How we sped up our DNS stack 3 times
Cloudflare has already gone 6th year and the provision of authoritative DNS servers has been our core infrastructure from the very beginning. Since then, we have grown to become the largest and fastest DNS service provider on the Internet, serving about 100,000 sites from the Alex top 1M sites list, and more than 6 million DNS zones.

To date, our DNS service responds to about 1 million requests per second - not counting traffic during attacks - using the global anycast network. Of course, the technologies that we, as a growing startup, used to serve hundreds and thousands of zones a few years ago, no longer cope with the millions that we have today. Last year we decided to replace two key elements in our DNS infrastructure: a part of our DNS server that responds to authoritative requests and a system that takes user changes and updates them on edge servers around the world.
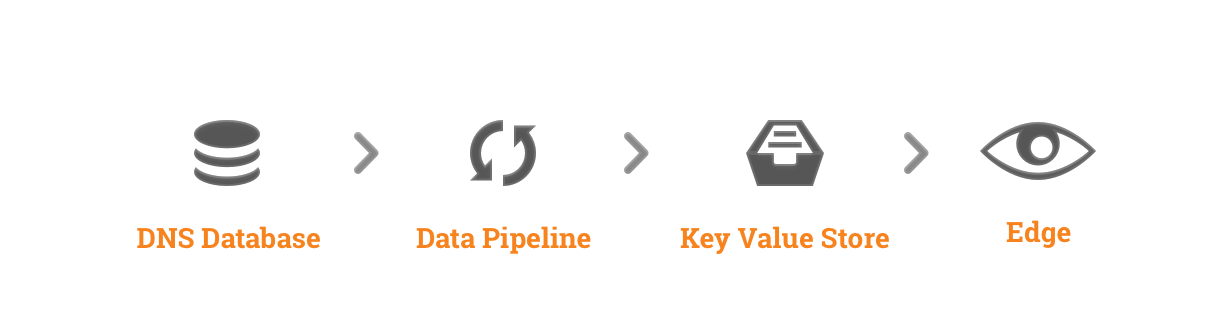
An approximate picture of our architecture is shown in the figure above. We store custom DNS records and other original information in a central database, then convert raw data into a format that our servers can use, and then distribute them to> 100 data centers (we call them PoPs - Points of Presents ("Points of Presence" )) using KV (key / value) storage.
The queries themselves are served by our own DNS server, rrDNS, which we have been developing and using for several years. In the early days of Cloudflare, our DNS solution was based on PowerDNS, but it was completely replaced by rrDNS in 2013.
The Cloudflare DNS command is thus responsible for two elements of the system: a data transfer system between servers and rrDNS. The initial idea was to replace our data transmission system with a completely new solution, since the current solution has become obsolete - like any infrastructure that has been in existence for more than 5 years. The current solution was built to work on top of PowerDNS and gradually evolved over time. It has accumulated enough flaws and hidden features, because it was originally created for translating DNS records into PowerDNS format.
New data model
In the old system, the data model was fairly simple. We stored DNS records approximately in the same form as they are represented in our graphical interfaces or API: one record for a resource record (resource record - RR). This meant that the data transfer service between servers had to deal only with simple serialization, when it was necessary to transfer zone data to our edge servers.
The zone metadata and RR were serialized using a mixture of JSON and Protocol Buffers, although we didn’t particularly use the schematic nature of these protocols, and as a result, the schemes became bloated and the final data was more than necessary. Not to mention the fact that as the number of resource records in the database grew to 100 million, this seemingly small difference in size became very noticeable.
It is worth recalling that DNS does not actually operate at the level of resource records when it responds to requests. You request a name and type (for example, example.com and AAAA ), and in return you will receive an RRSet - which is a collection of several RRs. In the old data model, RRSets were split into multiple records for the RR (one key per record), which usually meant multiple calls to the KV storage to respond to a single DNS query. We wanted to fix this and group the data around the RRSet so that one request would require only one access to the KV storage. Since it is very important for Cloudflare to optimize DNS performance, multiple requests to the KV storage have made it difficult to make rrDNS as fast as possible.
In the same vein, for requests like A / AAAA / CNAME, we decided to group the data into one key by "address", instead of one key on RRSet. This further helps to get rid of additional access to the repository in many cases. Keying the keys also helps reduce the memory usage on the cache that we use for the KV storage, as we store more information for one key.
