transcend. According to the client, one of the days when installing the drive into the USB port of the computer, it was suggested to format it. According to the client, he refused from this and turned to the system administrator for help. The system administrator, finding that when the USB drive is connected, the computer is “suspended”, did not think of anything better than to agree with the proposal of the operating system to format it ( never do this! ). Next, the system administrator used the popular automatic recovery program R-Studio. The result of her work in the form of anonymous folders was copied to the client on another drive. When viewing the result, the client found that about a quarter of the files could not be opened and, worst of all, 1C Accounting 7.7 refused to start with the restored database, citing the lack of files.

rice one
As it turned out, the client’s backup copy of this database is more than a year old.
The first step in solving such problems is to create a block-by-block copy of the original drive (or, as is customary to write, since the time when the carriers were only drives on flexible and hard magnetic disks — sector-by-sector). When reading, an unstable reading speed is detected, which indicates serious deterioration of NAND memory (multiple NAND reads by a page's NAND memory controller and error correction due to redundant error correction code ( ECC ) is a very resource-intensive operation, which ultimately affects read speed). If there are unread plots, you need to fill them with a pattern, which later will help us identify files that have not been read in full.
')
Next, proceed to the analysis. It is necessary to establish which file system and within which limits it previously was on a USB flash. That is, it is necessary to search for regular expressions characteristic of various file system metadata, but before starting it, check the simple option, which implies that the partition boundaries are the same. To do this, set the current file system settings.
Open LBA 0 (0x0 in the image file) and check for the presence of the partition table or the Boot sector of the file system.

rice 2
In our case, we see at the 0x1C2 offset of the partition type 0x0B, which means that at the moment there is a FAT32 partition on the USB drive, which starts from 0x80 sectors (DWORD at the offset 0x1C6), 0x003C2000 sectors in length (DWORD at the offset 0x1CA). Go to the boot sector of the described section in sector 0x80 (in the image file bytes 0x10000)
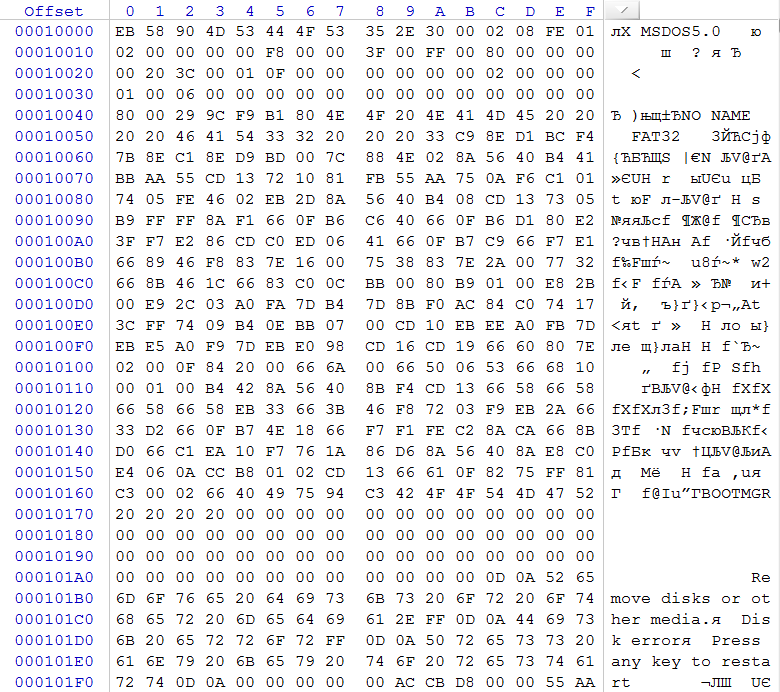
rice 3
It is necessary to calculate the starting point of reference, that is, the place of the zero cluster relative to which the space is calculated, and also to determine the size of the cluster.
