SDAccel - first acquaintance

SDAccel is an OpenCL programming system for Xilinx FPGAs. Currently, the problem of developing projects for FPGAs in the traditional languages of the hardware description, such as VHDL / Verilog, is becoming more and more acute. One of the methods to solve the problem is to use the C ++ language. OpenCL is one of the options for using the C ++ language to develop FPGA firmware.
A small introduction about phase transitions
I had to do programming FPGA back in 2000. At that time, computers were not very powerful, and FPGAs were very small. I worked with FPGA MAX7000 series from Altera. For the development of firmware used a great system MaxPlus II. The main tool there was a graphics editor. VHDL and Verilog support were already there, but were very weak. Only the synthesized subset of VHDL, Verilog, was supported. But it was possible to get the VHDL model of the finished FPGA with a sdf file of time delays. And the ratio of PC power and FPGA volume allowed for modeling the entire FPGA project with time delays. Now you can only dream about it. Around this time, a phase transition began in the development of FPGA projects. It was a transition from schematic input to using VHDL / Verilog to simulate individual nodes and the entire project. In our company, it coincided with the transition from Altera and MaxPlus II to Xilinx and ISE. We have completed this transition in 2004.
At the moment there is a second phase transition. It is associated with the transition of FPGA project development from VHDL / Verilog to C ++. The fact is that with a modern ratio of PC power and FPGA volume, it is almost impossible to conduct a FPGA project simulation session on VHDL / Verilog. A simulation session can last from several hours to several days. Such time can be allowed for the final verification of the project, but not for development.
What is OpenCL?
The OpenCL system was proposed in 2008 by Apple. In the future, the Khronos Group was organized, which included leading companies such as INTEL, NVIDIA, AMD, ARM, GOOGLE, SONY, SAMSUNG and many others. In addition to OpenCL, other systems are also developing there, for example, OpenXR, a virtual reality system.
')
OpenCL is a C ++ based design system for heterogeneous systems such as:
- conventional processors
- multiprocessor clusters
- graphics processors
- FPGA
OpenCL defines the system model, C ++ language extensions, the library of functions for the computer HOST.
Large simulation time associated with the simulation at the level of the clock frequency. Using the C language removes the clock signal from the project description. Only data operations remain in the project. This allows you to increase the speed of modeling and development by several orders of magnitude.
One of the first notable C programming systems is Mentor Graphics's Catapult system. This system appeared in 2004 and is successfully used, including by Microsoft, to implement its Bing search server using Altera FPGAs.
The company Xilinx approximately in 2013 released Vivado HLS, which allows you to develop individual components in C ++ and subsequently incorporate them into the main project. Several more products are created on the basis of Vivado HLS:
- SDSoc - acceleration of individual functions. The system is designed only for Zynq (this is a chip in which in one case there is a FPGA and an AWS processor). The system is already available.
- SDAccel is an OpenCL programming system. The system is available, but not all.
- SDNet is a network application design system. Not yet available and talking about it is still early.
SDSoc and SDAccel are characterized by the fact that the FPGA project already fades into the background. In the foreground - the algorithm. Both systems allow you to carry out modeling at the level of the original algorithm written in C / C ++ and then transfer it to the FPGA. This allows you to dramatically increase the complexity of the algorithm. And it is not by chance that now both of these systems are being introduced into image processing.
If we compare the programming for the FPGA on VHDL / Verilog and on C / C ++, then the analogy between programming for conventional C / C ++ and assembler processors suggests. Yes, assembly language can be made more compact and fast code. But in C / C ++ you can write a more complex program.
