Internal mechanisms of TCP, affecting the download speed: part 2
In the first part, we disassembled the “triple handshake” of TCP and some technologies - TCP Fast Open, flow control and overload and window scaling. In the second part, we learn what TCP Slow Start is, how to optimize the data transfer rate and increase the initial window, and also collect all the recommendations for optimizing the TCP / IP stack together.
Slow start (Slow-Start)
Despite the presence of flow control in TCP, network collapse accumulation was a real problem in the mid-80s. The problem was that although the flow control did not allow the sender to “drown” the recipient in the data, there was no mechanism that would not allow it to be done with the network. After all, neither the sender nor the recipient know the width of the channel at the time of the beginning of the connection, and therefore they need some kind of mechanism to adapt the speed to changing conditions in the network.
For example, if you are at home and download a large video from a remote server that has downloaded all your downlink to ensure maximum speed. Then another user from your home decided to download a voluminous software update. The available channel for video suddenly becomes much smaller, and the server sending the video should change its data sending speed. If it continues at the same speed, the data will simply “pile up” on some intermediate gateway, and the packets will be “dropped”, which means inefficient use of the network.
')
In 1988, Van Jacobson and Michael J. Karels developed several algorithms to combat this problem: slow start, overload prevention, fast retransmission, and fast recovery. They soon became an indispensable part of the TCP specification. It is believed that thanks to these algorithms, it was possible to avoid global problems with the Internet in the late 80s / early 90s, when traffic grew exponentially.
To understand how a slow start works, let’s go back to the example of a client in New York trying to download a file from a server in London. First, a triple handshake is performed, during which the parties exchange their values of reception windows in ACK packets. When the last ACK packet has gone to the network, you can begin the exchange of data.
The only way to estimate the channel width between the client and server is to measure it during data exchange, and this is exactly what a slow start does. First, the server initializes a new window overload variable (cwnd) for a TCP connection and sets its value conservatively, according to the system value (on Linux, this is initcwnd).
The value of the variable cwnd does not exchange between the client and the server. This will be the local variable for the server in London. Next, a new rule is introduced: the maximum amount of data “in transit” (not confirmed via ACK) between the server and the client should be the smallest value of rwnd and cwnd. But how can the server and the client "agree" on the optimal values of their windows overload. After all, the conditions in the network are constantly changing, and I would like the algorithm to work without the need to adjust each TCP connection.
Solution: start the transfer with a slow speed and increase the window as the reception of packets is confirmed. This is a slow start.
The initial value of cwnd was initially set to 1 network segment. In RFC 2581, this was changed to 4 segments, and then to RFC 6928 - up to 10 segments.
Thus, the server can send up to 10 network segments to the client, after which it must stop sending and wait for confirmation. Then, for each received ACK, the server can increase its cwnd value by 1 segment. That is, for each package confirmed through the ACK, two new packages can be sent. This means that the server and client quickly “occupy” the available channel.
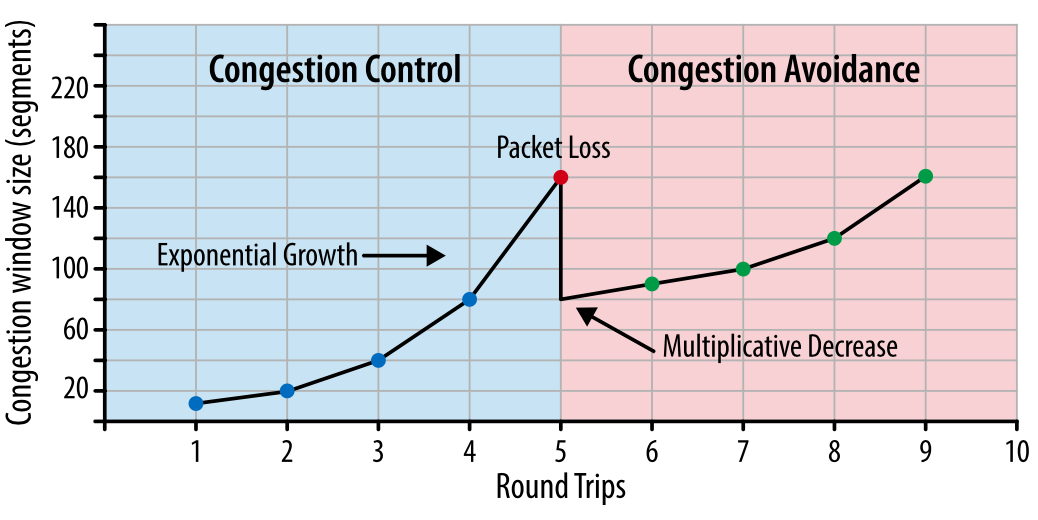
Fig. 1. Control overloading and its prevention.