To do this, we need the following parameters, described in the boot sector (will be specified as an offset from the beginning of the sector): sector size at offset 0x0B is 0x200 (512 bytes), the number of sectors in the cluster at offset 0x0D is 0x08, the cluster size is obtained by multiplying the size sectors per number of sectors in a cluster 0x08 * 0x0200 = 0x1000 (4096 bytes), the number of reserved sectors before the first copy of the FAT tables - by offset 0x0E = 0x01FE (510 sectors), the number of copies of FAT - by offset 0x10 = 0x02, the size of one copy of FAT - at offset 0x24 = 00000F01 (3841 sectors). Using the obtained parameters, we will calculate the position of the beginning of the data area: 0x10000 + 0x01FE * 200 + 0x00000F01 * 2 * 200 = 0x410000 (8320 sector). A small catch from the creators of FAT32 is that at the moment we calculated the beginning of the data area for the FAT32 partition, but it is not a zero starting point, since the first two entries in the FAT table are reserved and not used for its intended purpose, and therefore the zero point is the beginning of the data area minus 2 clusters. In this case, it will be 0x410000-0x1000 * 2 = 0x40E000 (8318 sector).
Let's check for the absence of records in the file allocation table and carry out the procedure for comparing copies for different readings.

Fig. four
Comparison of copies of FAT showed that there are no discrepancies. Analysis of the contents of one of the copies of FAT showed that according to the table on the section only one cluster is filled.
Next, you need to evaluate the root directory for deleted entries. The position of the first cluster of the root directory is specified in the boot sector at offset 0x2C = 0x00000002. For the second cluster, FF indicates FF FF FF 0F, which means the end of the chain, that is, the root directory consists of one cluster.

rice five
At the address calculated above, we see the root directory (root directory), which contains the only 32-byte record. At offset 0x0B we see the value 0x08, which indicates the type of the record - the volume label. The fact that the file allocation tables are filled with zeros and there is no hint of any other entries in the root directory indicates that this section has been formatted.
To test the assumption that the partition was not recreated and all file system parameters are correct, you need to search for the regular expression 0x2E 0x2E 0x20 0x20 0x20 0x20 0x20 0x20 with offset inside sector 0x20 (this expression is the sign of the beginning of the FAT32 directory).
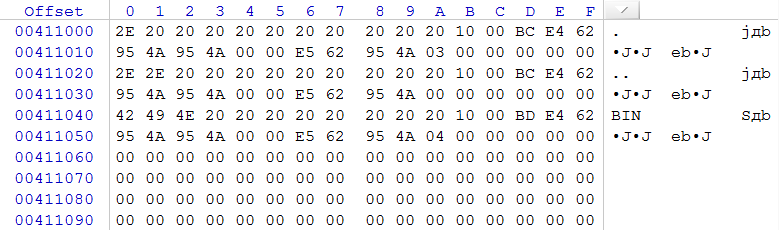
rice 6
When finding a regular expression, it is necessary to make sure that this is indeed a directory, on other grounds, since in some cases a coincidence is possible and the found regular expression is not an element of the directory. According to the information in fig. 6, it can be said that this directory began with cluster 3 (the current cluster number of the DWORD directory is contained in the WORD at offset 0x1A (the younger part) and WORD at the offset 0x14 (senior part)) and was described in the root directory, since in the offsets 0x3A and 0x34 contains zeros (initial cluster of the parent directory). Check if the cluster number in this directory corresponds to the zero point of the file system created after formatting. For this, the cluster cluster number is multiplied by the size of the current cluster and we add to the zero point 0x03 * 0x1000 + 0x40E000 = 0x411000. As you can see, the calculated address corresponds to the actual location. It is possible to set the name of this directory only if the root directory previously consisted of more than one cluster, and the link to this directory was not in the first cluster, since the contents of the first cluster were completely destroyed during formatting along with the file allocation tables.
Next, we continue the search for the regular expression 0x2E 0x2E 0x20 0x20 0x20 0x20 0x20 0x20 with an offset within sector 0x20.

rice 7
Repeat all checks: 0x04 * 0x1000 + 0x40E000 = 0x412000. Again we see the correspondence of the directory position to the parameters of the current file system. But, besides this, we see that there is a cluster number of the parent directory 0x03, which means that this directory was nested, and looking at fig. 6, you can set the name of the directory, which is shown in Fig. 7. So, according to fig. 6, at offset 0x4B we see the value 0x10 - this means that this entry points to a directory, and by offset 0x5A and 0x54, the number 0x00000004 indicates a pointer to the 4th cluster. At offset 0x40 - the name of the directory "BIN". This is the way directory relationships are established in the corrupted FAT partition. After completing some more checks of directories in different parts of the image, we can conclude that the drive has formatted within the boundaries of the previous file system and the parameters of the newly created file system are inherited from the previous one, that is, further analytical operations should be performed within the section, described in the partition table, taking into account the parameters of the current file system.