Calculator model
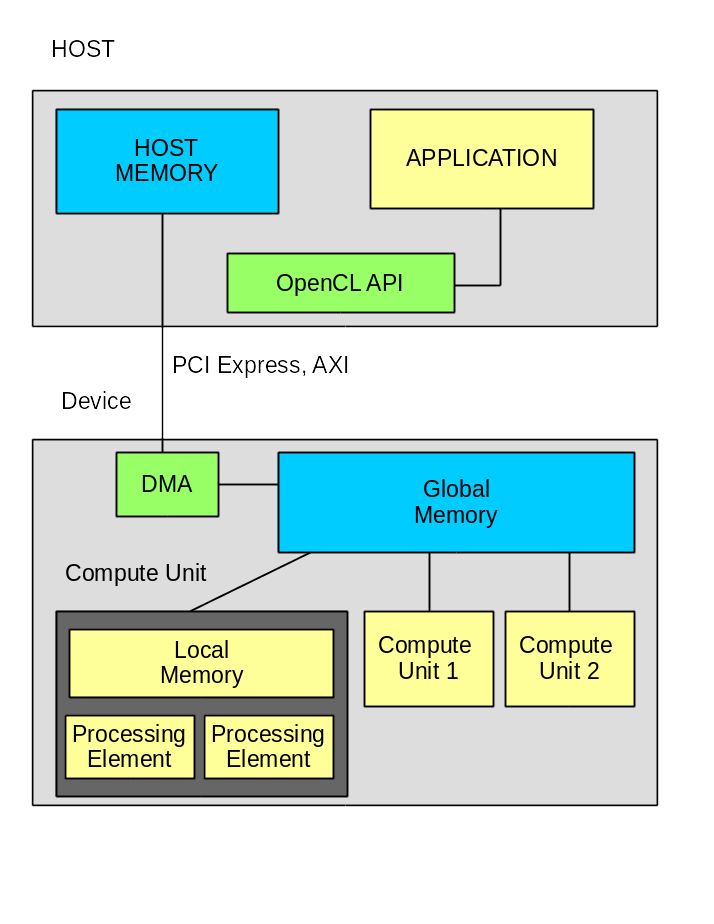
The system consists of HOST computer and computer, which are interconnected by bus. In most cases, this is a PCI Express bus. However, Altera already offers solutions for its FPGAs with an integrated workstations processor. In this case, the AXI bus is used. According to some rumors, Intel (which bought Altera) is developing a Xeon processor with integrated FPGA. The main design system there will be OpenCL, and QPI will be used for interaction between the processor and FPGA.
Inside the computer there is one or several “Compute Unit” blocks, each of which consists of one or several “Processing Element”. At this level there is a fundamental difference between graphics processors and FPGAs. If the number of “Processing Element” is defined in the graphics processor (although it is different in different models), then in the FPGA this may vary depending on the task.
The standard defines several memory classes:
- HOST Memory - the memory available to the application on the HOST computer. Usually this is the computer's RAM.
- Global Memory - the memory available for HOST and for the calculator. Usually it is a dynamic memory connected to the FPGA or to the graphics processor.
- Global Constant Memory - read and write memory for HOST and read-only on the computer.
- Local Memory - memory available only within one “Compute Unit”
- Private Memory - memory available only within the same “Processing element”
Additionally, Xilinx introduces "Global OnChip Memory" - a memory available to all "Compute Unit".
Simplified work algorithm:
- HOST initializes the device.
- HOST loads the program into the calculator
- HOST prepares data in HOST Memory
- HOST launches DMA channel to transfer data from HOST Memory to Global Memory and waits for DMA completion.
- HOST starts a calculator and waits for the completion of the calculation.
- HOST starts the DMA channel to transfer the result from Global Memory to HOST Memory and waits for the DMA to complete.
- HOST uses the results of the calculation.
It is important to note the following - all communication between HOST and the calculator goes through Global Memory. In more complex algorithms, it is possible to transmit data for the next cycle in parallel with the calculations.
What is a kernel?
Kernel is the basic concept of OpenCL. As a matter of fact, this is a function that is performed on one “Processing Element”. Multiple kernels can run within the same Compute Unit. This is the main way to ensure parallel operations for GPUs.
Example of function definition:
__kernel void krnl_vadd( __global int* a, __global int* b, __global int* c, const int length); Unlike the usual description, new keywords appear here, they are defined in the OpenCL standard.
- __kernel - defines the function that will be executed on the calculator.
- __global - determines that data is located in global memory.