Having defined the new data model, we needed to determine how we serialized the data and send it to the edge servers. As already mentioned, we previously used a mixture of JSON and Protocol Buffers, but we decided to replace this with a completely MessagePack implementation.
Why MessagePack?
MessagePack is a binary, typed data serialization format, but does not rigidly bind data to a schema. In this sense, it looks a bit like JSON. Both the sender and the recipient can add or ignore additional fields - this is already on the conscience of the application.
For comparison, Protocol Buffers (or other formats like Cap'n Proto ) require you to first define a data scheme in a language-independent format, and then generate code for a specific implementation. Since DNS already has a large structured scheme, we did not want to repeat its implementation in another language, and then support it. In the previous implementation of Protocol Buffers, we did not describe the schemes for all DNS types as follows - to avoid the need for this support - and in the end it resulted in a very confusing data model for rrDNS.
And when we looked at new formats, we wanted something quick, easy to use and that could easily integrate with our codebase and the libraries we used. rrDNS actively uses the miekg / dns library on Go, which operates with a large collection of structures for each RR type, for example:
type SRV struct { Hdr RR_Header Priority uint16 Weight uint16 Port uint16 Target string `dns:"domain-name"` } When decoding data from our services to rrDNS, we need to convert the RR into these structures. And it turned out that the tinylib / msgp library we tried represents good opportunities for code generation. This allows you to automatically generate effective Go code from these structure descriptions without the need to support schema definition in another format.
This meant that we could continue to work with the RR structures from miekg (with which we were already familiar with rrDNS), serialize them directly into binary data, and then deserialize them on the edge servers directly into the structures we need. We didn’t have to take care of the correspondence of one set of structures to another, which greatly simplified the work.
MessagePack is also incredibly fast compared to other formats. Here is a clipping from comparing serialization speeds in different formats for Go ; we can see that it greatly exceeds the speed of other cross-platform solutions, and this also greatly influenced our choice.
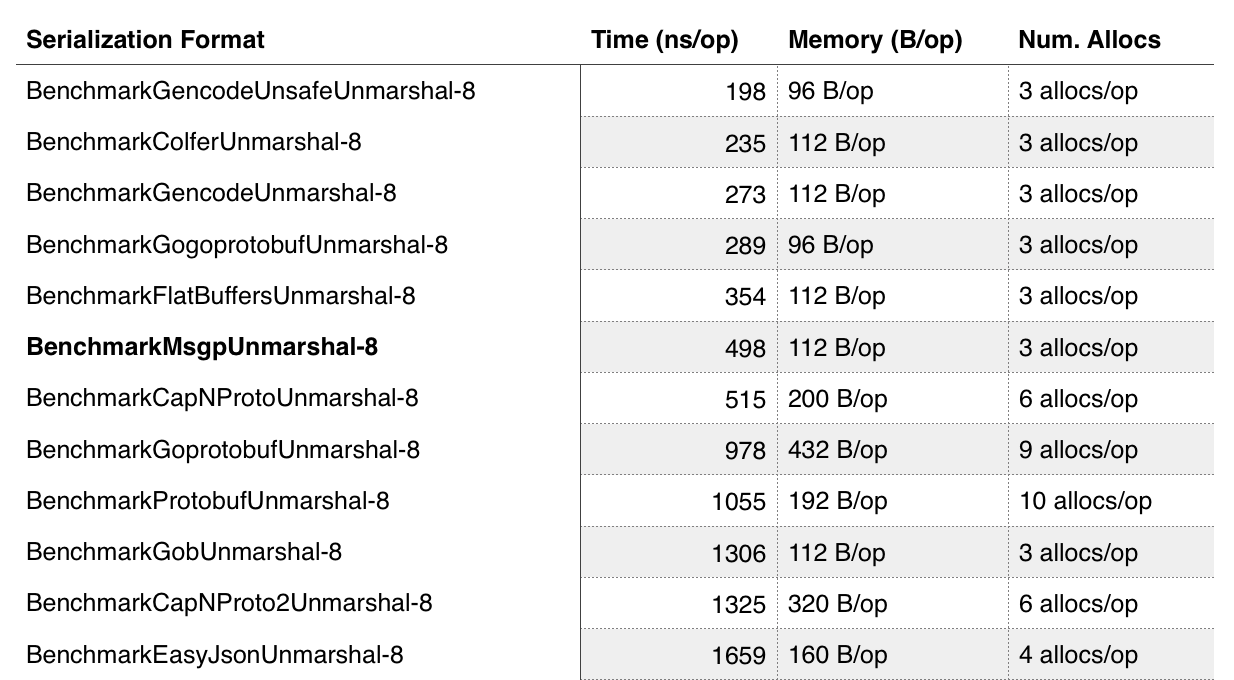
The surprise for us was that after the transition to the new model, we actually reduced the amount of space occupied by the data on the edge servers 9 times, which was much better than what we expected. This once again proves how much a bloated data model can have on a system.
