Nvidia has published a report on the development and optimization of current GPUs and compared them with Google’s TPU
A recent Google report on the device and purpose of the TPU makes it possible to make an unequivocal conclusion - without accelerated computations, a serious deployment of the AI system is simply inappropriate.
Most of the necessary economic computing around the world today is made in the global data centers, and they are changing every year. Not so long ago, they served web pages, distributed advertising and video content, and now they recognize the voice, identify the image in video streams, and provide the necessary information at the exact moment when we need it.

Increasingly, these features are activated using one of the forms of artificial intelligence, the so-called. "Deep learning." This is an algorithm that studies on huge amounts of data to create systems that solve such tasks as translation from different languages, diagnosing cancer and training unmanned vehicles. Changes introduced by artificial intelligence into our lives are accelerated at an unprecedented pace.
One of the researchers of deep learning, Jeffrey Hinton, recently said in an interview with The New Yorker: “Take any old classification problem in which you have a lot of data, and it will be solved by“ deep learning ”. We have thousands of different applications on the basis of “deep learning”.
Look at google. The use of innovative research in deep learning in their performance attracted the attention of the whole world: the amazing accuracy of the Google Now service; a momentous victory over the greatest go player in the world; Google Translate's ability to work in 100 different languages ...
"Deep learning" has achieved unprecedented effective results. But this approach requires that computers process huge amounts of data at the exact moment that Moore’s law slows down. “Deep learning” is a new computational model that requires the invention of a new computational architecture.
')
NVIDIA occupied this niche for some time. In 2010, Dan Ciresan, a researcher at the Swiss AI laboratory named after Professor Jürgen Schmidhuber, discovered that NVIDIA GPUs can be used for in-depth training of neural networks with an acceleration of 50 times compared to CPU. A year later, Schmidhuber laboratory used graphics processors to develop the first neural networks based on "deep learning", which won international contests in handwriting recognition and computer vision.
Then, in 2012, Alex Krizhevsky, then a student at the University of Toronto, won the now famous ImageNet annual pattern recognition contest using a couple of graphics processors. (Schmidhuber captured a comprehensive history of the influence of “deep learning” using the GPU on modern computer vision).
AI researchers around the world have discovered that the NVIDIA computational model, originally intended for graphics accelerators and supercomputers, is ideal for “deep learning”. This, like 3D graphics, processing and graphical modeling of images in medicine, molecular dynamics, quantum chemistry and weather simulation, is an algorithm of linear algebra that massively uses parallel computation of tensors or multidimensional vectors. And although the NVIDIA Kepler graphics processor, developed in 2009, opened the world to the possibility of using a graphics accelerator for computing in “deep learning” problems, it has never been specifically optimized for this task.

We decided to fix this by developing new generations of GPU architecture, first Maxwell and then Pascal, which included many new architectural developments optimized for “deep learning”. Presented just four years after the KIepler, the Tesla K80 model, our Pascal-based Tesla accelerator P40 Inferencing Accelerator, provides a 26-fold increase in performance, well ahead of Moore's law.
During this time, Google has developed a special accelerator chip, called a tensor processor, or TPU, sharpened by the function of issuing the finished result. His corporation and put into operation in 2015.
Not so long ago, the Google team published technical information on the benefits of TPU. They claim, among other things, that TPU has a 13-fold superiority over the K80, but does not compare TPU with the current generation P40 based on Pascal.
To update Google's comparison, to quantify the performance jump from K80 to P40 and to demonstrate how TPU compares with current NVIDIA technology, we created the table below.
P40 combines computational accuracy and throughput, internal memory and memory bandwidth to achieve unprecedented performance for both the learning task and the output of the finished result. For training, the P40 has a tenfold throughput and 12 teraflops of 32-bit floating point performance. For outputting the finished result, the P40 has high performance for operations with eight-bit integers and high memory bandwidth.
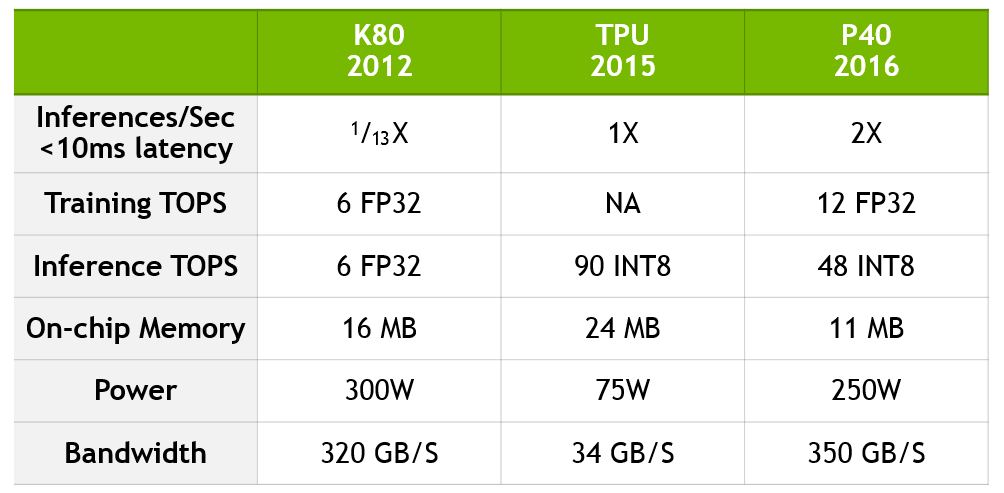
The data is based on the “In-Datacenter Performance Analysis of a Tensor Processing Unit” report by Jouppi et al [Jou17] and NVIDIA's own data. The K80-TPU performance factors are based on the average acceleration factor of CNN0 and CNN1 from a Google report, which compares the performance with the semi-finished K80. The K80-P40's performance factors are based on GoogLeNet, a widely available CNN model with similar performance characteristics.
