Machine War: PVS-Studio vs TensorFlow

"I'll be back" ©. I think everyone knows this phrase. And although today we will not speak about the return of the terminator, the topic of the article is somewhat similar. Today we’ll tell you about checking the TensorFlow machine learning library and try to find out if we can sleep well, or if the Skynet hour is close ...
Tensorflow
TensorFlow is a machine learning library developed by Google and available as an open-source project from November 9, 2015. Currently it is used in research and in dozens of Google’s commercial products, including Google Search, Gmail, Photos, YouTube, Translate, Assistant, etc. The project’s source code is available in the repository on GitHub , as well as on the website Google projects .

Why did you choose this project?
')
- Google. If the project is developed by Google, Microsoft or other eminent developers, then its verification and error detection is, in a way, a challenge. In addition, I think many people are interested in how developers from eminent corporations are mistaken (or not mistaken).
- Machine learning. Recently, this topic is gaining more and more popularity. And for good reason, some results are really impressive! I do not give examples, if you wish, you can easily find them yourself.
- Statistics on github. It is also an important criterion, because the more popular the project, the better. So, TensorFlow beats all conceivable and inconceivable records! It is in the top C ++ projects, has more than 50,000 stars and more than 20,000 forks. Incredible!
Of course, by such a project can not pass. I don’t even know why my colleagues didn’t check it before. Well, I'll fix it.
And what was checked?
If you know what PVS-Studio is, then you also know the answer to this question. But do not rush to read further, what if you don’t know everything about our analyzer? For example, that we have already had a C # analyzer for more than a year and about half a year - a version for Linux .

For those who are not in the subject. The source code analysis was carried out using the PVS-Studio static analyzer, which looks for errors in programs written in C, C ++ and C #. PVS-Studio works under Windows and Linux and at the moment over 400 diagnostic rules are implemented in it, the description of which can be found on the corresponding page .
In addition to analyzer development, we check open-source projects and write articles based on the results of testing. At the moment we have checked more than 280 projects in which we found more than 10,800 errors . And these are not some ordinary projects, but rather well-known ones: Chromium , Clang , GCC , Roslyn , FreeBSD , Unreal Engine , Mono , etc.
PVS-Studio is available for download , so I advise you to try on your project and see what interesting things you can find.
By the way, the PVS-Studio tag is on StackOverflow ( link ). I recommend asking questions there, so that in the future other developers could quickly find the information they need without waiting for our answers by mail. We, in turn, are always happy to help our users.
Article format
This time I want to move away from the traditional verification sequence: 'I loaded the project → I checked → I wrote about the errors found' and to tell in more detail about some of the analyzer settings, and how they can be useful. In particular, I will show how you can effectively deal with false positives, which can be useful for disabling diagnostics and excluding from checking or outputting certain files. And, of course, let's take a look at what PVS-Studio managed to find in the TensorFlow source code.
Preparation for analysis
Now that PVS-Studio is available under Linux , there is a choice of where to perform the verification of the project: under Linux or Windows. Most recently, I tested one project under openSUSE, it was quite simple and convenient, but I decided to check TensorFlow under Windows. So familiar. In addition, it can be built using CMake, which implies further work in the Visual Studio development environment, for which we have a plugin (by the way, in its latest version, line selection with erroneous code appeared).
Officially build TensorFlow under Windows is not supported ( according to the site ). However, there is also a link on how to build a project using CMake. And, I must say, it is easy to assemble according to this instruction .
As a result, we obtain a set of .vcxproj files combined into .sln , which means that we can continue to conveniently work with the project from within Visual Studio. And it pleases. I worked from under the Visual Studio 2017 IDE, the support of which was added in the PVS-Studio 6.14 release .
Note. Before analyzing, it would be nice to put together a project, make sure everything is going well and there are no errors. This is necessary in order to be sure that the analysis will pass qualitatively and the necessary syntactic and semantic information will be available to the analyzer. So, on the TensorFlow website there is a note: By default, building TensorFlow from sources consumes a lot of RAM. Well, it's okay, because I have 16Gb RAM on my machine. And what do you think? During the build, I had an error Fatal Error C1060 (compiler is out of heap space)! Not enough memory! It was quite unexpected. And, no, I didn’t run 5 virtual machines simultaneously with the build. In fairness, I note that when building via bazel, you can limit the amount of RAM used (as described in the TensorFlow assembly instructions).
