Everything is bad

Well, everything is bad. It’s a little fun to say this: at the conference ( Web à Québec ) there was a lot of talk about a wonderful future and things possible thanks to new technologies. On new tools and devices that should make our lives easier. My friends know that I usually have a very cynical view of technology; I personally fear all these smart devices that respond to my words, what other speakers admired.
Mainly because the more time I spend on programming and spend in this industry, the more I learn how everything works from the inside, and the less trust all this inspires in me. I picked up the image for the slide. This is the painting "The Triumph of Death" by Peter Bruegel. To some extent, she reveals my attitude to the "smart home".

I want to show that having even a very simple application that looks very, very reasonable, and show a lot of problems and potential errors that can hide in it and unpleasantly surprise us. I want to demonstrate that it’s hard to really feel safe when it comes to code. It will be a scary story!

To reveal my point of view, I will start with a basic application familiar to any developer in this room. Here I have a small web application. On the right - users, using their devices, connect to my frontend, executing code written in some language and responsible for the application logic. There is a connection to the database where the information is stored. Next - cron, it is needed for a number of background tasks, perhaps, not particularly difficult. Then comes the cloud, which is probably used by many other components of the system. Maybe you store images in S3 or something else.
So, this is a reasonable application, but there will be problems easily in it: if any mechanism fails, the whole system ceases to function correctly. Instead, we consider the following:
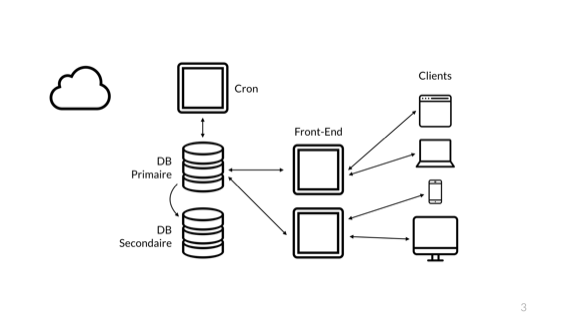
Such a scheme is safer. Now I have an additional front, and I can connect or disconnect any of them and still be accessible to customers. The second node of the database gives us the possibility of failover in case of problems, but this is not a backup solution. Just one person is enough, DROP TABLE users and real-time replication to remove the Users table and lose this hot spare. So let's say that we acted reasonably and created a backup in this cloud.
Thus, only one server with cron is needed, because asynchronous tasks can be solved a little later. That's better. Our architecture is quite reliable and convenient, and now we will only worry about the code.

