Application server on pl / pgsql
Artem Makarov , head of IT department at Project 111 , at one of the past PG Day, told how a business can decide on a solution such as building its own ERP system on Postgres and an application server based on stored procedures. Which of this followed the bad, good sides. It should be noted that Artem was never a real programmer, although he wrote quite a lot of code. Rather, he can be called the anti-manager and evangelist, and lobbyist for the business of IT solutions. Therefore, in his report the view is not only from the technical specialist, but also from the manager.
Who are we?
In order to explain our choice, it is worth explaining the specifics of our company. If you open the Project 111 site (our programmers are already looking at whether the slashdot effect will be there), we will be very similar to an e-commerce online store, but we are not talking about an online store, we are B2B. That is, we have regular customers, there are a lot of them, marketing is going crazy, inventing new schemes, discounts, promotions and so on, so we have a rather complicated sales process that is long and takes almost a week. Our clients, partners on the site are full-fledged employees in the ERP system , that is, they use very many functions of the sales department, only they cannot pay for themselves. Therefore, our system is rather heavy, including at the front end.
')
We are a medium sized company. The numbers are not very big: we have 2300 users logged into the site (our partners with their discounts and conditions), but these are “heavy users”, that is, they create the same burden as an employee in a warehouse or in finance. We have long made a bet on the Internet, 97-98% of orders are placed online , 60% of orders are not in the hands of a sales employee, they automatically go to the warehouse.
How did you get the idea to build the systems yourself?
The beginning of the 2000s, when we were engaged in this, the word “highload” did not sound, the ajax did not seem to even exist. In general, there was some, Internet Explorer 5.5. The management of the company had a strict feeling that the future was over the Internet, that taking orders over the phone was bad , that either we would distribute our application among partners, or maybe we would have a website (and we had a website). Our site (domain) is registered like in 1998, 5 years later than that of Dell. And we looked around.
In the early 2000s, a couple of new columns with fresh burial ground appeared at the ERP system cemetery each year. And the choice around "what to buy," "what to build future systems for" was very difficult. That is, we were afraid of vendor locking, and, on the other hand, we did not understand the roadmap of these ERP systems. In addition, ERP-systems have fairly tight licensing restrictions, they still exist. If you think: why not take 1C, screw Bitrix to it and trade with might and main? 1C still has a clearly structured limitation, which does not allow to proxy its Web API. There is some kind of XML API, that is, you can pull the 1C method. But every connection that can theoretically be used by this method must be licensed. That is, if you expose a real-time service working with 1C to the site, then you should buy all the licenses. You have 10 thousand users, then you have to buy 10 thousand licenses, if they still exist at all.
There is a different approach. This is a stand-alone ERP system and a stand-alone website, there is some kind of exchange between them. But I said that we have a difficult business sales process: to calculate the cost of the order, we will probably ask a dozen and a half or two tables. These are volume discounts, historical discounts and discount lists, a contract of a specific client, a clause of a contract, a currency, some European price list has been picked up. To write this algorithm is in some way a pain. And if you have to write this algorithm in your ERP system? One person wrote. Then go sometime to a PHP programmer and say, here are 25 tables for you, just replicated in XML, and you also repeat this algorithm. Of course, he repeats, but it turns out that the first algorithm may have errors, and the second is not the case. So you do the same job twice.
Therefore, we decided to build a site-centric ERP , that is, one core that owns all the data, all the business logic, and all that is around is just interfaces. They already have some intelligence, but the business units are practically free. Two hours ago we discussed CMS systems and Bitrixes, as we observe our respected partners and market competitors, recently one of the companies switched to the next version of 1C. They reported that “the largest partner of 1C is some kind of gold, our team of programmers worked for a year and implemented it,” we see that they have lost all their functions for half a year. Why? Because they threw out the old site and they have to make a new one. Therefore, reserves are made by telephone. Well, the last factor, in addition to site-centricity, the fear of “boxes” is what the picture depicts. We had the belief that we could do it.

In general, it is considered that doing business logic on stored procedures is, as it were, not good . I was even shy. We have been doing this for many years, but Roman practically made me say, provoked that later at some stage it turned out that in fact there were a lot of people like us. I'm not the only one.
What are the myths?
Lost portability between different databases. Yes, there is. Difficult to maintain. Yes, the stored procedures in Eclipse are somehow not very, not there. How to deploy? Fair It is difficult to develop in a team. Indeed, you compiled your pl / sql-procedure, figak-figak, and someone else compiled it. It seems reasonable. And finally, if you start writing the stored procedure now, you have no sharding, how will you make distributed configurations using some kind of synthetic key? It also seems reasonable.
But from a technical point of view it is difficult to argue. Let's answer some children's questions. “Portability between databases, and who needs this at all?” Imagine such a dialogue. Client: “Tell me, can I transfer your application to another database?” But it’s not a question, though every day Microsoft - Oracle, Microsoft - Oracle. And who needs it?

Portability between databases is a positive function for the seller, who sells the product. But when you received this product and use it, it is not so important anymore.
Next point: difficult to maintain. Yes, it is difficult to maintain a boxed product, if you have 100 installations throughout the country, each one has a separate stored procedure. Suddenly, the client there handles his playful something compiles and immediately nervously, how to deploy, how to roll? Somehow difficult.
Again, if you are a consumer of this product, you yourself wrote and use it yourself, you do not have 10,000 installations, this is not your problem. Is it difficult to keep the box in a big team? We are a small business, we are not “HighLod”, not Yandex, not Google, we are an ordinary taxpayer. At a time when Avito’s open spaces are plowing highload, I don’t know, Yandex, Mail.RU, we are a regular taxpayer and stand knee-deep in 1C. We have no money for big teams, we have no money for programmers with such a square head. We have a small team. If there is time left and it will be interesting, I will tell you how we actually designed, implemented.
But by the time of launch, support for legacy code, the old system, the very 1C and others, and 2.5 people were engaged in writing, updating the system, migration: 2 real programmers and me. That is, it’s not about big teams.
What do we have left?
Myths left : sharding, distributed configurations . It's very easy to argue against sharding: guys, have you read about Skype? They have everything on stored procedures, pgbouncer , pl / proxy, and more. If your database does not allow the application to climb directly into itself, it can only pull stored procedures, then what is inside - you deceive any application. That is, to do sharding on stored procedures and so on - this is not what is possible, but necessary, if your requests are necessary. We have pl / proxy , dblink , foreign data wrapper , which is not. Are you sure you need to do sharding right away? This was already mentioned on the reports yesterday. In general, we now know that for medium-sized businesses, if you are not Mail.ru, not Yandex, then maybe this is not so and important.
Why PostgreSQL?
First of all, mature pl / pgsql . He appeared in the 98th or even the 97th year. Strictness, functionality and academic approach. If you look at the Postgres documentation, it’s written like a good tutorial. That is, when we take a sysadmin to work who needs to be able to read the documentation, I test it using FreeBSD manuals and documentation, that is, there is good English, everything is clear and in one place. Open source and free license - there is nothing to say, various risks are reduced. If we implemented the 1C seven in 2005, then we would have experienced a lot of pain and would have changed several information systems. Changing the database has nothing to do with it.
And somewhere from the 98th year we had such a funny saytik, in the 98th year it was launched and worked on PostgreSQL. I was not there yet, I joined after a year and a half. In my opinion it was release 6.4. In addition, an understandable development plan. We still had only plans for a public website, not closed to partners, but for everyone, when anyone can come, register. We already knew that a half or two years and will be T-Search. After all, developers open to interaction, a good community, you can understand what will happen over time, and make realistic plans. And they come true.

The bad and good sides of stored procedures. Imagine that you are not a giant IT company, you are a business that is not satisfied with a boxed system, you need your own application server. If you go along the classical path, then something like that in Java can be written in C, but the programmer’s incentive must be very high. And all these pains will rest on these programmers. You need to think about the distribution of memory, about the leaks that will inevitably be, you need at least some kind of scripting language, because it is impossible for a working business that earns money, trades, or “deploy” three times a day. Business must adapt on the go, you can not stop. And scripting language allows you to change business rules on the go. You also need some kind of profiling. In general, not so easy. So, posgres takes it all on himself.
We do not think about memory leaks at all, we have never had any problems. We have been online there for several months. And if it hurts us a lot and we want to upgrade, we are updating, but we don’t stop the run-time at all. We have no memory leaks. These are things that are solved for us by very good programmers. Us as an ordinary trading business is at hand. Scripting language - pl / pgsql, take it and use it. Verification of rights, etc., profiling - this will be later. But also the problems are solved.
That is, we get an application server for dummy, which has no restrictions , there is no ORM that binds your hands, that is, you can do anything and not experience some kind of architectural consequences. In some limits. Simple language, low threshold for entry. Junior, who was not given a production, but showed how and what to write, if he has relational thinking, it is achieved, in my opinion, at the age a little earlier than object thinking, he is already able to produce normal code, which can already be put into production by looking. I retire in 20 years in fact, and I still have the ability to understand the pl / pgsql code and write less myself, but I can optimize the code. That is, this knowledge is stored for a long time.
Safety is something we thought about at the beginning of the 2000s, it is very difficult to push SQL injection through the stored procedure, you really need to shoot yourself in the foot, you need to aim well. Why was this important then? Everyone wrote their CMS-systems, every second was full of holes. It seems to me that in 2001-2002, with a bunch of CMS and 15-20% of sites, it was possible to dig some injection in 10 minutes.
The next item in the slide is very controversial - it is isolation from the interface . We have thrown out front-end applications several times, some internal development or a site that is inaccessible to the final customer, only for partners. There was not much code there, it was quickly transferred to another technology and you didn’t lose business logic at all. The isolation from the interface is somewhere good, somewhere is evil. And when our business logic has nothing to do with representation, we can change the technology on the frontend.
Let's go back to the beginning of the 2000s. How many interface technologies have changed there? You must program in Visual Basic, on the Internet Information server. Someone sawed on pearl, PHP, Ruby, nowhere to go from all these words. Interface technologies change very quickly, and SQL is still alive. The very old function in our system was written in 1998, as a relic to it you approach. True, we sawed it the other day, but this code can work. That is, what we wrote 12 years ago will work on that same run-time, at least in this circle no one will look contemptuously: “and he is in PHP”. SQL is a normal language, although somewhere limited. A long time life of business logic is useful.