Knowing that the database consisting of DBF files must contain the configuration file 1CV7.MD, we will search the sequence 0x31 0x43 0x56 0x37 0x20 0x20 0x20 0x20 0x4D 0x44. In order to reduce the number of deliberately false results, the search is best performed within 32-byte blocks with zero offset.
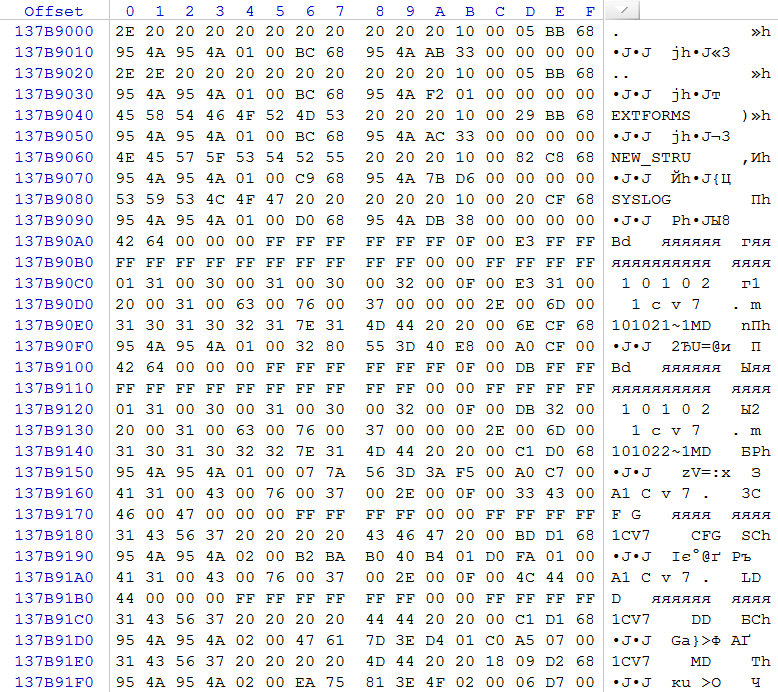
Fig. eight
Thus, we find all the directories that contain a pointer to the file 1CV7.MD. In our case, only one such directory was found, which suggests that we have found the first cluster of the required directory. This is followed by an analysis of the position of the parent directories, up to the root directory. Each directory found is written into a FAT table (first, as a directory from one cluster, by writing FF FF FF 0F for the corresponding table element). Also in the root directory is written reference to the child.
At the current stage, we will copy the found files with the assumption of their continuity, since both copies of the FAT do not contain information about fragmentation (recall that they were irretrievably destroyed by the system administrator as a result of rash formatting of USB flash). After copying the base directory 1C, we analyze the number of files. Considering that the directory fragment was one cluster in size, we extracted no more than 126 files, which is clearly much smaller than it should be in the directory with DBF and CDX files belonging to the 1C database. Approximately the same result will be issued by the automatic recovery program, as evidenced by the result obtained by the system administrator through the use of R-Studio.
The extracted files include 1CV7.MD (configuration file) and 1CV7.DD (data dictionary file). After completing the integrity check, we will create a temporary folder on our disk, where we place 1CV7.MD. We specify this path when adding a new database and open the configurator, through which we will create a clean database based on this configuration. Let's compare the generated DD file with the restored one, if the descriptions and the number of directories are identical, then no additional actions are required, and, having a complete list of files, you can start searching for the remaining fragments of the 1C base directory. To do this, you need to search for sequences from ASCII character codes used in the names of the missing DBF files. As the directory fragments are found, append the continuation of the chain to the file allocation table. After each operation of complementing the chain of the directory, perform file copying and analyze how much the number of missing DBF files has decreased, and re-form the sequence of ASCII character codes to search for the next fragment.

