How it works in the java world. Concurrentmap
The basic principle of programming is: do not reinvent the wheel. But sometimes, to understand what is happening and how to use the tool correctly, we need to do it. Today we invent ConcrurrentHashMap.
First we need 2 things. Let's start with 2 tests - the first one will say that our implementation does not have data races (in fact, we need to check whether our test is correct also by testing a deliberately incorrect implementation), we will use the second test to test performance in terms of throughput.
Consider only a few methods from the Map interface:
public interface Map<K, V> { V put(K key, V value); V get(Object key); V remove(Object key); int size(); } Thread-safety correctness test
It is almost impossible to write a thread safety test quite exhaustively, you need to take into account all aspects defined in Chapter 17 of the JLS , moreover, the test largely depends on the hardware memory model or the implementation of the JVM.
For the thread-safe correctness test, we use one of the ready-made stress test libraries, such as jcstress , which will run your code, trying to find inconsistencies in the data. Although jcstress is still marked as experimental, it is the best choice. Why is it difficult to write your own concurrency test? Watch Shipilev's lecture .
I use jstress-gradle-plugin to run jstress. The complete source code can be found how-it-works-concurrent-map .
public class ConcurrentMapThreadSafetyTest { @State public static class MapState { final Map<String, Integer> map = new HashMap<>(3); } @JCStressTest @Description("Test race map get and put") @Outcome(id = "0, 1", expect = ACCEPTABLE, desc = "return 0L and 1L") @Outcome(expect = FORBIDDEN, desc = "Case violating atomicity.") public static class MapPutGetTest { @Actor public void actor1(MapState state, LongResult2 result) { state.map.put("A", 0); Integer r = state.map.get("A"); result.r1 = (r == null ? -1 : r); } @Actor public void actor2(MapState state, LongResult2 result) { state.map.put("B", 1); Integer r = state.map.get("B"); result.r2 = (r == null ? -1 : r); } } @JCStressTest @Description("Test race map check size") @Outcome(id = "2", expect = ACCEPTABLE, desc = "size of map = 2 ") @Outcome(id = "1", expect = FORBIDDEN, desc = "size of map = 1 is race") @Outcome(expect = FORBIDDEN, desc = "Case violating atomicity.") public static class MapSizeTest { @Actor public void actor1(MapState state) { state.map.put("A", 0); } @Actor public void actor2(MapState state) { state.map.put("B", 0); } @Arbiter public void arbiter(MapState state, IntResult1 result) { result.r1 = state.map.size(); } } } In the first test of MapPutGetTest, we have two threads running simultaneously the methods actor1 and actor2, respectively, both of them put some value in the map and check them back, if there is no data race, both streams should see the specified values.
In the second MapSizeTest, we simultaneously place two different keys in the map and after checking the size - if there is no data race - the expected result should be = 2.
In order to check the correctness of the test, we will execute it on a deliberately non-secure HashMap - we must observe the violation of atomicity. If we run the test on a thread-safe ConcurrentHashMap, we should not see a violation of consistency.
Results with HashMap:
[FAILED] ru.skuptsov.concurrent.map.test.ConcurrentMapTest.MapPutGetTest Observed state Occurrences Expectation Interpretation -1, 1 293,867 FORBIDDEN Case violating atomic 0, -1 282,190 FORBIDDEN Case violating atomic 0, 1 28,013,763 ACCEPTABLE return 0 and 1 [FAILED] ru.skuptsov.concurrent.map.test.ConcurrentMapTest.MapSizeTest Observed state Occurrences Expectation Interpretation 1 1,434,783 FORBIDDEN size of map = 1 race 2 11,733,097 ACCEPTABLE size of map = 2 In the thread-safe HashMap, we see some statistical number of inconsistent results, both tests failed.
Results with thread-safe ConcurrentHashMap:
[OK] ru.skuptsov.concurrent.map.test.ConcurrentMapTest.MapPutGetTest Observed state Occurrences Expectation Interpretation 0, 1 20,195,000 ACCEPTABLE [OK] ru.skuptsov.concurrent.map.test.ConcurrentMapTest.MapSizeTest Observed state Occurrences Expectation Interpretation 2 6,573,730 ACCEPTABLE size of map = 2 ConcurrentHashMap passed the test, at least we can recognize that our test can detect some simple concurrency problems. The same results can be checked for Collection.synchronizedMap and HashTable.
