Under the hood of the development environment. Basic models
Some time ago I had the opportunity to develop components for development environments for Netbeans and JDeveloper. Hmm ..., in fact, quite a long time ago, and it would be necessary to write an article about this until I forgot everything and cloud environments did not finally take over the world. So, I was lucky to look into the insides of the products that we use every day, in this article I will discuss some aspects of the design of development environments and the principles of designing models used inside Java IDE. As examples, I will use Netbeans, but in other environments everything is approximately the same, because the same problems give rise to similar solutions.
The IDE provides tools for editing documents (primarily text-based source files) that are part of the project. At the same time, we do not just work with a character set, as it usually happens in a simple text editor, but take into account the meaning of the document content, as well as other documents in the same project, in project dependencies and in library dependencies.
When designing development environments, the architectural pattern MVC is actively used. The V (View) layer is what we see on the screen, what the user interacts with: text and graphic editors, various navigators (on the project, on the project file tree, on the file structure), dialog boxes, etc ... Under this layer is hidden invisible layer M (Model) - this is a very developed object structure representing the data with which the development environment works. documents in various levels of abstraction. I will mention for order and C (Controller), this is the most incomprehensible layer, under the controllers understand the components designed to change the data, but rarely it turns out to allocate the controller as an independent full-fledged component, often it is just a role. For example, a text editor is, obviously, a document view, but at the same time it changes the content, i.e. This is kind of like a controller too.
')
The development environment works with files, which means we need objects that will represent these files, or rather the position of these files on the disk. There is a historical moment, for a long time in Java there was no API that allowed to track events about changes in the file system. What to do if we are interested in file system events, and no one sends these events? There is a standard solution: we will introduce an intermediate layer - a virtual file system (VFS). Further, the IDE components work with the file system exclusively through VFS methods, for example, if we suddenly need to create a new file, we are not accessing java.io.File, but asking the virtual file system to create a file, it in turn creates the file using that same java. io.File and then sends an event about the appearance of a new file. All components of the development environment that are interested in tracking file events, subscribe to VFS events, and get notified that a new file has been created.

However, one problem remained: the files in the project can be changed by third-party programs (headlights, notepad, git cli, etc.). I happened to observe this solution: in order to change a file with a third-party program, you need to switch to it, which means the development environment window will lose input focus, so by running the project rescan when the focus returns to the development environment, we will catch almost all third-party changes. Now, of course, all IDEs are trying to listen to the events of the operating system where possible.
In Netbeans, files on disk are represented using the FileObject class.
To display a file in some editor, you have to load it into memory. So we need an object that will represent the file being loaded into memory. Often in this layer begins to take into account the contents of the file. After all, files store data, and the data is different in one case is Java code, in the other - XML in the third JSON. XML data can also be different. It can be a Mavin project or a JPA settings file. You can look inside the file, look at its extension and decide with which class we will represent files with this content. In Netbean, files in memory are represented using the DataObject class.
The development environment caches these objects and each time returns the same instance for the same physical file. Those. these objects are not created by the user using the constructor, but are requested from the platform, for example:
The objects of this layer provide the developer access to the contents of the physical file, while, if this has not been done before, the contents are transparently loaded by the development environment into the computer memory. For example:
Thus, we got access to the lowest-level model representing the contents of a text file. The BaseDocument used in Netbeans implements the good old Swing Document interface:
Sometimes they use the names Text Buffer or Character Buffer, a document, but the essence is the same - it's just an array of characters of variable length.
The test buffer is protected from competitive changes using its associated lock. In Netbeans and JDeveloper, this is the Read / Write lok, in the eclipse it is a regular monitor.