And now I can't wait to click on the cherished button “Analyze solution with PVS-Studio” and see what interesting things can be found, but first it would be nice to exclude from the analysis those files that are not interesting to us, for example, third-party libraries. This is done in the settings of PVS-Studio quite simply: on the 'Don't Check Files' tab, we set the masks of those files and paths that we are not interested in analyzing. There is already a set of paths in the settings (for example, / boost /). I added two masks to it: / third_party / and / external /. This will allow not only to exclude warnings from the results window, but also not to perform the analysis of files in these directories, which has a positive effect on the analysis time.
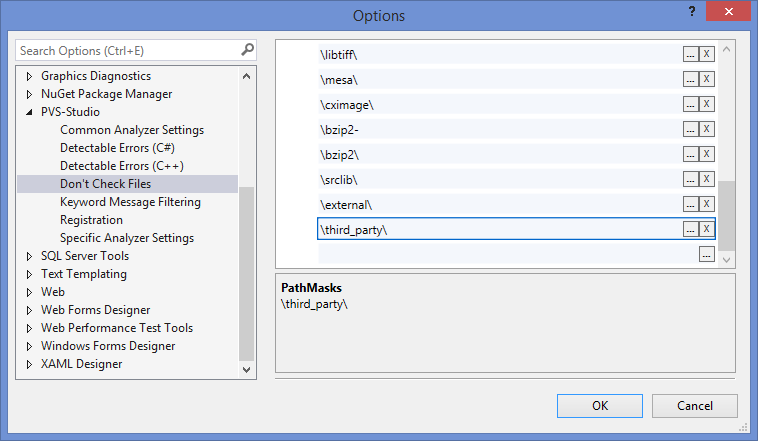
Figure 1 - Specify analysis exceptions in the settings of PVS-Studio
And now you can run the analysis and see what interesting things you can find.
Note. 'Don't Check Files' can be configured 'before' and 'after' analysis. I told about the first case above, in the second one the filtering of the already received log will be performed, which is also useful and will eliminate the viewing of unnecessary warnings. This will be below.
False alarms: funny arithmetic
Why false alarms are important (and unpleasant)
False positives are a headache for everyone: for us, the developers of the static analyzer, and for the users, as they clog up a useful conclusion. A large number of false positives can repel people from using the tool. In addition, people often evaluate analyzers by the criterion of how many false alarms they give out. It's not so simple, and this topic is suitable for a separate article and discussion. My colleague, by the way, recently just wrote an article on this topic , I recommend reading.
How to deal with false positives?
Our task is to try to filter out as many false positives as possible at the analysis stage so that the user doesn’t know about them at all. For this purpose, exceptions are introduced into the diagnostic rules, i.e. special cases in which it is not necessary to issue warnings. The number of these exceptions can vary greatly from diagnostics to diagnostics: somewhere they may not exist at all, but tens of such exceptions can be realized somewhere.
Nevertheless, all cases are not covered (sometimes they are very specific), so our second task is to give the user the opportunity to independently eliminate false alarms from the results of the analysis. For this, the PVS-Studio analyzer implements a number of mechanisms, such as suppression of false positives through comments, configuration files, and suppression bases. Again, a separate article has been written about this, so here I will not dig deep into it.
False positives and TensorFlow
Why do I even started a conversation about false positives? Firstly, because the fight against false positives is important, and, secondly, because that's what I saw when I checked TensorFlow and filtered the output according to the V654 diagnostic rule.