Here are a few abstractions.
In the upper left corner you see data structures: trees, maps, arrays, dictionaries, sets, lists, etc. They allow us to structure information into something more than bits of memory. Obviously, this is good.
Next we have identifiers. I consider them abstractions. They can be your auto-increment identifiers in the database, a UUID or GUID, or variables, pointers, URLs or URIs. They basically allow you to refer to an element, part of the data or an object without the need for its full description. Typically, identifiers are related by context, which gives them meaning. I can say: “You are John,” and people who know a particular John will have an idea of who John is, based on his acquaintance, on indicators such as his height, profession, age, etc. Identifiers allow we define what the whole true element supports.
Here we have numbers. None of those present here today can raise his hand and say that he is implementing his own half-adder in each of his projects. We basically just use numbers directly, not bits, as before.
Bottom left is our network. These are all just abstractions. Your connections, ordered data streams, IP addresses and port numbers (which are also identifiers!), Packets, etc. Fortunately, we are not just transmitting electrical signals over the cable.
Next comes the time. And here I will not describe it. Philosophers, metaphysicians and scientists for thousands of years argued to get closer to what we mean by this word today.
And then we have the lines, the format for everything else that we do not know how to portray.
Each of these essential tools is necessary for us to work and perform tasks without knowledge of what has been created for decades by science, mathematics and technology. However, if we are not aware of some of the limitations of these abstractions and use them in ways that contradict the actual properties of the abstractions, this can lead to irreversible consequences.
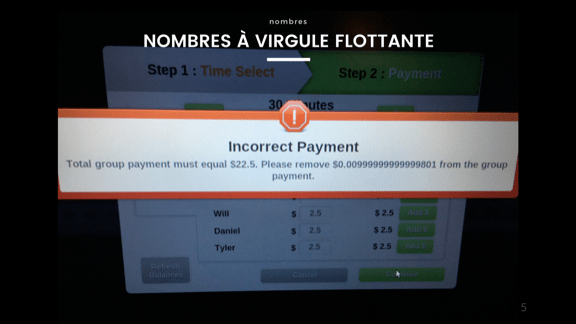
Let's start with floating point primes. If you have ever seen a sum of 0.1 + 0.2, equal to 0.30000000000000004, you know what it is. There is an infinity of numbers from 0.1 to 0.2, but we have a limited number of bytes to represent them. Some numbers are not completely divided, and without working with the fractional part it will be very difficult not to lose accuracy when the computer starts replacing the numbers so that they acquire meaning.
Perhaps you have met this when working with money. The trick is this: do not use floating point numbers when it comes to money if you do not want to lose them. Always take the smallest indivisible unit you need. It doesn't matter if cents, millidollars, picodollars or femtodollars are just non-floating point numbers.
I heard about a project in which the bank tried to broadcast its old code bases using node.js. Unfortunately for the team, no one told them that there are only floating-point numbers in JavaScript, and the team had to abandon the project.
By the way, languages with JavaScript type floats have an upper limit on the precision of integers, in this case 2 53 .
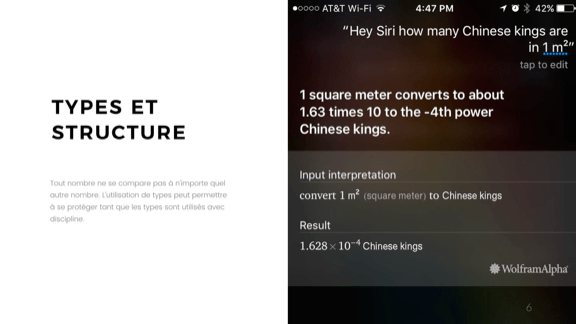
With integers a bit easier. People for the most part understand better the limitations that helps. But this is not enough: you need the right structure and type of use, because not all integers mean the same thing. Think of the Mars Climate Orbiter, which failed because some parts of the code worked in imperial units, and others in the metric system. Oops.
The image shows a special look at these intricate units. Ask Siri or Wolfram | Alpha how many Chinese kings are on one square meter, and you will get 1,628 × 10 –4 . Not quite sure what that means, but every time it is reliably determined.
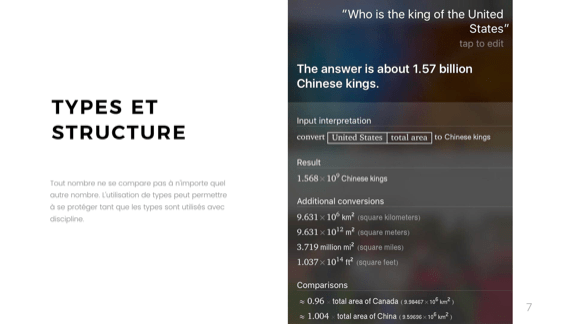
More interesting when language processing is added. I do not understand why, but to the question “Who is the king of the United States?” We get the answer “1.57 billion Chinese kings.”
As a rule, it is quite easy to prevent such an error. Be careful and if you are dealing with a fancy type system, use it to the fullest. Do not chase the "whole" for all its types; specify what are the integers, what is their unit.
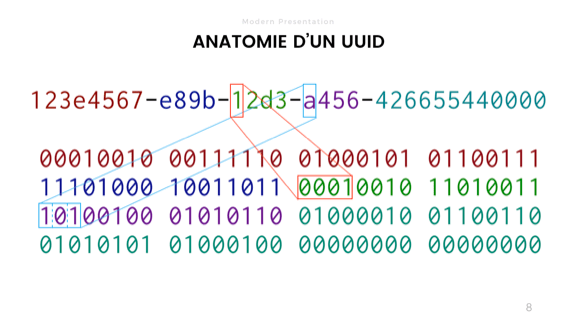
Suppose that my application does an excellent job with its redundancy and also does an excellent job with number manipulation. Perhaps I even had users. Now I need to pay attention to such a useful thing as sharding, or maybe I will just work with external services. In any case, I will most likely use a UUID or GUID, since they are unpredictable and can “guarantee” uniqueness.
UUIDs are just a group of bits that you compare. If they all came together, the ID passed the test. If not, then it is different. There are many different options, some random, some based on time or address.
As we can see, the UUID is what is located on the top of the slide, with hexadecimal numbers separated by hyphens. This is a little risky.

