Green light to developers - from startup to the stars. Valentin Gogichashvili
The PG Day conference is held for the fourth time. During this time we have accumulated a large base of useful materials from our speakers. The level of reports in the industry every year is becoming higher and higher, but there are topics that, like good wine, do not lose their relevance.
At one of the past PG Day, Valentin Gogichashvili , who heads Data Engineering in Zalando, told how PostgreSQL is used in a company with a large staff of developers, highly dynamic processes, and how they came to this choice.
It's no secret that Zalando is a regular guest at PG Day. At PG Day'17 Russia we will present you three wonderful reports from German colleagues. Murat Kabilov and Alexey Klyukin will talk about the internal development of Zalando for the deployment of highly accessible PostgreSQL clusters . Alexander Kukushkin will tell about the practice of operating PostgreSQL in AWS . Dmitry Dolgov will help to understand the internals and performance of the JSONB data type in the context of using PostgreSQL as a document-oriented storage.

For the first time in my entire life I will present it in Russian. Do not judge if any translations and terms will be very funny for you. I'll start with myself. I am Valentine, head of Data Engineering in Zalando.
')



Zalando is a very famous in Europe online store selling shoes and everything related to clothing. That's how it looks about. Brand awareness of about 98% in Germany, our marketers did a very good job. Unfortunately, when marketers work well, it becomes very bad technology departments. At the time when I came to Zalando 4 years ago, our department consisted of 50 people, and we grew by 100% per month. And so it went on for a very long time. Now we are one of the biggest online stores. We have three warehouse centers, millions of users and 8 thousand employees.


Behind the interface screen, you have a great idea; terrible things are happening, including such warehouses: we have three such things. And this is only one small room, which is sorted. From a technological point of view, everything is much more beautiful, it is very good to draw diagrams. We have a wonderful person who can draw.

Postgres occupies one of the most important niches in our structure, because Postgres records everything related to user data. In fact, Postgres records everything except search data. We are looking at Solar's. Our technology office currently employs 700 people. We grow very fast and are constantly looking for people. Berlin has a large office. Smaller offices in Dortmund, Dublin and Helsinki. In Helsinki, opened literally last month, there is now going hiring.


What are we doing as a technology company?
We used to be Java and Postgres company: everything was written in Java and recorded in Postgres. In March 2015, we announced the concept of radical agility , which gives our teams endless autonomy with the choice of technology. Therefore, it is very important for us that Postgres is still the technology for our developers that they will choose themselves, and not I will come and say, “Well, let's write to Postgres”. Six terabytes occupies the base for “transactional” data. The largest database that is not included there is the event log, which we use to record our timeseries, business events (about 7 terabytes). It is interesting to work with this data. Many new things you learn about everything.

What problems do we have?
Constant growth, fast weekly development cycles: new features roll out every week. And downtime is not encouraged. Recently, we have a problem - autonomous development teams are dragging databases into their Amazon AWS accounts, and DBA-shniki do not have access to these databases.

I will tell about how we change the data scheme so that the production does not stand idle. How we work with data (access to databases in Zalando is carried out through a layer of stored procedures). I will explain very briefly why I think this is important. And as we shardim, as we break the database, also tell.

So, in Postgres, one of the most important abilities is the ability to change data schemes with virtually no locks . The problems that exist in Oracle, in MySQL and in many other systems, and which essentially led to the fact that NoSQL databases have risen as full members of our friendly family of databases, lies in the fact that other databases cannot so quickly and well change data schemas. In PostgreSQL no locks are needed to add a column or rename it, drop it or add default values, expand directories.
All that is needed is a barrier lock, which must ensure that no one else touches this table, and change the directory. Almost all operations do not require rewriting gigabytes of data. It's the most important. In particular, it is possible to create and delete indexes CONCURRENTLY (an index will be created without locking your table).
Problems after all exist with. Until now, it is not possible to add constraint NOT NULL to a large giant table without having to check that there are really no zero values in the table in the columns. This is correct because we trust constraints. But, unfortunately, there are a couple of exceptions that need to be applied in order for all this to work well, there are no scary locks that will stop the entire system.

How did we organize it? When I started in Zalando, I was the only DBA. I wrote all the scripts that change the database structure. Then we realized that it was terrible, because we need to do this on every staging environment. I started dumping directories in different environments and comparing them with diffs. There was an idea to automate the creation of dbdiffs. I realized that it’s not possible to waste time on such a tool, and it’s still easier to write with my hands the transition scripts from one version to another. But the name dbdiff remains.
With the growth that we had, it became impossible to write dbdiff by ourselves. So we had to teach developers to write SQL, train them and certify the basics of PostgreSQL, so that they understand how the database works, why there are locks, where regressions occur, etc. Therefore, we have introduced certification for "releasers". Only a person with such a certificate of our team receives administrative rights to the base and can stop the system. We, of course, come to the rescue and help, advise, do everything to ensure that the guys do not have problems.