Bad sides
Too good insulation , yes. In principle, if you have a good application server, it has business logic, acl's are closely related to interfaces. We have two interfaces: an internal employee program and a website. And both applications are very different. Sharing this knowledge and skills was not as valuable as getting a long-lived application server.
No well- integrated development tools - yes, that’s real. If some connection with the version control system was integrated into pgAdmin , if the code there was slightly better highlighted, substituted ... Here we still have pain, I admit. Some of us work in pgAdmin, some people like ems-sql for auto-substitution, but there is a lot of work to be done.
Next moment. I said that we do not solve problems with caching , we do not solve problems with memory allocation , but if you don’t have enough caching that the program gives you, you will have new layers of abstraction . It's not very good. If you have a programmer who wrote business logic cannot satisfy the front-end, then some middleware appears (which most likely a front-end programmer in some Java or C writes), which does this for himself. In fact, this is a difficult problem. Because caching and cache invalidation is the hardest of two problems , the most difficult in theory. Everybody knows the second - give the correct names to the variables.
Sometimes when writing stored procedures, it is difficult to stop in time. In Java, our programmer caught me writing a stored procedure that created letters on pl / perl and mime and then sent them. I won't do this anymore.

What's inside?
Now we have posgres 9.4. Development started at 7.4. Did anyone hold 7.4 in his hands? Writing stored procedures? Someone felt this pain. For those who did not see, the body of the stored procedure was in single quotes. And there is not exactly the syntax is not highlighted, everything was purulent brown. But there were brave people who decided on this. Our business logic is 3,000 stored procedures , they are not very large, you can count them by code size. Note that if at the beginning we wrote you a lot of code, now, over the last 5.5-6 years, not so much. The code is quite plump, there are comments, function headers. This is most likely not the code that Andrei talked about: which are hard for 80 lines per day for programmers. The bases are well normalized , there are 700 tables, hundreds of them are analytics, which we will soon pull out. We are probably growing a little faster, but the base is about that.
We love short transactions . Short transactions - this is a high speed, there is no “overhead” on swollen indices, waiting for locks. If we can write a short business function, we make it short. We love “constraints” , foreign keys, and so on, because it eliminates a huge number of errors. Last year, we ran into a “violation” violation in one function that worked for almost 6 years. And there was a mistake in it that very rarely manifested itself. It is difficult to give an example. But if the storekeeper takes one box with his left hand, another box with the right hand, presses the barcode scanner with his nose and moves something else, only then this error occurred. And she never arose! We caught her because constraint worked. In general, constraints are a blessing, it does not allow you to shoot yourself in the foot.
We say that the tables are normalized, but we love denormalization . Denormalization is mainly needed for the site. We are stuffing a bunch of different data into a rather wide table, and on our site we have fast enough interfaces. Easy to give, few “joins”.
We hate ORM and “code generators" . Our own ideology, ORM, contradicts, but I can show you, when we stepped on it, why it upset us.

The frontend is tomcat + nginx , it has several products running on it. In addition to the site, there are also Intranet products (CMS and CRM are different), reporting (freestanding serv in Jasper). There is an internal application that started on Borland C Builder, now it is Embercadero (almost does not develop, there are less and less of such interfaces). All this works through pgbouncer , about which individual thankful words. There is still a lot of all: analytics, seo, asterisk, which directs calls. It is also integrated into our database and uses the same business logic.

Go ahead.In fact, production is one server , the second is a replica, which is for tests and some offload for analytics. The servers are quite ordinary, but we did not save on hardware. As you can see, they are not heavily loaded. LA is no higher than three, but it may be more serious now, in summer, in winter. Why?In a trading company, unlike the social network, there is a very small hot data set. Active products out of 100 thousand - twenty, out of 100 thousand customers - active pieces 10. In principle, despite the fact that the base is growing, the company's money grows, customers arrive, still this is not enough, it is well trampled down in memory. I can reveal the figures: the gross margin (net profit of business before tax) 40 minutes per season allows you to buy such a server. And this, again, returning to the word about sharding.
Think, these figures say that if it is economical to write code, do not read the “SELECT *” server into the applicationfrom two tables and not joining them in Java cycles, then you can get by with a very modest iron. And this we still do not use a replica for offload. That is, reading requests from the site go to the combat cluster.
We do not use SSD . I have to admit, there was such a mistake: we have a network engineer who tests the servers very meticulously, and we know that the best way to test a raid is to assemble a RAID5. And we are now in “production” in RAID5 by mistake, we accidentally noticed when our battery died.

Go ahead.We ended up laughing, but here it will be somewhat more boring. How does it work? As we have said, no application directly enters the database with dirty hands, each application operates under its own role. All stored procedures are laid out in different ways.
What do we see here?
We have folder roles like web group and employer group , which have almost no rights. And in these roles, folders are pushed into application roles. The application “role for the site” (web) and any role “employer” (for the “emploorsky” application). Note the statement timeout of 10 thousand. Why is this done? This means that if the site manages to pull such a request, which will not be fulfilled in 10 seconds, the request will be thrown out. In fact, the answer is simple. If you have something stuck somewhere, and users on the site begin to pull it, and the bases are not given away, then everything only gets worse. It is necessary to detach insolent. Note that the roll back transaction is still warmed up buffer cache. Even if she did not give anything to the user, she still put it in the buffer cache. When you have several people received an exception (10 thousand people, 2 of them received), they warmed the base of the cache, and the third request will come success. If you do not do this, then you will overflow with pool, Java will understand , pgbouncer may not have enough sockets.
Next we create the schemas and distribute the rights to the schema to each application. Here it is obvious that the customer can both include a web application (WebGroup) and an application from the internal group. If a person is able to do everything inside the office, then even if everything is on the site. And in the very last paragraph, we forbid applications to see the code of the procedures being entered and the data schema.
In fact, this is already too much. If someone hacks your application, it will not see your secret tables. He will not be able to read the data anyway, and here he will not even see the name of the stored procedures.

What are the functions?
The first and only function that does not have an in_SessionID input parameter is authorization. Not individuals work with us, but partners, it is 50a person is in the same company, so it’s more convenient for us as a domain registrar: a company login, one login and password. This function returns the session, and pay attention to the definition - it is a security definer, it has the right to pull 2 groups, an internal application and an external one.

All other functions have the SessionID input parameter - this allows you to log in once, associate a session with a user, issue it in a browser cookie or into the application's memory, and pull all other functions. They always have the Session input parameter and are manipulated inside to recover who causes them. That is, the function OrderCreatewhich is called from the site or from the internal application, it works from a single user. Inside it, we can determine who specifically of the subjects of the system is pulling it at the moment.
Functions that are on the site, additionally covered. It is clear that the OrderCreate function should have the Customer input parameter , for which customer we set the order. Here we cover it. CompanyID appears through the session, and one company cannot create an order for another.
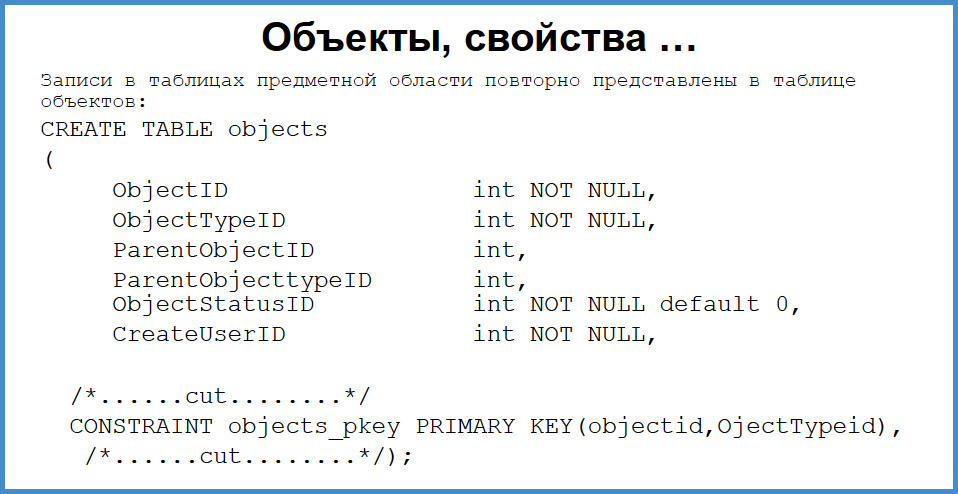
Next you need to deal with the ACL. Here I will quickly slip through, because this is a deep area and will have to be cut a lot. Each domain table (customers, campaigns, orders, contracts, price items) has a projection on the table of objects. That is, the customers table entry has the object_id table entry and object_type = 84, as I recall. What does this give?On this unified representation of objects to the subject area, you can attach properties, life cycles, some restrictions, locks and, on top of this, construct a rights check.