Depending on the language or stack you are resorting to, you may have libraries that allow you to store UUIDs as binary blobs in memory. Or the lines where their abstract representations are stored. In some cases, you will have to use strings as an intermediate format, for example, when transferring information on different systems that do not support raw binary data, such as SQL queries or JSON.
That is the risk. By default, most strings in most languages have case-sensitive comparison operators. So, although these three UUIDs are identical in their authentic binary representation, they will not be compared as equal strings. Case sensitivity exists in any case and must be taken into account by your system, since the string representation is not an ideal abstract of the true properties of the UUID.
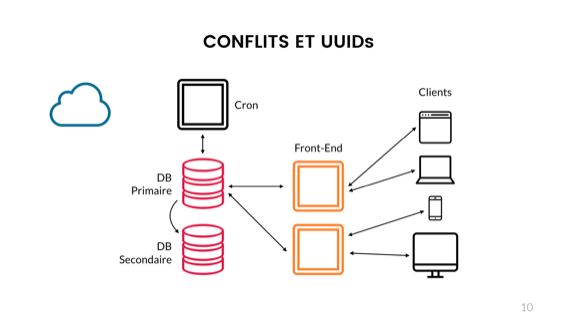
Indeed, various components that do not use the same exact presentation can be a serious headache. Your front-end, back-end, database, and cloud services users must either be case insensitive or inconsistent with the overall view.
For certain languages, special libraries are required, one part of which will do everything correctly, and you cannot expect the same from the other. Databases can be complicated:
- Using PostgreSQL, you get a case-insensitive comparison, but a lower-case representation.
- MySQL supports the creation of an uppercase UUID, but does not have a storage format for them. It is recommended to choose case sensitive VARCHAR.
- MSSQL can store a GUID, but is suitable for presentation in upper case.
- Oracle can store raw data, so there should be no problems.
- Redis does not support UUIDs, and most likely you will have to use a case-sensitive string.
- MongoDB does everything right with the binary representation.
Nevertheless, even if you, for your part, do everything flawlessly, there is no guarantee that the system will work. Just one subsystem is enough to destroy everything. For example, external services, such as some Amazon services, have many different offers that are not always consistent with each other (for example, DynamoDB and SimpleDB are case sensitive, so a third AWS service based on them will most likely inherit these properties). If this happens to you, if you, say, use PostgreSQL locally and store the UUID as a UUID, then nothing good will come of it. Theoretically, objects may start to conflict with each other or simply disappear, since your local representation of the lower register does not exist for the upper register service.
Any part of the system that acts differently than others can cause problems. You will have to store the canonical UUID (for comparison) with its small copy (for its original version) or to study how each service stores the material. Not very fun.

However, string comparison can lead to big trouble. Another interesting property of the compared strings (not only strings, but also most arrays and data structures) is in your desire for the operation to take place as quickly as possible.
If I compare password hashes, the uppermost one is the correct one, and the second and third ones are other attempts, then when my '==' operator reaches the difference, it is reset and returns false.
This is interesting because the duration of the calculation is information. In the area of security and cryptography, we strive to hide as much information as possible. A hacker can send multiple requests with different assumptions, and then see how long the processing takes, and understand how close the intended answer is to the solution. This can lead to leakage of information about the value of the hash, the attacker is able to offer new options based on time.
In fact, this is a time attack. Although there are many more varieties.