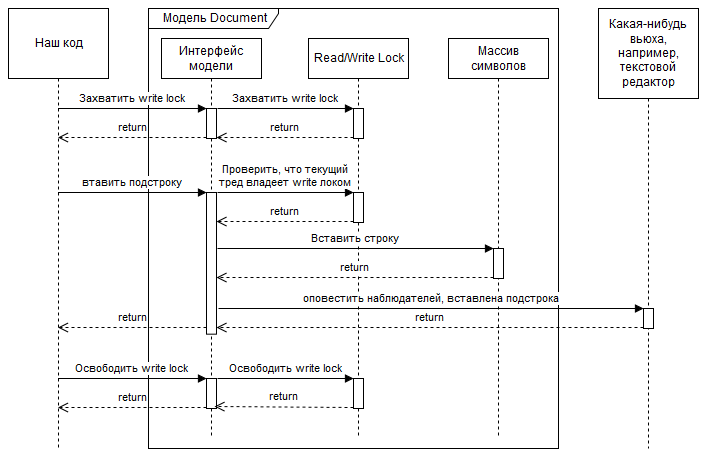
To make changes, you must either explicitly or implicitly seize the lock (the write lock), then the model changes and events about the changes are sent. Here, of course, options are possible, but usually events are sent in the same stream in which changes are made, and before the release of Lok, this creates a certain danger, but also gives the user more freedom. (Nuance: event handler code, running in a thread owning the write lock, may try to change this model, this behavior is sometimes preferred to be forbidden) This is how it all looks for the case of explicit locking using Read / Write lock:
The context of the development environment component is understood as: the file being edited (optional), the current project (the project in which the file is open), the current selection (selection). Accordingly, there are project models, selections, and we have already discussed the file model earlier.
When you open the editor (or create any other component), the development environment platform tells it the current context. The term “informs” means the following: the editor is trivial to call the editor.setContext (context) method or its equivalent, and the context is just an object with three fields: a file, a project, a selection.
Thus, the context is the starting point that allows the editor to extract all the information necessary for the operation of tools such as autocomplete, validation, etc., which use information from other files for their work. This information is presented in the form of high-level models and we will talk about their design in the next article.
The IDE provides tools for editing documents (primarily text-based source files) that are part of the project. At the same time, we do not just work with a character set, as it usually happens in a simple text editor, but take into account the meaning of the document content, as well as other documents in the same project, in project dependencies and in library dependencies.
When designing development environments, the architectural pattern MVC is actively used. The V (View) layer is what we see on the screen, what the user interacts with: text and graphic editors, various navigators (on the project, on the project file tree, on the file structure), dialog boxes, etc ... Under this layer is hidden invisible layer M (Model) - this is a very developed object structure representing the data with which the development environment works. documents in various levels of abstraction. I will mention for order and C (Controller), this is the most incomprehensible layer, under the controllers understand the components designed to change the data, but rarely it turns out to allocate the controller as an independent full-fledged component, often it is just a role. For example, a text editor is, obviously, a document view, but at the same time it changes the content, i.e. This is kind of like a controller too.
')
Disk File, Virtual File System
The development environment works with files, which means we need objects that will represent these files, or rather the position of these files on the disk. There is a historical moment, for a long time in Java there was no API that allowed to track events about changes in the file system. What to do if we are interested in file system events, and no one sends these events? There is a standard solution: we will introduce an intermediate layer - a virtual file system (VFS). Further, the IDE components work with the file system exclusively through VFS methods, for example, if we suddenly need to create a new file, we are not accessing java.io.File, but asking the virtual file system to create a file, it in turn creates the file using that same java. io.File and then sends an event about the appearance of a new file. All components of the development environment that are interested in tracking file events, subscribe to VFS events, and get notified that a new file has been created.
However, one problem remained: the files in the project can be changed by third-party programs (headlights, notepad, git cli, etc.). I happened to observe this solution: in order to change a file with a third-party program, you need to switch to it, which means the development environment window will lose input focus, so by running the project rescan when the focus returns to the development environment, we will catch almost all third-party changes. Now, of course, all IDEs are trying to listen to the events of the operating system where possible.
In Netbeans, files on disk are represented using the FileObject class.