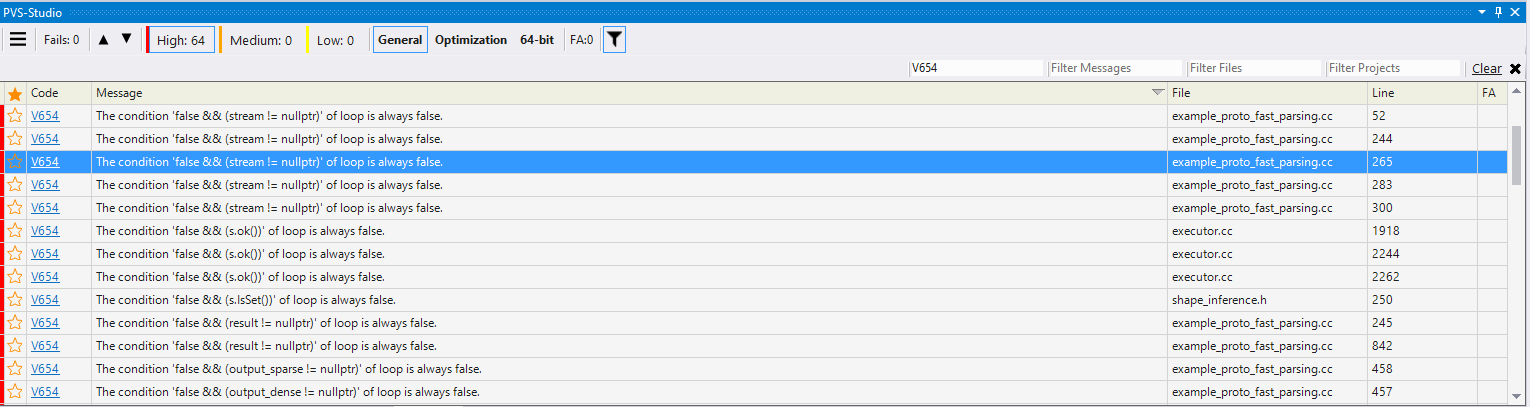
Figure 2 - All found V654 operations have a similar pattern.
64 operations, and all, like one, the same pattern - code of the form:
false && expr In the code itself, these places look like this:
DCHECK(v); DCHECK(stream != nullptr); DCHECK(result != nullptr); This is how the DCHECK macro is declared :
#ifndef NDEBUG .... #define DCHECK(condition) CHECK(condition) .... #else .... #define DCHECK(condition) \ while (false && (condition)) LOG(FATAL) .... #endif What follows from this code? DCHECK - debug macro. In the debug version of the code it is revealed in the condition check ( CHECK (condition) ), in the release version - in a loop that will not be executed once - while (false && ....) . Due to the fact that I was collecting the release version of the code, the macro was opened accordingly (in a while loop ). As a result, the analyzer seems to be cursing in the case, because the result of the expression is always always false . But what is the use of these warnings, if they are issued to the code that was meant to be so? As a result, the percentage of false positives for this diagnostic will be the same as in the diagram below.
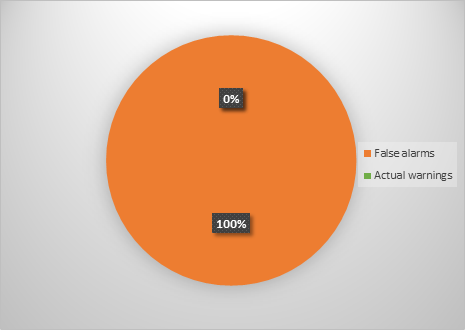
Figure 3 - The ratio of good and false positives diagnostics V654
Maybe you thought it was a joke? No, not a joke, 100% false positives. I spoke about such specific cases above. He also said that there are ways to deal with them. With a slight movement of the hand and the button 'Add selected messages to suppression base' we can correct this ratio in the opposite direction.

Figure 4 - Fighting False Positives
This way you can suppress all current warnings by removing them from the output window. But this is not entirely correct, since if you again use the DCHECK macro in the course of writing the code, warnings will be issued again. There is a solution. It is necessary to suppress the triggering in the macro, leaving a special comment. The suppression code will look like this:
//-V:DCHECK:654 #define DCHECK(condition) \ while (false && (condition)) LOG(FATAL) The comment should be placed in the same header file where the macro is declared.
That's all, now you can no longer worry about the DCHECK macro, because V654 warning on him will no longer be issued. As a result, we again successfully fought with false positives. Anyway, after these actions, the false positive chart for V654 will look like this.