How does the slow start affect the development of browser applications? Since every TCP connection must go through a slow start phase, we cannot immediately use the entire available channel. It all starts with a small window of overload, which gradually grows. Thus, the time it takes to reach a given transmission rate is a function of the round-trip delay and the initial value of the overload window.
The time to reach the value of cwnd equal to N.
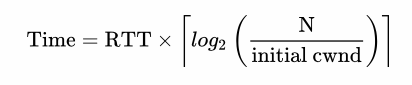
To experience how this will be in practice, let's take the following assumptions:
- Client and server reception windows: 65,535 bytes (64 KB)
- The initial value of the window overload: 10 segments
- Circular delay between London and New York: 56 milliseconds
Despite the receive window of 64 KB, the bandwidth of a TCP connection is initially limited to the overload window. To reach the limit of 64 KB, the overload window should grow to 45 segments, which will take 168 milliseconds.

The fact that the client and server can be able to exchange megabits per second between themselves does not matter for a slow start.

Fig. 2. The growth of the window overload.
To reduce the time it takes to reach the maximum overload window, you can reduce the time required for packets on the round trip — that is, locate the server geographically closer to the client.
A slow start has little effect on downloading large files or streaming video, since the client and server have reached the maximum overload window for a few tens or hundreds of milliseconds, but this will be a single TCP connection.
However, for many HTTP requests, when the target file is relatively small, the transfer may end before the maximum congestion window is reached. That is, web application performance is often limited by the round-trip time between the server and the client.
Restart Slow Start (Slow-Start Restart - SSR)
In addition to controlling the transmission speed in new connections, TCP also provides a slow start restart mechanism, which resets the congestion window value if the connection has not been used for a specified period of time. The logic here is that the network conditions could change during the inactivity of the connection, and to avoid overloading, the window value is reset to a safe value.
Not surprisingly, SSR can have a serious impact on the performance of long-lived TCP connections that may temporarily be "idle", for example, due to user inactivity. Therefore, it is better to disable SSR on the server in order to improve the performance of long-lived connections. On Linux, you can check the SSR status and disable it with the following commands:
$> sysctl net.ipv4.tcp_slow_start_after_idle $> sysctl -w net.ipv4.tcp_slow_start_after_idle = 0