rice 9
It should also be remembered that when writing a chain of directory fragments to the file allocation table, it is necessary to analyze the fragments so that the LFN records are linked . In the case of only short records, the chain can be written with any order of fragments.
In this case, performing a search for 5 sequences, it was possible to find all the other fragments of the directory with the base 1C.
After the complete chain of directory fragments has been built, we perform repeated copying of all 1C database files with the assumption of their continuity. User information is contained in DBF files, so you need to check their integrity.
The main method for monitoring the integrity of a DBF file is to check the information contained in the service header and whether the contents of the file match the description in the header.
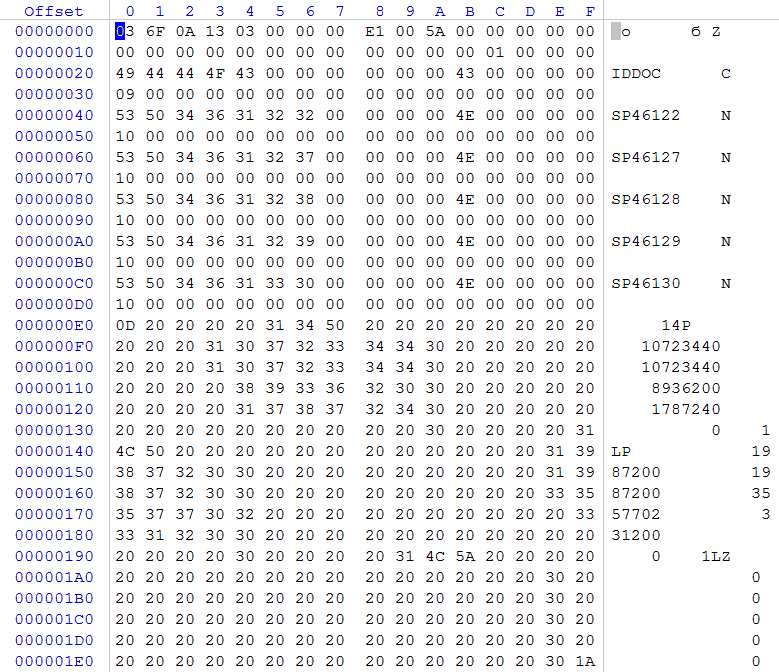
rice ten
Initially, the header is evaluated: its length is checked, indicated at offset 0x08, and whether the offset indicated in it leads to the final marker 0x0D. Base field records, starting at offset 0x20, are described by 32-byte records, in which the field name follows at offset 0x00, field type at offset 0x0B, and field size at offset 0x10. The sum of the +1 field sizes (one extra byte for each record in the database is the status of the record in the DBF) must be equal to the content at offset 0x0A (the size of one record in the database). In the figure DBF files we see the following field lengths: 0x09 + 0x10 + 0x10 + 0x10 + 0x10 + 0x10 + 0x01 = 0x5A.
Let's check the correctness of the file size. To do this, we multiply the number of records, which is indicated in the header at offset 0x04 by the size of one record in the database at offset 0x0A, followed by addition with the contents at offset 0x08.
0x00000003 * 0x005A + 0xE1 = 0x01EF. At the received offset should be a marker of the end of the file 0x1A.
To control the integrity of the field contents, you can use the visual method.

rice eleven
In this view option you need to scroll through the contents of the records from beginning to end. If the filling is homogeneous, there are data types in each field that are typical for the header and there is no foreign content, then after the DBF file has been viewed, it can be concluded that its contents are correct.
If you find content that does not match the description of the field in the database header, you need to set the exact place where the incorrect data starts.

Fig. 12
Based on the description of the fields in the header and the contents of a specific DBF file, it is possible to form presumptive ASCII sequences, which should be located at specified offsets in the missing fragments. In the absence of similar databases on one of the drives (including file copies of the same database), this method will allow you to quickly find all the missing fragments in the drive image. Separately, we note that additional difficulties will arise in joining fragments if the size of an entry in a DBF file is small or multiple 16. If there are other databases of the same type, the task will be many times more complicated (this statement is true at all stages of work, starting with searching for fragments of the desired directory).