New data service
Another important feature of Cloudflare DNS is our ability to update changes across the planet in seconds, not minutes or hours. Our existing data transfer system barely coped with the growing number of zones, and even with a change of 5 zones per second, in the most quiet periods, we needed a new solution.
Updating data worldwide is not easy
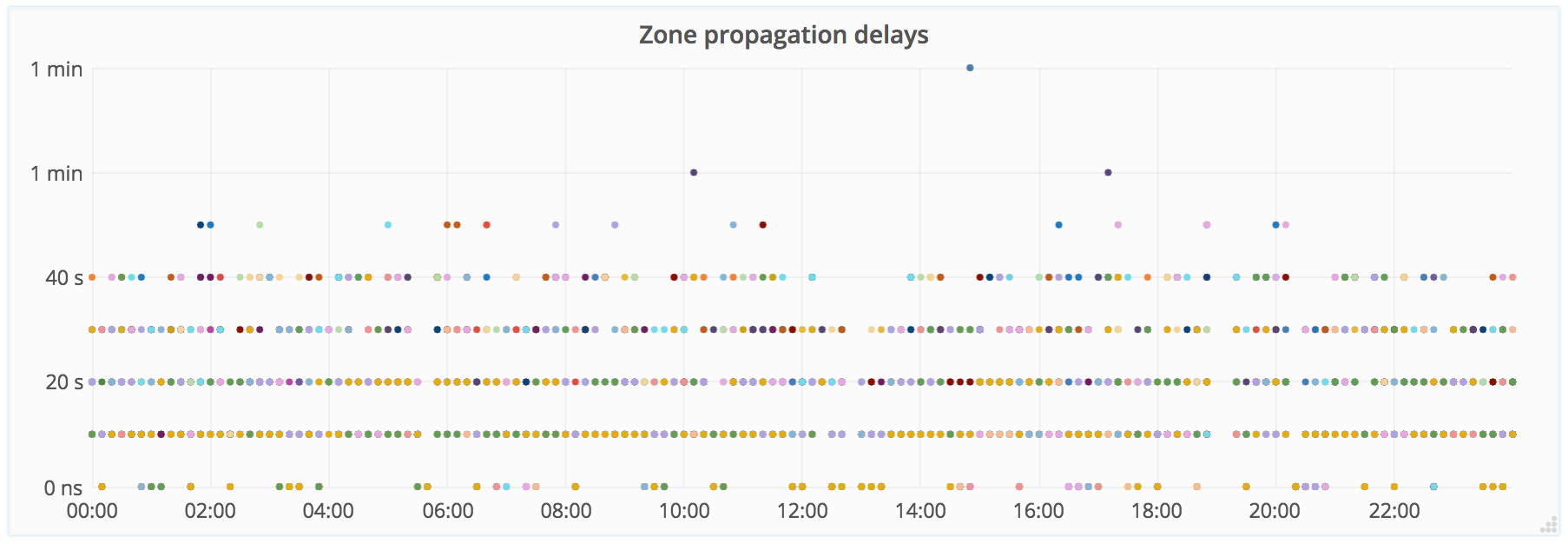
Recently we have been monitoring this process and can visualize the update time of changes around the world. The graph below shows data from our end-to-end monitoring: first we make changes to the DNS using our API, and we monitor how quickly the data was updated in different parts of the world. Each point on the graph represents a separate sample testing one of our PoPs (Points of Presence) and the delay is measured between the actual change through the API and when it becomes visible to the world.
Due to several levels of cache — both internal and non-controlled by us — we can see the distribution in 10 second intervals and values less than 1 minute, and they are constantly changing. This permission is enough for monitoring and notifications, but we certainly plan to improve it. Under normal conditions, new DNS data in 99% of cases becomes available within 5 seconds.
In the first graph, we see several incidents where delays of a couple of minutes were visible on a small number of PoPs due to connection problems, but on the whole, all samples show a very stable result.
For contrast, here is a chart from the old data transmission system for the same period. It is easy to see the growing delays for all PoPs.