To demonstrate the effect of a slow start on transferring a small file, let's imagine that a client from New York requested a 64 KB file from a server in London over a new TCP connection with the following parameters:
- Circular delay: 56 milliseconds
- Client and server throughput: 5 Mbps
- Client and server reception window: 65,535 bytes
- The initial value of the window overload: 10 segments (10 x 1460 bytes = ~ 14 KB)
- Processing time on the server to generate a response: 40 milliseconds
- Packages are not lost, ACK per packet, GET request fits into 1 segment
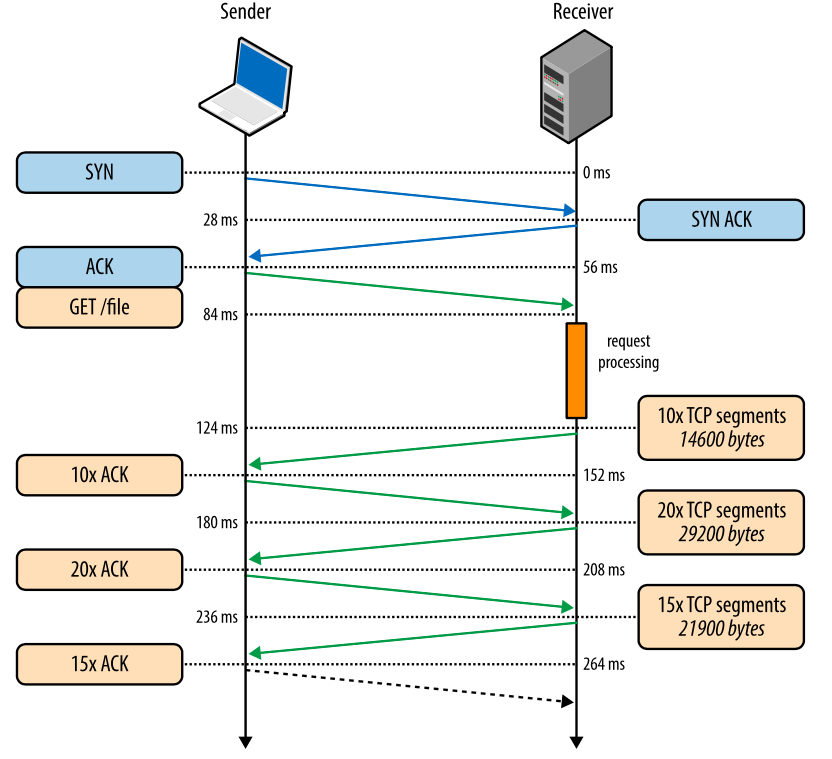
Fig. 3. Downloading a file through a new TCP connection.
- 0 ms: client starts TCP handshake with SYN packet
- 28 ms: the server sends a SYN-ACK and sets its size rwnd
- 56 ms: the client confirms the SYN-ACK, sets its size rwnd and immediately sends an HTTP GET request
- 84 ms: the server receives an HTTP request
- 124 ms: the server finishes creating a 64 KB response and sends 10 TCP segments, then waits for an ACK (the initial value of cwnd is 10)
- 152 ms: the client receives 10 TCP segments and responds with an ACK to each
- 180 ms: the server increases cwnd for each received ACK and sends 20 TCP segments
- 208 ms: the client receives 20 TCP segments and responds with an ACK to each
- 236 ms: the server increases cwnd for each received ACK and sends the 15 remaining TCP segments
- 264 ms: the client receives 15 TCP segments and responds with an ACK to each
264 milliseconds takes the transfer of the file size of 64 KB through a new TCP connection. Now let's imagine that the client reuses the same connection and makes the same request again.

Fig. 4. Downloading a file through an existing TCP connection.
- 0 ms: the client sends an HTTP request
- 28 ms: server receives an HTTP request
- 68 ms: the server generates a 64 KB response, but the value of cwnd is already greater than the 45 segments required to send this file. Therefore, the server sends all segments at once.
- 96 ms: the client receives all 45 segments and responds with an ACK to each
The same request made through the same connection, but without spending time on the handshake and increasing the bandwidth through a slow start, is now executed in 96 milliseconds, that is, 275% faster!
In both cases, the fact that the client and server use a channel with a bandwidth of 5 Mbit / s did not have any effect on the download time of the file. Only overload window sizes and network latency were limiting factors. Interestingly, the difference in performance when using new and existing TCP connections will increase if the network delay increases.
As soon as you are aware of the problems with delays when creating new connections, you will immediately want to use such optimization methods as keepalive, pipelining of packages (R) and multiplexing.
