As we from the CRUD-engine service did
We create an online designer of accounting and reporting systems. The constructor allows you to create an accounting web application with “standard” logic without programming. By standard logic, it means that the application will not have buttons in the form of bananas, which do exactly what you have thought. Although, if desired, the application logic can be extended using programming languages JavaScript (client side, server side), SQL (and even then these buttons can be made).
The article will address issues:
The essence of the constructor is that the system administrator determines the set of entities, sets the set of fields (attributes) of each entity. For each entity, a table will be generated at the database level. And separately sets access rights to it, depending on many factors. As a result, the system will generate CRUD interfaces for all users based on their access rights. The administrator can also set up a graph of admissible states (statuses) for the entity and transitions between states. Such a graph will essentially describe the business process of the movement of the entity. All business process management interfaces are also generated automatically.
')
For example, for a store, the essence of an item has attributes of weight, price, expiration date, date of manufacture, etc. The item has a status in stock, in a store, purchased. The store manager sees the goods in his store. The main butcher sees all the meat products of the network. Of course, this is all very simplistic.
Initially, this constructor was created “for itself”. We really didn’t want to create hundreds of tables, CRUD pages, a bunch of different reports, the ability to separate data (rows and columns) for another customer. At the same time, we wanted to keep each project under our total control. If we were asked to do almost anything, we could do it. The designer provided us with the speed of development and its cheapness (the developers of the kernel, the systems almost did not penetrate into the business processes), the applied logic was done by analysts. The fact that the designer was his, made it possible to do everything that your heart desires. At the same time, the core of the system was developed.
Previously, for each new potential customer, we deployed a copy of the project. Installed this copy on his or our servers. Customized the application in the designer for the customer. Once again, the manager asked me to create ten more copies of the application (with different URL addresses) in order to show them to different clients, IIS took up all the RAM of the server. The speed of all applications significantly subsided. It was clear that with proper administration of IIS and with the completion of the architecture of the designer, some (maybe even a large) amount of resources could be won. But we realized that we were going in the wrong direction.
Thinking in detail about the problems, we identified three main ones:
Next we brainstormed. It described three main options for implementation.
Option 1:
Everything is done in one super application. To create an additional ApplicationEntity entity, all system entities (metadata tables in the database) must somehow refer to their ApplicationEntity. On the web server to do processing for restricting rights (who sees what, who rules, etc.).
Advantages of option 1:
Disadvantages option 1:
Option 2:
From the last minus of the previous paragraph, the following decision was born. Web server to make one application, make a set of databases (one per client). The web server catches all requests of the form * .getreport.pro, by the third level domain in the mini DB mapper it searches for the connectionstring to the required client database. Next, the system works in the old way, because In the database, where we connect, there are only data on the client system.
Advantages of option 2:
Disadvantages option 2:
Option 3:
Service-box option. A host of virtual machines are deployed on the server. Each virtual machine has one separate web application deployed from its database. The main server is engaged only in forwarding requests.
Advantages of option 3:
Disadvantages option 3:
After lengthy meetings , the second option was chosen . The following describes why it has the described advantages, and how we leveled its disadvantages.
There is a single web application through which all requests from all clients pass. It is clear that with time, if there is a need, it will turn into a web farm. Changes in the code for this will be minimal.
The client makes a request to the server with the URL address myapplication.getreport.pro, the web server accesses the database containing the mapping between the URL addresses of the requests and the connectionstring to the client base. Each connectionstring is based on a unique DBMS user who has rights only to his own database.
To minimize database requests, this mapping is placed in the cache of the web server in a key-value type structure (Dictionary in C #). The cache is constantly updated every few seconds.
There are no other connectionstrings in the application code and configurations. When creating a new connection to the database, the application has nowhere to get the data for the connection, except from this cache. So we exclude the possibility of a SQL query slip into another database of another client.
The default constructor of the EntityFramework context is private. As a result, for any access to the database, we must clearly indicate to which database we make the request. And since in any context only one connectionstring is available (from the GetClientConnectionString method), then we simply have nowhere to miss. Below is the implementation of the GetClientConnectionString method.
When a user logs in, she issues an accessToken to the client’s browser. All requests to the system, except the login request, occur using this accessToken. These tokens are stored in the client database, respectively, tokens from one client will not work with another. Tokens are GUIDs that are generated with each login again. Thus, the selection of a token is not possible. It is this separation of tokens at the level of different databases and the definition of the connectionstring from the request that makes this variant of the architecture more secure than the variant with a single super base.
When requesting from the client to the server, after the connectionstring is defined, there are several levels of security checks. At the first level, we define the class AuthHandler: DelegatingHandler. It has the SendAsync method, which will be called each time any API method is called. If there is no accessToken field in the request header or the user with such accessToken is not found, the system will generate an error without even calling the controller's API method.
Next, the code of the desired controller is called, which calls the appropriate DAL core method. Any critical kernel method (which changes or scans data) is first looking for a user in the list of users by its accessToken. Next, we check the rights of a specific user and execute the main method code. It's all standard.
Since the application consists of a single web application, then updating the web part is quick and easy. Curious is the case with databases. We use the Code First approach, so that with any user request, all migrations will be inflated on his database.
In fact, migrations to all databases will be inflated even earlier (during the launch of the application). The fact is that we have a mechanism for sending notifications to the user by mail. Notifications are regular letters that can be sent to any users of the system depending on any data. We use for this server-side scripting programming language. At the start of the application, this service starts, which refers to all user databases in order to find out if there are letters to send. At this time, there is a rolling migration on all user databases.