Therefore, within each function of the domain that distributes orders, ships the machines, there is a function that checks rights. We pull this function by passing the object ID, the object type and the “action” type to it. She inside herself either says OK, or throws an exception . If we throw an exception , it is very easy to catch it in the application. Any connector (JDBC, any custom) these exceptiongood catches and transfers to the client. The user receives an error and can analyze it. If we do not need to diagnose an error on the client, but simply filter something, then we pass such a parameter. It seems quite cumbersome, but in fact the verification of rights in this way is more an imperceptible part of the programmer’s work, does not interfere with creating business logic, only creates unification.
Was everything without problems?
Not.This is a sad picture that describes the moment when we started. Look at the bottom of the picture - autumn 2009. What we got. We had a website, it was about 200 people, 300, they grew. In the pool, 5-6 connections were issued simultaneously in one step, and another 60-70 connections were occupied by the internal application. We decided that since within the company 60 users work, then why are there any pools, they worked directly. Suddenly we felt pain. A server with 16 cores, that is, 4 sockets with 4 cores for 2009 was pretty cool, and when we saw LA 60 , on 16 cores ...
What caused the reason?
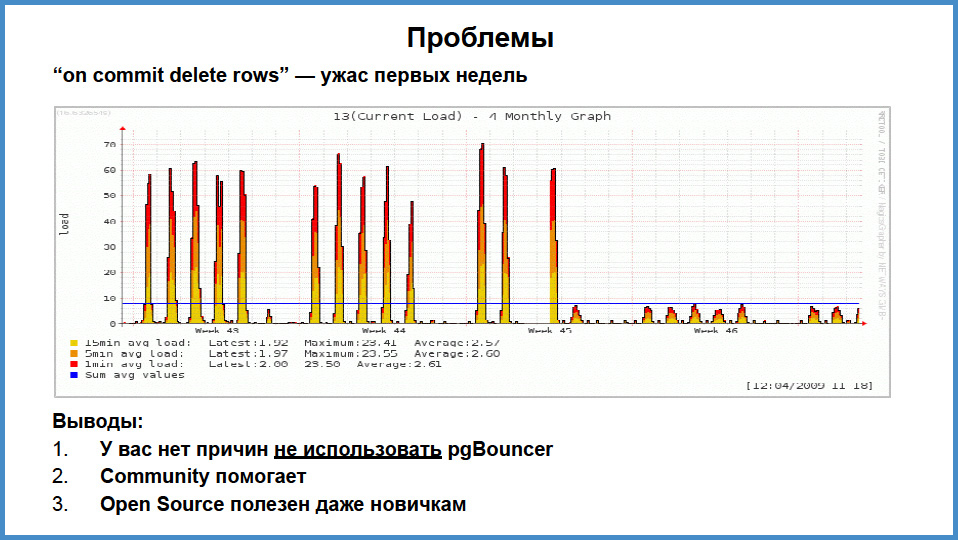
This problem no longer exists, but I have to say it to you, this is such as auto-training. And secondly, to caution how to: always listen to the elders. We thought we didn't need pgbouncer. In principle, it is not needed if we did everything normally. But in each session that we opened on the next page, we have initialized stored procedures of the ON COMMIT DELETE ROWS type . In the pre-9.1 or 9.2 version there was a feature that we later learned about. It turns out that at the beginning of each transaction, on each temporary label with type ON COMMIT DELETE ROWS, TRUNCATE was fed into each connection and then, at the end of the transaction, TRUNCATE was also applied . That is, if you have 100 connections, each with 30 temporary tables of type ON COMMIT DELETE ROWS, then you have 3000 temporary tables. And even if none of these tables were involved in a transaction, this TRUNCATE is stillserved twice. You understand what was happening.
How did it help us that Postgres is open source?
We have a "sishny" programmer, who climbed over after some time of pain and saw where transactions open and close approximately. Put the "notes", and saw that this truncate occurs. I climbed onto the website of the website and wrote to the newsletter in broken English that with each transaction you do this and that. I was shocked when, in response, Tom Lane said, “Yes, I guess. It is hard to be surprised that we clean the tables temporary, but the fact that we, including those that do not work, is not very good. ” And then Bruce Momzhan pulled himself up , whom I did not expect at all, if he is here, then thank him very much. And he wrote:"Guys, do not worry, I will include it in my personal todo-list and try to have it pierced in the official todo-list." And so it happened. We immediately found a solution. First, I compiled pgbouncer, it took 7 minutes there. 7 minutes after the illumination, we saw this. Ed .: See the right part of the graph on the slide]. That is, the load fell, it just became super-comfortable, the connections stopped hanging. There were some problems during the start of transactions, there was a slight delay of 15 ms, but you could live with that. In my opinion, until the end of the year we lived with this scheme, having increased the number of clients for this season three times. Thanks to Bruce and thanks to the community.

There are problems. There is such a line, in which there is an error and even a hint in which it is. There is a lack of pl / pgsqlAs a code of business logic, although the base is strict and there are a lot of opportunities to protect yourself, the code is not verified very well. Whoever did not notice, there is a comma between the val2 and val3 . Guess what result will produce a notice , if we in all vals (i1, i2, i3, i4) transfer edinichki. In the “notice” will be 4 numbers. What kind? The first and second - edinichki , and the third and fourth? This will be NULL . And how to live with it? Seeing the space, the poster simply ignores everything else. I also wrote about this in the newsletter, I do not remember who answered, Gregg Smith , it seems: "this is legacy, because pl / pgsql is a legacy of SQL code."The syntax that we can afford in SQL is translated here. This is yes, this is a problem, but this is one of the very few problems we have encountered.
The next issue is documentation . This is a story about the most serious accident that we had. If you put DROP CASCADE on a table, then you will lose all the exception in the notice , all objects that will be deleted in cascade will be shown. If you have 5-6 tables linked by foreign key , you say truncateaccording to the table, then you will be answered that the second table will be cleared. He will not say that 4 of them will be cleared. And we ran into it. I was really told in the documentation that this was necessary, but such things happen.
The last problem is not a problem, it is rather a surprise. We decided to experiment with pl / proxy to read-only off-load requests to the replica. It turned out that pl / proxy does not support ref-cursors , and we very much love ref-cursors. Because any connector to the database supports cursors, they are easy to modify, they, unlike the record, can be transferred between functions. Everything is just built on cursors. If there was JSON , we would build on JSON. We are now considering whether to transfer the front-end of the site to JSON. Then we will be able to unload through pl / proxy and achieve a refutation of the very same myth that supposedly cannot be, having built everything on stored procedures, to “ shard ”. You can, if you do not use the cursor.
How is our life going?
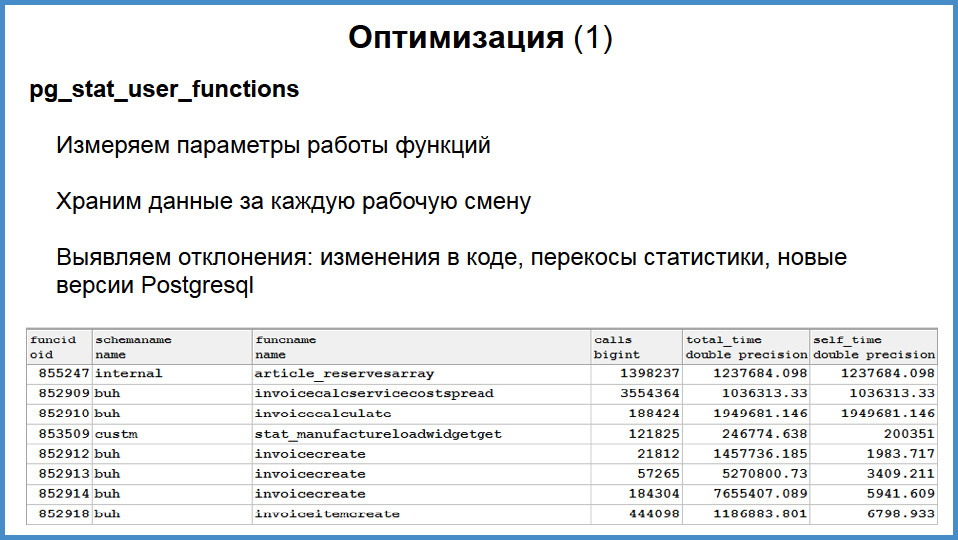
I will talk about programming a little, the programmer is bad, but I know about optimization . When all business logic is in stored procedures, then you always know who is at fault. Because whoever gets into the database, he will climb through the stored procedure, and thanks to pg_stat_user_functions , we know all about it.
What are we doing?
In this pg_stat_user_functions viewthere is a scheme, name of the tablet, the total number of calls, the total execution time and the own execution time of the function with sub-millisecond resolution, which is enough for all cases.