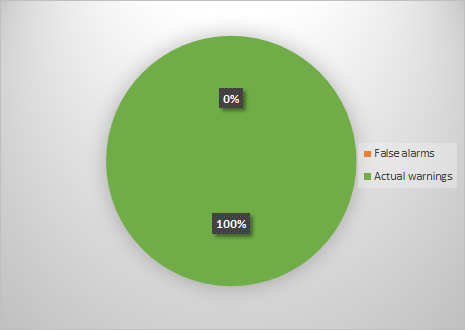
Figure 5 - Successfully eliminated false positives
Now the picture looks a completely different way, because the percentage of false positives is 0. Such is the entertaining arithmetic. Why all this talk about false positives? I just wanted to explain that false positives are inevitable. The goal of the analyzer is to get rid of as many of them as possible at the analysis stage, but due to the specifics of the project, you may have to deal with them. I hope I managed to convey that it is possible (and necessary) to deal with false positives, and this is done quite simply.
Some more settings
Surely you can’t wait to look at the errors found, but I call for patience and I propose to consider some other settings that will help make life easier when working with the results of the analysis.
Warnings in automatically generated files
In the course of the analysis, it was checked not only the code that the programmers wrote themselves, but also automatically generated ones. We are not interested in viewing warnings on such a code, so we need to somehow exclude them from the analysis. Here come the settings mentioned earlier 'Don't check files'. Specifically for this project, I set exceptions for the following file names:
pywrap_* *.pb.cc This made it possible to hide more than 100 general-purpose (GA) warnings with an average confidence level (Medium).
Disabling specific diagnostics
Another analyzer setting that turned out to be useful is disabling groups of diagnostic rules. Why this may be relevant? For example, about 70 V730 warnings were issued on this project (not all members of the class are initialized in the constructor). Do not pass by these warnings, because they can signal difficult-to-detect errors. However, it is not always clear to someone unfamiliar with the code whether the uninitialized member will actually lead to problems, or there is some tricky way to further initialize it. And for the article errors of this type are not the most interesting. Therefore, they should be reviewed by developers, and we will not focus on this. From here, the goal is formed - disabling a whole group of diagnostic rules. This is done easily and simply: in the settings of the PVS-Studio plugin, it is enough to remove the selection for the 'Check box' from the corresponding diagnostics.
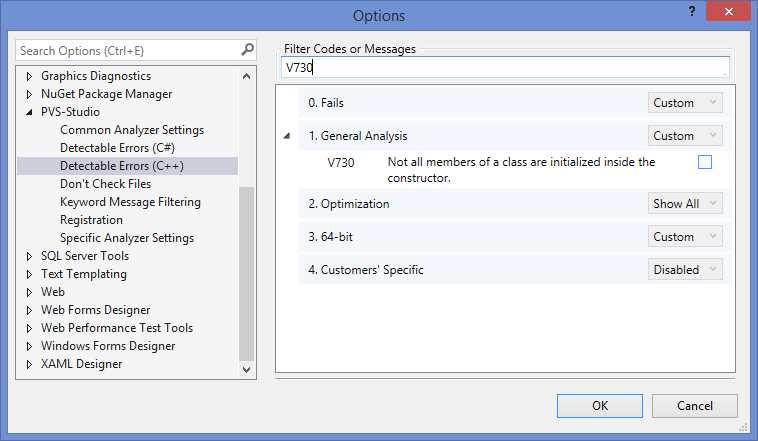
Figure 6 - Disabling irrelevant diagnostics
By disabling those diagnostic rules that are not relevant for your project, you thereby simplify further work with the output of the analyzer.
Parsing Alerts
Well, let's move on to perhaps the most interesting part - the analysis of those code fragments that PVS-Studio found suspicious.