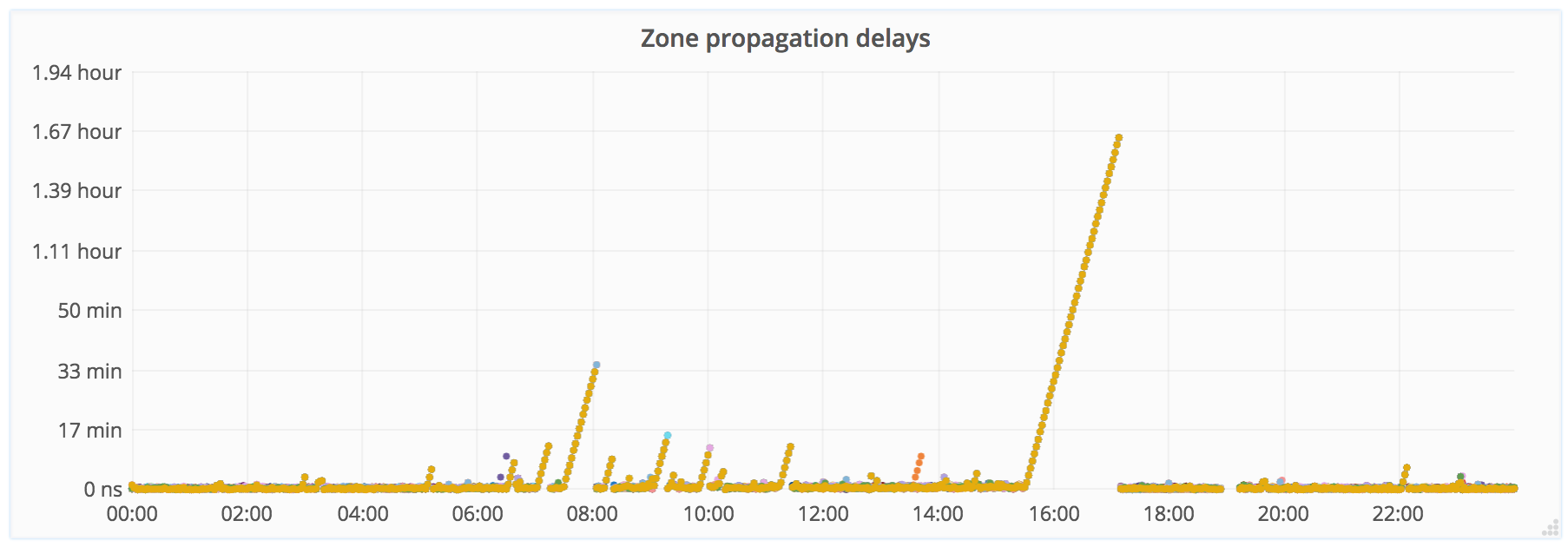
With the new data model, which was better suited to our request patterns, we implemented a new service that picks up changes in the zones from the central database, does the necessary processing and sends data to the KV storage.
The new service (written in our favorite language Go) has been in production since July 2016, and at the moment we have migrated over 99% of all user zones to it. If you remove cases with delays due to network problems, the new data transmission system has so far shown zero delays.
Authoritative rrDNS v2
rrDNS is a modular program that allows you to write various "filters" that can transfer the processing of certain types of requests to another code. The authoritative filter takes the incoming DNS request, looks at the zones to which the request belongs and executes all the necessary logic to find the RRSet and return it to the client.
Since we completely revised the underlying DNS data model on our edge servers, we also needed to significantly redo the “Authoritative Filter” in rrDNS. This was also one of the dark corners of our code base, which has not changed for many years. As with any aging code base, changing it was a daunting task, and we decided to rewrite this filter completely from scratch. This made it possible to start everything from a clean slate, based on a new data model, with an eye on performance and with more suitable solutions for the volume and format of DNS traffic that we have today. The decision to rewrite from scratch also made it much easier to develop using best practices, such as high code coverage with tests and good documentation.
The new version of the authoritative filter has been in production since the end of 2016 and has already played a key role in working with the DNS of our new load-balancing solution .