Twice a day, at 8 in the morning and at 8 in the evening, since we mostly have Moscow and St. Petersburg clients, we insert our own nameplate of the result of this view. We keep the snapshot in the morning and in the evening.
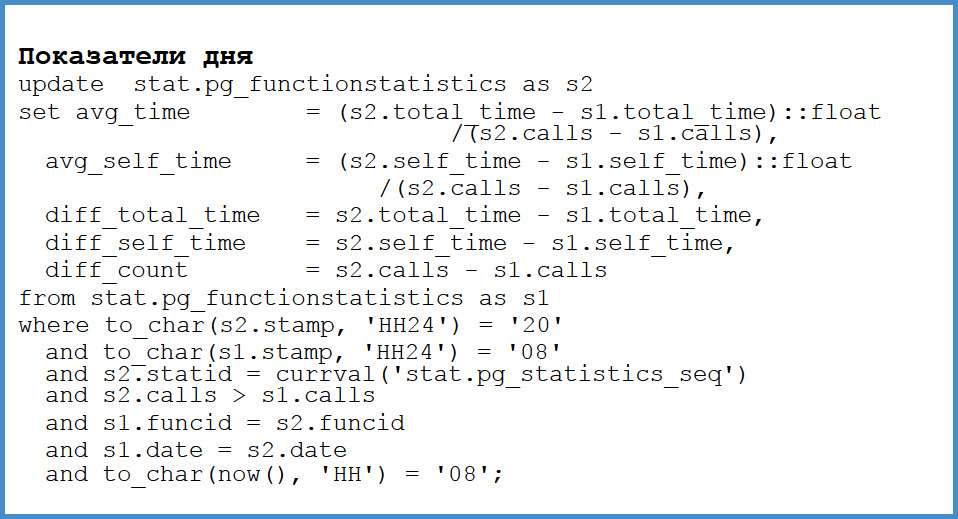
After that we update it. We calculate the delta between the number of calls, the delta between total time and the delta between self time. What does this give us?

As soon as something slows down, we just check. Over the past week, if we compare this week with the past, what function has become more frequent or more expensive? And we immediately find it. Moreover, there is a constant request that I have in the console, which shows the functions that have deteriorated. Where do these deteriorations come from? There are several reasons. First, the planner could skew , somewhere forgot the index , updated new versions and some algorithm used to work this way, and some sort of commercial. This is very quickly detected. That is, we do not need to chase with lanterns for an unknown request, which is not known from which frontend came, who called it. We immediately see the problem.
But pg_stat_function does not solve all problems. Why?First, the cursors. If there is a function that returns a cursor, it can fetch a minute, and the function worked for one millisecond. That is, you will not see slow cursors in the top, but we have many cursors.
The function has branching. For example, there is a function that launches an order. It can be started by human hands, there are a lot of rights checks. Either money came, they sent an event and we let the order go to work. That is, the branching of functions is when the same function in different conditions can be called in a very different time.
There are point loads . There are such business functions that are very important. For example, a person works there 15 minutes a day, but a lot depends on it. And slowly from a person the load grows, but he does not notice. This also comes to light. We go deeper.
We use pg_stat_statements . Also store data for the work shift at the beginning and end, and analyze all the same. But it gives a lot more.

This is what our query to pg_stat_statements looks like . What is great is that the atomic request of the stored procedure is pg_stat_statements. There is an expression there: we retrieved the data there, a semicolon, a line break, a comment, updated the data. Here are two of these fragments will fall into pg_stat_statements, including comments, and " custom formatting ", which is very useful.
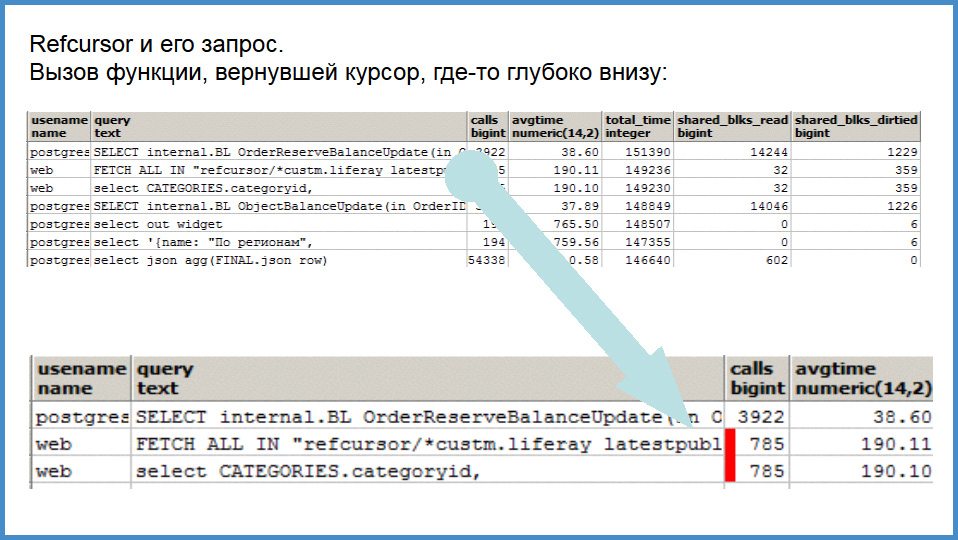
Here's what it looks like.At the top there is a general list, and below is a fragment of interest. The function that is called and returns a ref-cursor , inside which there is one atomic expression, falls into this “view” three times. The function itself that works instantly and is somewhere in the basement, 2 ms, falls. Atomic query of SELECT categories is hit and the cursor fetch is hit. They are easy to identify. That is, if you have a problem in the cursors, you do not know what function it is connected with, you can automatically analyze the atomic queries and cursors that coincide roughly in time, coinciding exactly in the number of calls, and you will compare them. Useful reception.
In the second line we fetch the named cursor. If your frontend is able to call the cursor by the name of this procedure when you call a stored procedure, then you will see it directly in the logs, anywhere. Also a useful trick.
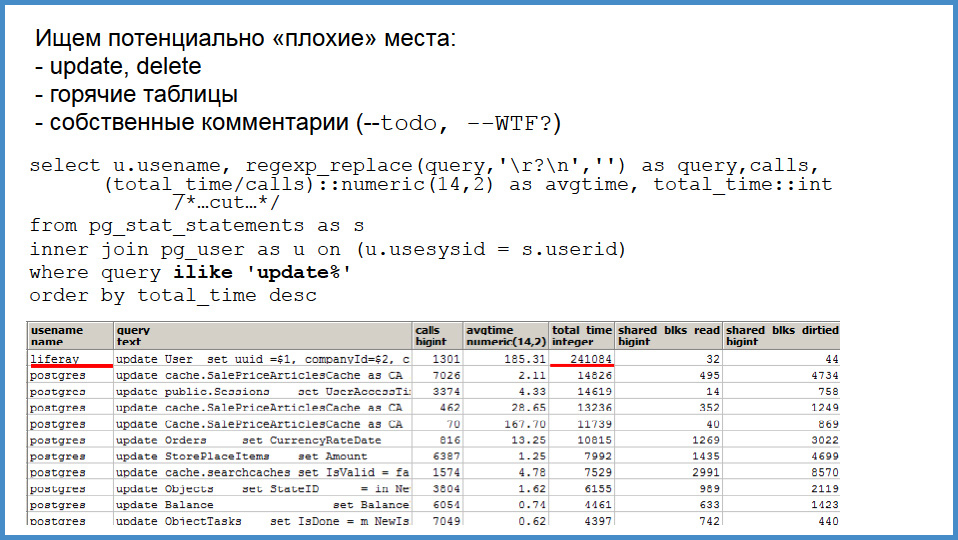
Thanks to pg_stat_statements , it’s easy to find potentially bad places. What kind? Firstly, an update is always expensive, and secondly, as I said, even your comments get into pg_stat_statements. Therefore, if someone over the request wrote “ TODO ” or “there is something out of order here”, then you go to pg_stat_statements and first of all you are looking for whether there are any queries with some of your dubious comments. And you quickly find them. It's very fast.
And now a little about the pain. Who managed to look at the second or third slide, our front-end site is based on Liferay . We cut out almost everything from there, but something remained. And something is hibernate which needs to be emulated that it writes to the table. Yes, this Liferay is writing a users tablet. In fact, he caches, that is, he caches a large part, but the little that we got, it got here. If we cut out Liferay with hibernate completely, then, actually, 20 times more will go somewhere into non-existence. I wanted to show the request Hibernate, but I realized that it does not fit. It's hard to deal with.
But once we had a problem with a supplier of popular business software. We have a system built on it, which we do not serve, the contractor has implemented. She issued an exception thatMS SQL server cannot execute a query larger than 64 kilobytes. We are told: you need to buy the enterprise version of 64-bit. In general, he says, the limitation of MS SQL Server, it is impossible to execute 65536 bytes request, this is not supported by any version. Due to the fact that there is a sales-manager, helpdesk-manager, junior, who wrote business logic, and somewhere else 10 meters away there is a person who wrote the 1C code generator, let's call them directly, do not reach it, believe that this is normal.
Why is this important to us? We are a small company, we have a small IT staff, we cannot afford such heavy technologies, because a lot of people have to share responsibility for these layers. Before this is hard to reach.