The result of all this work was that the amount of memory required in IIS for working with all applications was significantly reduced. I can’t give exact figures, but a hundred business applications of users (ie databases) easily fit into the server with 4GB of operatives, and it still fits much more. The system has ceased to sink from memory.
However, the performance of the CPU has not grown much. Profiling revealed a major problem. The system does not know anything in advance (at the compilation stage) about the tables to which the user makes queries. Even for the simplest query to the data on any table, it is necessary to perform a very large number of queries to the database of metadata. The results of these queries will generate a sql. The resulting sql will already return real data, it runs very quickly.
Next, we wondered if it was possible to somehow reduce the number of requests to the metadata schema. We received a negative answer. To build a query, you need to know the name of the table in the database, the names of all the columns of the table, the role of the current user. For each role you need to know the columns that it is allowed to see. A lot of additional data to determine the rows that she is allowed to see, I will not go into details, but there are actually a lot of different requests to different metadata tables. And all this metadata is needed. Getting the metadata was almost two orders of magnitude longer than the execution of the request itself.
Such places were not enough. To verify any rights, one or another metadata was needed. Having thought it over, we decided to cache all this metadata on the server. But this decision is ideologically more complicated than it might seem at first glance. The previous caches that I described contain very small sets of disconnected data. In fact, they contain simple maps (URL -> connectionstring, accessToken -> account + Date). And this cache is large, tightly coupled, long tunable, with a complex structure.
If we implement a caching system in the forehead, then we will get a tricky structure (so that we could have quick access to the data through the Dictionary by keys), and a complex code to fill it in. In all methods that modify metadata, you will have to call the RefreshCache method, and there are very few of such methods. It would be very unpleasant to forget to call such a method. The RefreshCache code itself with the implementation in the forehead is also very severely large and ugly. This is caused by the fact that it is impossible to write the entire structure, what we want to get in the giant Include, then request all the data from the database. This is unrealistically slow. As a result, you have to split the request into a bunch of small requests, then glue the NavigationProp in the code, it already works faster. As a result, when adding a new metadata entity to the system, a decent headache will arise: for all CRUD methods, call RefreshCache, file a new entity into this method, and stick it into all NavigationProp for all entities. Generally speaking, this did not please us, but it would help. If you see a good move, look for a better move .
We identified two inconsistent problems:
The first problem was solved by introducing EntityFramework into the guts. We redefined the SaveChanges method of EntityFramework. Inside it we check if we have changed the entities we are interested in. If changed - we rebuild the cache.
The second problem was solved in two stages. At the first stage, we wrote the very bad code. First, we wanted to see that the speed really increase dramatically. Secondly, we wanted to see the code with which we need to do something. The fastest code for getting all the necessary metadata, we have come down to getting lists of metadata entities without all Include. Then we did the gluing of all NavigationProp manually.
The code for obtaining a complete list of all metadata entities is divided by threads. This is due to the fact that there are only a couple of large lists, all the time of receiving data essentially rests on them. This implementation simply reduces Ping. The problem with this code is that the more entities there are, the more connections there are between them. Growth is nonlinear. In general, the code works well, but did not want to write it. In the end, we decided to do everything through reflection (to implement the same algorithm as described above, but in a cycle for all properties and entities).
Before writing this flexible caching method, the RefreshCache runtime on the largest database we have (600+ user tables, 100+ roles) took about 10 seconds. After the implementation of this method - 11.5 seconds. In fact, all the additional time is taken to refer to the fields through reflection, but the time delay is small. Perhaps part of the time began to occupy the fact that now all NavigationProps are initiated from all entities, but not all have been used before. The advantage of this approach is that you can now write table.Columns.First (). Table.Columns ... Ie All references within this set of entities are analyzed; you can write code without fear of a sudden NullReferenceException.
The introduction of the cache described above significantly increased the speed of the system. The load on the CPU has become minimal. Even on a single-core machine, everything works fast for many hundreds of users with minimal CPU usage.
When transferring customers to the service, the question of the safety of their data became more acute. When we delivered boxed solutions (gave away bin), then questions about data integrity did not arise. Clients had their own servers, their admins, their backups.
In the cloud version, we act very simply. We have only two types of entities that the client is afraid of losing. This is his data in the database that the user enters, and the files that he attaches. Both we store in Amazon S3. Files are basically stored right there, uploaded there via a web server, not stored on a local disk. When a user downloads a file, the web server itself downloads it from Amazon and gives it to the client. Every night, backups of all paid databases are loaded into Amazon. Once a month I download all the backup database to the local machine.
From the point of view of files, data loss is possible when they are lost in Amazon S3. Data from the database should disappear from Amazon S3, the web server and my local machine.
Thus, the text described above shows how we made the architecture productive, scalable and secure. This approach allowed our managers to create prototypes of applications (even almost finished applications) without programmers. Maintenance of the entire project began to take much less time. We managed to greatly increase the speed of the system and cheapen the server.
This is the most complex and interesting system that I personally have ever done. Only a small but important aspect is described here (sharing of resources between user applications). In fact, the system is quite large and multifunctional. Writing this post helped to systematize and realize what we did and why. I think that this text will be interesting to those who are thinking of summarizing their achievements to the level of service. I believe that our problems and solutions are not unique. Maybe someone will criticize some of the solutions, suggest something more correct / fast / flexible. Ultimately this can make us stronger. And, of course, we wanted to be heard about us. Suddenly, after reading this post, you will want to log in to our system and look at it.Now we are launching an affiliate program for developers and IT integrators (in my profile the site of our company is indicated). We want our accounting system designer to be useful to others.