This problem can be solved by replacing the comparison operator with a strict disjunction. Set the value to false, and then make a bitwise or one byte comparison with the XOR. Each time both values are the same, 0 (false) is returned, and each time the values are different, 1 (true) is returned. OR leads to the original value, and if in the end it is not 0, then you know that there is a difference.
Still need to be careful. You need to make sure that there is no leakage of information about the amount of data and that certain optimizations do not harm you. Good cryptographic libraries do this anyway. Use bcrypt or scrypt, and there will be no problems with passwords, but the more you know, the better.
It's funny that sometimes cryptography requires that everything happen as slowly as possible from a design point of view, but as quickly as possible in implementation, as this prevents brute force attacks.

Of course, some devices take it too close to the heart, and their sluggishness is not really necessary!
So, we have this wonderful application. Now it does an excellent job with redundancy, integers, floating-points, UUIDs and passwords. I have a lot more users, and performance relative to response time begins to decline. From the blog posts I learned that I was losing an important percentage of users who did not receive a response every tenth second of the time spent. This is a signal to action!
Some operations last longer and restrain others. As a rule, it is really difficult to predict what this may be, and peak times are annoying. Someone from the team comes up with an idea that will help solve all the problems. What is this idea?
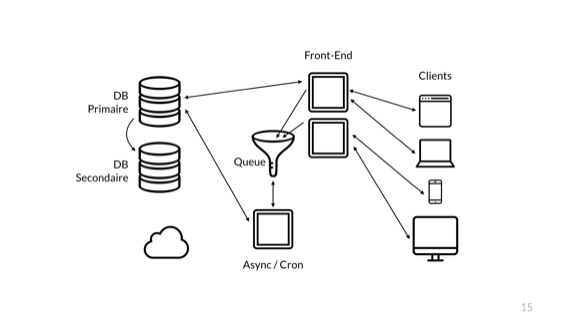
Stick to the queue! The external server simply sends simple short requests to the database directly, and all complex, time consuming queued. Data is accepted into the queue without processing, and I can quickly return the results to users.
And what? All my actions are returned. Damn, it's even faster than before!
However, there is some problem.
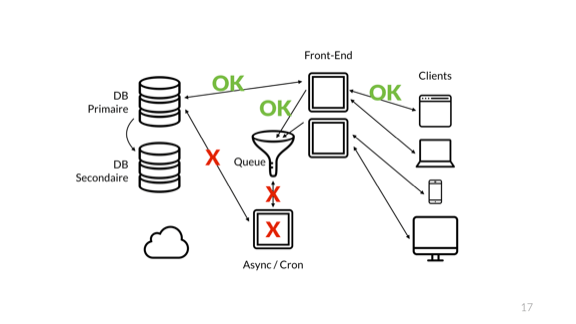
When we added the queue, an interesting thing happened: the transfer of the general state of the system to an external server ceased. If earlier, thanks to returning the result from the end-to-end operation, system users could see if all their requests were processed, then the implementation of the queue destroyed this concept.
Now the external server allows us to find out only about the presence of direct connections. We have no idea about the queue user, the asynchronous server, its ability to interact with the database or with the asynchronous queue itself.
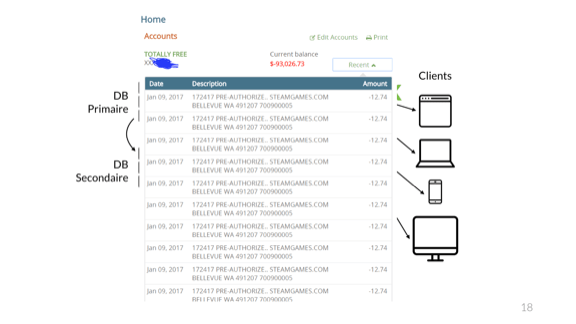
In fact, if the work is not done carefully, the events can be repeated. Here is the user Reddit, who bought the game for 12.74 dollars. He bought it once, but received a request for payment many times, until there was an excess of a loan of –93 thousand dollars on his bank account.
Of course, there is no guarantee that this problem is caused by the queue, but very similar to that. When something goes wrong and the end-to-end data flow is broken up in mysterious ways, the consequences are usually extremely noticeable.
But that is not all. The reason why my application started to work slowly: it was overloaded. So now I have completely separated the perceived performance from the actual load in the system.
No matter how bad everything is in the back end, the performance of the frontend does not change. This scheme works in the case of a temporary overload for some large operations, but does not justify itself when it comes to long-term stability. By controlling the performance of the frontend, we, in fact, watched the entire system. If I divide it into two parts, my monitoring shows not only the performance, but also the performance of only half of the system.
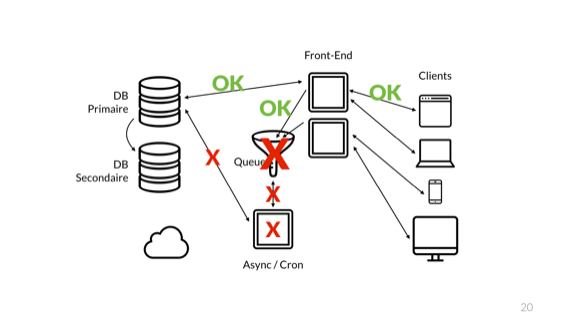
As a result, the queue is full and crashes. Of course, not only she fails.