Increasing the initial value of the TCP overload window
This is the easiest way to increase performance for all users or applications using TCP. Many operating systems already use the new value of 10 in their updates. For Linux 10, the default value for the window overload, starting with kernel version 2.6.39.
Overload prevention
It is important to understand that TCP uses packet loss as a feedback mechanism that helps regulate performance. A slow start creates a connection with a conservative overload window value and doubles the amount of data transferred at a time until it reaches the receiver's receive window, the sshtresh system threshold or until packets start to be lost, after which the overload prevention algorithm is enabled.
Overload prevention is built on the assumption that packet loss is an indicator of network congestion. Somewhere in the paths of packets on the link or on the router, packets have accumulated, and this means that you need to reduce the overload window in order to prevent further traffic from “blocking” the network.
After the overload window is reduced, a separate algorithm is applied to determine how the window should further grow. Sooner or later, another packet loss will occur, and the process will be repeated. If you have ever seen sawing traffic through a TCP connection, this is precisely because overload control and prevention algorithms adjust the overload window in accordance with the packet losses in the network.
It is worth noting that the improvement of these algorithms is an active area of both scientific research and the development of commercial products. There are options that work better on networks of a particular type or for transferring a particular type of file, and so on. Depending on which platform you are running, you use one of many options: TCP Tahoe and Reno (original implementation), TCP Vegas, TCP New Reno, TCP BIC, TCP CUBIC (default on Linux) or Compound TCP (by default on windows) and many others. Regardless of the specific implementation, the effects of these algorithms on the performance of web applications are similar.
Proportional speed reduction for TCP
Determining the best way to recover from packet loss is not a trivial task. If you are too “aggressive” in responding to this, the accidental loss of the packet will have an excessively negative effect on the connection speed. If you do not respond quickly enough, then most likely it will cause further packet loss.
Initially, TCP used the algorithm of multiple decrease and successive increase (Multiplicative Decrease and Additive Increase - AIMD): when a packet is lost, the overload window is halved and gradually increases by a specified amount with each round trip. In many cases, AIMD proved to be an overly conservative algorithm, so new ones were developed.
Proportional Rate Reduction (PRR) is a new algorithm described in RFC 6937, whose goal is faster recovery after packet loss. According to Google’s measurements, where the algorithm was developed, it reduces the network delay by an average of 3-10% in packet loss connections. PPR is enabled by default in Linux 3.2 and above.
The product of the channel width by delay (Bandwidth-Delay Product - BDP)
The built-in mechanisms for dealing with congestion in TCP have an important consequence: the optimal window values for the receiver and sender should vary according to the round-trip delay and the target data transfer rate. Recall that the maximum number of unconfirmed packets "in transit" is defined as the smallest value from the receive and overload windows (rwnd and cwnd). If the sender has exceeded the maximum number of unconfirmed packets, then it must stop the transmission and wait until the recipient confirms a certain number of packets so that the sender can restart the transmission. How long should he wait? This is determined by the circular delay.
BDP determines how much data can be “on the go”
If the sender often has to stop and wait for the ACK-confirmation of previously sent packets, this will create a gap in the data stream, which will limit the maximum connection speed. To avoid this problem, window sizes should be set large enough so that you can send data, awaiting receipt of ACK confirmations on previously sent packets. Then the maximum transfer rate will be possible, no breaks. Accordingly, the optimal window size depends on the speed of the circular delay.
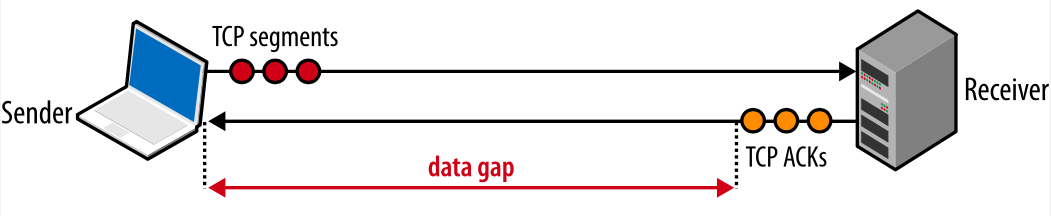
Fig. 5. The gap in the transmission due to the small values of the windows.