I usually like to start with the classic error that is allowed in both C ++ projects and C # - an error of the form a == a , which is found by the diagnostic rules V501 and V3001 . But there are no such mistakes! And in general, the set of detected errors is sufficient ... specific. But let's not pull, get down to business.
void ToGraphDef(const Graph* g, GraphDef* gdef, bool pretty) { .... gtl::InlinedVector<const Edge*, 4> inputs; .... for (const Edge* e : inputs) { const string srcname = NewName(e->src(), pretty); if (e == nullptr) { ndef->add_input("unknown"); } else if (!e->src()->IsOp()) { } else if (e->IsControlEdge()) { ndef->add_input(strings::StrCat("^", srcname)); } else if (e->src_output() == 0) { ndef->add_input(srcname); } else { ndef->add_input(strings::StrCat(srcname, ":", e->src_output())); } } .... } → Link to GitHub
PVS-Studio warning : V595 The 'e' pointer was used before it was verified against nullptr. Check lines: 1044, 1045. function.cc 1044
In the loop, the elements of the vector are traversed and, depending on the value of the element, certain actions are performed. Checking e == nullptr implies that the pointer may be null. Here is just a line above, during the call to the NewName function, this pointer is dereferenced: e-> src () . The result of such an operation is undefined behavior, which may lead, inter alia, to the emergency termination of a program.
But the TensorFlow code is not so simple. The filling of this vector ( inputs ) is higher and looks like this:
for (const Edge* e : n->in_edges()) { if (e->IsControlEdge()) { inputs.push_back(e); } else { if (inputs[e->dst_input()] == nullptr) { inputs[e->dst_input()] = e; } else { LOG(WARNING) << "Malformed graph node. multiple input edges: " << n->DebugString(); } } } Looking attentively at this code, it can be understood that zero inputs will never be written to the inputs vector, because before adding elements, pointer dereference is always performed, moreover, before a pointer dereference, its check for equality nullptr is missing . Since the inputs vector will not contain null pointers, it turns out that the expression e == nullptr , which we talked about earlier, will always be false .
Anyway, this is a tricky code, and PVS-Studio successfully found it. Go ahead.
Status MasterSession::StartStep(const BuildGraphOptions& opts, int64* count, ReffedClientGraph** rcg, bool is_partial) { .... ReffedClientGraph* to_unref = nullptr; .... if (to_unref) to_unref->Unref(); .... } → Link to GitHub
PVS-Studio warning : V547 Expression 'to_unref' is always false. master_session.cc 1114
In the body of the method, a local variable to_unref is declared , initialized by the value nullptr . Before the if statement, this pointer is not used, its value does not change. Therefore, since the pointer has remained zero, the body of the if operator will never be executed. This code may have remained after refactoring. Maybe this pointer should have been used somewhere between initialization and validation, but another one was used instead (mixed up), but I did not find similar names. It looks suspicious.
Go ahead.
struct LSTMBlockCellBprop .... { .... void operator()(...., bool use_peephole, ....) { .... if (use_peephole) { cs_prev_grad.device(d) = cs_prev_grad + di * wci.reshape(p_shape).broadcast(p_broadcast_shape) + df * wcf.reshape(p_shape).broadcast(p_broadcast_shape); } if (use_peephole) { wci_grad.device(d) = (di * cs_prev).sum(Eigen::array<int, 1>({0})); wcf_grad.device(d) = (df * cs_prev).sum(Eigen::array<int, 1>({0})); wco_grad.device(d) = (do_ * cs).sum(Eigen::array<int, 1>({0})); } .... } }; → Link to GitHub
PVS-Studio warning : V581 The conditional expressions of the 'if' are agreed alongside each other are identical. Check lines: 277, 284. lstm_ops.h 284
There are two conditional operators with the same conditional expression, while the expression between these operators (in this case, the use_peephole parameter) does not change. Sometimes this may indicate a rather serious error, when in one of the cases we used not the expression that was meant, but in this case, starting from the context, we can conclude that we simply duplicated conditional statements. I think this is not a mistake, but all operations could be placed in one conditional operator.
