Hallucinate like Trump, or mini-analysis of Recurrent Neural Networks
I have been working on machine learning problems and deep architectures (neural networks) for a long time, and I had to do a mini-presentation of the system that generates time series to emulate various processes. Since it is better to talk on serious topics with humor, I decided to pick up some cheerful example so that the speech would be heard with smiles on their faces. We are very lucky because we live at the same time as a great speaker, whose speeches make people's hearts beat faster. I'm talking about Donald Trump. Therefore, it would be quite natural to create a system that would hallucinate talk like Trump.

Recurrent Neural Networks are a type of artificial neural networks designed to recognize patterns in a data sequence, be it text, genome, handwriting, spoken words, or numeric sequences coming from sensors, the stock market, and government agencies. The main difference of Recurrent Neural Networks (hereinafter TIN) from other architectures is the so-called memory availability. TIN stores the previous values in its state. It can be said that TRN builds dynamic models, i.e. models that change over time in such a way that they provide an opportunity to achieve sufficient accuracy, depending on the context of the examples that were provided.
A good tutorial about these architectures.
')
I would also like to recommend the excellent post of Andrei Karpatny, who is one of the leading researchers in Depth Education in the world, about the incredible effectiveness of the TRN.
The Unreasonable Effectiveness of Recurrent Neural Networks
To build a model, I needed to find the corpus of Trump's speeches. After a little search, I found Trump's speeches at the debates, plus a few interviews and statements on various topics. I cleaned the files of dates, marks the behavior of the room (laughter, etc.), translated into lower case and merged everything into one file called
The second important point is the choice of a framework for building models. If desired, you can write a system from scratch, for example for Python there is a library CudaMat, to perform matrix calculations on graphics cards. Since, in general, the passage through the Neural Network is a set of matrix multiplications using activation functions, various architectures can be implemented fairly quickly on the basis of CudaMat. But I will not reinvent the wheel and take, as an example, two frameworks for Deep Learning systems.
First, this is probably the most common and convenient framework for Torch based on Lua. Lua is probably the fastest interpreted language, with a powerful native backend for graphics accelerators and a state-of-art JIT compiler. Why-is-Lua-so-fast Lua is actively used in Deep Mind, just go to their GitHub .
The second is DeepLearning4j - an open framework for building Neural Networks and distributed learning for the JVM of the world, actively supported by SkyMind. The advantages of the framework include the ease of connecting visualizations, the presence of distributed learning (data-paralell), and a sense of comfort for Java developers. In fact, my goal was to compare the speed of learning and the approaches of the two frameworks.
I also want to note that the following was performed on my MacBook Pro laptop (2015), where there is no NVIDIA GPU, and therefore everything ran on the CPU, which limited me in choosing the size of the model and the time I could spend on preparing the presentation. The difference between CPU and GPU is visible to the naked eye.
GPU
CPU
Let's start with the simplest and fastest. You can install the system from here github.com/jcjohnson/torch-rnn But if you put this system as it is on your car, the Mac owners will face the incompatibility problem of the new version of torch-hd5f with the other dependencies (and I think not only Macs, since DeepMind is this problem). This problem is being overcome, and for this I am sending you here . But the best and easiest way is to take the finished Docker image from here and launch the container.
Throw the body of speeches in the folder torch / torch-rnn / data / under the name speeches.txt ( lies here ).
We start the container with the following command
The -v flag and the path after it mean that I want to map the path from my local file system to the Docker container (to the root system / data /), because during the training the model records intermediate results, I do not want to lose them after the container is destroyed. Yes, and in subsequent launches, I can use the finished model, both to continue the training and to generate.
The remaining commands are identical both for the container launch and for the launch in the native system.
To begin with, it is necessary to do preliminary data processing. Transfer to speech format with hd5f format. File paths are written for the container version, change them to your directory.
We start training
if you run on a system with a GPU, then the -gpu -0 flag, it is by default. Since I do not have an accelerator, I indicated a limit on the size of the sequence to 50 characters. The number of settings is quite large. I chose the size of the PHN 128 layer, 2 layers, because otherwise my training could drag on very, very long. I left the number of epochs and other parameters by default, since I needed some starting point.