While Google and NVIDIA have chosen different paths of development, there are several topics that are common to these approaches:
The world of computer technology is undergoing a historical transformation, which is already referred to as the AI revolution. Today, its influence is most evident in large data centers - Alibaba, Amazon, Baidu, Facebook, Google, IBM, Microsoft, Tencent, and others. They need to increase their workloads for AI, without spending billions of dollars on the construction and power supply of new data centers without the use of specialized technologies. Without accelerated calculations, large-scale development and implementation of AI systems is almost impossible.
Most of the necessary economic computing around the world today is made in the global data centers, and they are changing every year. Not so long ago, they served web pages, distributed advertising and video content, and now they recognize the voice, identify the image in video streams, and provide the necessary information at the exact moment when we need it.
Increasingly, these features are activated using one of the forms of artificial intelligence, the so-called. "Deep learning." This is an algorithm that studies on huge amounts of data to create systems that solve such tasks as translation from different languages, diagnosing cancer and training unmanned vehicles. Changes introduced by artificial intelligence into our lives are accelerated at an unprecedented pace.
One of the researchers of deep learning, Jeffrey Hinton, recently said in an interview with The New Yorker: “Take any old classification problem in which you have a lot of data, and it will be solved by“ deep learning ”. We have thousands of different applications on the basis of “deep learning”.
Unprecedented efficiency
Look at google. The use of innovative research in deep learning in their performance attracted the attention of the whole world: the amazing accuracy of the Google Now service; a momentous victory over the greatest go player in the world; Google Translate's ability to work in 100 different languages ...
"Deep learning" has achieved unprecedented effective results. But this approach requires that computers process huge amounts of data at the exact moment that Moore’s law slows down. “Deep learning” is a new computational model that requires the invention of a new computational architecture.
')
NVIDIA occupied this niche for some time. In 2010, Dan Ciresan, a researcher at the Swiss AI laboratory named after Professor Jürgen Schmidhuber, discovered that NVIDIA GPUs can be used for in-depth training of neural networks with an acceleration of 50 times compared to CPU. A year later, Schmidhuber laboratory used graphics processors to develop the first neural networks based on "deep learning", which won international contests in handwriting recognition and computer vision.
Then, in 2012, Alex Krizhevsky, then a student at the University of Toronto, won the now famous ImageNet annual pattern recognition contest using a couple of graphics processors. (Schmidhuber captured a comprehensive history of the influence of “deep learning” using the GPU on modern computer vision).
Optimization for "deep learning"
AI researchers around the world have discovered that the NVIDIA computational model, originally intended for graphics accelerators and supercomputers, is ideal for “deep learning”. This, like 3D graphics, processing and graphical modeling of images in medicine, molecular dynamics, quantum chemistry and weather simulation, is an algorithm of linear algebra that massively uses parallel computation of tensors or multidimensional vectors. And although the NVIDIA Kepler graphics processor, developed in 2009, opened the world to the possibility of using a graphics accelerator for computing in “deep learning” problems, it has never been specifically optimized for this task.
We decided to fix this by developing new generations of GPU architecture, first Maxwell and then Pascal, which included many new architectural developments optimized for “deep learning”. Presented just four years after the KIepler, the Tesla K80 model, our Pascal-based Tesla accelerator P40 Inferencing Accelerator, provides a 26-fold increase in performance, well ahead of Moore's law.
During this time, Google has developed a special accelerator chip, called a tensor processor, or TPU, sharpened by the function of issuing the finished result. His corporation and put into operation in 2015.
Not so long ago, the Google team published technical information on the benefits of TPU. They claim, among other things, that TPU has a 13-fold superiority over the K80, but does not compare TPU with the current generation P40 based on Pascal.
Google update comparison
To update Google's comparison, to quantify the performance jump from K80 to P40 and to demonstrate how TPU compares with current NVIDIA technology, we created the table below.
P40 combines computational accuracy and throughput, internal memory and memory bandwidth to achieve unprecedented performance for both the learning task and the output of the finished result. For training, the P40 has a tenfold throughput and 12 teraflops of 32-bit floating point performance. For outputting the finished result, the P40 has high performance for operations with eight-bit integers and high memory bandwidth.
The data is based on the “In-Datacenter Performance Analysis of a Tensor Processing Unit” report by Jouppi et al [Jou17] and NVIDIA's own data. The K80-TPU performance factors are based on the average acceleration factor of CNN0 and CNN1 from a Google report, which compares the performance with the semi-finished K80. The K80-P40's performance factors are based on GoogLeNet, a widely available CNN model with similar performance characteristics.
While Google and NVIDIA have chosen different paths of development, there are several topics that are common to these approaches:
- AI requires accelerated computation. Specialized accelerators provide a significant part of the data processing necessary to keep up with the growing demands of "deep learning" in an era when Moore's law slows down.
- Tensor processing underlies the performance assurance for in-depth training and delivery of finished results.
- Tensor processing is an important new workload that businesses must consider when building modern data centers.
- Accelerating the processing of tensors can significantly reduce the cost of creating modern data centers.
The world of computer technology is undergoing a historical transformation, which is already referred to as the AI revolution. Today, its influence is most evident in large data centers - Alibaba, Amazon, Baidu, Facebook, Google, IBM, Microsoft, Tencent, and others. They need to increase their workloads for AI, without spending billions of dollars on the construction and power supply of new data centers without the use of specialized technologies. Without accelerated calculations, large-scale development and implementation of AI systems is almost impossible.
Source: https://habr.com/ru/post/327396/
All Articles