How we did ML Boot Camp III

March 19 ended the third machine learning championship on the platform ML Boot Camp . 614 people sent solutions and fought for the top prize ー MacBook Air. For us, this is an important project: we want to expand the community of ML-specialists in Russia. Therefore, even a novice can understand our tasks. Theoretically ... Professionals compete due to the complexity of metrics and a large number of task parameters.
From the second contest a lot has changed. We doubled the number of participants, screwed a new metric to the server, fixed bugs and created the ML community in Telegram . We tell how the third contest was held.
Came up with a task
In the first contest, we determined the class of a sequence of zeros and ones. In the second, we evaluated the performance of machines for a real task, based on the list of system parameters.
All this is great, but it’s not always clear from the outside why. In the third championship we wanted to show the maximum applicability of machine learning in real projects. Therefore, they brought the task closer to the products of the Mail.Ru Group ー games. We offered to predict the behavior of the user according to his data for the last two weeks. Participants received at the entrance 12 game signs:
- maximum game level
- the number of levels that the player tried to pass
- number of attempts at the highest level
- total number of attempts
- average number of moves at completed levels
- number of used boosters
- number of boosters used during successful attempts (player passed level)
- number of points
- number of bonus points
- number of stars
- the number of days the user played the game
- did the player return to levels already passed
According to these signs, the contest participants guessed whether the person will remain in the game or leave it. The data was collected from 25 thousand real users of one of the online games Mail.Ru Group and anonymized. This task is much better practically applied. She looks textured. We love such tasks, therefore:

