Bash scripts, part 4: input and output
Bash scripts: start
Bash scripts, part 2: loops
Bash scripts, part 3: command line options and keys
Bash scripts, part 4: input and output
Bash Scripts, Part 5: Signals, Background Tasks, Script Management
Bash scripts, part 6: functions and library development
Bash scripts, part 7: sed and word processing
Bash scripts, part 8: awk data processing language
Bash scripts, part 9: regular expressions
Bash scripts, part 10: practical examples
Bash scripts, part 11: expect and automate interactive utilities
Last time, in the third part of this series of materials on bash scripts, we talked about command line parameters and keys. Our today's topic is input, output, and everything connected with it.


You are already familiar with the two methods of working with what command line scripts display:
')
- Display the displayed data on the screen.
- Redirect output to file.
Sometimes you have to show something on the screen, and write something to a file, so you need to figure out how input and output is processed in Linux, which means learning how to send the results of the scripts to the right place. Let's start by talking about standard file descriptors.
Standard File Descriptors
Everything in Linux is files, including input and output. The operating system identifies files using descriptors.
Each process is allowed to have up to nine open file descriptors. The bash shell reserves the first three descriptors with identifiers 0, 1, and 2. This is what they mean.
0,STDIN —standard input stream.1,STDOUT —standard output stream.2,STDERR —standard error stream.
These three special descriptors handle the input and output of data in the script.
You need to properly understand the standard streams. They can be compared with the foundation on which the interaction of scripts with the outside world is built. Consider the details of them.
STDIN
STDIN — the standard shell input stream. For the terminal, the standard input is the keyboard. When an input redirection character is used in scripts - < , Linux replaces the standard input file descriptor with the one specified in the command. The system reads the file and processes the data as if they were entered from the keyboard.Many bash commands accept input from
STDIN if no file is specified on the command line from which to take data. For example, this is true for the cat .When you enter the
cat command on the command line without specifying any parameters, it accepts input from STDIN . After you enter the next line, cat simply displays it on the screen.STDOUT
STDOUT — standard shell output stream. By default this is the screen. Most bash commands output data to STDOUT , which causes it to appear in the console. The data can be redirected to a file by attaching it to its contents, the >> command serves for this.So, we have a certain data file to which we can add other data using this command:
pwd >> myfile What
pwd will print will be added to the file myfile , while the data already in it will not go anywhere.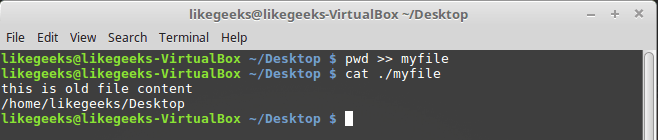
Redirect command output to file
So far so good, but what if you try to accomplish something like the one shown below, referring to a non-existent file
xfile , conceiving all this so that an error message xfile into the file myfile . ls –l xfile > myfile After executing this command, we will see error messages on the screen.

Attempt to access non-existent file
When trying to access a file that does not exist, an error is generated, but the shell did not redirect the error messages to the file, displaying them on the screen. But we wanted the error messages to be in the file. What to do? The answer is simple - use the third standard descriptor.
STDERR
STDERR is a standard shell error stream. By default, this descriptor points to the same thing as STDOUT , which is why we see a message on the screen when an error occurs.So, suppose we need to redirect error messages, say, to a log file, or somewhere else, instead of displaying them on the screen.
▍ Error Forwarding
As you already know, the
STDERR — file descriptor STDERR — 2. We can redirect errors by placing this descriptor in front of the redirect command: ls -l xfile 2>myfile cat ./myfile The error message is now in the file
myfile .
Redirecting error to file
▍ Redirecting error and output streams
When writing command line scripts, a situation may arise when you need to organize both the redirection of error messages and the redirection of standard output. In order to achieve this, you need to use the redirection commands for the corresponding descriptors, indicating the files where the errors and the standard output should fall:
ls –l myfile xfile anotherfile 2> errorcontent 1> correctcontent 
Redirecting errors and standard output
The shell will redirect what the
ls normally sends to STDOUT to the correctcontent file correctcontent to the 1> construction. Error messages that would fall into STDERR appear in the errorcontent file due to the redirection command 2> .If necessary, both
STDERR and STDOUT can be redirected to the same file using the &> command: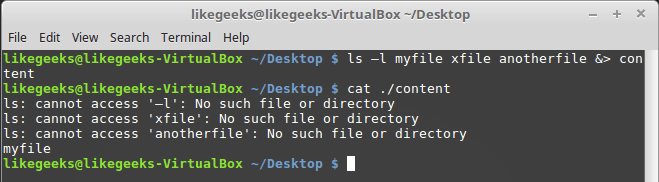
Redirect STDERR and STDOUT to the same file
After executing the command, what is intended for
STDERR and STDOUT is in the content file.Scripting output redirection
There are two methods for output redirection in command line scripts:
- Temporary redirection, or redirection of a single line output.
- Permanent redirection, or redirection of the entire output in the script or in some part of it.
▍ Temporary output redirection
In the script, you can redirect the output of a separate line in
STDERR . In order to do this, it is enough to use the redirection command, specifying the STDERR descriptor, and you should put the ampersand symbol ( & ) before the descriptor number: #!/bin/bash echo "This is an error" >&2 echo "This is normal output" If you run the script, both lines will appear on the screen, since, as you already know, by default, errors are output to the same place as the usual data.