In the course of training, the model from time to time is discarded on the disk, and in the future you can continue training with these checkpoints. The documentation describes this in detail. Also, if you wish, you can display model samples in the course of training, that is, see how much the model is progressing in studying the structure of the Donald language. I will show how the model is being trained using the example of DeepLearning4j.
After a few hours, the training ends and a new cv directory appears in the data directory, where the model is located at various stages of the training.

To sample the sequence from the model, enter
The checkpoint flag shows where to get the model, I installed the last entry. Temperature is quite an important parameter of the SoftMax function, it shows how determined the sequence is. Higher values give a noisier and stochastic output, low ones can repeat the input with minor changes. Valid values are from 0 to 1. However, all this is also documented here .
I will show the results of the model below.
The DeepLearning4j framework is not as popular and famous as torch, at the same time it has a number of advantages. It is based on ND4J arrays, or as they are called NumPy for Java. These are arrays that are not on the heap, and work with them goes through native calls. Also, DeepLearning4j has an excellent type system and it is quite intuitively possible to implement all the major architectures, the only thing that does not go beyond the knowledge of theory.
I posted the code here . The code is based on the GravesLSTM Character model, I used the design of Alex Black. To display the process of training the model, I connected the visualization of data. Parameters of the model tried to pick up similar to the torch model. But the differences exist, and below we will see what is happening in the process.
According to Andrei Karpatny, learning neural networks is more art than science. Learning parameters play a crucial role. There are no universal rules, but only recommendations and a sense of intuition. Each parameter must be chosen for a specific set of problems. Even the initial initialization of the scales plays a role in whether the model converges or not. As an example, Andrey's tweet a 20 layer model. weight init N (0,0.02): stuck completely. try weight init N (0, 0.05): optimizes right away. initialization matters a lot: \
I started training with different parameters of learning rate. And that's what came out.
First launch with learning rate 0.1 and initialization XAVIER

It can be seen that somewhere from step 3000, the model was stuck and the loss function started oscillating around the same values. One of the possible reasons was that with a large training parameter, the parameters skip the optimum, and an oscillation is obtained, the gradient jumps. In principle, this is not surprising, since the learning parameter 0.1 is quite large, it is recommended to test it in the interval from 0.1 to 0.001, or even less. I started with more.
I started the system with the parameter 0.01 and here is the result.
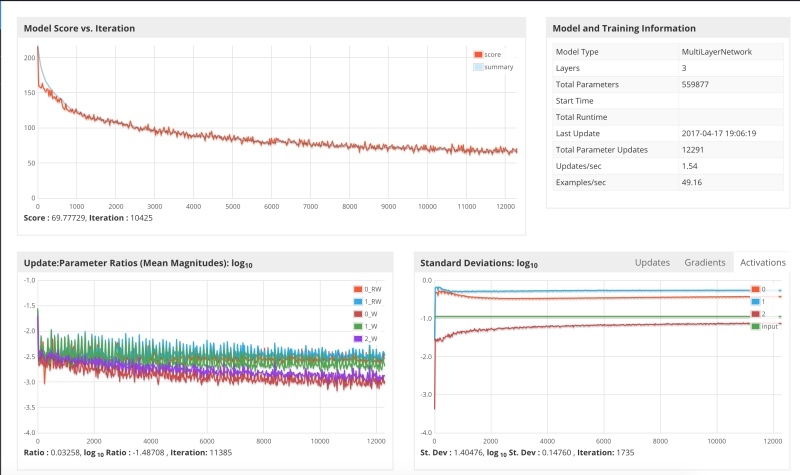
It can be seen that the gradient descent has slowed down considerably, and that even though the gradient is strictly decreasing, it requires a lot of steps and I stopped learning, since it consumed my laptop power.
The third launch of the system with a training parameter of 0.05.