The error gets to the interface nodes, and as a result we get catastrophic failures.
How can we be? Someone arranges a meeting, says that such is unacceptable. And what are the developers doing?
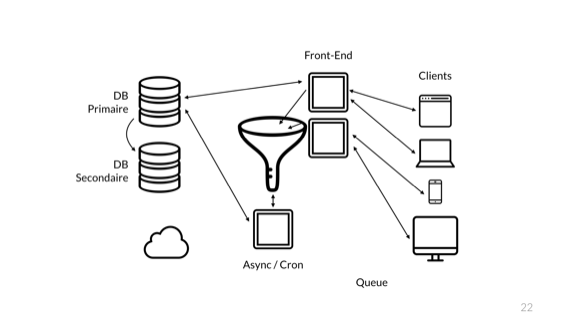
Increase the queue. But that is not all. Since at the time of the accident all the data in the queue was lost, all participants in the meeting also agree to make it permanent. It slows it down, and since we love redundancy, why not add another queue?
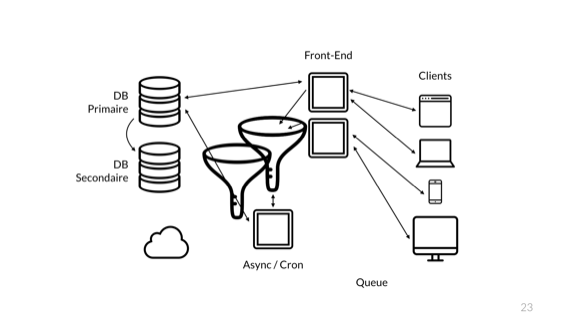
The next time an error occurs, we can do the same.
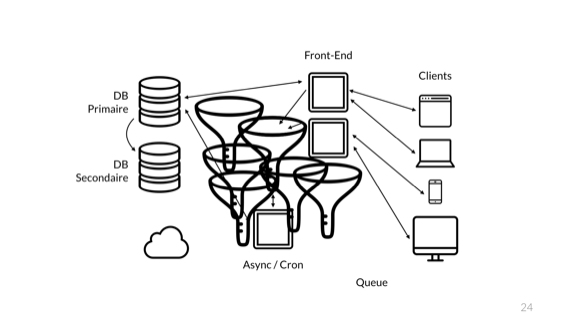
All these queues are a good solution. But we are a great big company, and therefore we need the technology of the next generation. We all know that this architectural scheme is terrible. So, we are introducing something special ...
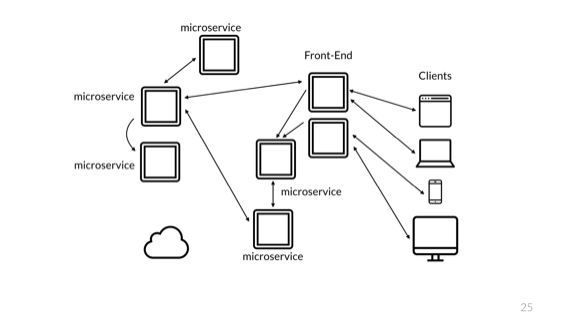
And these are microservices!
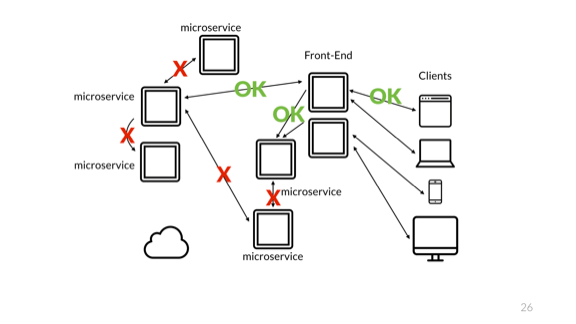
Of course, the problem is the same. The difficulty is still related to monitoring only part of the system. Such changes in the architecture should be invisible to users, but they have a very important influence on the maintenance and operation of the system.
Combining a user and operator or excluding one of them is a deadly mistake for your project. Operations become very complicated.
Of course, this is not all! All our components must be able to interact with each other.
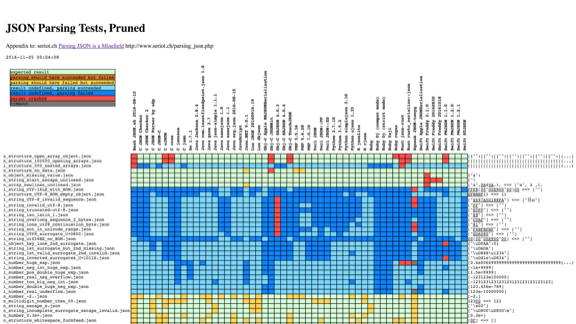
We could choose something like JSON. This is a chart from seriot.ch that tracks about 50 implementations of JSON libraries in more than ten languages.
Almost each of them processes information in its own way.