UPD 1. Added questionnaire (there was no such option in the sandbox).
The article will address issues:
- The choice of application architecture in the transition to the service model. More precisely, the web server sharding and database between users.
- Optimization of dynamic code execution. Those. the code that does not know what he is referring to. Code using metadata to work.
- The “safe” architecture (of course, relatively, as everything related to this topic) differentiates user rights.
- The safety of user data.
The essence of the constructor is that the system administrator determines the set of entities, sets the set of fields (attributes) of each entity. For each entity, a table will be generated at the database level. And separately sets access rights to it, depending on many factors. As a result, the system will generate CRUD interfaces for all users based on their access rights. The administrator can also set up a graph of admissible states (statuses) for the entity and transitions between states. Such a graph will essentially describe the business process of the movement of the entity. All business process management interfaces are also generated automatically.
')
Images of the basic system interface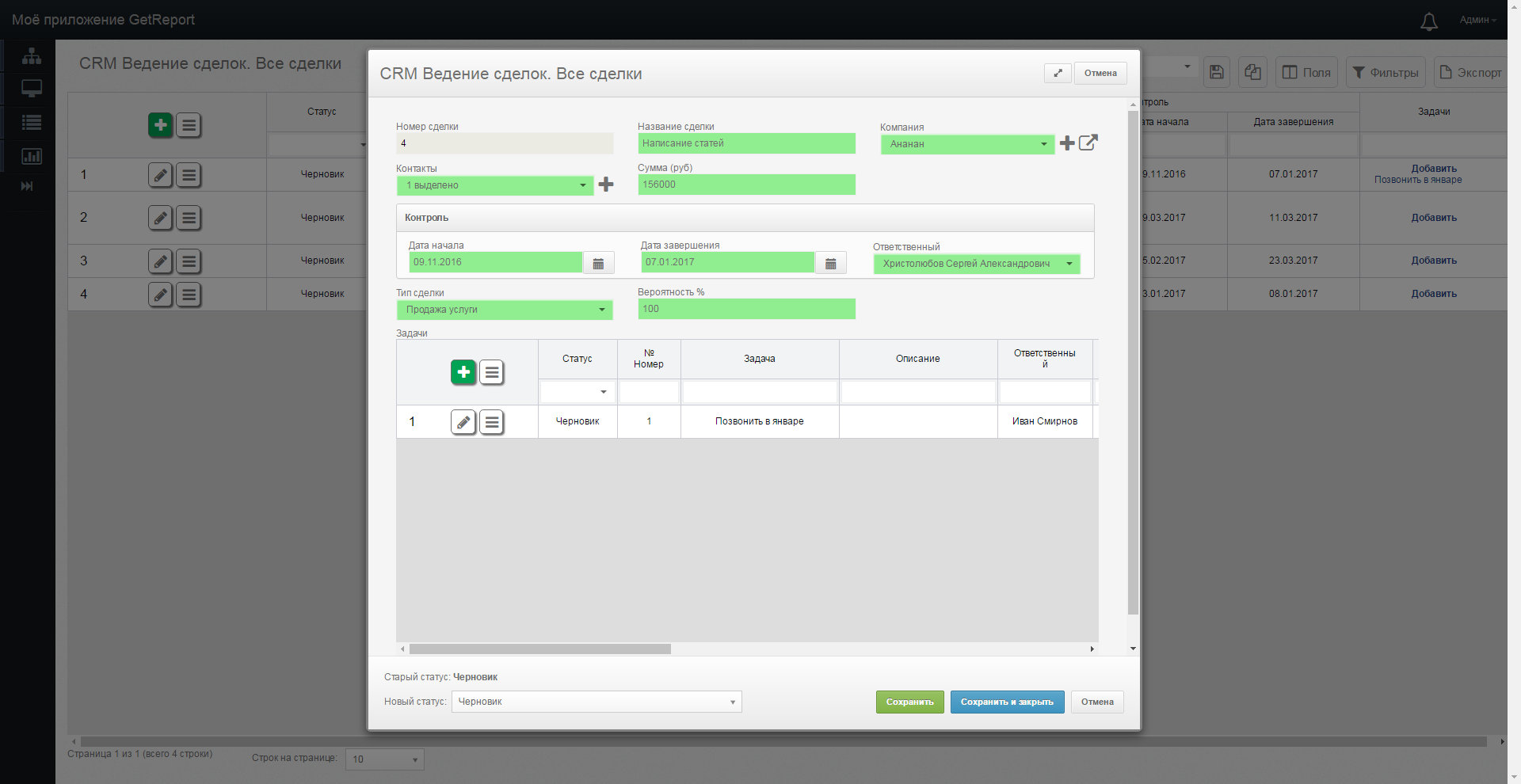

For example, for a store, the essence of an item has attributes of weight, price, expiration date, date of manufacture, etc. The item has a status in stock, in a store, purchased. The store manager sees the goods in his store. The main butcher sees all the meat products of the network. Of course, this is all very simplistic.
Initially, this constructor was created “for itself”. We really didn’t want to create hundreds of tables, CRUD pages, a bunch of different reports, the ability to separate data (rows and columns) for another customer. At the same time, we wanted to keep each project under our total control. If we were asked to do almost anything, we could do it. The designer provided us with the speed of development and its cheapness (the developers of the kernel, the systems almost did not penetrate into the business processes), the applied logic was done by analysts. The fact that the designer was his, made it possible to do everything that your heart desires. At the same time, the core of the system was developed.