It is necessary to check the integrity of each DBF file, of which there are several hundreds in one 1C database. After passing all the checks and charges of the file fragments, the final check in the 1C Enterprise configurator will follow.
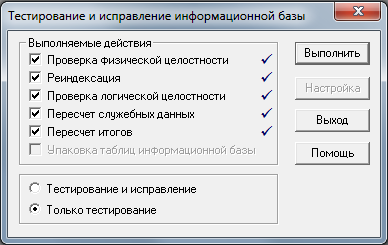
rice 13
Ideally, the test results should pass successfully all the items noted in the checkboxes. If errors are detected by the first two points, then it is necessary to analyze the error log in the configurator and find out in which DBF files there are foreign data that were not detected during the checks. If errors are detected when checking the logical integrity, then again it is necessary to analyze the error log to find out whether the base problem is in the quality of its collection, or in errors made by developers of the 1C configuration.
Let us pay attention to the fact that if this USB flash were not formatted, then after reading it, the data recovery procedure would be much simpler, which would have a significant effect on the cost and the duration of the work in the smaller direction. In conclusion, I would like to caution all users and service personnel from rash actions in emergency situations that repeatedly exacerbate the problem, and also wish to perform backup operations more often.
Next post: Recovering files after a cryptographic trojan
Previous publication: Recovering Data from a Damaged RAID 50 Array
rice one
As it turned out, the client’s backup copy of this database is more than a year old.
The first step in solving such problems is to create a block-by-block copy of the original drive (or, as is customary to write, since the time when the carriers were only drives on flexible and hard magnetic disks — sector-by-sector). When reading, an unstable reading speed is detected, which indicates serious deterioration of NAND memory (multiple NAND reads by a page's NAND memory controller and error correction due to redundant error correction code ( ECC ) is a very resource-intensive operation, which ultimately affects read speed). If there are unread plots, you need to fill them with a pattern, which later will help us identify files that have not been read in full.
')
Next, proceed to the analysis. It is necessary to establish which file system and within which limits it previously was on a USB flash. That is, it is necessary to search for regular expressions characteristic of various file system metadata, but before starting it, check the simple option, which implies that the partition boundaries are the same. To do this, set the current file system settings.
Open LBA 0 (0x0 in the image file) and check for the presence of the partition table or the Boot sector of the file system.
rice 2
In our case, we see at the 0x1C2 offset of the partition type 0x0B, which means that at the moment there is a FAT32 partition on the USB drive, which starts from 0x80 sectors (DWORD at the offset 0x1C6), 0x003C2000 sectors in length (DWORD at the offset 0x1CA). Go to the boot sector of the described section in sector 0x80 (in the image file bytes 0x10000)
rice 3
It is necessary to calculate the starting point of reference, that is, the place of the zero cluster relative to which the space is calculated, and also to determine the size of the cluster.
To do this, we need the following parameters, described in the boot sector (will be specified as an offset from the beginning of the sector): sector size at offset 0x0B is 0x200 (512 bytes), the number of sectors in the cluster at offset 0x0D is 0x08, the cluster size is obtained by multiplying the size sectors per number of sectors in a cluster 0x08 * 0x0200 = 0x1000 (4096 bytes), the number of reserved sectors before the first copy of the FAT tables - by offset 0x0E = 0x01FE (510 sectors), the number of copies of FAT - by offset 0x10 = 0x02, the size of one copy of FAT - at offset 0x24 = 00000F01 (3841 sectors). Using the obtained parameters, we will calculate the position of the beginning of the data area: 0x10000 + 0x01FE * 200 + 0x00000F01 * 2 * 200 = 0x410000 (8320 sector). A small catch from the creators of FAT32 is that at the moment we calculated the beginning of the data area for the FAT32 partition, but it is not a zero starting point, since the first two entries in the FAT table are reserved and not used for its intended purpose, and therefore the zero point is the beginning of the data area minus 2 clusters. In this case, it will be 0x410000-0x1000 * 2 = 0x40E000 (8318 sector).
Let's check for the absence of records in the file allocation table and carry out the procedure for comparing copies for different readings.
Fig. four
Comparison of copies of FAT showed that there are no discrepancies. Analysis of the contents of one of the copies of FAT showed that according to the table on the section only one cluster is filled.