SDAccel offers three ways to implement the kernel:
- OpenCL standard
- C ++ - this will use all the features of Vivado HLS
- VHDL / Verilog - this will use all the features of the FPGA
The main difference in the implementation for the GPU and FPGA
Using the example of a simple addition function of two vectors, it is very convenient to trace the main difference in the effective implementation of the code for graphics processors and for FPGAs.
The addition function for the GPU will look like this:
__kernel void krnl_vadd( __global int* a, __global int* b, __global int* c, const int length) { int idx = get_global_id(0); c[idx] = a[idx] + b[idx]; return; } And for FPGA like this:
__kernel void __attribute__ ((reqd_work_group_size(1, 1, 1))) krnl_vadd( __global int* a, __global int* b, __global int* c, const int length) { for(int i = 0; i < length; i++){ c[i] = a[i] + b[i]; } return; } Please note that the version for the GPU does not use the length parameter. It is assumed that for each element of the vector will be running its own copy of the kernel. Each instance will receive its idx number and perform the addition. The number of simultaneously running instances will be determined by the capabilities of this GPU. If the vector is too large, there will be several starts. For FPGA this can also be done, but it is not very effective. The best results are given by the variant in which only one “Compute Unit” and one “Processing Elenet” are used. Note that before the function declaration, the reqd_work_group_size (1, 1, 1) attribute was added, and there is a loop inside the function itself. The attribute value 1,1,1 means that only one kernel will be used. And this knowledge will be used to optimize the computational structure. The cycle itself with the help of additional attributes can be expanded into a parallel computing structure. The best result will be achieved if the length is constant.
SDAccel
Starting with version 2016.3, SDAccel and SDSoc are combined into one package called SDx. SDSoc works in Windows and Linux. SDAccel only works under some versions of Linux, in particular - CentOs 6.8; There are no reasonable explanations for such restrictions, I hope in the future SDAccel will work under Windows. The SDx package is based on Eclipse. It adds the project type "Xilinx SDx". When you create a project, you must select a platform. While the selection is small. The figure shows a view of the platform selection window:

The platform will determine the module and basic firmware FPGA. SDAccel uses Partial Reconfiguration technology. A correspondence is required between the base firmware, which is loaded into the FPGA and the one on the basis of which the SDAccel project is formed. This correspondence is supported by the name and version of the platform. Please note that the top line is the FMC126P module. I try to create a platform for it, while unsuccessfully.
Another important screenshot is the project properties:
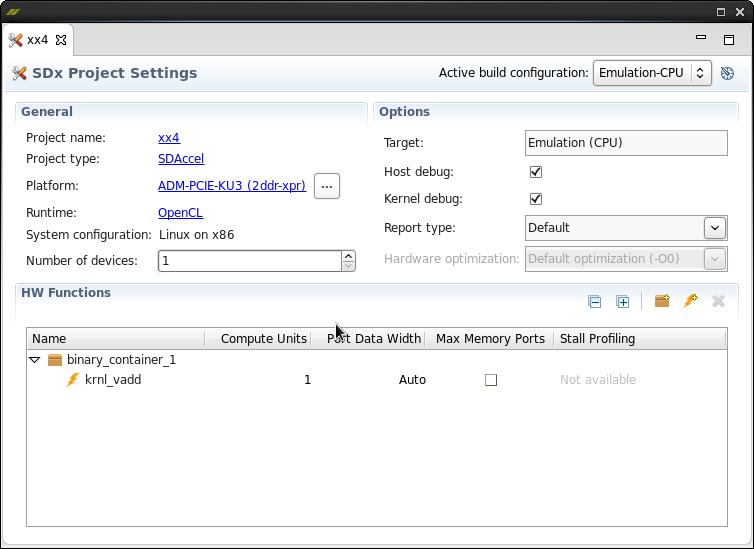
Pay attention to the “HW Functions” field.
- binary_container_1 is what will be loaded into the FPGA.