It's not very good.
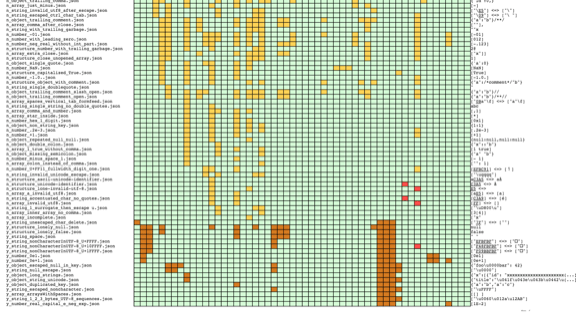
The JSON standard is very small, but it probably means that it provides a space for interpretation and, therefore, for special non-standard behavior.
The most interesting thing: if you run several microservices and send an equally carefully processed data set to all of them, this can lead to inconsistent behavior. Take, for example, invalid JSON with a set of identical keys that have different values. Let's say I have an object “person”, where the attribute “name” appears twice, the first time is “Mark”, the second time is “John”.
Most likely, the analyzer will behave in one of three ways:
- Refuse to parse the record, as it should be.
- Keep the first name (Mark).
- Keep the middle name (John).
The choice of the last two methods depends on the order of analysis (using the stack or in turn).
Suppose I have three services, each of them has its own version of behavior. Then one service will stop and refuse to process the record, and the other two will see different values for the same object. Handle them with care.
Another problem is time. Different clocks operate at different speeds. Last year, I conducted an experiment for a presentation on calendars (no, don't laugh, the calendars are actually very interesting), during which I turned off the clock synchronization on my computer. Then I did the same with the oven and microwave to see where the deviation would be greatest. Somewhere in three or four weeks, the time on the microwave shifted by about 3 minutes, on the laptop - by about 2 minutes and 16 seconds, and on the oven - did not change.
Clocks deviate depending on hardware, temperature, voltage, humidity, etc. They cannot be accurate for a long time.
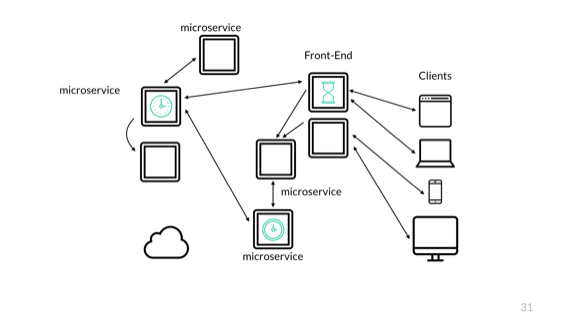
So, without synchronization, the timestamps for the same event can be divided and lead to disparate results. To avoid this, NTP is required. You can monitor the time and see that its deviation is insignificant. Nevertheless, for events that occur very quickly, even NTP can have enough ways to cause problems.
And this happens even on one device. In the previous work, we somehow broke the Hadoop cluster. It turned out that we ran fast trades on the millisecond scale and noted the time at two points: when the request was received and at the close of the auction. We could then use this data to register the event and calculate the time difference to find out how long the processing takes.
On the fateful day, when the transaction was carried out especially quickly, the NTP synchronization of the computer clock led to a deviation of a fraction of a second: it is enough to put a second time stamp before the first one. For complete happiness, this happened at about midnight on the last day of the month or at some other turn of the cycle.
The events ended the day before they began, which was very embarrassing for the cluster, which simply fell on obviously garbage data.
The trick here is to create a significant difference between monotone and system time.
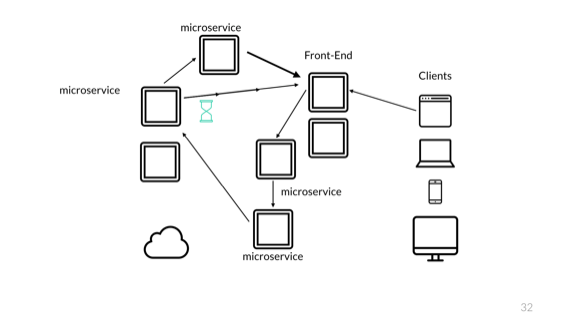
But that is not all. Time always causes problems. Working with similar systems, we can get completely different logical endings.
In this case, the client can send a request that will transfer it to the first service, then to the second and the third. Suppose the service confirms the purchase of goods and sends a notification about this to the interface. After the third service immediately sends an order for the fourth service, which, say, confirms delivery or something like that. It also sends a notification to the interface.
At this stage, due to network delays, the interface may receive information that the shipment occurs before the purchase is confirmed.
If you are a front-end developer, you are able to anticipate such events and handle them properly. If, instead, the same events fall into any audit system, it may well take them for an error, raise an alarm, cancel the dispatch, etc. Who knows what horrors will occur.
Then it is necessary to use logical time to track causality, instead of considering it unconditional, but this is too broad a topic to talk about it here.
In fact, logical errors are quite funny. They allow us to travel in time.