Optimization
It is quite short here, everyone probably knows about it. We have statistics on updates , inserts , delites in tables, dead tuples , statistics on references to indices. How can this be used? Very simple.If you consider that for one business transaction of an order from 10 positions each position must be updated once, then you start a transaction, remove counters, complete a transaction, remove counters and see that it has been processed 10 times. Sometimes it turns out that each position is updated n-factorial times, and n is the number of positions in the order. And you understand that theory is at variance with practice. You are looking for algorithms and you find them. These are cycles. Cycles are always a source of pain. These are forgotten where clauses , that is, we update the data with the correct values, but we update them more than 1 time, when we no longer need it, say “stop”, and it still updates.
Sometimes this is a subquery where DISTINCT was forgotten to do, that is, the WHERE query ...ID IN , and it returns many non-unique values, which causes problems. And, of course, forgotten indexes.

And finally, I said that sometimes there are rare business functions , when a person approaches them once a day and does it reluctantly, and the function runs slower and slower. The record was: for a person, from a 15-minute job turned into a 2-hour. And no one knew about it, not even its head. When we accidentally found it, there was just joy and a splash of champagne. That is, we must constantly study the log of stored procedures , top functions in pg_stat_statements , catch anomalies in pg_stat_functionsand just clean up the code. It's like painting the Brooklyn Bridge: we optimize the top-5, then there are more and more new, we walk in a circle. But this is a guarantee of user comfort.
In the end, we got rid of the temporary tables, the ones that caused the pain in 2009, because they had to be truncated on each transaction. We successfully get rid of legacy code , window functions , recursive queries . This is some kind of miracle. For the most part, all the code we wrote on this functionality is installed faster and is well read.
Finally, how do we debug a function if there is a difficult place: clock timestamp, note before, note after and you can see the time you can profile.
How do we care for the code?
As I said, we now have 3,000 functions there. Last year we made a very big update, we improved most of the business logic, updated it for the site, everyone was happy. We had a huge amount of code thrown out: idle interface, idle functions. How to get rid of it? Somewhere in your Eclipse or IDE IDEA, you can connect classes, methods, set it all up, but you don’t know if it’s really used in the application or not. If your business logic is entirely written in functions, then with the help of pg_stat_user_function you will find out if the function is called or not.
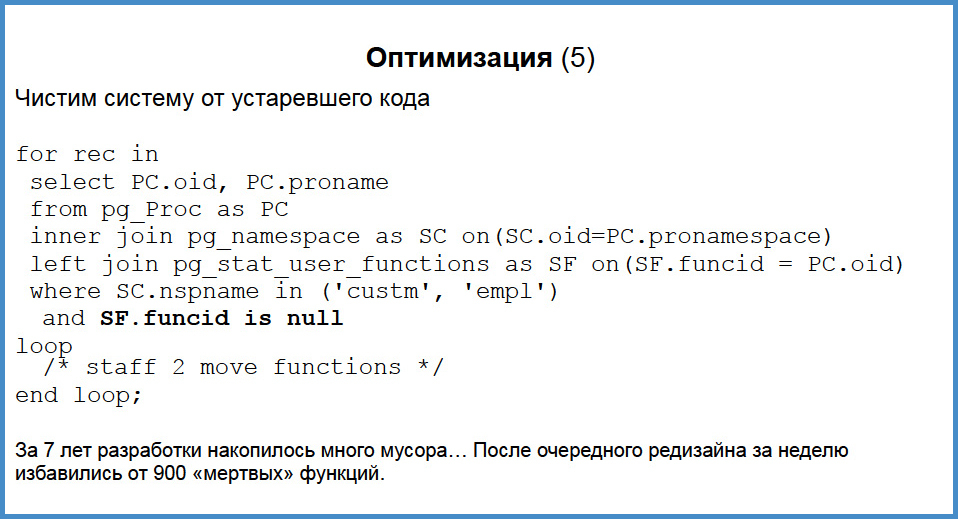
If you have worked for three months, look at the statistics and you will find functions that are not called at all. And in this way we have accumulated almost a thousand dead functions over the past 7 years. With the help of the query, we almost without thinking for a minute (maybe two hours thought), wrote a stored procedure that received the cycle names of these functions and the schema, and transferred them to the “ to-delete ” schema . To our surprise, in two weeks there were only two exceptions with missing functions. One function switched some limits, it was called a “divorce”, and the other was my personal one, I hadn’t been calling it out of some need for a long time.
That is, this is a good opportunity, which is probably unavailable in other cases. Not only can you profile and develop code in one integrated environment, you can do powerful code redesign in the same environment. Once we redid the SessionID data type, before we had no uid, we used int8. When we decided to hang out on the Internet, for compatibility with Liferay we had to switch to a UID. Using some scripts, analyzing pg_proc, we wrote a large SQL script that did DROP FUNCTION , CREATE FUNCTION and changed data types, and all this was done in one transaction in 8 minutes at night. 2500 stored procedures have changed.