File in computer memory
To display a file in some editor, you have to load it into memory. So we need an object that will represent the file being loaded into memory. Often in this layer begins to take into account the contents of the file. After all, files store data, and the data is different in one case is Java code, in the other - XML in the third JSON. XML data can also be different. It can be a Mavin project or a JPA settings file. You can look inside the file, look at its extension and decide with which class we will represent files with this content. In Netbean, files in memory are represented using the DataObject class.
The development environment caches these objects and each time returns the same instance for the same physical file. Those. these objects are not created by the user using the constructor, but are requested from the platform, for example:
DataObject myDataObject = DataObject.find(myFileObject); The objects of this layer provide the developer access to the contents of the physical file, while, if this has not been done before, the contents are transparently loaded by the development environment into the computer memory. For example:
BaseDocument myDocument = (BaseDocument) myDataObject.getCookie(EditorCookie.class).openDocument(); Text content
Thus, we got access to the lowest-level model representing the contents of a text file. The BaseDocument used in Netbeans implements the good old Swing Document interface:
- using the getLength () method, you can find out the number of characters in the document;
- getText (int offset, int length) - returns the document fragment as a string;
- using the insertString (...) and remove (int offs, int len) methods, you can make changes.
Sometimes they use the names Text Buffer or Character Buffer, a document, but the essence is the same - it's just an array of characters of variable length.
Competitive Access and Notifications
A model is the representation of some data as a set of objects. By calling the methods of these objects, you can change the model. At the time of the changes, the model sends notifications - in fact it calls the methods of objects registered as observers.
The development environment is multi-threaded. Firstly, there is a thread in which keystroke events are processed, mouse events, UI components are laid out and rendered - GUI Event Dispatcher Thread (EDT). Typing text in the editor, we make changes to the text buffer in this thread. And, say, a wizard performing a complex operation in this thread will twist the progress indicator and make changes in the model in the background thread. In general, it makes sense to run any lengthy operation in the background thread to avoid blocking and slowing down the user interface. Therefore, the models used in the development environment are generally thread-safe.
The test buffer is protected from competitive changes using its associated lock. In Netbeans and JDeveloper, this is the Read / Write lok, in the eclipse it is a regular monitor.
To make changes, you must either explicitly or implicitly seize the lock (the write lock), then the model changes and events about the changes are sent. Here, of course, options are possible, but usually events are sent in the same stream in which changes are made, and before the release of Lok, this creates a certain danger, but also gives the user more freedom. (Nuance: event handler code, running in a thread owning the write lock, may try to change this model, this behavior is sometimes preferred to be forbidden) This is how it all looks for the case of explicit locking using Read / Write lock:
| Platform | File view on disk | File presentation in memory | Text buffer | Access to locks |
|---|---|---|---|---|
| Netbeans | Fileobject | Dataobject | Document | Document readLock , writeLock |
| JSR-198 | java.net.URI and static methods of the VirtualFileSystem class | javax.ide.model.Document | Document | javax.ide.model.Transaction |
| Eclipse | IPath , IFileStore | IFileBuffer , ITextFileBuffer | IDocument | ISynchronizable |
JSR 198 (A Standard Extension API for Integrated Development Environments) is an attempt to standardize the development environment API and SPI. Attempt fails, implemented only in JDeveloper, and even there is not used by anyone. But this thing has a cognitive value - such a brief squeeze of aide apes and concepts.
Context
The context of the development environment component is understood as: the file being edited (optional), the current project (the project in which the file is open), the current selection (selection). Accordingly, there are project models, selections, and we have already discussed the file model earlier.
When you open the editor (or create any other component), the development environment platform tells it the current context. The term “informs” means the following: the editor is trivial to call the editor.setContext (context) method or its equivalent, and the context is just an object with three fields: a file, a project, a selection.
Thus, the context is the starting point that allows the editor to extract all the information necessary for the operation of tools such as autocomplete, validation, etc., which use information from other files for their work. This information is presented in the form of high-level models and we will talk about their design in the next article.
Source: https://habr.com/ru/post/326632/
All Articles