Extreme migration to PostgreSQL: without stopping, losing and testing

Just a month ago, Yandex.Money ended the relocation of the user profile service from Oracle to PostgreSQL. So now we have a proven solution to migrate large amounts of data without loss and stop using their service.
Under the cut, I will tell you more about how it all happened, why we chose to migrate SymmetricDS and why we still couldn’t do without “manual” efforts. I will also share some developments on the auxiliary code for migration.
For the first migration and run-in of the solution, we chose a service serving user profiles. The profile includes the payment history, favorites, reminders, and other such things - all important, but not critical for the operation of the system. We have a database without embedded logic, so we only needed to transfer the data and sequences to the new platform.
So, after 3 months, user profiles should work without Oracle
In connection with the impending releases on other projects, they decided to complete the transfer in three months. The migration team consisted of 4 people, but these were Senior level developers and DBA specialists. So that a small team could manage in a short period of time, they looked for the most automated solution for the project: without writing the data migration code, manually assembling the database schema, etc. The database contains about 50 tables, so the probability of human error is especially high with manual conversions.
Usually such migrations are performed with the service stopped - during off hours. But Yandex.Money payments take place around the clock, so it was impossible to stop the system for the sake of internal "optimizations". In fact, for this component, the business agreed to a one or two minute suspension for us, without losing data.
Looking for the perfect tool
The quarterly term of the project did not leave room for the invention of its own quasi-bicycles. Therefore, by brainstorming, we collected and screened out a list of suitable products for migration:
Oracle GoldenGate - it may seem that this is the silver bullet. At least until familiarization with the price.
SymmetricDS - there is a scheme migration, it will be created or updated during the registration of the PostgreSQL node in the Oracle master node. It is possible to transform the data when uploading or downloading using BASH, Java or SQL.
Full Convert - can migrate the scheme and data, but the possibilities of customization are limited, there are no variable transformers (the code for changing data during migration).
Oracle to PostgreSQL Migration - transfers schema, data, foreign keys, indexes. Semi-automatic replication, no transformation, but you can set the type correspondence in different databases.
ESF Database Migration Toolkit - migrates all the same as Oracle to PostgreSQL Migration. Data is transmitted in batch mode, the ability to migrate to multiple threads is missing.
Ora2Pg - transfers the scheme, data, foreign keys, indexes, migration in several streams is possible. From minuses: slow transfer of tables with blob / clob types (about 200 records / s), no transformer.
- SQLData Tool - migrates only the schema, limited customization options.
The rest of the products on the market are either already abandoned by the developers, or do not have developed support in the community.
As a result, we chose Ora2Pg to migrate the database schema and SymmetricDS for data migration. In general, the latter is designed more to synchronize different DBMS than to transfer data. But in our case, he allowed to provide migration without stopping services.
Thousand and one little thing to migrate
When we were running migration on copies of the production base, we found a whole set of “features” and oddities in the migration solution. PostgreSQL did not correctly work out some queries that passed without problems in Oracle. For example, SELECT * caused an error and stopped the operation of the entire database service. In general, such requests are bad form, in fact they were different, and I cited these as merely a legal example. It turned out that this is most likely a Java driver problem, so at the time of the project implementation it was easier not to use problematic queries. Later this bug was fixed.
There were difficulties with transactions with the AutoCommit-OFF flag set . In PostgreSQL, the code crashed if, when it was executed, the transaction was not previously opened. Oracle behaved differently: the transaction was rolled back or ended with code that came into the same thread of execution. The solution for PostgreSQL is to write code that checks for an explicitly open transaction for all data change requests.
When executing queries, the user profile service did not specify the sorting order of the displayed values (ORDER BY), since in Oracle, the absence of a sign indicates the output in chronological order. And on this we slipped into PostgreSQL, which output the results of the query separately - combed the code so that ORDER BY is everywhere.