Chose the metric
And wrong with her
Initially, we suggested that participants send us a file in which a discrete answer for each user would be stored, whether it will remain in the game: 0 (no) or 1 (yes). At this point, we screwed up a bit and mixed up the metric. It turned out that we were going to measure the success of the sample using the average error (MAE). This metric considers the differences between each proposed answer and the correct answer, then adds them together and divides by the number of answers.
The fact is that MAE is not intended for discrete values, which participants immediately told us. In fact, it gives the same result as accuracy (the number of correct answers divided by the number of questions).
We could just change the name of the metric to accuracy or suggest sending the probability of user’s departure. But after talking with the participants, we decided to move on to avoid hacking the leaderboard.
Scared of hacking leaderboard
The situation in which a participant achieves a “perfect” answer in a test sample can be called a leaderboard hacking. On a test sample, hacking does not guarantee victory. With the accuracy metric, you can simply calculate all the correct answers and get 1. Obviously, this does not work on the final sample, where the chances to guess the selection will be 50/50.
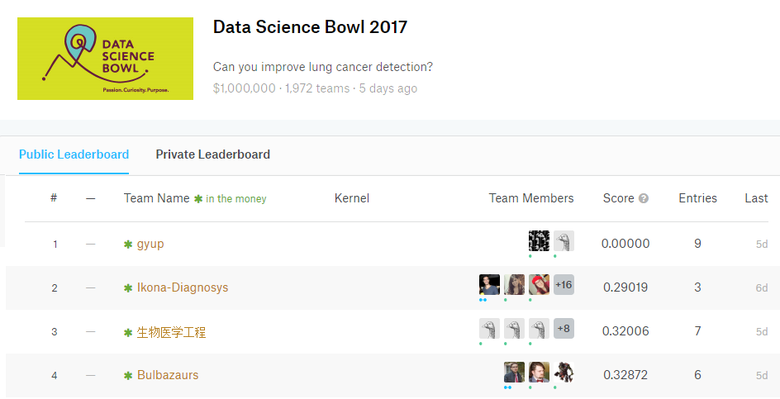
Hacked leaderboard in the championship at Kaggle with a prize fund of $ 1 million. In gyup, the ideal result is 0 with a logarithmic loss function (LogLoss) as a metric. It is a pain for any organizer of such championships.
Hacked leaderboard scares potential participants from the championship. They look and think: "Why should I waste my strength if that type has already done perfectly." They do not know if there is a really powerful algorithm behind his estimate.
Thought of sensitivity metrics
How much one error affects the whole result - let's take it for the sensitivity of the metric. In the case of accuracy, we could get too small a gap between the top players and the rest, because the error affects the result linearly. And this is extremely offensive for the tops (it is always pleasant to win by a wide margin), and for the rest (it is annoying when it seems that you are a bit weak, although there is a gap between you). In addition, there was a danger that people with exactly the same score would be in the top. And then what to do? A limited amount of prizes :)
With other metrics, the error affects the result more strongly. With a standard error, for example, it is squared. We tried to find a sensitive enough metric so that the participants had where to turn.
Chose a logarithmic loss function
Having scrambled for some time between the ROC , the root-mean-square error (RMSE) and the logarithmic loss function , we chose the latter as a criterion:
This function is non-linear, has a large range of values and is very sensitive to gross errors. If you say that the user is 100% gone, and he suddenly does not go ー you're in the deep ... "Punch" it is much more difficult.
The behavior of Loglossa compared to MAE can be estimated on the graphs:
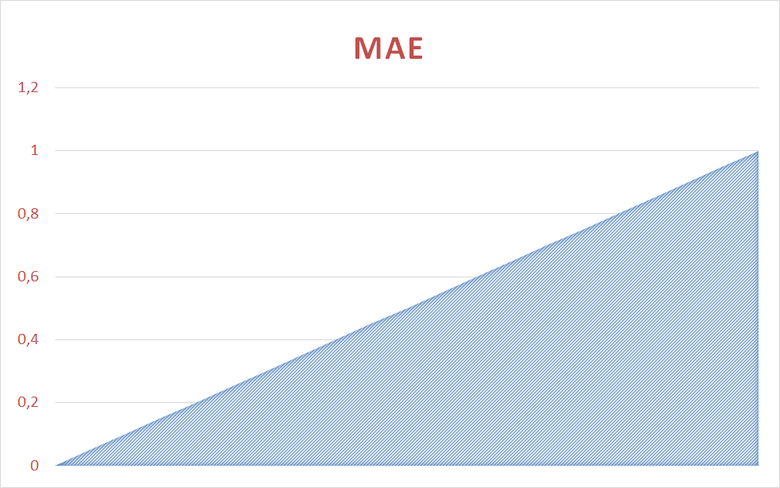
The average error varies linearly from 0 to 1
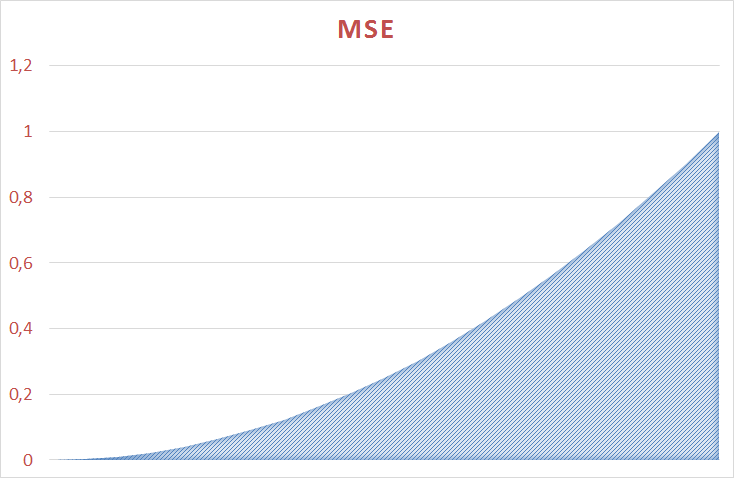
The average error varies nonlinearly from 0 to 1
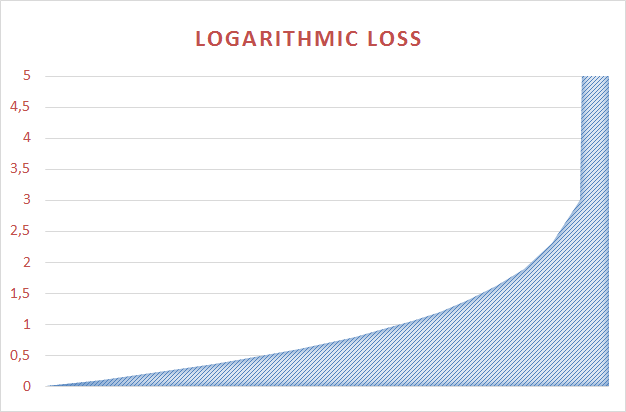
The logarithmic loss function varies nonlinearly from 0 to 34.6
Monitor results
With the new criteria, the work of the participants was in full swing, but the result was average. Most score quickly reached 0.38 and got up. The metric did not allow to move from this point.
At a certain moment, for the sake of motivation, I challenged the participants, saying that I would shave my head if they could climb at least 0.36 :). During the championship this did not happen.
Mikhail Karachun (winner) at the third attempt achieved a criterion of 0.3856 on the test sample and 0.3869 on the final one. By the finish of the championship, he received a result of 0.3808 on the test and 0.3814 on the final. For this, it took another 125 shipments.
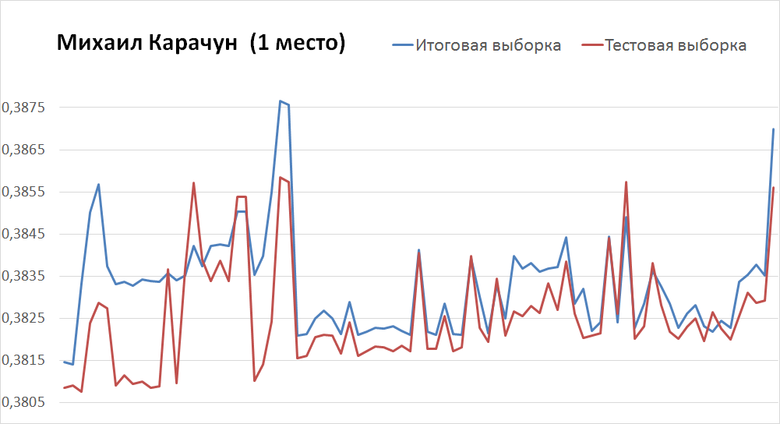
Latest shipped ー left
Yevgeny Tsatsorin also started with vigorous 0.3832 (test) and 0.3851 (total) and in 40 shipments came to the final 0.3818 (test) and 0.3816 (total). Note that his final decision gave a better result on the final sample than on the test one. The graph looks very smooth, nice; there is a feeling that in a couple of days Eugene could come out on top.