Hopes and expectations
High expectations for JSON and JSONB: as I said, this is a problem with cursors, from which we will get rid of and get PL / Proxy just on a platter. Secondly, we have the expectation that we will transfer part of the interfaces to Android, and there JSON is very convenient. It is possible to denormalize well, having sorted all sorts of filters and ACLs for a site in JSON, should work very quickly, considering what wonderful things there are with indexes. We are very pleased BRIN indexesbecause we have analytics, but it will be rendered to another database. Both BDR and logical replication - we still do not know why we need it, but we really want to try. Firstly, it solves issues with analytics, that is, you can selectively drive out some data there to another database, and secondly, you may also want to make a distributed system (like Avito), although we don’t have to, as you know.
Well, we continue to prepare for you only the most interesting success stories from the leaders of both small but successful companies and major international holdings, such as Avito, Yandex, Zalando, Pivotal and others. Applications for reports can now be found on the conference website and vote for the most relevant topics for you!
Who are we?
In order to explain our choice, it is worth explaining the specifics of our company. If you open the Project 111 site (our programmers are already looking at whether the slashdot effect will be there), we will be very similar to an e-commerce online store, but we are not talking about an online store, we are B2B. That is, we have regular customers, there are a lot of them, marketing is going crazy, inventing new schemes, discounts, promotions and so on, so we have a rather complicated sales process that is long and takes almost a week. Our clients, partners on the site are full-fledged employees in the ERP system , that is, they use very many functions of the sales department, only they cannot pay for themselves. Therefore, our system is rather heavy, including at the front end.
')
We are a medium sized company. The numbers are not very big: we have 2300 users logged into the site (our partners with their discounts and conditions), but these are “heavy users”, that is, they create the same burden as an employee in a warehouse or in finance. We have long made a bet on the Internet, 97-98% of orders are placed online , 60% of orders are not in the hands of a sales employee, they automatically go to the warehouse.
How did you get the idea to build the systems yourself?
The beginning of the 2000s, when we were engaged in this, the word “highload” did not sound, the ajax did not seem to even exist. In general, there was some, Internet Explorer 5.5. The management of the company had a strict feeling that the future was over the Internet, that taking orders over the phone was bad , that either we would distribute our application among partners, or maybe we would have a website (and we had a website). Our site (domain) is registered like in 1998, 5 years later than that of Dell. And we looked around.
In the early 2000s, a couple of new columns with fresh burial ground appeared at the ERP system cemetery each year. And the choice around "what to buy," "what to build future systems for" was very difficult. That is, we were afraid of vendor locking, and, on the other hand, we did not understand the roadmap of these ERP systems. In addition, ERP-systems have fairly tight licensing restrictions, they still exist. If you think: why not take 1C, screw Bitrix to it and trade with might and main? 1C still has a clearly structured limitation, which does not allow to proxy its Web API. There is some kind of XML API, that is, you can pull the 1C method. But every connection that can theoretically be used by this method must be licensed. That is, if you expose a real-time service working with 1C to the site, then you should buy all the licenses. You have 10 thousand users, then you have to buy 10 thousand licenses, if they still exist at all.
There is a different approach. This is a stand-alone ERP system and a stand-alone website, there is some kind of exchange between them. But I said that we have a difficult business sales process: to calculate the cost of the order, we will probably ask a dozen and a half or two tables. These are volume discounts, historical discounts and discount lists, a contract of a specific client, a clause of a contract, a currency, some European price list has been picked up. To write this algorithm is in some way a pain. And if you have to write this algorithm in your ERP system? One person wrote. Then go sometime to a PHP programmer and say, here are 25 tables for you, just replicated in XML, and you also repeat this algorithm. Of course, he repeats, but it turns out that the first algorithm may have errors, and the second is not the case. So you do the same job twice.
Therefore, we decided to build a site-centric ERP , that is, one core that owns all the data, all the business logic, and all that is around is just interfaces. They already have some intelligence, but the business units are practically free. Two hours ago we discussed CMS systems and Bitrixes, as we observe our respected partners and market competitors, recently one of the companies switched to the next version of 1C. They reported that “the largest partner of 1C is some kind of gold, our team of programmers worked for a year and implemented it,” we see that they have lost all their functions for half a year. Why? Because they threw out the old site and they have to make a new one. Therefore, reserves are made by telephone. Well, the last factor, in addition to site-centricity, the fear of “boxes” is what the picture depicts. We had the belief that we could do it.
In general, it is considered that doing business logic on stored procedures is, as it were, not good . I was even shy. We have been doing this for many years, but Roman practically made me say, provoked that later at some stage it turned out that in fact there were a lot of people like us. I'm not the only one.
What are the myths?
Lost portability between different databases. Yes, there is. Difficult to maintain. Yes, the stored procedures in Eclipse are somehow not very, not there. How to deploy? Fair It is difficult to develop in a team. Indeed, you compiled your pl / sql-procedure, figak-figak, and someone else compiled it. It seems reasonable. And finally, if you start writing the stored procedure now, you have no sharding, how will you make distributed configurations using some kind of synthetic key? It also seems reasonable.
But from a technical point of view it is difficult to argue. Let's answer some children's questions. “Portability between databases, and who needs this at all?” Imagine such a dialogue. Client: “Tell me, can I transfer your application to another database?” But it’s not a question, though every day Microsoft - Oracle, Microsoft - Oracle. And who needs it?
Portability between databases is a positive function for the seller, who sells the product. But when you received this product and use it, it is not so important anymore.
Next point: difficult to maintain. Yes, it is difficult to maintain a boxed product, if you have 100 installations throughout the country, each one has a separate stored procedure. Suddenly, the client there handles his playful something compiles and immediately nervously, how to deploy, how to roll? Somehow difficult.
Again, if you are a consumer of this product, you yourself wrote and use it yourself, you do not have 10,000 installations, this is not your problem. Is it difficult to keep the box in a big team? We are a small business, we are not “HighLod”, not Yandex, not Google, we are an ordinary taxpayer. At a time when Avito’s open spaces are plowing highload, I don’t know, Yandex, Mail.RU, we are a regular taxpayer and stand knee-deep in 1C. We have no money for big teams, we have no money for programmers with such a square head. We have a small team. If there is time left and it will be interesting, I will tell you how we actually designed, implemented.
But by the time of launch, support for legacy code, the old system, the very 1C and others, and 2.5 people were engaged in writing, updating the system, migration: 2 real programmers and me. That is, it’s not about big teams.
What do we have left?
Myths left : sharding, distributed configurations . It's very easy to argue against sharding: guys, have you read about Skype? They have everything on stored procedures, pgbouncer , pl / proxy, and more. If your database does not allow the application to climb directly into itself, it can only pull stored procedures, then what is inside - you deceive any application. That is, to do sharding on stored procedures and so on - this is not what is possible, but necessary, if your requests are necessary. We have pl / proxy , dblink , foreign data wrapper , which is not. Are you sure you need to do sharding right away? This was already mentioned on the reports yesterday. In general, we now know that for medium-sized businesses, if you are not Mail.ru, not Yandex, then maybe this is not so and important.
Why PostgreSQL?
First of all, mature pl / pgsql . He appeared in the 98th or even the 97th year. Strictness, functionality and academic approach. If you look at the Postgres documentation, it’s written like a good tutorial. That is, when we take a sysadmin to work who needs to be able to read the documentation, I test it using FreeBSD manuals and documentation, that is, there is good English, everything is clear and in one place. Open source and free license - there is nothing to say, various risks are reduced. If we implemented the 1C seven in 2005, then we would have experienced a lot of pain and would have changed several information systems. Changing the database has nothing to do with it.
And somewhere from the 98th year we had such a funny saytik, in the 98th year it was launched and worked on PostgreSQL. I was not there yet, I joined after a year and a half. In my opinion it was release 6.4. In addition, an understandable development plan. We still had only plans for a public website, not closed to partners, but for everyone, when anyone can come, register. We already knew that a half or two years and will be T-Search. After all, developers open to interaction, a good community, you can understand what will happen over time, and make realistic plans. And they come true.
The bad and good sides of stored procedures. Imagine that you are not a giant IT company, you are a business that is not satisfied with a boxed system, you need your own application server. If you go along the classical path, then something like that in Java can be written in C, but the programmer’s incentive must be very high. And all these pains will rest on these programmers. You need to think about the distribution of memory, about the leaks that will inevitably be, you need at least some kind of scripting language, because it is impossible for a working business that earns money, trades, or “deploy” three times a day. Business must adapt on the go, you can not stop. And scripting language allows you to change business rules on the go. You also need some kind of profiling. In general, not so easy. So, posgres takes it all on himself.
We do not think about memory leaks at all, we have never had any problems. We have been online there for several months. And if it hurts us a lot and we want to upgrade, we are updating, but we don’t stop the run-time at all. We have no memory leaks. These are things that are solved for us by very good programmers. Us as an ordinary trading business is at hand. Scripting language - pl / pgsql, take it and use it. Verification of rights, etc., profiling - this will be later. But also the problems are solved.
That is, we get an application server for dummy, which has no restrictions , there is no ORM that binds your hands, that is, you can do anything and not experience some kind of architectural consequences. In some limits. Simple language, low threshold for entry. Junior, who was not given a production, but showed how and what to write, if he has relational thinking, it is achieved, in my opinion, at the age a little earlier than object thinking, he is already able to produce normal code, which can already be put into production by looking. I retire in 20 years in fact, and I still have the ability to understand the pl / pgsql code and write less myself, but I can optimize the code. That is, this knowledge is stored for a long time.
Safety is something we thought about at the beginning of the 2000s, it is very difficult to push SQL injection through the stored procedure, you really need to shoot yourself in the foot, you need to aim well. Why was this important then? Everyone wrote their CMS-systems, every second was full of holes. It seems to me that in 2001-2002, with a bunch of CMS and 15-20% of sites, it was possible to dig some injection in 10 minutes.
The next item in the slide is very controversial - it is isolation from the interface . We have thrown out front-end applications several times, some internal development or a site that is inaccessible to the final customer, only for partners. There was not much code there, it was quickly transferred to another technology and you didn’t lose business logic at all. The isolation from the interface is somewhere good, somewhere is evil. And when our business logic has nothing to do with representation, we can change the technology on the frontend.