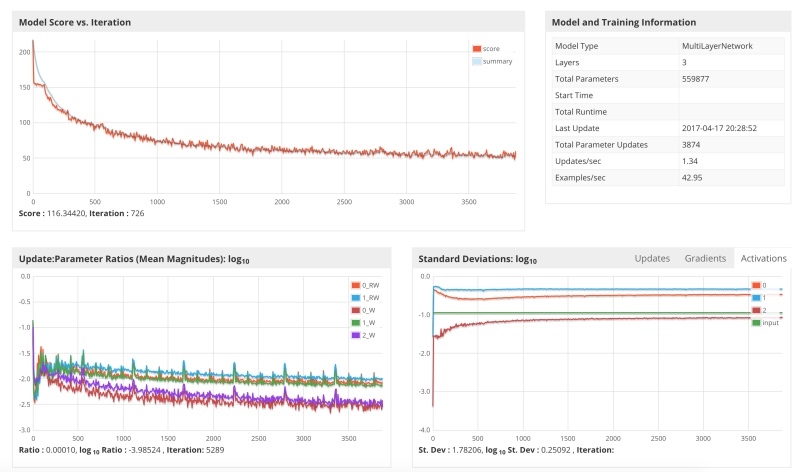
The results show that the gradient descended faster, but again stuck at the end and began to oscillate, which is not surprising, since the value of 0.05 is not much less than 0.1
The best option is to set the reduction of the learning parameters in the process. A striking example of this is the architecture of LeNet. The principle is that we start with large parameters and decrease as we descend. Here is a launch with such a schedule.
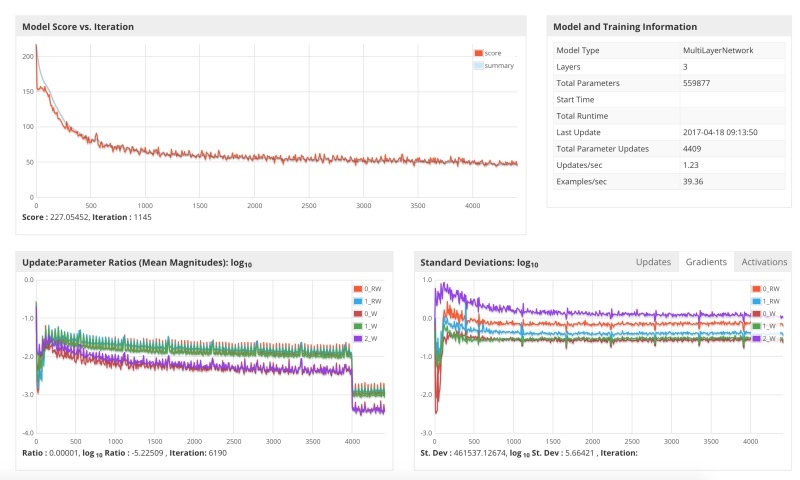
The lower graph shows how at step 4000, the size of the update decreases, and at the same time the loss function breaks through the barrier and a further descent begins. I didn’t finish the workout, because I needed my laptop for work, and I did this analysis literally a couple of days in my spare time. In addition, there are many learning parameters, such as regularization, moment, and others. In case of serious work, it is necessary to carefully select these parameters, since minor changes may be decisive for whether the model will converge, or whether it will be stuck at a local minimum.
And now the funniest and most interesting. How she studied and what gave us a model. On the example of DeepLearning4j logs.
Since at the very beginning the Recurrent Neural Network does not know anything about the language or the data structure, we begin to feed the body of speech to it. Here is the conclusion after several mini-batches (we sample the model with a random crop).
It can be seen that the model already understands that words are separated by spaces. Even some pronouns appear as he, they.
It is evident that our Sharikov has already said his first abyrvalg. The model correctly begins to capture the pronouns I, he, we, you. Some simple words are also present, like bad, know.
Go ahead.
Already looks like English.
Total after
Completed 340 minibatches of size 32x1000 characters
What a. Im not going to be so bad. It was so proud of me. Familiar narcissistic intonation.
And this? I will have great people.
Then, what we saw in Mexico and we are building, apparently wanted a wall, but there was interest.
Note that the model began to issue such results very quickly, only after 340 mini-batches. Since I did not bring the training to the end on DeepLearning4j, we will look at the results of the model using the example of Torch-RNN.
