Internal mechanisms of TCP, affecting the download speed: part 1
Acceleration of any processes is impossible without a detailed presentation of their internal structure. Acceleration of the Internet is impossible without understanding (and the appropriate setting) of the underlying protocols - IP and TCP. Let's deal with the features of the protocols that affect the speed of the Internet.
IP (Internet Protocol) provides routing between hosts and addressing. TCP (Transmission Control Protocol) provides an abstraction in which the network reliably operates over an essentially unreliable channel.
The TCP / IP protocols were proposed by Screw Cerf and Bob Kahn in the “Communication Protocol for Packet-Based Network” article published in 1974. The original proposal, registered as RFC 675, was edited several times and in 1981, the 4th version of the TCP / IP specification was published as two different RFCs:
')
- RFC 791 - Internet Protocol
- RFC 793 - Transmission Control Protocol
Since then, several improvements have been made to TCP, but its foundation remains the same. TCP quickly replaced other protocols, and now it uses the main components of how we imagine the Internet: websites, email, file transfer, and others.
TCP provides the necessary abstraction of network connections so that applications do not have to solve various related tasks, such as retransmitting lost data, delivering data in a specific order, data integrity, and the like. When you work with a TCP stream, you know that the bytes sent will be identical to the received ones, and that they will come in the same order. We can say that TCP is more “sharpened” for correct data delivery, and not for speed. This fact creates a number of problems when it comes to optimizing the performance of sites.
The HTTP standard does not require the use of TCP as a transport protocol. If we want, we can transmit to the HTTP through a datagram socket (UDP - User Datagram Protocol) or via any other. But in practice, all HTTP traffic is transmitted via TCP, thanks to the convenience of the latter.
Therefore, it is necessary to understand some internal TCP mechanisms in order to optimize sites. Most likely, you will not work with TCP sockets directly in your application, but some of your design decisions will dictate the performance of TCP through which your application will work.
Triple handshake
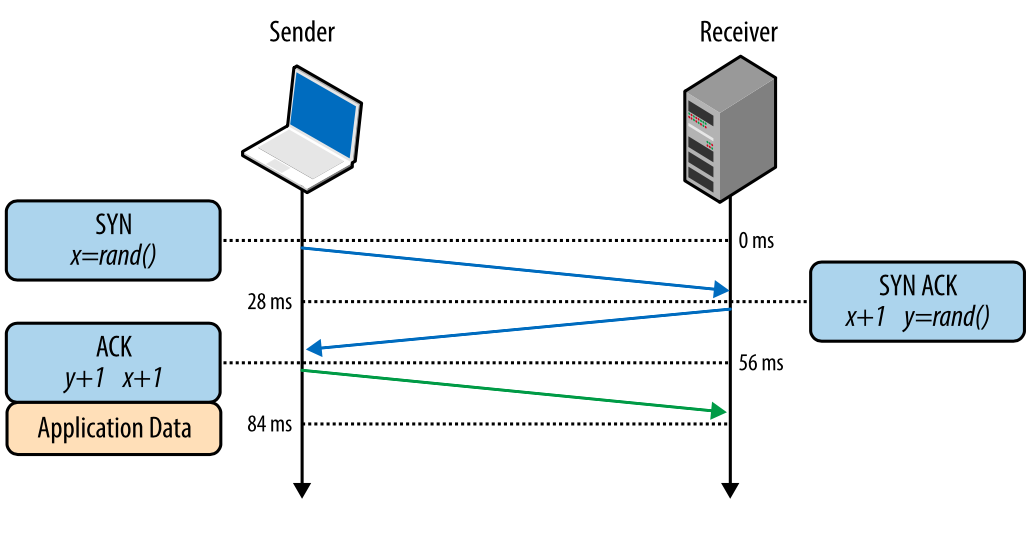
All TCP connections begin with a triple handshake (Figure 1). Before the client and the server can exchange any application data, they must “agree” on the initial number of the packet sequence, as well as a number of other variables associated with this connection. The numbers of sequences are chosen randomly on both sides for the sake of security.
SYN
The client selects a random number X and sends a SYN packet, which may also contain additional TCP flags and option values.
SYN ACK
The server selects its own random number Y, adds 1 to the value of X, adds its flags and options, and sends the response.
ASK
The client adds 1 to the X and Y values and completes the handshake by sending an ACK packet.
Fig. 1. Triple handshake.
After the handshake is complete, data exchange can be initiated. The client can send a data packet immediately after the ASC packet, the server must wait for the ASC packet to start sending data. This process takes place at every TCP connection and presents a serious difficulty in terms of site performance. After all, each new connection means some network latency.
For example, if the client is in New York, the server is in London, and we are creating a new TCP connection, it will take 56 milliseconds. 28 milliseconds for the packet to go in one direction and as much to return to New York. The width of the channel does not play any role here. Creating TCP connections turns out to be “expensive”, so connection reuse is an important opportunity to optimize any TCP-based applications.
TCP Fast Open (TFO)
Loading a page can mean downloading hundreds of its components from different hosts. This may require the browser to create dozens of new TCP connections, each of which will give a delay due to the handshake. Needless to say, this may slow down the download speed of such a page, especially for mobile users.
TCP Fast Open (TFO) is a mechanism that reduces latency by allowing data to be sent inside a SYN packet. However, it also has its limitations: in particular, on the maximum data size inside the SYN packet. In addition, only some types of HTTP requests can use TFO, and this only works for repeated connections, since it uses a cookie.