Previously, for each new potential customer, we deployed a copy of the project. Installed this copy on his or our servers. Customized the application in the designer for the customer. Once again, the manager asked me to create ten more copies of the application (with different URL addresses) in order to show them to different clients, IIS took up all the RAM of the server. The speed of all applications significantly subsided. It was clear that with proper administration of IIS and with the completion of the architecture of the designer, some (maybe even a large) amount of resources could be won. But we realized that we were going in the wrong direction.
Choice of architecture
Thinking in detail about the problems, we identified three main ones:
- Managers wanted to create applications without referring to programmers. And even better, customers themselves create applications without referring to managers.
- The server had to withstand an order of magnitude heavy loads with the same resources.
- Upgrading the system should occur with less pain. We had a lot of unrelated projects that had to be accompanied and updated separately.
Next we brainstormed. It described three main options for implementation.
Option 1:
Everything is done in one super application. To create an additional ApplicationEntity entity, all system entities (metadata tables in the database) must somehow refer to their ApplicationEntity. On the web server to do processing for restricting rights (who sees what, who rules, etc.).
Advantages of option 1:
- Ideologically very simple implementation. From what it was, to make such an implementation of the architecture is most simple. To do this, you need to stick a couple of hundred if throughout the project.
- Simple deployment of a new system. When creating a system, a number of rows are inserted into several metadata tables, quickly and easily.
- The system is very easy to update. One web server, one base, normal deployment.
Disadvantages option 1:
- The solution looks very unstable (in terms of security). Even if all this division of rights between applications is correctly and correctly implemented, then with any modification of the code there is a risk that the new check will be incorrect. As a result, one user will get access to the admin part of the foreign system.
- The resulting super-base will be extremely poorly scaled. If we have a lot of clients, then it will be possible to divide the base into 2+ servers only by means of DB sharding / replication. It is very limited, opaque. It is much more pleasant to have different bases for different clients.
Option 2:
From the last minus of the previous paragraph, the following decision was born. Web server to make one application, make a set of databases (one per client). The web server catches all requests of the form * .getreport.pro, by the third level domain in the mini DB mapper it searches for the connectionstring to the required client database. Next, the system works in the old way, because In the database, where we connect, there are only data on the client system.
Advantages of option 2:
- Different databases for different customers. It's safe. A web server cannot do anything with a foreign database if it does not know the connectionstring before it. And if he knows, then in the standard mechanism of the designer there is a check of the user's rights inside his base (this is a well-debugged tool, the basis of the system core).
- Different databases for different customers. It is scalable. If necessary, they can be divided into different machines without a big headache. Web server is scaled by IIS.
- The system simply update. One web server, normal deploy. Code-first with auto migrations enabled updates all databases to the latest version. However, this is a less transparent update option than the single base version.
- The ability to give a particular client a connectionstring to his database, so that the client feels that his base is under his control, that he can do anything with it.
Disadvantages option 2:
- It is more difficult to follow a large number of bases. It is necessary to check that all migrations to all databases rolled.
- Rather tricky in code and time-consuming deployment of new applications. It is necessary to create a whole new database (either through the code first, or through the restore reference database), the new DBMS user, give the rights to the new database to the new user, etc.
Option 3:
Service-box option. A host of virtual machines are deployed on the server. Each virtual machine has one separate web application deployed from its database. The main server is engaged only in forwarding requests.
Advantages of option 3:
- Complete application isolation. Maximum security. Each application runs in its own sandbox.
- If necessary, we can give the client a working box with all its data. Just give him a virtual file.
- The ability to scale applications is almost infinitely linear. Those. Twice as many servers — twice as high in performance.
- A simple scan of the new application is to create a clone of virtuals and begin to transfer requests there.
- The ability to give a specific client a connectionstring up to its database, so that the client feels that his base is under his control, that he can do anything with it.
Disadvantages option 3:
- The main disadvantage is performance. Earlier we created a separate web application for the project, now we need to create a whole virtual machine, from our own OS and DBMS. CPU, in principle, should not sink, but there is really a lot of RAM. Usually RAM on the server is the main parameter when calculating the price.
- Very complex warm new version. You need to create a separate script "update". Which will cycle through virtualkam, stop the web server, update the database and bins. Either make such an “update” service on each virtual machine that monitors the version and updates the web server by taking data via FTP (or something like that). In any case, updating the version of the system with such an architecture is quite a fun thing.
After lengthy meetings , the second option was chosen . The following describes why it has the described advantages, and how we leveled its disadvantages.
The architecture of our version
There is a single web application through which all requests from all clients pass. It is clear that with time, if there is a need, it will turn into a web farm. Changes in the code for this will be minimal.
The client makes a request to the server with the URL address myapplication.getreport.pro, the web server accesses the database containing the mapping between the URL addresses of the requests and the connectionstring to the client base. Each connectionstring is based on a unique DBMS user who has rights only to his own database.
To minimize database requests, this mapping is placed in the cache of the web server in a key-value type structure (Dictionary in C #). The cache is constantly updated every few seconds.
There are no other connectionstrings in the application code and configurations. When creating a new connection to the database, the application has nowhere to get the data for the connection, except from this cache. So we exclude the possibility of a SQL query slip into another database of another client.