It can be seen as the network begins to hallucinate. The size of the samples can be changed by specifying various parameters, there is also a difference in the indication of the temperature parameter. Here is an example with a low temperature - 0.15.
It is seen that the network begins to speak. Since Mr. Trump speaks rather simple language, the most likely state transitions in the network are reduced to simple constructions.
The disadvantages of this model are visible to the naked eye.
This example is a little toy, and at the same time, it shows the main points in the training of Neural Networks. If you have any questions, or this topic is of interest, then I can share information in the future. My Twitter Feed - @ATavgen
Recurrent Neural Networks
Recurrent Neural Networks are a type of artificial neural networks designed to recognize patterns in a data sequence, be it text, genome, handwriting, spoken words, or numeric sequences coming from sensors, the stock market, and government agencies. The main difference of Recurrent Neural Networks (hereinafter TIN) from other architectures is the so-called memory availability. TIN stores the previous values in its state. It can be said that TRN builds dynamic models, i.e. models that change over time in such a way that they provide an opportunity to achieve sufficient accuracy, depending on the context of the examples that were provided.
A good tutorial about these architectures.
')
I would also like to recommend the excellent post of Andrei Karpatny, who is one of the leading researchers in Depth Education in the world, about the incredible effectiveness of the TRN.
The Unreasonable Effectiveness of Recurrent Neural Networks
Models and training
To build a model, I needed to find the corpus of Trump's speeches. After a little search, I found Trump's speeches at the debates, plus a few interviews and statements on various topics. I cleaned the files of dates, marks the behavior of the room (laughter, etc.), translated into lower case and merged everything into one file called
speeches.txtThe second important point is the choice of a framework for building models. If desired, you can write a system from scratch, for example for Python there is a library CudaMat, to perform matrix calculations on graphics cards. Since, in general, the passage through the Neural Network is a set of matrix multiplications using activation functions, various architectures can be implemented fairly quickly on the basis of CudaMat. But I will not reinvent the wheel and take, as an example, two frameworks for Deep Learning systems.
First, this is probably the most common and convenient framework for Torch based on Lua. Lua is probably the fastest interpreted language, with a powerful native backend for graphics accelerators and a state-of-art JIT compiler. Why-is-Lua-so-fast Lua is actively used in Deep Mind, just go to their GitHub .
The second is DeepLearning4j - an open framework for building Neural Networks and distributed learning for the JVM of the world, actively supported by SkyMind. The advantages of the framework include the ease of connecting visualizations, the presence of distributed learning (data-paralell), and a sense of comfort for Java developers. In fact, my goal was to compare the speed of learning and the approaches of the two frameworks.
I also want to note that the following was performed on my MacBook Pro laptop (2015), where there is no NVIDIA GPU, and therefore everything ran on the CPU, which limited me in choosing the size of the model and the time I could spend on preparing the presentation. The difference between CPU and GPU is visible to the naked eye.
GPU
CPU
Torch-rnn
Let's start with the simplest and fastest. You can install the system from here github.com/jcjohnson/torch-rnn But if you put this system as it is on your car, the Mac owners will face the incompatibility problem of the new version of torch-hd5f with the other dependencies (and I think not only Macs, since DeepMind is this problem). This problem is being overcome, and for this I am sending you here . But the best and easiest way is to take the finished Docker image from here and launch the container.
Throw the body of speeches in the folder torch / torch-rnn / data / under the name speeches.txt ( lies here ).
We start the container with the following command
docker run -v /Users/<YOUR_USER_NAME>/torch/torch-rnn/data:/data --rm -ti crisbal/torch-rnn:base bash The -v flag and the path after it mean that I want to map the path from my local file system to the Docker container (to the root system / data /), because during the training the model records intermediate results, I do not want to lose them after the container is destroyed. Yes, and in subsequent launches, I can use the finished model, both to continue the training and to generate.
The remaining commands are identical both for the container launch and for the launch in the native system.