Let's go back to the beginning of the 2000s. How many interface technologies have changed there? You must program in Visual Basic, on the Internet Information server. Someone sawed on pearl, PHP, Ruby, nowhere to go from all these words. Interface technologies change very quickly, and SQL is still alive. The very old function in our system was written in 1998, as a relic to it you approach. True, we sawed it the other day, but this code can work. That is, what we wrote 12 years ago will work on that same run-time, at least in this circle no one will look contemptuously: “and he is in PHP”. SQL is a normal language, although somewhere limited. A long time life of business logic is useful.
Bad sides
Too good insulation , yes. In principle, if you have a good application server, it has business logic, acl's are closely related to interfaces. We have two interfaces: an internal employee program and a website. And both applications are very different. Sharing this knowledge and skills was not as valuable as getting a long-lived application server.
No well- integrated development tools - yes, that’s real. If some connection with the version control system was integrated into pgAdmin , if the code there was slightly better highlighted, substituted ... Here we still have pain, I admit. Some of us work in pgAdmin, some people like ems-sql for auto-substitution, but there is a lot of work to be done.
Next moment. I said that we do not solve problems with caching , we do not solve problems with memory allocation , but if you don’t have enough caching that the program gives you, you will have new layers of abstraction . It's not very good. If you have a programmer who wrote business logic cannot satisfy the front-end, then some middleware appears (which most likely a front-end programmer in some Java or C writes), which does this for himself. In fact, this is a difficult problem. Because caching and cache invalidation is the hardest of two problems , the most difficult in theory. Everybody knows the second - give the correct names to the variables.
Sometimes when writing stored procedures, it is difficult to stop in time. In Java, our programmer caught me writing a stored procedure that created letters on pl / perl and mime and then sent them. I won't do this anymore.
What's inside?
Now we have posgres 9.4. Development started at 7.4. Did anyone hold 7.4 in his hands? Writing stored procedures? Someone felt this pain. For those who did not see, the body of the stored procedure was in single quotes. And there is not exactly the syntax is not highlighted, everything was purulent brown. But there were brave people who decided on this. Our business logic is 3,000 stored procedures , they are not very large, you can count them by code size. Note that if at the beginning we wrote you a lot of code, now, over the last 5.5-6 years, not so much. The code is quite plump, there are comments, function headers. This is most likely not the code that Andrei talked about: which are hard for 80 lines per day for programmers. The bases are well normalized , there are 700 tables, hundreds of them are analytics, which we will soon pull out. We are probably growing a little faster, but the base is about that.
We love short transactions . Short transactions - this is a high speed, there is no “overhead” on swollen indices, waiting for locks. If we can write a short business function, we make it short. We love “constraints” , foreign keys, and so on, because it eliminates a huge number of errors. Last year, we ran into a “violation” violation in one function that worked for almost 6 years. And there was a mistake in it that very rarely manifested itself. It is difficult to give an example. But if the storekeeper takes one box with his left hand, another box with the right hand, presses the barcode scanner with his nose and moves something else, only then this error occurred. And she never arose! We caught her because constraint worked. In general, constraints are a blessing, it does not allow you to shoot yourself in the foot.
We say that the tables are normalized, but we love denormalization . Denormalization is mainly needed for the site. We are stuffing a bunch of different data into a rather wide table, and on our site we have fast enough interfaces. Easy to give, few “joins”.
We hate ORM and “code generators" . Our own ideology, ORM, contradicts, but I can show you, when we stepped on it, why it upset us.
The frontend is tomcat + nginx , it has several products running on it. In addition to the site, there are also Intranet products (CMS and CRM are different), reporting (freestanding serv in Jasper). There is an internal application that started on Borland C Builder, now it is Embercadero (almost does not develop, there are less and less of such interfaces). All this works through pgbouncer , about which individual thankful words. There is still a lot of all: analytics, seo, asterisk, which directs calls. It is also integrated into our database and uses the same business logic.
Go ahead.In fact, production is one server , the second is a replica, which is for tests and some offload for analytics. The servers are quite ordinary, but we did not save on hardware. As you can see, they are not heavily loaded. LA is no higher than three, but it may be more serious now, in summer, in winter. Why?In a trading company, unlike the social network, there is a very small hot data set. Active products out of 100 thousand - twenty, out of 100 thousand customers - active pieces 10. In principle, despite the fact that the base is growing, the company's money grows, customers arrive, still this is not enough, it is well trampled down in memory. I can reveal the figures: the gross margin (net profit of business before tax) 40 minutes per season allows you to buy such a server. And this, again, returning to the word about sharding.
Think, these figures say that if it is economical to write code, do not read the “SELECT *” server into the applicationfrom two tables and not joining them in Java cycles, then you can get by with a very modest iron. And this we still do not use a replica for offload. That is, reading requests from the site go to the combat cluster.
We do not use SSD . I have to admit, there was such a mistake: we have a network engineer who tests the servers very meticulously, and we know that the best way to test a raid is to assemble a RAID5. And we are now in “production” in RAID5 by mistake, we accidentally noticed when our battery died.
Go ahead.We ended up laughing, but here it will be somewhat more boring. How does it work? As we have said, no application directly enters the database with dirty hands, each application operates under its own role. All stored procedures are laid out in different ways.
What do we see here?
We have folder roles like web group and employer group , which have almost no rights. And in these roles, folders are pushed into application roles. The application “role for the site” (web) and any role “employer” (for the “emploorsky” application). Note the statement timeout of 10 thousand. Why is this done? This means that if the site manages to pull such a request, which will not be fulfilled in 10 seconds, the request will be thrown out. In fact, the answer is simple. If you have something stuck somewhere, and users on the site begin to pull it, and the bases are not given away, then everything only gets worse. It is necessary to detach insolent. Note that the roll back transaction is still warmed up buffer cache. Even if she did not give anything to the user, she still put it in the buffer cache. When you have several people received an exception (10 thousand people, 2 of them received), they warmed the base of the cache, and the third request will come success. If you do not do this, then you will overflow with pool, Java will understand , pgbouncer may not have enough sockets.
Next we create the schemas and distribute the rights to the schema to each application. Here it is obvious that the customer can both include a web application (WebGroup) and an application from the internal group. If a person is able to do everything inside the office, then even if everything is on the site. And in the very last paragraph, we forbid applications to see the code of the procedures being entered and the data schema.
In fact, this is already too much. If someone hacks your application, it will not see your secret tables. He will not be able to read the data anyway, and here he will not even see the name of the stored procedures.
What are the functions?
The first and only function that does not have an in_SessionID input parameter is authorization. Not individuals work with us, but partners, it is 50a person is in the same company, so it’s more convenient for us as a domain registrar: a company login, one login and password. This function returns the session, and pay attention to the definition - it is a security definer, it has the right to pull 2 groups, an internal application and an external one.
All other functions have the SessionID input parameter - this allows you to log in once, associate a session with a user, issue it in a browser cookie or into the application's memory, and pull all other functions. They always have the Session input parameter and are manipulated inside to recover who causes them. That is, the function OrderCreatewhich is called from the site or from the internal application, it works from a single user. Inside it, we can determine who specifically of the subjects of the system is pulling it at the moment.
Functions that are on the site, additionally covered. It is clear that the OrderCreate function should have the Customer input parameter , for which customer we set the order. Here we cover it. CompanyID appears through the session, and one company cannot create an order for another.
Next you need to deal with the ACL. Here I will quickly slip through, because this is a deep area and will have to be cut a lot. Each domain table (customers, campaigns, orders, contracts, price items) has a projection on the table of objects. That is, the customers table entry has the object_id table entry and object_type = 84, as I recall. What does this give?On this unified representation of objects to the subject area, you can attach properties, life cycles, some restrictions, locks and, on top of this, construct a rights check.
Therefore, within each function of the domain that distributes orders, ships the machines, there is a function that checks rights. We pull this function by passing the object ID, the object type and the “action” type to it. She inside herself either says OK, or throws an exception . If we throw an exception , it is very easy to catch it in the application. Any connector (JDBC, any custom) these exceptiongood catches and transfers to the client. The user receives an error and can analyze it. If we do not need to diagnose an error on the client, but simply filter something, then we pass such a parameter. It seems quite cumbersome, but in fact the verification of rights in this way is more an imperceptible part of the programmer’s work, does not interfere with creating business logic, only creates unification.
Was everything without problems?
Not.This is a sad picture that describes the moment when we started. Look at the bottom of the picture - autumn 2009. What we got. We had a website, it was about 200 people, 300, they grew. In the pool, 5-6 connections were issued simultaneously in one step, and another 60-70 connections were occupied by the internal application. We decided that since within the company 60 users work, then why are there any pools, they worked directly. Suddenly we felt pain. A server with 16 cores, that is, 4 sockets with 4 cores for 2009 was pretty cool, and when we saw LA 60 , on 16 cores ...
What caused the reason?
This problem no longer exists, but I have to say it to you, this is such as auto-training. And secondly, to caution how to: always listen to the elders. We thought we didn't need pgbouncer. In principle, it is not needed if we did everything normally. But in each session that we opened on the next page, we have initialized stored procedures of the ON COMMIT DELETE ROWS type . In the pre-9.1 or 9.2 version there was a feature that we later learned about. It turns out that at the beginning of each transaction, on each temporary label with type ON COMMIT DELETE ROWS, TRUNCATE was fed into each connection and then, at the end of the transaction, TRUNCATE was also applied . That is, if you have 100 connections, each with 30 temporary tables of type ON COMMIT DELETE ROWS, then you have 3000 temporary tables. And even if none of these tables were involved in a transaction, this TRUNCATE is stillserved twice. You understand what was happening.
How did it help us that Postgres is open source?
We have a "sishny" programmer, who climbed over after some time of pain and saw where transactions open and close approximately. Put the "notes", and saw that this truncate occurs. I climbed onto the website of the website and wrote to the newsletter in broken English that with each transaction you do this and that. I was shocked when, in response, Tom Lane said, “Yes, I guess. It is hard to be surprised that we clean the tables temporary, but the fact that we, including those that do not work, is not very good. ” And then Bruce Momzhan pulled himself up , whom I did not expect at all, if he is here, then thank him very much. And he wrote:"Guys, do not worry, I will include it in my personal todo-list and try to have it pierced in the official todo-list." And so it happened. We immediately found a solution. First, I compiled pgbouncer, it took 7 minutes there. 7 minutes after the illumination, we saw this. Ed .: See the right part of the graph on the slide]. That is, the load fell, it just became super-comfortable, the connections stopped hanging. There were some problems during the start of transactions, there was a slight delay of 15 ms, but you could live with that. In my opinion, until the end of the year we lived with this scheme, having increased the number of clients for this season three times. Thanks to Bruce and thanks to the community.