Next, you need to evaluate the root directory for deleted entries. The position of the first cluster of the root directory is specified in the boot sector at offset 0x2C = 0x00000002. For the second cluster, FF indicates FF FF FF 0F, which means the end of the chain, that is, the root directory consists of one cluster.
rice five
At the address calculated above, we see the root directory (root directory), which contains the only 32-byte record. At offset 0x0B we see the value 0x08, which indicates the type of the record - the volume label. The fact that the file allocation tables are filled with zeros and there is no hint of any other entries in the root directory indicates that this section has been formatted.
To test the assumption that the partition was not recreated and all file system parameters are correct, you need to search for the regular expression 0x2E 0x2E 0x20 0x20 0x20 0x20 0x20 0x20 with offset inside sector 0x20 (this expression is the sign of the beginning of the FAT32 directory).
rice 6
When finding a regular expression, it is necessary to make sure that this is indeed a directory, on other grounds, since in some cases a coincidence is possible and the found regular expression is not an element of the directory. According to the information in fig. 6, it can be said that this directory began with cluster 3 (the current cluster number of the DWORD directory is contained in the WORD at offset 0x1A (the younger part) and WORD at the offset 0x14 (senior part)) and was described in the root directory, since in the offsets 0x3A and 0x34 contains zeros (initial cluster of the parent directory). Check if the cluster number in this directory corresponds to the zero point of the file system created after formatting. For this, the cluster cluster number is multiplied by the size of the current cluster and we add to the zero point 0x03 * 0x1000 + 0x40E000 = 0x411000. As you can see, the calculated address corresponds to the actual location. It is possible to set the name of this directory only if the root directory previously consisted of more than one cluster, and the link to this directory was not in the first cluster, since the contents of the first cluster were completely destroyed during formatting along with the file allocation tables.
Next, we continue the search for the regular expression 0x2E 0x2E 0x20 0x20 0x20 0x20 0x20 0x20 with an offset within sector 0x20.
rice 7
Repeat all checks: 0x04 * 0x1000 + 0x40E000 = 0x412000. Again we see the correspondence of the directory position to the parameters of the current file system. But, besides this, we see that there is a cluster number of the parent directory 0x03, which means that this directory was nested, and looking at fig. 6, you can set the name of the directory, which is shown in Fig. 7. So, according to fig. 6, at offset 0x4B we see the value 0x10 - this means that this entry points to a directory, and by offset 0x5A and 0x54, the number 0x00000004 indicates a pointer to the 4th cluster. At offset 0x40 - the name of the directory "BIN". This is the way directory relationships are established in the corrupted FAT partition. After completing some more checks of directories in different parts of the image, we can conclude that the drive has formatted within the boundaries of the previous file system and the parameters of the newly created file system are inherited from the previous one, that is, further analytical operations should be performed within the section, described in the partition table, taking into account the parameters of the current file system.
Knowing that the database consisting of DBF files must contain the configuration file 1CV7.MD, we will search the sequence 0x31 0x43 0x56 0x37 0x20 0x20 0x20 0x20 0x4D 0x44. In order to reduce the number of deliberately false results, the search is best performed within 32-byte blocks with zero offset.
Fig. eight
Thus, we find all the directories that contain a pointer to the file 1CV7.MD. In our case, only one such directory was found, which suggests that we have found the first cluster of the required directory. This is followed by an analysis of the position of the parent directories, up to the root directory. Each directory found is written into a FAT table (first, as a directory from one cluster, by writing FF FF FF 0F for the corresponding table element). Also in the root directory is written reference to the child.
At the current stage, we will copy the found files with the assumption of their continuity, since both copies of the FAT do not contain information about fragmentation (recall that they were irretrievably destroyed by the system administrator as a result of rash formatting of USB flash). After copying the base directory 1C, we analyze the number of files. Considering that the directory fragment was one cluster in size, we extracted no more than 126 files, which is clearly much smaller than it should be in the directory with DBF and CDX files belonging to the 1C database. Approximately the same result will be issued by the automatic recovery program, as evidenced by the result obtained by the system administrator through the use of R-Studio.