To begin with, it is necessary to do preliminary data processing. Transfer to speech format with hd5f format. File paths are written for the container version, change them to your directory.
python scripts/preprocess.py --input_txt /data/speeches.txt --output_h5 /data/speeches.h5 --output_json /data/speeches.json We start training
th train.lua -batch_size 3 -seq_length 50 -gpu -1 -input_h5 /data/speeches.h5 -input_json /data/speeches.json if you run on a system with a GPU, then the -gpu -0 flag, it is by default. Since I do not have an accelerator, I indicated a limit on the size of the sequence to 50 characters. The number of settings is quite large. I chose the size of the PHN 128 layer, 2 layers, because otherwise my training could drag on very, very long. I left the number of epochs and other parameters by default, since I needed some starting point.
In the course of training, the model from time to time is discarded on the disk, and in the future you can continue training with these checkpoints. The documentation describes this in detail. Also, if you wish, you can display model samples in the course of training, that is, see how much the model is progressing in studying the structure of the Donald language. I will show how the model is being trained using the example of DeepLearning4j.
After a few hours, the training ends and a new cv directory appears in the data directory, where the model is located at various stages of the training.
To sample the sequence from the model, enter
th sample.lua -gpu -1 -sample 1 -verbose 1 -temperature 0.9 -checkpoint /data/cv/checkpoint_74900.t7 -length 2000 The checkpoint flag shows where to get the model, I installed the last entry. Temperature is quite an important parameter of the SoftMax function, it shows how determined the sequence is. Higher values give a noisier and stochastic output, low ones can repeat the input with minor changes. Valid values are from 0 to 1. However, all this is also documented here .
I will show the results of the model below.
DeepLearning4j
The DeepLearning4j framework is not as popular and famous as torch, at the same time it has a number of advantages. It is based on ND4J arrays, or as they are called NumPy for Java. These are arrays that are not on the heap, and work with them goes through native calls. Also, DeepLearning4j has an excellent type system and it is quite intuitively possible to implement all the major architectures, the only thing that does not go beyond the knowledge of theory.
I posted the code here . The code is based on the GravesLSTM Character model, I used the design of Alex Black. To display the process of training the model, I connected the visualization of data. Parameters of the model tried to pick up similar to the torch model. But the differences exist, and below we will see what is happening in the process.
According to Andrei Karpatny, learning neural networks is more art than science. Learning parameters play a crucial role. There are no universal rules, but only recommendations and a sense of intuition. Each parameter must be chosen for a specific set of problems. Even the initial initialization of the scales plays a role in whether the model converges or not. As an example, Andrey's tweet a 20 layer model. weight init N (0,0.02): stuck completely. try weight init N (0, 0.05): optimizes right away. initialization matters a lot: \
I started training with different parameters of learning rate. And that's what came out.
First launch with learning rate 0.1 and initialization XAVIER
It can be seen that somewhere from step 3000, the model was stuck and the loss function started oscillating around the same values. One of the possible reasons was that with a large training parameter, the parameters skip the optimum, and an oscillation is obtained, the gradient jumps. In principle, this is not surprising, since the learning parameter 0.1 is quite large, it is recommended to test it in the interval from 0.1 to 0.001, or even less. I started with more.
I started the system with the parameter 0.01 and here is the result.
It can be seen that the gradient descent has slowed down considerably, and that even though the gradient is strictly decreasing, it requires a lot of steps and I stopped learning, since it consumed my laptop power.
The third launch of the system with a training parameter of 0.05.
The results show that the gradient descended faster, but again stuck at the end and began to oscillate, which is not surprising, since the value of 0.05 is not much less than 0.1
The best option is to set the reduction of the learning parameters in the process. A striking example of this is the architecture of LeNet. The principle is that we start with large parameters and decrease as we descend. Here is a launch with such a schedule.
The lower graph shows how at step 4000, the size of the update decreases, and at the same time the loss function breaks through the barrier and a further descent begins. I didn’t finish the workout, because I needed my laptop for work, and I did this analysis literally a couple of days in my spare time. In addition, there are many learning parameters, such as regularization, moment, and others. In case of serious work, it is necessary to carefully select these parameters, since minor changes may be decisive for whether the model will converge, or whether it will be stuck at a local minimum.
results
And now the funniest and most interesting. How she studied and what gave us a model. On the example of DeepLearning4j logs.