There are problems. There is such a line, in which there is an error and even a hint in which it is. There is a lack of pl / pgsqlAs a code of business logic, although the base is strict and there are a lot of opportunities to protect yourself, the code is not verified very well. Whoever did not notice, there is a comma between the val2 and val3 . Guess what result will produce a notice , if we in all vals (i1, i2, i3, i4) transfer edinichki. In the “notice” will be 4 numbers. What kind? The first and second - edinichki , and the third and fourth? This will be NULL . And how to live with it? Seeing the space, the poster simply ignores everything else. I also wrote about this in the newsletter, I do not remember who answered, Gregg Smith , it seems: "this is legacy, because pl / pgsql is a legacy of SQL code."The syntax that we can afford in SQL is translated here. This is yes, this is a problem, but this is one of the very few problems we have encountered.
The next issue is documentation . This is a story about the most serious accident that we had. If you put DROP CASCADE on a table, then you will lose all the exception in the notice , all objects that will be deleted in cascade will be shown. If you have 5-6 tables linked by foreign key , you say truncateaccording to the table, then you will be answered that the second table will be cleared. He will not say that 4 of them will be cleared. And we ran into it. I was really told in the documentation that this was necessary, but such things happen.
The last problem is not a problem, it is rather a surprise. We decided to experiment with pl / proxy to read-only off-load requests to the replica. It turned out that pl / proxy does not support ref-cursors , and we very much love ref-cursors. Because any connector to the database supports cursors, they are easy to modify, they, unlike the record, can be transferred between functions. Everything is just built on cursors. If there was JSON , we would build on JSON. We are now considering whether to transfer the front-end of the site to JSON. Then we will be able to unload through pl / proxy and achieve a refutation of the very same myth that supposedly cannot be, having built everything on stored procedures, to “ shard ”. You can, if you do not use the cursor.
How is our life going?
I will talk about programming a little, the programmer is bad, but I know about optimization . When all business logic is in stored procedures, then you always know who is at fault. Because whoever gets into the database, he will climb through the stored procedure, and thanks to pg_stat_user_functions , we know all about it.
What are we doing?
In this pg_stat_user_functions viewthere is a scheme, name of the tablet, the total number of calls, the total execution time and the own execution time of the function with sub-millisecond resolution, which is enough for all cases.
Twice a day, at 8 in the morning and at 8 in the evening, since we mostly have Moscow and St. Petersburg clients, we insert our own nameplate of the result of this view. We keep the snapshot in the morning and in the evening.
After that we update it. We calculate the delta between the number of calls, the delta between total time and the delta between self time. What does this give us?
As soon as something slows down, we just check. Over the past week, if we compare this week with the past, what function has become more frequent or more expensive? And we immediately find it. Moreover, there is a constant request that I have in the console, which shows the functions that have deteriorated. Where do these deteriorations come from? There are several reasons. First, the planner could skew , somewhere forgot the index , updated new versions and some algorithm used to work this way, and some sort of commercial. This is very quickly detected. That is, we do not need to chase with lanterns for an unknown request, which is not known from which frontend came, who called it. We immediately see the problem.
But pg_stat_function does not solve all problems. Why?First, the cursors. If there is a function that returns a cursor, it can fetch a minute, and the function worked for one millisecond. That is, you will not see slow cursors in the top, but we have many cursors.
The function has branching. For example, there is a function that launches an order. It can be started by human hands, there are a lot of rights checks. Either money came, they sent an event and we let the order go to work. That is, the branching of functions is when the same function in different conditions can be called in a very different time.
There are point loads . There are such business functions that are very important. For example, a person works there 15 minutes a day, but a lot depends on it. And slowly from a person the load grows, but he does not notice. This also comes to light. We go deeper.
We use pg_stat_statements . Also store data for the work shift at the beginning and end, and analyze all the same. But it gives a lot more.
This is what our query to pg_stat_statements looks like . What is great is that the atomic request of the stored procedure is pg_stat_statements. There is an expression there: we retrieved the data there, a semicolon, a line break, a comment, updated the data. Here are two of these fragments will fall into pg_stat_statements, including comments, and " custom formatting ", which is very useful.
Here's what it looks like.At the top there is a general list, and below is a fragment of interest. The function that is called and returns a ref-cursor , inside which there is one atomic expression, falls into this “view” three times. The function itself that works instantly and is somewhere in the basement, 2 ms, falls. Atomic query of SELECT categories is hit and the cursor fetch is hit. They are easy to identify. That is, if you have a problem in the cursors, you do not know what function it is connected with, you can automatically analyze the atomic queries and cursors that coincide roughly in time, coinciding exactly in the number of calls, and you will compare them. Useful reception.
In the second line we fetch the named cursor. If your frontend is able to call the cursor by the name of this procedure when you call a stored procedure, then you will see it directly in the logs, anywhere. Also a useful trick.
Thanks to pg_stat_statements , it’s easy to find potentially bad places. What kind? Firstly, an update is always expensive, and secondly, as I said, even your comments get into pg_stat_statements. Therefore, if someone over the request wrote “ TODO ” or “there is something out of order here”, then you go to pg_stat_statements and first of all you are looking for whether there are any queries with some of your dubious comments. And you quickly find them. It's very fast.
And now a little about the pain. Who managed to look at the second or third slide, our front-end site is based on Liferay . We cut out almost everything from there, but something remained. And something is hibernate which needs to be emulated that it writes to the table. Yes, this Liferay is writing a users tablet. In fact, he caches, that is, he caches a large part, but the little that we got, it got here. If we cut out Liferay with hibernate completely, then, actually, 20 times more will go somewhere into non-existence. I wanted to show the request Hibernate, but I realized that it does not fit. It's hard to deal with.
But once we had a problem with a supplier of popular business software. We have a system built on it, which we do not serve, the contractor has implemented. She issued an exception thatMS SQL server cannot execute a query larger than 64 kilobytes. We are told: you need to buy the enterprise version of 64-bit. In general, he says, the limitation of MS SQL Server, it is impossible to execute 65536 bytes request, this is not supported by any version. Due to the fact that there is a sales-manager, helpdesk-manager, junior, who wrote business logic, and somewhere else 10 meters away there is a person who wrote the 1C code generator, let's call them directly, do not reach it, believe that this is normal.
Why is this important to us? We are a small company, we have a small IT staff, we cannot afford such heavy technologies, because a lot of people have to share responsibility for these layers. Before this is hard to reach.
Optimization
It is quite short here, everyone probably knows about it. We have statistics on updates , inserts , delites in tables, dead tuples , statistics on references to indices. How can this be used? Very simple.If you consider that for one business transaction of an order from 10 positions each position must be updated once, then you start a transaction, remove counters, complete a transaction, remove counters and see that it has been processed 10 times. Sometimes it turns out that each position is updated n-factorial times, and n is the number of positions in the order. And you understand that theory is at variance with practice. You are looking for algorithms and you find them. These are cycles. Cycles are always a source of pain. These are forgotten where clauses , that is, we update the data with the correct values, but we update them more than 1 time, when we no longer need it, say “stop”, and it still updates.
Sometimes this is a subquery where DISTINCT was forgotten to do, that is, the WHERE query ...ID IN , and it returns many non-unique values, which causes problems. And, of course, forgotten indexes.
And finally, I said that sometimes there are rare business functions , when a person approaches them once a day and does it reluctantly, and the function runs slower and slower. The record was: for a person, from a 15-minute job turned into a 2-hour. And no one knew about it, not even its head. When we accidentally found it, there was just joy and a splash of champagne. That is, we must constantly study the log of stored procedures , top functions in pg_stat_statements , catch anomalies in pg_stat_functionsand just clean up the code. It's like painting the Brooklyn Bridge: we optimize the top-5, then there are more and more new, we walk in a circle. But this is a guarantee of user comfort.
In the end, we got rid of the temporary tables, the ones that caused the pain in 2009, because they had to be truncated on each transaction. We successfully get rid of legacy code , window functions , recursive queries . This is some kind of miracle. For the most part, all the code we wrote on this functionality is installed faster and is well read.
Finally, how do we debug a function if there is a difficult place: clock timestamp, note before, note after and you can see the time you can profile.
How do we care for the code?
As I said, we now have 3,000 functions there. Last year we made a very big update, we improved most of the business logic, updated it for the site, everyone was happy. We had a huge amount of code thrown out: idle interface, idle functions. How to get rid of it? Somewhere in your Eclipse or IDE IDEA, you can connect classes, methods, set it all up, but you don’t know if it’s really used in the application or not. If your business logic is entirely written in functions, then with the help of pg_stat_user_function you will find out if the function is called or not.
If you have worked for three months, look at the statistics and you will find functions that are not called at all. And in this way we have accumulated almost a thousand dead functions over the past 7 years. With the help of the query, we almost without thinking for a minute (maybe two hours thought), wrote a stored procedure that received the cycle names of these functions and the schema, and transferred them to the “ to-delete ” schema . To our surprise, in two weeks there were only two exceptions with missing functions. One function switched some limits, it was called a “divorce”, and the other was my personal one, I hadn’t been calling it out of some need for a long time.
That is, this is a good opportunity, which is probably unavailable in other cases. Not only can you profile and develop code in one integrated environment, you can do powerful code redesign in the same environment. Once we redid the SessionID data type, before we had no uid, we used int8. When we decided to hang out on the Internet, for compatibility with Liferay we had to switch to a UID. Using some scripts, analyzing pg_proc, we wrote a large SQL script that did DROP FUNCTION , CREATE FUNCTION and changed data types, and all this was done in one transaction in 8 minutes at night. 2500 stored procedures have changed.
Hopes and expectations
High expectations for JSON and JSONB: as I said, this is a problem with cursors, from which we will get rid of and get PL / Proxy just on a platter. Secondly, we have the expectation that we will transfer part of the interfaces to Android, and there JSON is very convenient. It is possible to denormalize well, having sorted all sorts of filters and ACLs for a site in JSON, should work very quickly, considering what wonderful things there are with indexes. We are very pleased BRIN indexesbecause we have analytics, but it will be rendered to another database. Both BDR and logical replication - we still do not know why we need it, but we really want to try. Firstly, it solves issues with analytics, that is, you can selectively drive out some data there to another database, and secondly, you may also want to make a distributed system (like Avito), although we don’t have to, as you know.
Well, we continue to prepare for you only the most interesting success stories from the leaders of both small but successful companies and major international holdings, such as Avito, Yandex, Zalando, Pivotal and others. Applications for reports can now be found on the conference website and vote for the most relevant topics for you!
Source: https://habr.com/ru/post/326758/
All Articles