But that is not all. Those present here are probably familiar with time zones. But did anyone here hear about belts in half an hour?
(Most people raise their hands.)
Yes, this belt is located in Newfoundland. It is within the country, it is good that you know.
But then again, who knows about the existence of a quarter-hour time zone? Similar was in New Zealand. Or that a 44-minute minute was recorded in Liberia? Maybe some here have heard that in 1927 in the time zones in China there were deviations in five minutes and a few seconds?
But that's not all. Changes in time zones are not always insignificant. For example, Samoa exists between UTC – 11 and UTC +13, completely switching days. The trick is that they are on the date line change. In 1892, the islands decided to align their calendars with the United States, based on market considerations. That year they had twice on July 4th. The first of July, the second of July, the third of July, the fourth of July, the fourth of July, the fifth of July ...
And again, in 2011 (quite recently!), They agreed on calendars with China, and this time on the Samoan Islands was not on December 31.
In addition, there is summer time. If you are familiar with Brazilian sysadmins, you may have heard of such a funny fact (I don’t know if they still do this) that every region / province / state in Brazil annually votes on whether they adhere to DST. It is impossible to know in advance whether to update time zone files.
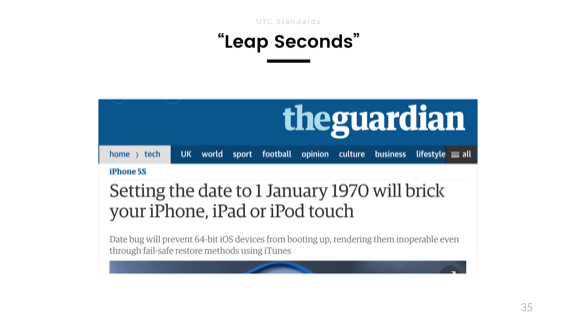
Next, leap seconds. The problems of time zones will be solved simply by UTC. But this has very interesting implications, since each type still uses UNIX timestamps and is freely convertible between UTC and the UNIX era, which begins on January 1, 1970.
, UTC , : , , . 1970 27- . UNIX .
, , - iPhone, 1 1970 . - . , , .
, ( , ), . — — , 1 1970 , , UTC , -27, . . 32 2106 , , .