Since at the very beginning the Recurrent Neural Network does not know anything about the language or the data structure, we begin to feed the body of speech to it. Here is the conclusion after several mini-batches (we sample the model with a random crop).
----- Sample 1 ----- Lfs mint alo she g tor, torink.han, aulb bollg rurr Atans ir'd ciI anlot, ade dos rhant eot taoscare werang he ca m hltayeu.,hare they Woy theaplir horet iul pe neaf it Yf therg. hhat anoy souk, thau do y RO Bury f if. haveyhaled Dhorlsy Ato thinanse rank fourile DaniOn Ttovele yhinl ans anu he B It can be seen that the model already understands that words are separated by spaces. Even some pronouns appear as he, they.
----- Sample 2 ----- aly Eo, He, to bakk st I stire I'micgobbsh brond thet we sthe mikadionee bans. Whether job lyok,. Whon not I ouuk. Wewer they sas I dait ond we polntryoiggsiof, waoe have ithale. I bale bockuyte seemer I dant you I Fout whey We kuow Soush Wharay nestibigiof, You knik is you know, boxw staretho bad It is evident that our Sharikov has already said his first abyrvalg. The model correctly begins to capture the pronouns I, he, we, you. Some simple words are also present, like bad, know.
Go ahead.
----- Sample 3 ----- cy doing to whit stoll. Ho just to deed to was very minioned, now, Fome is a soild say and is is soudd and If no want nonkouahvion. if you beeming thet take is our tough us iss could feor youlk to at Lend and we do toted to start to pasted to doind the we do it. I jind and I spongly stection Caread. Already looks like English.
Total after
Completed 340 minibatches of size 32x1000 characters
----- Sample 4 ----- Second. They left you asses, believe me, but I will have great people.I solling us some -- and you see something youve seen deterner to Mexico, we are building interest. 100,000. Im not going to be so bad. It was so proud of me. Incredible and or their cities which I kept the same wealthy. They dont want them, were the world companies. Yes, they get the fraud, except people deals 100. Its like never respaved us. Thats what were going to do an orfone thats seen this. What a. Im not going to be so bad. It was so proud of me. Familiar narcissistic intonation.
And this? I will have great people.
Then, what we saw in Mexico and we are building, apparently wanted a wall, but there was interest.
Note that the model began to issue such results very quickly, only after 340 mini-batches. Since I did not bring the training to the end on DeepLearning4j, we will look at the results of the model using the example of Torch-RNN.
So we're going to run. But I was going to have all the manufacturing things as you know what we're not going to be very soon to this country starting a president land the country. It's the committed to say the greatest state. You know, I like Iran is so badly. I said, "I'm not as you know what? Why aren't doing my sad by having any of the place so well, you look at 78%, I've done and they're coming in the Hispanics are so many. The different state and then I mean, it's not going to be these people that are politicians that they said, "You know, every poll said "We will bring it. I think we don't want to talk about the stupid new of this country. We love it of money. It's running the cary America great. It can be seen as the network begins to hallucinate. The size of the samples can be changed by specifying various parameters, there is also a difference in the indication of the temperature parameter. Here is an example with a low temperature - 0.15.
I want to take our country and they can be a great country and they want to do it. They want to take a look at the world is a lot of things are the worst thing that we have to do it. We have to do it. I mean, they want to tell you that we will be the world is a great country and they want to be a great country is going to be a great people. I mean, I want to be saying that we have to do it. They don't know what they don't want to say that we have to do it. It is seen that the network begins to speak. Since Mr. Trump speaks rather simple language, the most likely state transitions in the network are reduced to simple constructions.
The disadvantages of this model are visible to the naked eye.
- The size of the data for the model is very small. I did not aggregate all possible speeches and speeches, but collected what was convenient to quickly assemble. For this kind of model, the size of the data plays the most important role, since neural networks are very data hungry.
- The size of the model is small (the number of layers), since I was limited in computing resources, and I had to do a small demonstration. By increasing the model, you can get more interesting results.
This example is a little toy, and at the same time, it shows the main points in the training of Neural Networks. If you have any questions, or this topic is of interest, then I can share information in the future. My Twitter Feed - @ATavgen
Source: https://habr.com/ru/post/326966/
All Articles