An interesting nuance was with composite transactions that changed data in both the original Oracle database and the instance transferred to PostgreSQL. To ensure that both bases have the same values, our team has developed a special transaction manager. He synchronously opened and closed transactions in both DBMSs. If errors occurred in such transactions, then they had to be solved manually.
And it started
Data migration was phased - according to a pre-approved list of 50 tables. They decided to do the switching at the level of each table in the database, which made it possible to achieve high flexibility and decomposition of the process. That is, at a certain moment, after the data was transferred, a special flag was set for the table, according to which the Ya.Money service switched to a data instance in PostgreSQL.
For successful migration of Oracle-PostgreSQL, it is important to plan in advance so that no annoying little thing is forgotten. We had such a plan, here it is under the spoiler:
What the developer needs to do:
get DDL tables on PostgreSQL;
highlight the interface for the DAO class;
create a DAO class for working with PostgreSQL;
create a flag to switch work from Oracle DAO to PostgreSQL DAO;
write tests for a new DAO with a coverage of 80% (using the jOOQ mechanism to avoid errors in the syntax of SQL queries). More is better;
roll in migration on a test bench;
perform migrations at the acceptance stand, make sure that the acceptance tests pass;
- Release changes to the combat environment.
Manual for DBA:
get from the developer DDL of the table being migrated to the PostgreSQL database, create the table and all related entities;
specify the migration method from the developer - is it necessary to first download the old data and synchronize the new records?
If there is a lot of data, then by what criteria it is possible to limit the volume of the initial load;configure SymmetricDS to synchronize the table;
in one transaction, start the initial download (if required) and synchronize new records;
periodically check the status of download and synchronization;
- just before switching services to PostgreSQL, move the sequences in the destination table for the stock by primary keys.
What you need to not forget the person responsible for the process:
make sure that the production supports PostgreSQL for a specific table;
check that production has successfully completed the initial data download and synchronization of new records is turned on;
ask the DBA to move the sequences to PostgreSQL;
switch one instance of the service to work with PostgreSQL, make sure that there are no errors in the logs and the logic of the service;
switch the remaining instances of the service;
- after a full switch, ask DBA to rename the migrated tables in Oracle. Carefully monitor the errors in the system - some "forgotten" logic of the service may still try to work with Oracle.
During the migration, some of the 50 tables worked on Oracle, the other on PostgreSQL. This is where SymmetricDS came in handy, which migrated data from Oracle to PostgreSQL and thus ensured consistency both for logic with transferred tables, and for those that still worked according to the old scheme.
After the data was transferred in the service, the checkbox “work with PostgreSQL” was set for each specific table, and the queries went to the new DBMS. First, the switching was checked on the dev-stand, then on the acceptance one. If OK - switch to production and rename the table in Oracle (to see if the old table is still being used).
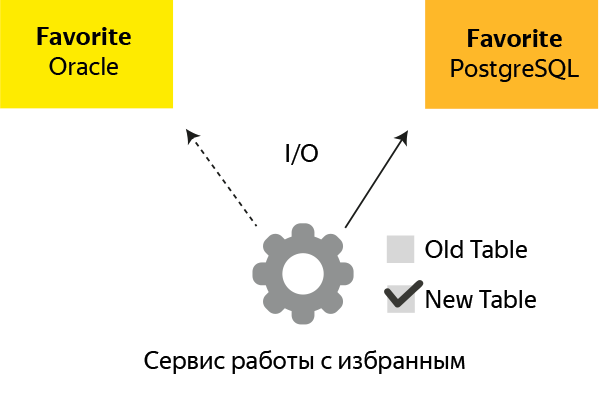
The diagram shows the essence of the idea: after creating a duplicate of the database on PostgreSQL, the service sets the flag new db, after which all calls go to the new database.
But the most difficult was to choose the right moment of switching. In fact, we had 3 migration options, depending on the criticality and complexity of the table:
Transfer table entirely with the subsequent switching . The option was suitable in cases where part of the requests could be lost (the user may be asked to click the button again, or the automatic continuation of the operation will work).