The default constructor of the EntityFramework context is private. As a result, for any access to the database, we must clearly indicate to which database we make the request. And since in any context only one connectionstring is available (from the GetClientConnectionString method), then we simply have nowhere to miss. Below is the implementation of the GetClientConnectionString method.
Implementing GetClientConnectionString
public static string GetClientConnectionString(this HttpContext context) { #if DEBUG if (Debugger.IsAttached && ConfigurationManager.ConnectionStrings[SERVICE_CONNECTION_STRING_NAME] == null) { /* ( URL connectionstring), . , */ return ConfigurationManager.AppSettings["DeveloperConnection-" + Environment.MachineName]; } #endif /* . , , .. Task, HttpContext, URL , . connectionstring, . .*/ if(context == null && TaskContext.Current != null) { // , ! return TaskContext.Current.ConnectionString; } /* , connectionstring */ if (context != null && ConfigurationManager.ConnectionStrings[SERVICE_CONNECTION_STRING_NAME] != null) { ServiceAccount account = context.GetServiceAccount(); if (account == null) { /* , , - connectionstring , */ return null; } if (account.GetCurrentPurchases().Any() == false) { /* ( ), connectionstring , */ return null; } return account.ConnectionString; } else if (ConfigurationManager.ConnectionStrings[DEFAULT_CONNECTION_STRING_NAME] != null) { /* , connectionstring */ return ConfigurationManager.ConnectionStrings[DEFAULT_CONNECTION_STRING_NAME].ConnectionString; } else { return null; } } Implementing multithreading for GetClientConnectionString (there is not always HttpContext)
/* http://stackoverflow.com/a/32459724*/ public sealed class TaskContext { private static readonly string contextKey = Guid.NewGuid().ToString(); public TaskContext(string connectionString) { this.ConnectionString = connectionString; } public string ConnectionString { get; private set; } public static TaskContext Current { get { return (TaskContext)CallContext.LogicalGetData(contextKey); } internal set { if (value == null) { CallContext.FreeNamedDataSlot(contextKey); } else { CallContext.LogicalSetData(contextKey, value); } } } } public static class TaskFactoryExtensions { public static Task<T> StartNewWithContext<T>(this TaskFactory factory, Func<T> action, string connectionString) { Task<T> task = new Task<T>(() => { T result; TaskContext.Current = new TaskContext(connectionString); try { result = action(); } finally { TaskContext.Current = null; } return result; }); task.Start(); return task; } public static Task StartNewWithContext(this TaskFactory factory, Action action, string connectionString) { Task task = new Task(() => { TaskContext.Current = new TaskContext(connectionString); try { action(); } finally { TaskContext.Current = null; } }); task.Start(); return task; } } When a user logs in, she issues an accessToken to the client’s browser. All requests to the system, except the login request, occur using this accessToken. These tokens are stored in the client database, respectively, tokens from one client will not work with another. Tokens are GUIDs that are generated with each login again. Thus, the selection of a token is not possible. It is this separation of tokens at the level of different databases and the definition of the connectionstring from the request that makes this variant of the architecture more secure than the variant with a single super base.
When requesting from the client to the server, after the connectionstring is defined, there are several levels of security checks. At the first level, we define the class AuthHandler: DelegatingHandler. It has the SendAsync method, which will be called each time any API method is called. If there is no accessToken field in the request header or the user with such accessToken is not found, the system will generate an error without even calling the controller's API method.
AuthHandler implementation
public class AuthHandler : DelegatingHandler { protected async override Task<HttpResponseMessage> SendAsync( HttpRequestMessage request, CancellationToken cancellationToken) { if (request.Method.Method == "OPTIONS") { var res = base.SendAsync(request, cancellationToken).Result; return res; } // API string classSuffix = "Controller"; var inheritors = Assembly.GetAssembly(typeof(BaseApiController)).GetTypes().Where(t => t.IsSubclassOf(typeof(ApiController))) .Where(inheritor => inheritor.Name.EndsWith(classSuffix)); // UnautorizedMethod. " " ( GUID ) var methods = inheritors.SelectMany(inheritor => inheritor.GetMethods().Select(methodInfo => new { Inheritor = inheritor, MethodInfo = methodInfo, Attribute = methodInfo.GetCustomAttribute(typeof(System.Web.Http.ActionNameAttribute)) as System.Web.Http.ActionNameAttribute })).Where(method => method.MethodInfo.GetCustomAttribute(typeof(UnautorizedMethodAttribute)) != null); // ConnectionString string connection = System.Web.HttpContext.Current.GetClientConnectionString(); if (string.IsNullOrEmpty(connection)) { var res = new HttpResponseMessage(System.Net.HttpStatusCode.NotFound); return res; } // , if (!request.RequestUri.LocalPath.EndsWith("/api/login/login") && methods.All(method => !request.RequestUri.LocalPath.ToLower().EndsWith($"/api/{method.Inheritor.Name.Substring(0, method.Inheritor.Name.Length - classSuffix.Length)}/{method.Attribute?.Name ?? method.MethodInfo.Name}".ToLower()))) { // login UnautorizedMethod // , .. , UnautorizedMethod - . // var accessToken = request.GetAccessToken(); var accountDbWorker = new AccountDbWorker(connection, null, DbWorkerCacheManager.GetCacheProvider(connection)); var checkAccountExists = accountDbWorker.CheckAccountExists(accessToken); if (checkAccountExists == false) { var res = new HttpResponseMessage(System.Net.HttpStatusCode.Unauthorized); return res; } else { // . AuthTokenManager.Instance.Refresh(request.GetTokenHeader()); } } else { //methods without any auth } // var response = await base.SendAsync(request, cancellationToken); return response; } } Next, the code of the desired controller is called, which calls the appropriate DAL core method. Any critical kernel method (which changes or scans data) is first looking for a user in the list of users by its accessToken. Next, we check the rights of a specific user and execute the main method code. It's all standard.