Temporary redirection
Run the script so that the
STDERR gets to the file. ./myscript 2> myfile As you can see, now the usual output is done to the console, and error messages get into the file.
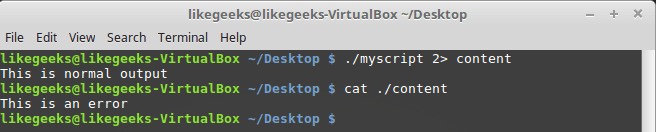
Error messages are written to the file.
▍ Permanent output redirection
If the script needs to redirect a lot of data displayed on the screen, adding the appropriate command to each
echo call is inconvenient. Instead, you can set output redirection to a specific descriptor for the duration of the script execution, using the exec command: #!/bin/bash exec 1>outfile echo "This is a test of redirecting all output" echo "from a shell script to another file." echo "without having to redirect every line" Run the script.

Redirect all output to file
If you view the file specified in the output redirection command, it turns out that everything that was output by
echo commands got into this file.The
exec command can be used not only at the beginning of the script, but also in other places: #!/bin/bash exec 2>myerror echo "This is the start of the script" echo "now redirecting all output to another location" exec 1>myfile echo "This should go to the myfile file" echo "and this should go to the myerror file" >&2 This is what happens after running the script and viewing the files to which we redirected the output.
Redirect output to different files
First, the
exec command sets the output redirection from STDERR to the file myerror . Then the output of several echo commands is sent to STDOUT and displayed on the screen. After that, the exec command sets the sending of what gets into STDOUT to the file myfile , and finally, we use the redirect command to STDERR in the echo command, which causes the corresponding line to be written to the myerror. file myerror.Having mastered this, you can redirect the output to where it should be. Now let's talk about input redirection.
Input redirection in scripts
To redirect input, you can use the same methodology that we used to redirect output. For example, the
exec command allows you to make a file a data source for STDIN : exec 0< myfile This command tells the shell that the input file should be the file
myfile , not the usual STDIN . Let's look at input redirection in action: #!/bin/bash exec 0< testfile count=1 while read line do echo "Line #$count: $line" count=$(( $count + 1 )) done This is what will appear on the screen after running the script.

Input redirection
In one of the previous articles, you learned how to use the
read command to read user input from the keyboard. If you redirect the input, making the file a data source, then the read command, when you try to read data from STDIN , will read it from the file, not from the keyboard.Some Linux administrators use this approach to read and post process log files.
Creating your own output redirection
Redirecting input and output in scripts is not limited to three standard file descriptors. As already mentioned, you can have up to nine open handles. The remaining six, with numbers from 3 to 8, can be used to redirect input or output. Any of them can be assigned to a file and used in script code.
You can assign a handle to the data output using the
exec command: #!/bin/bash exec 3>myfile echo "This should display on the screen" echo "and this should be stored in the file" >&3 echo "And this should be back on the screen" After launching the script, part of the output will be displayed on the screen, part - in the file with descriptor
3 .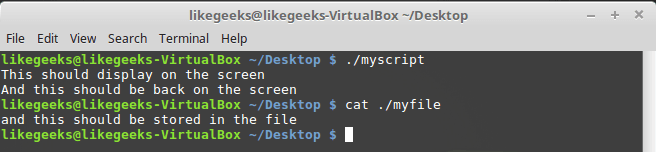
Output redirection using own descriptor
Creating file descriptors for data entry
You can redirect input in the script in the same way as output. Save the
STDIN in another descriptor before redirecting the input.After you finish reading the file, you can restore
STDIN and use it as usual: #!/bin/bash exec 6<&0 exec 0< myfile count=1 while read line do echo "Line #$count: $line" count=$(( $count + 1 )) done exec 0<&6 read -p "Are you done now? " answer case $answer in y) echo "Goodbye";; n) echo "Sorry, this is the end.";; esac Test the script.
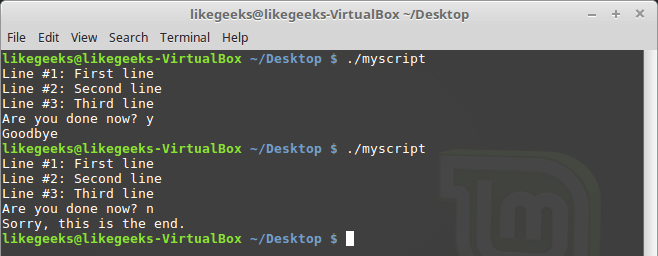
Input redirection
In this example, file descriptor 6 was used to store the reference to
STDIN . Then the input was redirected, the data source for STDIN was the file. After that, the input to the read command came from the redirected STDIN , that is, from the file.After reading the file, we return
STDIN to its original state, redirecting it to handle 6 . Now, in order to check that everything works correctly, the script asks the user a question, waits for input from the keyboard and processes what is entered.Closing File Descriptors
The shell automatically closes file handles after the script has completed. However, in some cases, you need to close the handles manually before the script finishes. In order to close a handle, it must be redirected to
&- . It looks like this: #!/bin/bash exec 3> myfile echo "This is a test line of data" >&3 exec 3>&- echo "This won't work" >&3 After executing the script, we get an error message.