Fitst ConcurrentHashMap attempt
The first naive approach is to simply synchronize each access to internal structures — an array of buckets.
In fact, we can write some parallel shell over the transmitted map provider. Similarly, java.util.Collections.synchronizedMap, Hashtable and guava synchronizedMultimap act.
public class SynchrinizedHashMap<K, V> extends BaseMap<K, V> implements Map<K, V>, IMap<K, V> { private final Map<K, V> provider; private final Object monitor; public SynchronizedHashMap(Map<K, V> provider) { this.provider = provider; monitor = this; } @Override public V put(K key, V value) { synchronized (monitor) { return provider.put(key, value); } } @Override public V get(Object key) { synchronized (monitor) { return provider.get(key); } } @Override public int size() { synchronized (monitor) { return provider.size(); } } } Changes in the non-volatile map-provider will be visible between the streams, according to the documentation:
There is a synchronized method for the same object. This object is visible to all threads.
Our simplest implementation runs parallel tests, but at what price? In each method there can be only one thread at the same time, even if we work with different keys, therefore with multi-threaded load we should not expect high performance. Let's measure it.
Performance test
For performance testing, we will use the jmh library.
@State(Scope.Thread) @Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS) @Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS) @Fork(3) @BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(MICROSECONDS) public class ConcurrentMapBenchmark { private Map<Integer, Integer> map; @Param({"concurrenthashmap", "hashtable", "synchronizedhashmap"}) private String type; @Param({"1", "10"}) private Integer writersNum; @Param({"1", "10"}) private Integer readersNum; private final static int NUM = 1000; @Setup public void setup() { switch (type) { case "hashtable": map = new Hashtable<>(); break; case "concurrenthashmap": map = new ConcurrentHashMap<>(); break; case "synchronizedhashmap": map = new SynchronizedHashMap<>(new HashMap<>()); break; } } @Benchmark public void test(Blackhole bh) throws ExecutionException, InterruptedException { List<CompletableFuture> futures = new ArrayList<>(); for (int i = 0; i < writersNum; i++) { futures.add(CompletableFuture.runAsync(() -> { for (int j = 0; j < NUM; j++) { map.put(j, j); } })); } for (int i = 0; i < readersNum; i++) { futures.add(CompletableFuture.runAsync(() -> { for (int j = 0; j < NUM; j++) { bh.consume(map.get(j)); } })); } CompletableFuture.allOf(futures.toArray(new CompletableFuture[1])).get(); } } 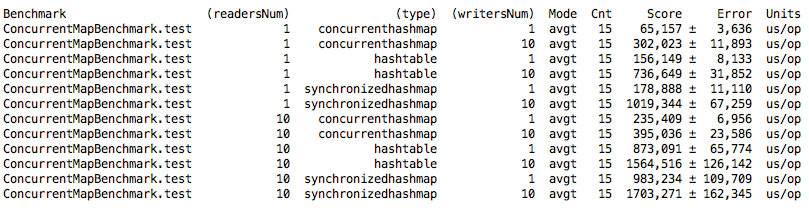
We made sure that the performance of our SynchronizedHashMap is almost the same as java's HashTable, and it is 2 times worse than ConcurrentHashMap. Let's try to improve performance.
Lock-striping ConcurrentHashMap attempt
The first improvement can be based on the idea that instead of blocking access to the entire map, it is better to synchronize access only if the threads access the same baket, where the bake index = key.hashCode ()% array.length. This method is called lock striping or fine-grained synchronization, see The Art of Multiprocessor Programming .
For an array of buckets, we will need an array of locks, when starting, the size of the array of locks should be equal to the internal size of the array - this is important, because we don’t want a situation where 2 locka are responsible for one bucket of the array.