How big should the receiving and overload windows be? Let us examine by example: let cwnd and rwnd be 16 KB, and the round-trip delay is 100 ms. Then:

It turns out that whatever the channel width between the sender and the receiver, such a connection will never give a speed greater than 1.31 Mbit / s. To achieve greater speed, you must either increase the value of the windows, or reduce the circular delay.
Similarly, we can calculate the optimal value of the windows, knowing the circular delay and the required channel width. We assume that the time remains the same (100 ms), and the sender's channel width is 10 Mbps, and the receiver is on a high-speed channel at 100 Mbps. Assuming that the network between them has no problems at intermediate sites, we get for the sender:
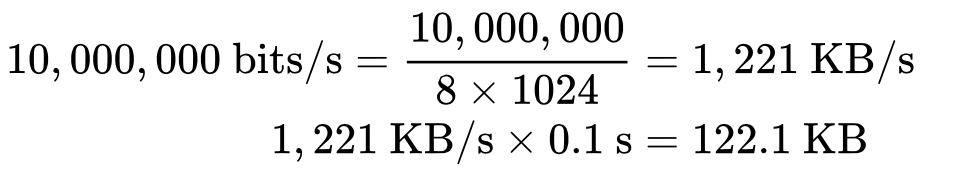
The window size should be at least 122.1 KB in order to fully occupy the channel at 10 Mbps. Recall that the maximum receive window size in TCP is 64 KB, unless window scaling is enabled (RFC 1323). Another reason to double check the settings!
The good news is that window size matching is automatically done in the network stack. The bad news is that this can sometimes be a limiting factor. If you have ever wondered why your connection transmits at a rate that makes up only a small fraction of the available channel width, this is most likely due to the small size of the windows.
BDP in high-speed local networks
Circular delay can be a bottleneck in local networks. To achieve 1 Gbit / s with a circular delay of 1 ms, you must have an overload window of not less than 122 KB. The calculations are similar to those shown above.
Head-of-line blocking (HOL blocking)
Although TCP is a popular protocol, it is not the only one, and not always the most suitable for each particular case. Its features such as delivery in order are not always necessary, and can sometimes increase the delay.
Each TCP packet contains a unique sequence number, and the data must arrive in order. If one of the packets has been lost, then all subsequent packets are stored in the receiver's TCP buffer until the lost packet is resubmitted and reaches the receiver. Since this happens in the TCP layer, the application does not “see” these retransmissions or the queue of packets in the buffer, and simply waits until the data is available. All that "sees" the application - this is the delay that occurs when reading data from the socket. This effect is known as blocking the turn start.
Locking the start of the queue frees applications from having to reorder the packets, which simplifies the code. But on the other hand, there is an unpredictable delay in the arrival of packets, which negatively affects the performance of applications.

Fig. 6. Block the start of the queue.
Some applications may not require guaranteed delivery or order delivery. If each package is a separate message, then delivery in order is not needed. And if each new message overwrites the previous ones, then the guaranteed delivery is also not needed. But in TCP there is no configuration for such cases. All packages are delivered in turn, and if some is not delivered, it is sent again. Applications for which latency is critical can use alternative transport, for example, UDP.
Packet loss is normal
Packet loss is even needed in order to provide better TCP performance. The lost packet works as a feedback mechanism that allows the receiver and sender to change the sending rate to avoid network overload and minimize latency.
Some applications can "cope" with the loss of the package: for example, to play audio, video or to transfer the status in the game, guaranteed delivery or delivery in order are not required. Therefore, WebRTC uses UDP as the primary transport.