Version update
Since the application consists of a single web application, then updating the web part is quick and easy. Curious is the case with databases. We use the Code First approach, so that with any user request, all migrations will be inflated on his database.
In fact, migrations to all databases will be inflated even earlier (during the launch of the application). The fact is that we have a mechanism for sending notifications to the user by mail. Notifications are regular letters that can be sent to any users of the system depending on any data. We use for this server-side scripting programming language. At the start of the application, this service starts, which refers to all user databases in order to find out if there are letters to send. At this time, there is a rolling migration on all user databases.
Work speed
The result of all this work was that the amount of memory required in IIS for working with all applications was significantly reduced. I can’t give exact figures, but a hundred business applications of users (ie databases) easily fit into the server with 4GB of operatives, and it still fits much more. The system has ceased to sink from memory.
However, the performance of the CPU has not grown much. Profiling revealed a major problem. The system does not know anything in advance (at the compilation stage) about the tables to which the user makes queries. Even for the simplest query to the data on any table, it is necessary to perform a very large number of queries to the database of metadata. The results of these queries will generate a sql. The resulting sql will already return real data, it runs very quickly.
Next, we wondered if it was possible to somehow reduce the number of requests to the metadata schema. We received a negative answer. To build a query, you need to know the name of the table in the database, the names of all the columns of the table, the role of the current user. For each role you need to know the columns that it is allowed to see. A lot of additional data to determine the rows that she is allowed to see, I will not go into details, but there are actually a lot of different requests to different metadata tables. And all this metadata is needed. Getting the metadata was almost two orders of magnitude longer than the execution of the request itself.
Such places were not enough. To verify any rights, one or another metadata was needed. Having thought it over, we decided to cache all this metadata on the server. But this decision is ideologically more complicated than it might seem at first glance. The previous caches that I described contain very small sets of disconnected data. In fact, they contain simple maps (URL -> connectionstring, accessToken -> account + Date). And this cache is large, tightly coupled, long tunable, with a complex structure.
If we implement a caching system in the forehead, then we will get a tricky structure (so that we could have quick access to the data through the Dictionary by keys), and a complex code to fill it in. In all methods that modify metadata, you will have to call the RefreshCache method, and there are very few of such methods. It would be very unpleasant to forget to call such a method. The RefreshCache code itself with the implementation in the forehead is also very severely large and ugly. This is caused by the fact that it is impossible to write the entire structure, what we want to get in the giant Include, then request all the data from the database. This is unrealistically slow. As a result, you have to split the request into a bunch of small requests, then glue the NavigationProp in the code, it already works faster. As a result, when adding a new metadata entity to the system, a decent headache will arise: for all CRUD methods, call RefreshCache, file a new entity into this method, and stick it into all NavigationProp for all entities. Generally speaking, this did not please us, but it would help. If you see a good move, look for a better move .
We identified two inconsistent problems:
- Call the RefreshCache code manually when changing any meta entity.
- A cumbersome, poorly maintained, highly coherent cache-building code in RefreshCache.
The first problem was solved by introducing EntityFramework into the guts. We redefined the SaveChanges method of EntityFramework. Inside it we check if we have changed the entities we are interested in. If changed - we rebuild the cache.
Code of automatic tracking of changes of the necessary entities EntityFramework
/* , . String[] - , ( , )*/ static readonly Dictionary<Type, string[]> _trackedTypes = new Dictionary<Type, string[]>() { { typeof(Account), new string[] { GetPropertyName((Account a) => a.Settings) } }, //.. { typeof(Table), new string[0] }, }; // , static string GetPropertyName<T, P>(Expression<Func<T, P>> action) { var expression = (MemberExpression)action.Body; string name = expression.Member.Name; return name; } /*, */ string[] GetChangedValues(DbEntityEntry entry) { return entry.CurrentValues .PropertyNames .Where(n => entry.Property(n).IsModified) .ToArray(); } /* */ bool IsInterestingChange(DbEntityEntry entry) { Type entityType = ObjectContext.GetObjectType(entry.Entity.GetType()); if (_trackedTypes.Keys.Contains(entityType)) { switch (entry.State) { case System.Data.Entity.EntityState.Added: case System.Data.Entity.EntityState.Deleted: return true; case System.Data.Entity.EntityState.Detached: case System.Data.Entity.EntityState.Unchanged: return false; case System.Data.Entity.EntityState.Modified: return GetChangedValues(entry).Any(v => !_trackedTypes[entityType].Contains(v)); default: throw new NotImplementedException(); } } else return false; } public override int SaveChanges() { bool needRefreshCache = ChangeTracker .Entries() .Any(e => IsInterestingChange(e)); int answer = base.SaveChanges(); if (needRefreshCache) { if (Transaction.Current == null) { RefreshCache(null, null); } else { Transaction.Current.TransactionCompleted -= RefreshCache; Transaction.Current.TransactionCompleted += RefreshCache; } } return answer; } The second problem was solved in two stages. At the first stage, we wrote the very bad code. First, we wanted to see that the speed really increase dramatically. Secondly, we wanted to see the code with which we need to do something. The fastest code for getting all the necessary metadata, we have come down to getting lists of metadata entities without all Include. Then we did the gluing of all NavigationProp manually.