At the level of data center (DC, a total of 2). A way to transfer critical tables, in which we first translate the first data center to PostgreSQL, and in the process of turning it on, turn off the second (from Oracle). At the time of the start - stop Oracle and PostgreSQL could work in parallel, so the synchronization and data switching mechanisms were useful here. There was no idle service at the same time.
- According to the method of "residual pressure . " We leave 2 copies: Oracle for processing late requests for switching and the new PostgreSQL. New tasks were processed in the new database, and old ones were deleted after execution in the remaining Oracle. This is how the base queues moved - auto payments, reminders, etc.
Not without complications. During the initial formation of the database schema for PostgreSQL, the converter did not produce a 100% ready-made version, as expected, in general. It was necessary to manually change some types of columns, correct the sequences and break the scheme into tables and indexes. However, the latter is for order and general aesthetics.
A little later, it turned out that SymmetricDS does not synchronize tables of more than 150 GB. Therefore, I had to sit down at the code and create a workaround for the transfer to such cases.
However, there was no silver bullet either. SymmetricDS did not transfer the CLOB \ BLOB fields if, because of them, the total size of the table was exceeded, so I had to write manual migration queues. Faced with quite exotic cases, when the migration from Oracle to PostgreSQL led to a sharp decline in performance. Nothing remained but to manually disassemble each individual case. For example, for one table, it was necessary to allocate the CLOB field into a separate table, transfer it to an SSD disk and read this field only if necessary.
Since it was necessary to maintain simultaneously active old and new copies of the database, for new ones we made a reserve for sequences to prevent layering and transfer of duplicate keys to PostgreSQL.
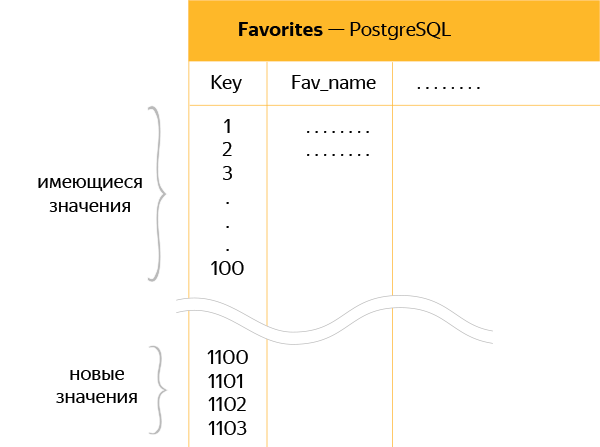
The diagram shows a schematic depiction of a new table in PostgreSQL with a “padding” between old and new data of 1000 keys.
That is, if the last key in the table was 100, then another 1,000 were added to this value, so that SymmetricDS could freely synchronize keys 101, 102 and all the others without overwriting new data.
Finishing Ribbon
For the planned quarter, our small team transferred 80% of the tables to PostgreSQL. The remaining 20% are large tables (on average more than 150 GB), including a collection table with CLOB \ BLOB volume fields. All this had to finish manually the next 1.5 months. Nevertheless, a bunch of SymmetricDS and Ora2Pg did most of the routine work, which was required by the conditions of the problem. Our development team has fairly replenished the internal moneybox “rake” for this project, some of which at the time of publication of the article probably remained behind the scenes.
But Yandex.Money is already preparing a landing party for the upcoming PG Day'17 conference, which will be held in St. Petersburg. Come to the advanced report and prepare tricky questions.
However, I propose to raise the most burning topics right here, in the comments. It is very curious to read about your migration experience and, perhaps, about what we have lost sight of.
In the Yandex.Money repository you will find some code for the solutions described in the article:
Transaction Manager Sources
- The code of the class checking the presence of a transaction.
')
Source: https://habr.com/ru/post/326998/
All Articles