Latest shipped ー left
Ivan Tyamgin from the third attempt came to 0.3984 (test) and 0.3995 (total) and for 100 shipments rose to 0.3807 (test) and 0.3816 (total).
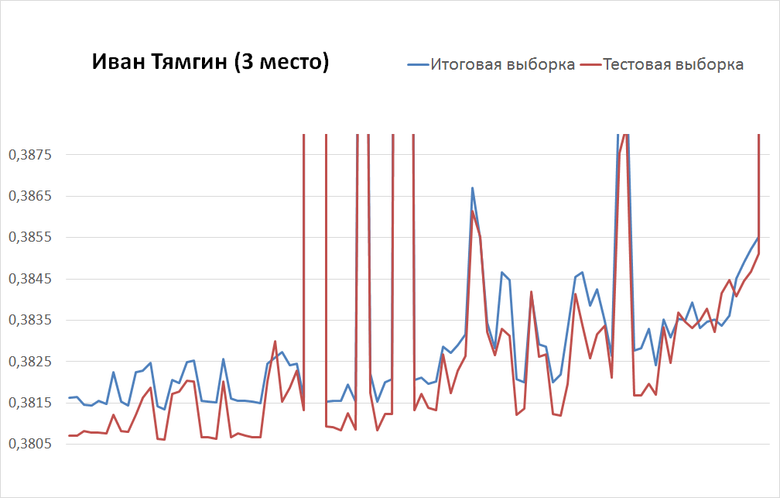
Latest shipped ー left
Summed up
After the opening of the final sample in the leaderboard, changes occurred. Ivan Tyamgin turned out to be one of the most stable: he retained his third place and lost only 0.009 when changing the sample.
Andrei Selivanov, the winner of the best solution on the test sample (0.3796), was already in 261st place (0.3844). Mikhail Karachun and Evgeny Tsatsorin also soared to the top, respectively, from the 5th and 37th places. Michael became the two-time winner of our championship!

Leaderboard: top 6 participants
Awarded winners
Fifty of the best participants in the championship received t-shirts with the ML Boot Camp logo. Leaders we also awarded prizes from Apple. For the sixth, fifth and fourth place - iPod nano, for the second and third - iPad, and for the first - MacBook Air.
We asked the championship leaders to tell how they managed to achieve such results, and collected their stories.

Mikhail Karachun used in his decision seven different models - from regression to neural networks.
Read the full analysis of the decision of Michael can be in his publication on Habré .

Yevgeny Tsatsorin used the random forest algorithm as a basis. At first, Eugene relied on the top 10 most important (according to the algorithm) features, then made up different sets of them to evaluate their effectiveness.
Full analysis of his decision is also on Habré .

Ivan Tyamgin chose xgboost as the main tool. Ivan used the technique of Bootstrap aggregating. I divided the sample 200 times randomly into training and control (the optimal ratio was 0.95 / 0.05) and ran xgboost. The final classifier is the voting (average) of all 200 basic classifiers. This gave a better result than samopisny Random Forest or AdaBoost.
The full story can be found in this publication .
In addition, we recommend reading the story of the seventh place from Alexander Kiselev. A great motivator for those who have not yet dealt with ML, but want to try;)
Prepared nishtyaki
Sandbox
Immediately after the finish of the competition, we opened the Sandbox. Members can now continue to upgrade their bots. And those who did not participate in the championship, join and try their hand.

In the sandbox you can solve the problems of old contests, including the closed student championship
The link is available full set of materials of this championship and two previous contests. For participants in real time, a separate sandbox leaderboard is formed for each task.
Group in Telegram
During the Russian AI Cup, we noticed that participants were happy to gather in messengers, and decided to support this trend. The official group of the championship helped us quickly respond to the comments. And participants were able to discuss their exciting moments. It turned out cool.
Experienced machine builders participate in the group, including championship winners.
Even after the end of the contest, there are discussions on the ML topic in the group - and not only. Add, if you solve the problems of the Sandbox. Here you will be helped by advice and a kind word.
Thanks
On behalf of Mail.Ru Group, we express our deep gratitude to UNN for them. N. I. Lobachevsky and personally to Nikolai Yuryevich Zolotykh and Oleg Durandin for invaluable assistance in preparing such interesting tasks and expert support of the championship! Nikolay and Oleg participated in the conduct of each of our ML championship, without them we would not have mastered half of what has been done now.
Choosing multiple solutions
During the championship, many asked to allow the choice of several options as final. For example, one with a more stable model, the second with a large score in public.
We will do that. In the next championship, participants will offer two final solutions instead of one. And we will form the final leaderboard for the best of the selected ones.
ML Boot Camp IV
We are pleased with the results of the third contest and on the 21st we will open the fourth contest! Join our championship, follow the news, try tasks in the Sandbox , and may the force be with you!
')
Source: https://habr.com/ru/post/326752/
All Articles