Bad Cache Code Example
// var taskColumns = Task.Factory.StartNewWithContext(() => { /* , isReadOnly , ..*/ using (var entities = new Context(connectionString, isReadOnly: true)) { return entities.Columns.ToList(); } }, connectionString); var taskTables = Task.Factory.StartNewWithContext(() => { using (var entities = new Context(connectionString, isReadOnly: true )) { return entities.Tables.ToList(); } }, connectionString); var columns = taskColumns.Result; var tables = taskTables.Result; /* Dictionary, ( )*/ var columnsDictByTableId = columns .GroupBy(c => c.TableId) .ToDictionary(c => c.Key, c => c.ToList()); foreach(var table in tables) { table.Columns = columnsDictByTableId[table.Id]; } The code for obtaining a complete list of all metadata entities is divided by threads. This is due to the fact that there are only a couple of large lists, all the time of receiving data essentially rests on them. This implementation simply reduces Ping. The problem with this code is that the more entities there are, the more connections there are between them. Growth is nonlinear. In general, the code works well, but did not want to write it. In the end, we decided to do everything through reflection (to implement the same algorithm as described above, but in a cycle for all properties and entities).
Generalized cacher
// private Task<List<T>> GetEntitiesAsync<T>(string connectionString, Func<SokolDWEntities, List<T>> getter) { var task = Task.Factory.StartNewWithContext(() => { using (var entities = new SokolDWEntities(connectionString, isReadOnly: true)) { return getter(entities); } }, connectionString); return task; } /// <summary> /// , /// NavigationProp /// . , Include EF, . /// , , , . /// . , , BaseEntity. /// BaseEntity [Required][Key][DatabaseGenerated(DatabaseGeneratedOption.Identity)] public long Id { get; set; } /// Dictionary ( ) /// </summary> /// <param name="entities"> , </param> private void SetProperties(params object[] entities) { // -> #entitiesByTypes[typeof(Account)] -> var entitiesByTypes = new Dictionary<Type, object>(); //dictsById[typeof(Account)][1] -> 1 var dictsById = new Dictionary<Type, Dictionary<long, BaseEntity>>(); //dictsByCustomAttr[typeof(Column)]["TableId"][1] -> , 1 var dictsByCustomAttr = new Dictionary<Type, Dictionary<string, Dictionary<long, object>>>(); //pluralFksMetadata[typeof(Table)] Table var pluralFksMetadata = new Dictionary<Type, Dictionary<PropertyInfo, ForeignKeyAttribute>>(); //needGroupByPropList[typeof(Column)] , Dictionary ( ) var needGroupByPropList = new Dictionary<Type, List<string>>(); // entitiesByTypes dictsById foreach (var entitySetObject in entities) { var listType = entitySetObject.GetType(); if (listType.IsGenericType && (listType.GetGenericTypeDefinition() == typeof(List<>))) { Type entityType = listType.GetGenericArguments().Single(); entitiesByTypes.Add(entityType, entitySetObject); if (typeof(BaseEntity).IsAssignableFrom(entityType)) { //dictsById BaseEntity ( ) var entitySetList = entitySetObject as IEnumerable<BaseEntity>; var dictById = entitySetList.ToDictionary(o => o.Id); dictsById.Add(entityType, dictById); } } else { throw new ArgumentException(); } } // pluralFksMetadata needGroupByPropList foreach (var entitySet in entitiesByTypes) { Type entityType = entitySet.Key; var virtualProps = entityType .GetProperties() .Where(p => p.GetCustomAttributes(true).Any(attr => attr.GetType() == typeof(ForeignKeyAttribute))) .Where(p => p.GetGetMethod().IsVirtual) .ToList(); // NavigationProp var pluralFKs = virtualProps .Where(p => typeof(IEnumerable).IsAssignableFrom(p.PropertyType)) .Where(p => entitiesByTypes.Keys.Contains(p.PropertyType.GetGenericArguments().Single())) .ToDictionary(p => p, p => (p.GetCustomAttributes(true).Single(attr => attr.GetType() == typeof(ForeignKeyAttribute)) as ForeignKeyAttribute)); pluralFksMetadata.Add(entityType, pluralFKs); foreach (var pluralFK in pluralFKs) { Type pluralPropertyType = pluralFK.Key.PropertyType.GetGenericArguments().Single(); if (!needGroupByPropList.ContainsKey(pluralPropertyType)) { needGroupByPropList.Add(pluralPropertyType, new List<string>()); } if (!needGroupByPropList[pluralPropertyType].Contains(pluralFK.Value.Name)) { needGroupByPropList[pluralPropertyType].Add(pluralFK.Value.Name); } } // NavigationProp var singularFKsDictWithAttribute = virtualProps .Where(p => entitiesByTypes.Keys.Contains(p.PropertyType)) .ToDictionary(p => p, p => entityType.GetProperty((p.GetCustomAttributes(true).Single(attr => attr.GetType() == typeof(ForeignKeyAttribute)) as ForeignKeyAttribute).Name)); var entitySetList = entitySet.Value as IEnumerable<object>; // (NavigationProp) foreach (var entity in entitySetList) { foreach (var singularFK in singularFKsDictWithAttribute) { var dictById = dictsById[singularFK.Key.PropertyType]; long? value = (long?)singularFK.Value.GetValue(entity); if (value.HasValue && dictById.ContainsKey(value.Value)) { singularFK.Key.SetValue(entity, dictById[value.Value]); } } } } MethodInfo castMethod = typeof(Enumerable).GetMethod("Cast"); MethodInfo toListMethod = typeof(Enumerable).GetMethod("ToList"); // dictsByCustomAttr foreach (var needGroupByPropType in needGroupByPropList) { var entityList = entitiesByTypes[needGroupByPropType.Key] as IEnumerable<object>; foreach (var propName in needGroupByPropType.Value) { var prop = needGroupByPropType.Key.GetProperty(propName); var