You can not write an article and not look at the copy-paste error.
struct CompressFlags { .... Format format; .... int quality = 95; .... bool progressive = false; .... bool optimize_jpeg_size = false; .... bool chroma_downsampling = true; .... int density_unit = 1; int x_density = 300; int y_density = 300; .... StringPiece xmp_metadata; .... int stride = 0; }; class EncodeJpegOp : public OpKernel { .... explicit EncodeJpegOp(OpKernelConstruction* context) : OpKernel(context) { .... OP_REQUIRES_OK(context, context->GetAttr("quality", &flags_.quality)); OP_REQUIRES(context, 0 <= flags_.quality && flags_.quality <= 100, errors::InvalidArgument("quality must be in [0,100], got ", flags_.quality)); OP_REQUIRES_OK(context, context->GetAttr("progressive", &flags_.progressive)); OP_REQUIRES_OK(context, context->GetAttr("optimize_size", &flags_.optimize_jpeg_size)); OP_REQUIRES_OK(context, context->GetAttr("chroma_downsampling", // <= &flags_.chroma_downsampling)); OP_REQUIRES_OK(context, context->GetAttr("chroma_downsampling", // <= &flags_.chroma_downsampling)); .... } .... jpeg::CompressFlags flags_; } → Link to GitHub
PVS-Studio warning : V760 Two blocks of text were found. The second block begins from line 58. encode_jpeg_op.cc 56
As can be seen from the code, in the constructor of the EncodeJpegOp class, the OP_REQUIRES_OK and OP_REQUIRES macros check the values of flags read from the flags_ field. However, in the last lines of the given code fragment for the constructor, the value of the same flag is checked. Very similar to copy-paste: duplicated, but forgot to fix.
The most interesting (and difficult) that often happens in such cases is to understand whether the copy-paste code is redundant, or if something else is implied. If the code is redundant, as a rule, there is nothing particularly terrible, but a completely different conversation, if a different code fragment was meant, since in this case we get a logical error.
After reviewing the body of the constructor, I could not find the stride field check. It is possible that in one of the cases this check was implied. On the other hand, in the constructor, the order of the fields is the same as the order in which the fields are declared in the CompressFlags structure. So it’s difficult to judge how to correct the code, you can only make assumptions. In any case, you should pay attention to this place.
Found analyzer and several suspicious places associated with the bit shift. Let's look at them. And I want to remind you that improper use of shift operations can lead to undefined behavior.

class InferenceContext { .... inline int64 Value(DimensionOrConstant d) const { return d.dim.IsSet() ? d.dim->value_ : d.val; } .... } REGISTER_OP("UnpackPath") .Input("path: int32") .Input("path_values: float") .Output("unpacked_path: float") .SetShapeFn([](InferenceContext* c) { .... int64 num_nodes = InferenceContext::kUnknownDim; if (c->ValueKnown(tree_depth)) { num_nodes = (1 << c->Value(tree_depth)) - 1; // <= } .... }) ....; → Link to GitHub
PVS-Studio warning : V629 Consider inspecting the '1 << c-> Value (tree_depth)' expression. Bit shifting of the 32-bit type. unpack_path_op.cc 55
The suspicion of this code is that here 32-bit and 64-bit values are mixed in the shift and assignment operations. Literal 1 is a 32-bit value for which a left-side shift is performed. The result of the shift is still of 32-bit type, but it is written to a 64-bit variable. This is suspicious, because if the value that the Value method returns is greater than 32, an undefined behavior will occur.
Quote from the standard : The value of E1 << E2 is E1 left-shifted E2 bit positions; vacated bits are zero-filled. If it is an unsigned pattern, it can be reduced to a minimum. Otherwise, if it is a non-negative value, and if it is an E1 * 2 ^ E2, it is a representation of the result; otherwise, the behavior is undefined .
This code can be corrected by deliberately writing 1 as a 64-bit literal, or by performing type extension through a cast. More details about the shifts are written in the article " Without knowing the ford, do not climb into the water. Part three ".
Expansion through the cast, by the way, was used elsewhere. Here is the code:
AlphaNum::AlphaNum(Hex hex) { .... uint64 value = hex.value; uint64 width = hex.spec; // We accomplish minimum width by OR'ing in 0x10000 to the user's // value, // where 0x10000 is the smallest hex number that is as wide as the // user // asked for. uint64 mask = ((static_cast<uint64>(1) << (width - 1) * 4)) | value; .... } → Link to GitHub
PVS-Studio warning : V592 The expression was enclosed by parentheses twice: (((expression)). One pair of parentheses is unnecessary or misprint is present. strcat.cc 43
This is a valid code that the analyzer found suspicious by detecting duplicate parentheses. The analyzer reasons like this: double brackets do not affect the result of the expression, therefore, perhaps, one pair of brackets is not located where necessary.