For simplicity, consider a map with an unchangeable array of buckets - this means that we will not be able to expand the initial capacity (if N >> initialCapacity we lose the O (1) map insert insertion guarantee. We also do not need loadFactor). Expandable cocurrent map is a separate large topic.
public class LockStripingArrayConcurrentHashMap<K, V> extends BaseMap<K, V> implements Map<K, V> { private final AtomicInteger count = new AtomicInteger(0); private final Node<K, V>[] buckets; private final Object[] locks; @SuppressWarnings({"rawtypes", "unchecked"}) public LockStripingArrayConcurrentHashMap(int capacity) { locks = new Object[capacity]; for (int i = 0; i < locks.length; i++) { locks[i] = new Object(); } buckets = (Node<K, V>[]) new Node[capacity]; } @Override public int size() { return count.get(); } @Override public V get(Object key) { if (key == null) throw new IllegalArgumentException(); int hash = hash(key); synchronized (getLockFor(hash)) { Node<K, V> node = buckets[getBucketIndex(hash)]; while (node != null) { if (isKeyEquals(key, hash, node)) { return node.value; } node = node.next; } return null; } } @Override public V put(K key, V value) { if (key == null || value == null) throw new IllegalArgumentException(); int hash = hash(key); synchronized (getLockFor(hash)) { int bucketIndex = getBucketIndex(hash); Node<K, V> node = buckets[bucketIndex]; if (node == null) { buckets[bucketIndex] = new Node<>(hash, key, value, null); count.incrementAndGet(); return null; } else { Node<K, V> prevNode = node; while (node != null) { if (isKeyEquals(key, hash, node)) { V prevValue = node.value; node.value = value; return prevValue; } prevNode = node; node = node.next; } prevNode.next = new Node<>(hash, key, value, null); count.incrementAndGet(); return null; } ... } } private boolean isKeyEquals(Object key, int hash, Node<K, V> node) { return node.hash == hash && node.key == key || (node.key != null && node.key.equals(key)); } private int hash(Object key) { return key.hashCode(); } private int getBucketIndex(int hash) { return hash % buckets.length; } private Object getLockFor(int hash) { return locks[hash % locks.length]; } private static class Node<K, V> { final int hash; K key; V value; Node<K, V> next; Node(int hash, K key, V value, Node<K, V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } } } It is important that all class fields are final - this ensures safe-publication and that no one will call methods until the final creation of an object is important to us because we have some initialization in the constructor.
Source code can be found here .
Test results:
We see that fine-grained synchronization implementation is better than general locking. The results, with one reader and one writer, are almost the same compared to ConcurrentHashMap, but when the number of streams increases, the difference is greater, especially where there are many readers.
Lock free concurrent hash map attempt
Honestly, synchronization is not a parallel programming method, because it puts threads in a sequential queue, making it wait for another thread to complete. And the additional cost of system context synchronization increases with an increase in the number of waiting threads, but all we want to do is a small number of instructions for changing the value of the map key.
We define some requirements for a new implementation of hashmap, which in theory should improve our implementation. And the requirements are as follows:
- If we have 2 threads that work with different keys (write or read), we don’t want any synchronization between them (word tearing in java is denied - access to two different array fields is thread safe)
- If several threads work with the same key (write and read), we don’t want to reorder operations ( more on the causes of problems in the modern cache structure ) and we need guarantees for the threads between threads, otherwise one thread may not notice the changed value by another flow. But we don't want to block the read stream and wait for the write stream to complete.
- We do not want to block several readers by one key if there is no one writing thread among them.
Let's concentrate on points 2 and 3. In fact, we can make the map read completely unblocked if we can (1) volatile read array of buckets, and then go inside the bucket with (2) volatile read next node linked list until we find the desired and volatile read of the node value itself.
For (2), we can simply mark the next and value fields in Node as volatile.
For (1) there is no such thing as a volatile array, even if the array is declared as volatile, it does not provide volatile semantics when reading or writing elements, while simultaneously accessing the k-th element of the array, external synchronization is required, volatile is only link to array We can use AtomicReferenceArray for this purpose, but it accepts only Object [] arrays. Alternatively, consider using Unsafe for a volatile array read and lock-free write. The same method is used in AtomicReferenceArray and ConcurrentHashMap.