groupPropValues = entityList .ToDictionary(e => e, e => (long?)prop.GetValue(e)); var castMethodSpecific = castMethod.MakeGenericMethod(new Type[] { needGroupByPropType.Key }); var toListMethodSpecific = toListMethod.MakeGenericMethod(new Type[] { needGroupByPropType.Key }); var groupByValues = entityList .GroupBy(e => groupPropValues[e], e => e) .Where(e => e.Key != null) .ToDictionary(e => e.Key.Value, e => toListMethodSpecific.Invoke(null, new object[] { castMethodSpecific.Invoke(null, new object[] { e }) })); if (!dictsByCustomAttr.ContainsKey(needGroupByPropType.Key)) { dictsByCustomAttr.Add(needGroupByPropType.Key, new Dictionary<string, Dictionary<long, object>>()); } dictsByCustomAttr[needGroupByPropType.Key].Add(propName, groupByValues); } } // (NavigationProp) foreach (var pluralFkMetadata in pluralFksMetadata) { if (!dictsById.ContainsKey(pluralFkMetadata.Key)) continue; var entityList = entitiesByTypes[pluralFkMetadata.Key] as IEnumerable<object>; foreach (var entity in entityList) { var baseEntity = (BaseEntity)entity; foreach (var fkProp in pluralFkMetadata.Value) { var dictByCustomAttr = dictsByCustomAttr[fkProp.Key.PropertyType.GetGenericArguments().Single()]; if (dictByCustomAttr.ContainsKey(fkProp.Value.Name)) { if(dictByCustomAttr[fkProp.Value.Name].ContainsKey(baseEntity.Id)) fkProp.Key.SetValue(entity, dictByCustomAttr[fkProp.Value.Name][baseEntity.Id]); } } } } } //Without locking private DbWorkerCacheData RefreshNotSafe(string connectionString) { GlobalHost.ConnectionManager.GetHubContext<AdminHub>().Clients.All.cacheRefreshStart(); //get data parallel var accountsTask = GetEntitiesAsync(connectionString, e => e.Accounts.ToList()); //.. var tablesTask = GetEntitiesAsync(connectionString, e => e.Tables.ToList()); //wait data var accounts = accountsTask.Result; //.. var tables = tablesTask.Result; DAL.DbWorkers.Code.Extensions.SetProperties ( accounts, /*..*/ tables ); /* " ", O(1) */ } Before writing this flexible caching method, the RefreshCache runtime on the largest database we have (600+ user tables, 100+ roles) took about 10 seconds. After the implementation of this method - 11.5 seconds. In fact, all the additional time is taken to refer to the fields through reflection, but the time delay is small. Perhaps part of the time began to occupy the fact that now all NavigationProps are initiated from all entities, but not all have been used before. The advantage of this approach is that you can now write table.Columns.First (). Table.Columns ... Ie All references within this set of entities are analyzed; you can write code without fear of a sudden NullReferenceException.
The introduction of the cache described above significantly increased the speed of the system. The load on the CPU has become minimal. Even on a single-core machine, everything works fast for many hundreds of users with minimal CPU usage.
Data integrity
When transferring customers to the service, the question of the safety of their data became more acute. When we delivered boxed solutions (gave away bin), then questions about data integrity did not arise. Clients had their own servers, their admins, their backups.
In the cloud version, we act very simply. We have only two types of entities that the client is afraid of losing. This is his data in the database that the user enters, and the files that he attaches. Both we store in Amazon S3. Files are basically stored right there, uploaded there via a web server, not stored on a local disk. When a user downloads a file, the web server itself downloads it from Amazon and gives it to the client. Every night, backups of all paid databases are loaded into Amazon. Once a month I download all the backup database to the local machine.
From the point of view of files, data loss is possible when they are lost in Amazon S3. Data from the database should disappear from Amazon S3, the web server and my local machine.
findings
Thus, the text described above shows how we made the architecture productive, scalable and secure. This approach allowed our managers to create prototypes of applications (even almost finished applications) without programmers. Maintenance of the entire project began to take much less time. We managed to greatly increase the speed of the system and cheapen the server.
Why did I write this text
This is the most complex and interesting system that I personally have ever done. Only a small but important aspect is described here (sharing of resources between user applications). In fact, the system is quite large and multifunctional. Writing this post helped to systematize and realize what we did and why. I think that this text will be interesting to those who are thinking of summarizing their achievements to the level of service. I believe that our problems and solutions are not unique. Maybe someone will criticize some of the solutions, suggest something more correct / fast / flexible. Ultimately this can make us stronger. And, of course, we wanted to be heard about us. Suddenly, after reading this post, you will want to log in to our system and look at it.Now we are launching an affiliate program for developers and IT integrators (in my profile the site of our company is indicated). We want our accounting system designer to be useful to others.
UPD 1. Added questionnaire (there was no such option in the sandbox).
Source: https://habr.com/ru/post/327240/
All Articles