The extracted files include 1CV7.MD (configuration file) and 1CV7.DD (data dictionary file). After completing the integrity check, we will create a temporary folder on our disk, where we place 1CV7.MD. We specify this path when adding a new database and open the configurator, through which we will create a clean database based on this configuration. Let's compare the generated DD file with the restored one, if the descriptions and the number of directories are identical, then no additional actions are required, and, having a complete list of files, you can start searching for the remaining fragments of the 1C base directory. To do this, you need to search for sequences from ASCII character codes used in the names of the missing DBF files. As the directory fragments are found, append the continuation of the chain to the file allocation table. After each operation of complementing the chain of the directory, perform file copying and analyze how much the number of missing DBF files has decreased, and re-form the sequence of ASCII character codes to search for the next fragment.
rice 9
It should also be remembered that when writing a chain of directory fragments to the file allocation table, it is necessary to analyze the fragments so that the LFN records are linked . In the case of only short records, the chain can be written with any order of fragments.
In this case, performing a search for 5 sequences, it was possible to find all the other fragments of the directory with the base 1C.
After the complete chain of directory fragments has been built, we perform repeated copying of all 1C database files with the assumption of their continuity. User information is contained in DBF files, so you need to check their integrity.
The main method for monitoring the integrity of a DBF file is to check the information contained in the service header and whether the contents of the file match the description in the header.
rice ten
Initially, the header is evaluated: its length is checked, indicated at offset 0x08, and whether the offset indicated in it leads to the final marker 0x0D. Base field records, starting at offset 0x20, are described by 32-byte records, in which the field name follows at offset 0x00, field type at offset 0x0B, and field size at offset 0x10. The sum of the +1 field sizes (one extra byte for each record in the database is the status of the record in the DBF) must be equal to the content at offset 0x0A (the size of one record in the database). In the figure DBF files we see the following field lengths: 0x09 + 0x10 + 0x10 + 0x10 + 0x10 + 0x10 + 0x01 = 0x5A.
Let's check the correctness of the file size. To do this, we multiply the number of records, which is indicated in the header at offset 0x04 by the size of one record in the database at offset 0x0A, followed by addition with the contents at offset 0x08.
0x00000003 * 0x005A + 0xE1 = 0x01EF. At the received offset should be a marker of the end of the file 0x1A.
To control the integrity of the field contents, you can use the visual method.
rice eleven
In this view option you need to scroll through the contents of the records from beginning to end. If the filling is homogeneous, there are data types in each field that are typical for the header and there is no foreign content, then after the DBF file has been viewed, it can be concluded that its contents are correct.
If you find content that does not match the description of the field in the database header, you need to set the exact place where the incorrect data starts.
Fig. 12
Based on the description of the fields in the header and the contents of a specific DBF file, it is possible to form presumptive ASCII sequences, which should be located at specified offsets in the missing fragments. In the absence of similar databases on one of the drives (including file copies of the same database), this method will allow you to quickly find all the missing fragments in the drive image. Separately, we note that additional difficulties will arise in joining fragments if the size of an entry in a DBF file is small or multiple 16. If there are other databases of the same type, the task will be many times more complicated (this statement is true at all stages of work, starting with searching for fragments of the desired directory).
It is necessary to check the integrity of each DBF file, of which there are several hundreds in one 1C database. After passing all the checks and charges of the file fragments, the final check in the 1C Enterprise configurator will follow.
rice 13
Ideally, the test results should pass successfully all the items noted in the checkboxes. If errors are detected by the first two points, then it is necessary to analyze the error log in the configurator and find out in which DBF files there are foreign data that were not detected during the checks. If errors are detected when checking the logical integrity, then again it is necessary to analyze the error log to find out whether the base problem is in the quality of its collection, or in errors made by developers of the 1C configuration.
Let us pay attention to the fact that if this USB flash were not formatted, then after reading it, the data recovery procedure would be much simpler, which would have a significant effect on the cost and the duration of the work in the smaller direction. In conclusion, I would like to caution all users and service personnel from rash actions in emergency situations that repeatedly exacerbate the problem, and also wish to perform backup operations more often.
Next post: Recovering files after a cryptographic trojan
Previous publication: Recovering Data from a Damaged RAID 50 Array
Source: https://habr.com/ru/post/327414/
All Articles