Attempt to access a closed file descriptor
The thing is, we tried to access a non-existing handle.
Be careful when closing file descriptors in scripts. If you sent data to a file, then closed the descriptor, then opened it again, the shell will replace the existing file with the new one. That is, everything that was previously written to this file will be lost.
Getting information about open handles
To get a list of all open handles in Linux, you can use the
lsof command. On many distributions, like Fedora, the lsof utility is in /usr/sbin . This command is very useful as it displays information about each descriptor that is open in the system. This includes what the processes running in the background have opened, and what has been opened by the logged in users.This command has a lot of keys, consider the most important.
-pAllows you to specify the processID.-dAllows you to specify the descriptor number to get information about.
In order to find out the
PID current process, you can use the special $$ environment variable in which the shell writes the current PID .The
-a switch is used to perform the logical lsof -a -p $$ -d 0,1,2 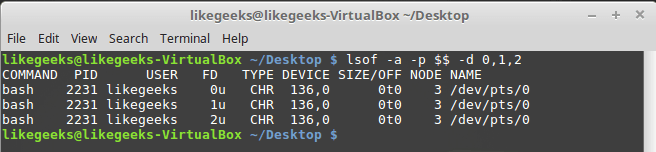
Displaying open descriptors
Type of files associated with
STDIN , STDOUT and STDERR — CHR (character mode). Since they all point to the terminal, the file name corresponds to the device name assigned to the terminal. All three standard files are readable and writeable.Let's look at the call to the
lsof from a script in which other descriptors are open, in addition to the standard ones: #!/bin/bash exec 3> myfile1 exec 6> myfile2 exec 7< myfile3 lsof -a -p $$ -d 0,1,2,3,6,7 That's what happens if you run this script.
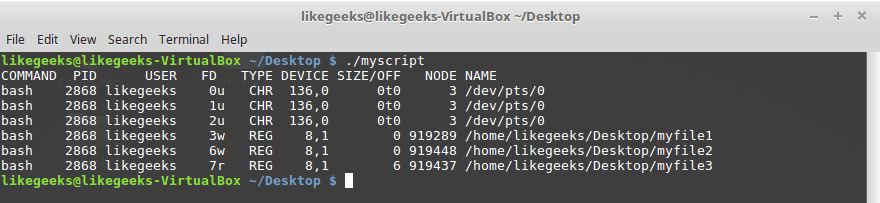
View the file descriptors opened by the script.
The script opened two descriptors for output (
3 and 6 ) and one for input ( 7 ). The paths to the files used to configure the descriptors are also displayed here.Output suppression
Sometimes you need to make sure that commands in a script, which, for example, can be executed as a background process, do not display anything on the screen. To do this, you can redirect the output to
/dev/null . This is something like a black hole.Here, for example, how to suppress error messages:
ls -al badfile anotherfile 2> /dev/null The same approach is used if, for example, you need to clear a file without deleting it:
cat /dev/null > myfile Results
Today you learned how input and output work in command line scripts. Now you know how to handle file descriptors, create, view and close them, know about the redirection of input, output and error streams. All this is very important in the development of bash-scripts.
Next time, we’ll talk about Linux signals, how to handle them in scripts, how to launch tasks on a schedule, and about background tasks.
Dear readers! This material provides the basics of working with input, output, and error streams. We are sure there are professionals among you who can tell about all this what comes only with experience. If so, we give you the floor.
Source: https://habr.com/ru/post/326594/
All Articles