But that is not all. . , , . - , ? ( .)
Not so much. , , — :
- . , .
- . - . ( ) .
- . , , . . , . , , , , .
- . . , . , , - . . , .
- , . , . , , . , .
- , .
- , , , — . , . - , : « , ». , , , .
. . .
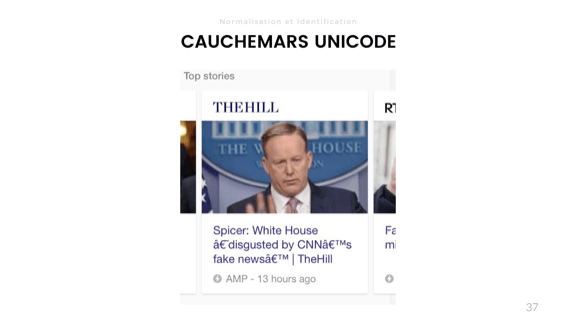
Oh no. . : , . . ( .)
Yes. , , . Latin-1 ( ISO-8859-1) UTF-8.

, UTF-8 ISO-8859-1 , ASCII.
. , HTTP ( ), , ( UTF-8), ( SQL , ), . , .
, , . , .

— . . :
- , 14 UTF-8, 12 UTF-16 20 UTF-32.
- , , . 14 UTF-8, 6 UTF-16 5 UTF-32.
- . 5, , .
- , , , , . « Delete, ». 4.
, , .
. 40+ .
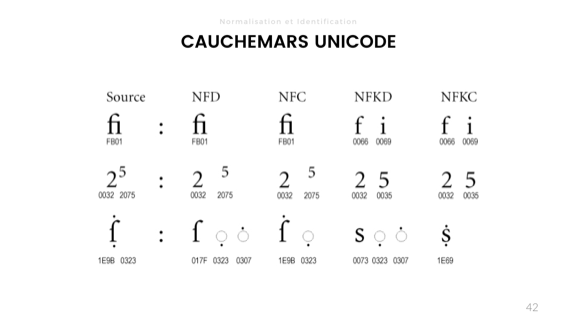
, (code points). , , . 30 , - , .
, , . .
. , , .


- ! ! 2012 « : SSL- », .
, . , , ( -), , « » . .

OpenSSL. .

GnuTLS .

API cURL PHP . , , CURLOPT_SSL_VERIFYHOST true. , PHP ( , C C++) true — , 1. 1 CURLOPT_SSL_VERIFYHOST . — 2.
Oops.

, class breaks, .
, . , . , .
class breaks, . .

« », , . . , , IoT .
. , (, , ?), , , -, . .
. , , , , . . ? , ?
, , , . - , . , , - , , . .
Do we use adequate means to ensure the safety of our creations? Will we leave everything as it is because we have not killed enough people yet? Maybe we all know about the problem, but simply deny our personal responsibility, until something forces us to act as a single whole in order to achieve more?
I do not know for sure, but all this is very scary. I can only hope that I am not one of those who ultimately cause enough harm to make laws. Maybe we should all be a little wary of this. Everything is bad, and we are to blame.
')
Source: https://habr.com/ru/post/327264/
All Articles