@SuppressWarnings("unchecked") // read array value by index private <K, V> Node<K, V> volatileGetNode(int i) { return (Node<K, V>) U.getObjectVolatile(buckets, ((long) i << ASHIFT) + ABASE); } // cas set array value by index private <K, V> boolean compareAndSwapNode(int i, Node<K, V> expectedNode, Node<K, V> setNode) { return U.compareAndSwapObject(buckets, ((long) i << ASHIFT) + ABASE, expectedNode, setNode); } private static final sun.misc.Unsafe U; // Node[] header shift private static final long ABASE; // Node.class size shift private static final int ASHIFT; static { try { // get unsafe by reflection - it is illegal to use not in java lib Constructor<Unsafe> unsafeConstructor = Unsafe.class.getDeclaredConstructor(); unsafeConstructor.setAccessible(true); U = unsafeConstructor.newInstance(); } catch (NoSuchMethodException | InstantiationException | InvocationTargetException | IllegalAccessException e) { throw new RuntimeException(e); } Class<?> ak = Node[].class; ABASE = U.arrayBaseOffset(ak); int scale = U.arrayIndexScale(ak); ASHIFT = 31 - Integer.numberOfLeadingZeros(scale); } In volatile getNode, we can now safely read values without locks.
Let's write lock-free V get (Object key) now:
public V get(Object key) { if (key == null) throw new IllegalArgumentException(); int hash = hash(key); Node<K, V> node; // volatile read of bucket head at hash index if ((node = volatileGetNode(getBucketIndex(hash))) != null) { // check first node if (isKeyEquals(key, hash, node)) { return node.value; } // walk through the rest to find target node while ((node = node.next) != null) { if (isKeyEquals(key, hash, node)) return node.value; } } return null; } In the first attempt there was a large memory-overhead with a lock pool - in fact, we can use the same fine-grained approach with no additional memory — just lock on the first node in the bucket, if it exists. If it does not exist, we cannot block on a non-existent element and need some lock-free method to set the header node — we have already written this method above — the compareAndSwapNode method.
@Override public V put(K key, V value) { if (key == null || value == null) throw new IllegalArgumentException(); int hash = hash(key); // no resize in this implementation - so the index will not change int bucketIndex = getBucketIndex(hash); // cas loop trying not to miss while (true) { Node<K, V> node; // if bucket is empty try to set new head with cas if ((node = volatileGetNode(bucketIndex)) == null) { if (compareAndSwapNode(bucketIndex, null, new Node<>(hash, key, value, null))) { // if we succeed to set head - then break and return null count.increment(); break; } } else { // head is not null - try to find place to insert or update under lock synchronized (node) { // check if node have not been changed since we got it // otherwise let's go to another loop iteration if (volatileGetNode(bucketIndex) == node) { V prevValue = null; Node<K, V> n = node; while (true) { ... simply walk through list under lock and update or insert value... } return prevValue; } } } } return null; } Full source code here .
Let's test its performance: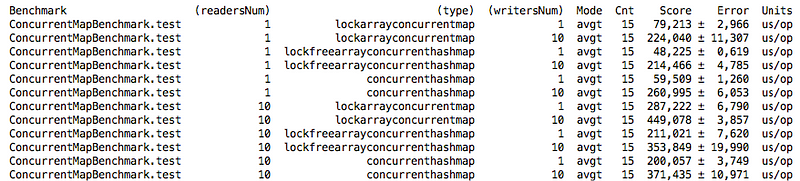
In some cases, we are even better than ConcurrentHashMap, but this is not a completely fair comparison. Because ConcurrentHashMap does lazy table initialization at load time and resize at least once at the boundary element threshold = initialCapacity * loadFactor. If we run the test again with the initialCapacity elements initialized! = N (= N / 6), the results will differ slightly:

This happened due to the fact that ConcurrentHashMap increases the initial size of the array of buckets and spends less time getting items by key, due to a decrease in the length of the linked list in the bucket.
It should be noted that we did not get a full-non-bloking data structure - just like ConcurrentHashMap, although all we need is just a linked list without locks, but with resizing and simultaneously modifying data this task is not so simple. - read here .
The original java 8 ConcurrentHashMap has a number of improvements that we did not mention, for example:
- Lazy initialization of the bucket table, which minimizes the memory footprint before first use
- Concurrent resizing bakeset array
- Counting items using LongAdder.
- Special types of nodes (starting from 1.8) - TreeBins, if the list length inside the bake grows larger than TREEIFY_THRESHOLD = 8 - the bake becomes a balanced tree with the worst search by key (O (log (Nbucket_size)))
It should be noted that the implementation of ConcurrentHashMap in Java 1.8 has been significantly changed from 1.7. In 1.7, this was the idea of segments, where the number of segments is equal to the level of parallelism. In java 8, an array of buckets is a single array.
')
Source: https://habr.com/ru/post/327186/
All Articles