- kernel-vadd is the name of the function
- Column "Comput Units" - in fact, this is the number of parallel implementations of the function
- “Max Memory Ports” column - allowing additional optimization when accessing global memory
Very important is the upper right field: "Active build configuration". In fact, the whole essence of this system is here. Three options are possible:
- Emulation CPU - OpenCL implementation on a processor
- Emulation-HW - OpenCL implementation on Vivado simulator
- System - the implementation of OpenCL on the selected hardware platform
The result of the compilation will be the executable file, by the way, it has the extension .exe, and the file with the extension .xclbin; This is a binary_container with the implementation of kernel functions.
For the three embodiments, a different OpenCL runtime environment is formed. Emulation CPU option is the fastest to run. Compilation and launch are very fast. It is in this mode that the algorithm must be checked.
Emulation-HW is a longer option to compile and execute. In this mode, Vivado HLS is invoked, the code for VHDL / Verilog / SystemC is synthesized and the Vivado simulator is started to execute the kernel. By compiling the results, you can determine the resources occupied and evaluate the execution delays. Simulation can be long, since there is already a clock frequency and we get all the related problems. Although surely for PCI Express and SODIMM used simplified models, which increases the speed of modeling.
Option System is working. Compilation includes FPGA tracing, which is quite a long process. A small project for ADM-PCIE-KU3 gets divorced for about an hour. To start, you need to install the device driver that comes with the platform. At startup, binary_container is loaded into the FPGA using the Partial Reconfiguration technology. The download itself is also not fast, about a minute. What is the reason I can not explain.
Program for HOST
The OpenCL standard defines an API. On the Khronos Group website, all functions are well described. But it all looks quite gloomy. However, Xilinx here also simplified our lives. The vector_addition example includes the xcl.h and xcl.cpp files, which describe the most necessary functions for working with one device. Here they are:
- xcl_world_single (), xcl_world_release () - initialization and shutdown of the device
- xcl_malloc () - allocating a buffer in global memory on the device
- xcl_import_binary () - binary_container download
- xcl_set_kernel_arg () - setting arguments for the kernel function
- xcl_memcpy_to_device () - transfer data to device
- xcl_memcpy_from_devce () - transfer data from device
- xcl_run_kernel3d () - function launch for execution
Of course, the program for HOST may not be one. It is quite possible to make a separate project and connect any Unit testing system, for example Google Test, to test the implementation of functions on the FPGA.
And what's inside FPGA?
In the catalog of components there is such a nice element "SDAccel OpenCL Programmable Region"

That's exactly what binary_container will be loaded into. It is seen that the element has an extremely small number of links. There is a S_AXI bus for control, a M_AXI bus for accessing global memory, and of course clock and reset signals. It is assumed that the FPGA has a DMA node, a dynamic memory controller, and axi_interconnect central node.
The SDAccel unit can be opened, inside it will look like this:

Not very good, but it is clear that there are two axi_interconnect blocks, and between them there are four kernel blocks. From this structure, it is recommended not to use a large amount of kernel, since each block will require its own AXI bus. It is not recommended to use more than 16 tires.
Potential advantages and real disadvantages
The main advantage of the system is the possibility of implementing complex algorithms for working with large data arrays. Of course, the concepts of "complex algorithm" and "large array" are conditional. In my subjective opinion, the application of the system will be effective for those algorithms that require more than 1 MB of test data to check. First of all, of course, image processing algorithms.
Another potential advantage is the possibility of switching to other equipment. For example, with Xilinx FPGA on Altera FPGA.
The main disadvantages are:
- This is a new system, for sure there are still unexplained bugs
- Work only under a limited number of options for Linux. Under Windows - does not work.
- The efficiency of translation from C ++ to VHDL / Verilog is in question. Although it is possible to implement a kernel on VHDL / Verilog.
The first acquaintance took place, what's next
Upon further study of SDAccel, I plan the following:
- The study of effective methods of working with memory, measuring the speed of work
- Development platform for the module FMC126P
- Implementation of the convolution node based on the FPFFTK library by Alexander Kapitanov ( capitanov )
PS By the way, OpenCL does not support
<stdio.h> , however there is a printf there. Including printf works when implemented on the FPGA.Source: https://habr.com/ru/post/326628/
All Articles