It cannot be ruled out that they wanted to put brackets here in order to explicitly emphasize the sequence of calculations, and so that they would not have to remember the priorities of the operations '<<' and '*'. But, since they are in the wrong place, there is no sense from them. I believe that the order of expressions here is correct (first, the amount of shift is given, and then the shift itself is performed), so you just need to put brackets correctly so that they are not misleading.
uint64 mask = (static_cast<uint64>(1) << ((width - 1) * 4)) | value; Go ahead.
void Compute(OpKernelContext* context) override { .... int64 v = floor(in_x); .... v = ceil(in_x1); x_interp.end = ceil(in_x1); v = x_interp.end - 1; .... } → Link to GitHub
PVS-Studio warning : V519 The 'v' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 172, 174. resize_area_op.cc 174
Write to the variable v twice, and the value of this variable is not used between assignments. Moreover, the same value is written to x_interp.end , which was previously written to the variable v . Even if we omit the fact of an unnecessary call to the ceil function, since it is not critical (although ...), the code still looks strange: either it is just strangely written, or it contains a cunning error.
Farther:
void Compute(OpKernelContext* context) override { .... int64 sparse_input_start; // <= .... if (sparse_input) { num_total_features += GetNumSparseFeatures( sparse_input_indices, *it, &sparse_input_start); // <= } if (num_total_features == 0) { LOG(WARNING) << "num total features is zero."; break; } if (rand_feature < input_spec_.dense_features_size()) { .... } else { .... const int32 sparse_index = sparse_input_start + // <= rand_feature - input_spec_.dense_features_size(); .... } .... } → Link to GitHub
PVS-Studio Warning : V614 Potentially uninitialized variable 'sparse_input_start' used. sample_inputs_op.cc 351
Suspicious in this code, it looks like the potentially uninitialized variable sparse_input_start can be used when initializing the constant sparse_index . At the moment of declaration, this variable is not initialized by any value, i.e. contains some rubbish. Below, under the condition that the expression sparse_input is true , the address of the variable sparse_input_start is passed to the function GetNumSparseFeatures , where, probably, this variable is initialized. But otherwise, if the body of this conditional operator is not executed, sparse_input_start will remain uninitialized.
Of course, it can be assumed that if sparse_input_start remains uninitialized, it will not get to its use, but this is too bold and not obvious, so it would be nice to set a standard value for the variable.
It's all?
Yes and no. To be honest, I myself was hoping to find more defects and wanted to write an article in the spirit of testing Qt , Mono , Unreal Engine 4 and the like, but it did not work out. Errors did not roll here and there, so you should pay tribute to the developers of the project. However, I was hoping that the project would be larger in size, but in the selected configuration only about 700 files were checked, including the auto-generated ones.
In addition, some remained outside the scope of this article, for example:
- Only warnings from the GA group were considered;
- The warnings of confidence level 3 (Low) were not considered;
- Several dozens of V730 warnings were issued , but it’s difficult to judge their criticality, therefore we leave them outside the article to the developers;
- And so forth
However, as we saw, PVS-Studio found a number of interesting code fragments, which were discussed in this article.
Summarizing
TensorFlow turned out to be quite interesting and high-quality from the point of view of the code project, but, as we saw, not without flaws. And PVS-Studio once again demonstrated that it is able to find errors even in the code of famous developers.
In conclusion, I would like to praise everyone who is working on TensorFlow for the quality code, and wish them good luck in the future.
Oh yes, I almost forgot.

Everyone who read to the end - thank you for your attention, a reckless code, and do not forget to use PVS-Studio !

If you want to share this article with an English-speaking audience, then please use the link to the translation: Sergey Vasiliev. War of the Machines: PVS-Studio vs. Tensorflow
Read the article and have a question?
Often our articles are asked the same questions. We collected answers to them here: Answers to questions from readers of articles about PVS-Studio, version 2015 . Please review the list.
Source: https://habr.com/ru/post/326256/
All Articles