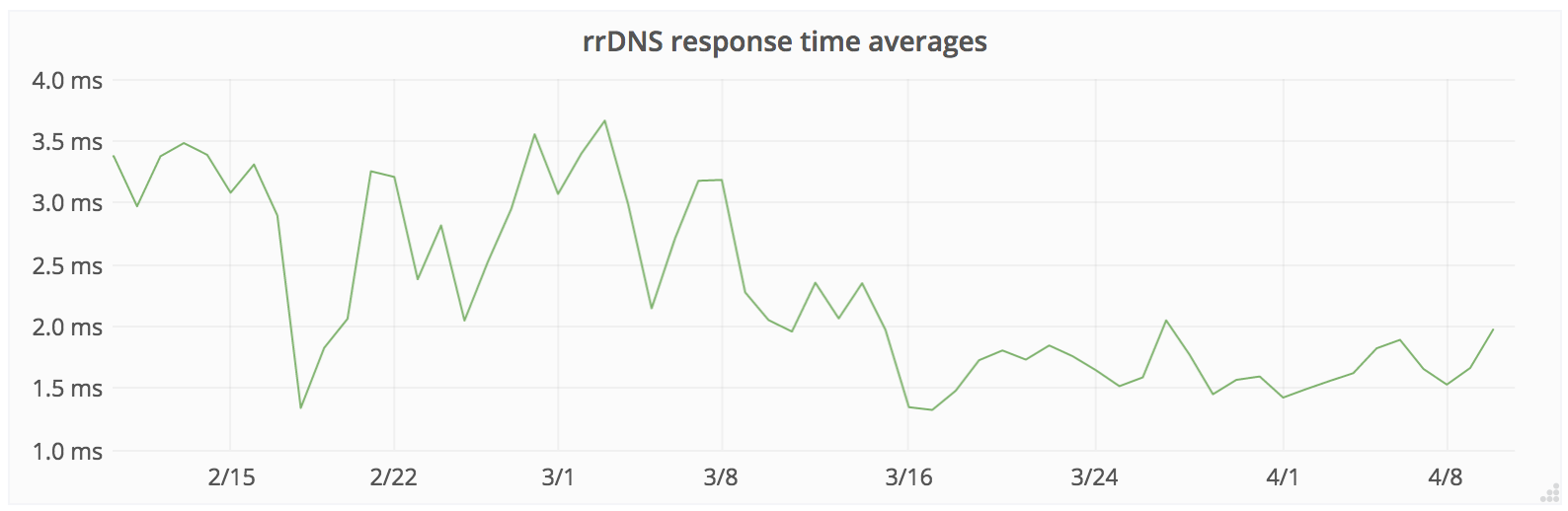
The results of the transition to the new filter pleased us: we began to respond to DNS queries on average 3 times faster than before, which was great news for our customers, and we improved our strength in circumventing large-scale DNS attacks. We can see on this graph that as the number of migrated zones has increased, the average response time has decreased significantly.
Pereobuvanie on the fly
The most time-consuming part of the project was the migration of clients from the old to the new version, moreover, so that no one had any problems and did not even know that we were doing something. To achieve this, Cloudflare took significant efforts from the masses of people in our customer relations and support departments. Cloudflare has many offices in different time zones - London, San Francisco, Singapore and Austin - and the synchronization of all was one of the key elements of success.
As one of the elements of the release process of the new rrDNS, we automatically collected and repeated requests from the production system on the old and new code in order to detect any unexpected differences. We also decided to use the same technique for migrating zones. For any zone to pass the test, we compared the possible answers for the entire zone between the old and the new system. The slightest difference in the result automatically excluded the zone from the migration process.
This allowed us to consistently test zone migration and correct flaws as they arise, releasing releases regularly. We decided not to go intimidating the transition from the old to the new system in one fell swoop, but launched them in parallel and gradually migrated the zones, keeping them in sync. This meant that we could migrate back at any time in case something happened.
As soon as we started the process, we quietly began to migrate several hundred thousand zones a day, and we closely watched how close we approached our initial goal of 99%. The last mile is still in progress, as there is always an element of engaging customers in certain complex configurations.

What have we achieved?
Replacing part of the Cloudflare core infrastructure required considerable effort from a large number of teams. What have we achieved?
- Performance gain 3 times in responses to DNS queries
- Faster and more reliable distribution of DNS updates worldwide
- A more comprehensive feature set, based on the current realities of traffic, and good documentation of the behavior of border servers
- Greater test coverage, better metrics and greater confidence in our code, which allows us to make changes and develop our DNS solutions more confidently.
Now that we can serve our DNS clients more quickly, we will soon roll out support for several new types of RRs and some new interesting features in the coming months.
')
Source: https://habr.com/ru/post/326372/
All Articles