Using TFO requires explicit support for this mechanism on the client, server, and application. It works on a server with a Linux kernel version 3.7 and above and with a compatible client (Linux, iOS9 and above, OSX 10.11 and above), and you also need to enable the corresponding socket flags within the application.
Google specialists have determined that TFO can reduce network latency with HTTP requests by 15%, speed up page loading by 10% on average, and in some cases up to 40%.
Overload control
In early 1984, John Nagle described the state of the network, named by him as an "overload collapse," which can form in any network where the width of the channels between nodes is not the same.
When the round-trip delay (round-trip packet transit time) exceeds the maximum retransmission interval, the hosts begin sending copies of the same datagrams to the network. This will cause the buffers to be clogged and packets to be lost. As a result, the hosts will send packets several times, and after several attempts the packets will reach the goal. This is called an "overload collapse."
Nagle showed that the overload collapse was not a problem for ARPANETN at that time, because the nodes had the same channel width, and the backbone (high-speed backbone) had excess bandwidth. However, this is no longer the case on the modern Internet. Back in 1986, when the number of nodes in the network exceeded 5,000, a series of overload collapses occurred. In some cases, this led to the fact that the speed of the network fell 1000 times, which meant the actual inoperability.
To cope with this problem, TCP used several mechanisms: flow control, congestion control, congestion avoidance. They determined the speed at which data could be transmitted in both directions.
Flow control
Flow control prevents sending too much data to the recipient that it cannot process. To prevent this from happening, each side of the TCP connection tells you the size of the available buffer space for the incoming data. This parameter is the “receive window” (rwnd).
When a connection is established, both sides set their rwn values based on their system default values. Opening a typical page on the Internet will mean sending a large amount of data from the server to the client, so the client reception window will be the main limiter. However, if a client sends a lot of data to the server, for example, uploading video there, then the receiving window of the server will be the limiting factor.
If for some reason one side cannot cope with the incoming data stream, it should report the reduced value of its receive window. If the receive window reaches 0, it serves as a signal to the sender that you no longer need to send data until the receiver's buffer is cleared at the application level. This sequence is repeated continuously in each TCP connection: each ACK packet carries a fresh rwnd value for both sides, allowing them to dynamically adjust the data rate in accordance with the capabilities of the receiver and sender.
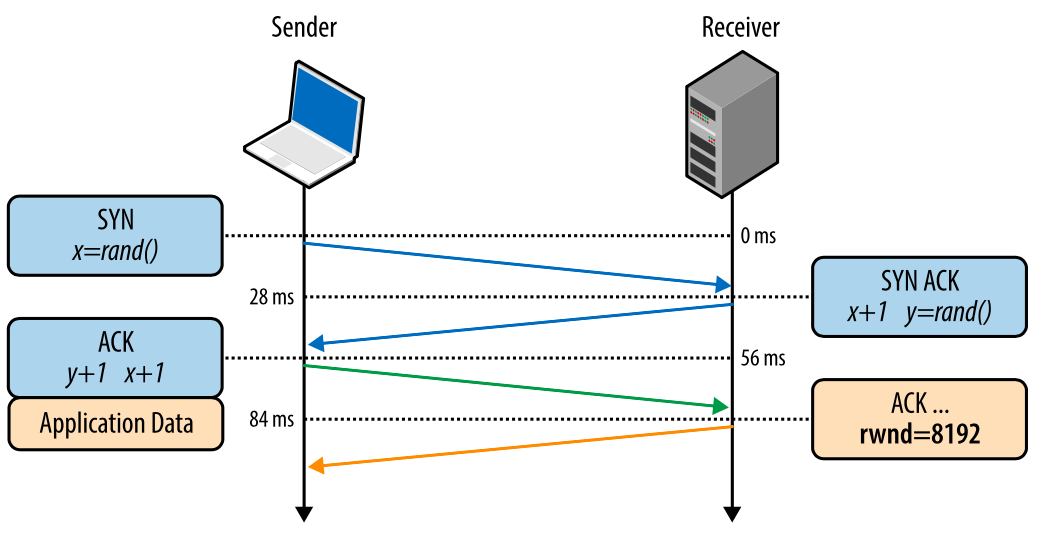
Fig. 2. Passing the receive window value.
Window scaling (RFC 1323)
The original TCP specification limited the transmit window value to 16 bits. This seriously limited it from above, since the reception window could not be more than 2 ^ 16 or 65,535 bytes. It turned out that this is often not enough for optimal performance, especially in networks with a large “bandwidth-delay product”.
To cope with this problem, the option of scaling a TCP window was introduced in RFC 1323, which made it possible to increase the receive window size from 65,535 bytes to 1 gigabyte. The window scaling parameter is transmitted during a triple handshake and represents the number of bits to shift to the left of the 16-bit receive window size in the following ACK packets.
Today, receive window scaling is enabled by default on all major platforms. However, intermediate nodes, routers and firewalls can overwrite or even delete this parameter. If your connection cannot fully utilize the entire channel, you need to start by checking the values of the receive windows. On the Linux platform, the window scaling option can be checked and set as follows:
$> sysctl net.ipv4.tcp_window_scaling $> sysctl -w net.ipv4.tcp_window_scaling=1 In the next part, we will understand what TCP Slow Start is, how to optimize the data transfer rate and increase the initial window, and also collect all the recommendations for optimizing the TCP / IP stack together.
Source: https://habr.com/ru/post/326258/
All Articles