If a packet loss occurred while playing audio, the audio codec can simply insert a small gap into the playback and continue processing incoming packets. If the gap is small, the user may not notice it, and waiting for the delivery of a lost packet may result in a noticeable delay in playback, which will be much worse for the user.
Similarly, if the game transfers its states, then there is no point in waiting for a packet describing the state at time T-1, if we already have information about the state at time T.
TCP optimization
TCP is an adaptive protocol designed to maximize network utilization. Optimization for TCP requires an understanding of how TCP responds to network conditions. Applications may need their own method of providing specified quality (QoS) to ensure stable operation for users.
The requirements of applications and the numerous features of TCP algorithms make their interconnection and optimization in this area a huge field for study. In this article, we just touched on some factors that affect TCP performance. Additional mechanisms such as selective acknowledgment (SACK), deferred acknowledgment, fast retransmission and many others complicate the understanding and optimization of TCP sessions.
Although the specific details of each algorithm and feedback mechanism will continue to change, the key principles and their consequences will remain:
- The triple TCP handshake carries a serious delay;
- TCP slow start applies to each new connection;
- TCP flow and congestion control mechanisms regulate the throughput of all connections;
- TCP throughput is adjustable through the size of the congestion window.
As a result, the speed with which data can be transmitted in a TCP connection in modern high-speed networks is often limited by round-trip time. While the channel width continues to grow, the delay is limited by the speed of light, and in many cases it is the delay, not the channel width, that is the bottleneck for TCP.
Server configuration setup
Instead of setting up each individual TCP parameter, it’s best to start by upgrading to the latest version of the operating system. TCP best practices continue to evolve, and most of these changes are already available in recent versions of the OS.
"Upgrading the OS on the server" seems like a trivial tip. But in practice, many servers are configured for a specific version of the kernel, and system administrators can be against updates. Yes, updating carries its own risks, but in terms of TCP performance, this is most likely to be the most effective action.
After upgrading the OS, you need to configure the server in accordance with best practices:
- Increase the initial value of the overload window: this will allow to transfer more data in the first exchange and significantly accelerates the growth of the overload window
- Disable Slow Start: Disabling Slow Start after a period of idle connection will improve the performance of long-lived TCP connections.
- Enable window scaling: this will increase the maximum value of the receive window and speed up connections where the delay is high.
- Enable TCP Fast Open: this will allow you to send data in the initial SYN packet. This is a new algorithm, it must be supported by both the client and the server. See if your application can benefit from it.
You may also need to configure other TCP parameters. Refer to the “TCP Tuning for HTTP” material, which is regularly updated by the HTTP Working Group.
For Linux users, ss will help check various open socket statistics. At the command prompt, type
ss --options --extended --memory --processes --info
and you will see the current peers and their settings.
Application setup
How an application uses connections can have a huge impact on performance:
- Any data transfer takes time> 0. Look for ways to reduce the amount of data sent.
- Zoom in to your customers geographically
- Reusing TCP connections can be a crucial point in improving performance.
Eliminating unnecessary data transfer is, of course, the most important type of optimization. If you still need to transfer certain data, it is important to make sure that the appropriate compression algorithm is used for them.
Moving data closer to clients by hosting servers around the world or using a CDN will help reduce round-trip time and greatly improve TCP performance.
Finally, in all cases where this is possible, existing TCP connections should be re-used to avoid delays caused by the slow start algorithm and overload control.
Finally, here is a checklist of what needs to be done to optimize TCP:
- Update server OS
- Ensure cwnd is set to 10
- Make sure window scaling is enabled.
- Disable slow start after idle connection
- Enable TCP Fast Open, if possible.
- Eliminate the transfer of unnecessary data
- Compress transmitted data
- Locate servers geographically closer to customers to reduce round-trip time.
- Reuse TCP connections where possible
- Review the recommendations of the HTTP Working Group.
Source: https://habr.com/ru/post/327050/
All Articles