Here is an example of what a very simple dbdiff looks like: the order_address and foreign key table is added. The problem is that if the table is changed during development, the source of this table must be changed each time. Since each object, each table lies in a separate file in git, you need to go in and change dbdiff every time, you can use the excellent opportunity pl / pgsql to load files from a directory.

Interestingly, the operation of adding a foreign key constraint is problematic because it requires locking the entire table, which can take a lot of time. In order to protect yourself, we recommend that you set statement_timeout to all - the number of seconds during which it is permissible for your system to keep locks. If the table fits in memory, 3 seconds is usually enough. If it does not fit, you will not scan it in 3 seconds.

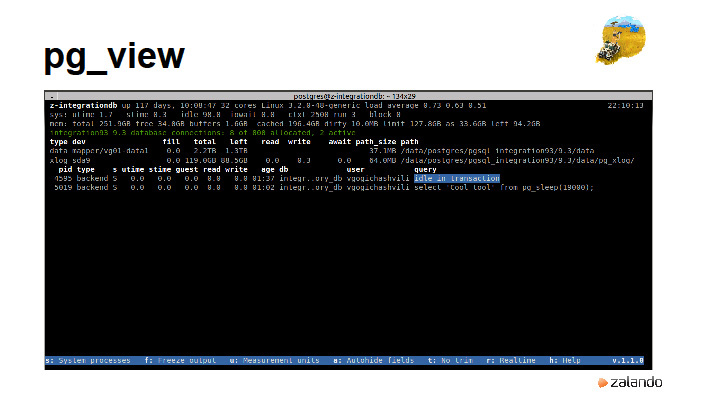
What else helps us? We are helped by the tools we wrote. pg_view collects all the database information we need, including locks, the partition occupancy with xlog. It looks something like top. This tool collects information about how much disk space is left so that you can stop the migration in time if something goes wrong and shows locks that occur in the database.
nice_updater is a program that controls the database, looks at its load, the workload of the xlog-partitions, slowly, 10-100 thousand records, executes update statements, periodically starts a vacuum. So we are doing big migrations. If you need to add some table or write new values to additional columns, this is very easy to do with nice_updater. We rolled out some operation, due to which a few gigabytes of incorrect data was formed, they need to be rewritten - nice_updater helps us very well. In my opinion, it is already in open source. We try all of our tools “open source”: the quality of the code is very high, documentation appears.
The biggest advice I can give is to force programmers to write code that is equal to everything, is there a database or not. Our biggest mistake was that Postgres worked too well, the developers thought that the database is always like gravity. Therefore, any disconnection of the database for 2 seconds is regarded by our developers as a horror and a complete disaster. They do not write ROLLBACK, do not handle errors of this type, they do not have tests.
Having the ability to disable the base for 30 seconds in order to conduct an upgrade or do something else with the base is, in fact, the first thing to be. Today, Andres and I [ca. Ed .: Andres Freund ] said that in general you need to make a mode that will randomly disable connections, so that developers learn to write normal code. We have a script that kills everything that takes more than five minutes. Statement timeout is set to 30 seconds by default. If someone writes a procedure that takes more than 30 seconds, he needs to give good reasons.



What do stored procedures give us?
The biggest advantage is the ability to replace data on the fly: add a new empty column, reading data from the old column. Then turn on the record in both columns and do readings from the new one, implementing a fallback to the old one using coalesce. Then migrate the data to a new column. And then you can already throw out the old one. A couple of times we did normalization of the tables so that the application code did not know about it at all. This feature is important for keeping the system in working condition.
With good training and with good tools, we managed in principle to avoid downtime caused by migrations or changes in the data structure. In order to understand the scale of the number of changes: we have about 100 dbdiffs rolling out per database. And they basically change the tables. They regularly say that relational databases lack flexibility in changing data structures. It is not true.
We try to do dbdiff transactions, but, unfortunately, there are commands that are not transactional, for example, changing enum.



How do they usually refer to the data?
Here we have a classical structure - a hierarchy of objects: customer, it has a bank account. There are many different orders, orders are listed positions. What is good about this hierarchy? Objects that are tied to a customer are associated only with it. In most cases, we do not need to go beyond this hierarchy. We are not interested at all when placing an order with Customer A, which orders are available with Customer B, and vice versa. Everyone knows that there are a lot of advantages: you stay in your comfort zone, use the same language in which you write business logic.
But we had big problems with hibernate, to teach developers to write code that will work well with transactions. Developers are trying to load the entire table into memory, then do something with it and commit some parts in a couple of minutes. A long transaction remains, and the longer it is, the more difficult it is to make migrations in schemas. Tables must be constantly displayed in the code. We have no such thing as a database separate from the application. We call this data logic. In essence, these are constraints that are superimposed on the data, and it is convenient to keep them in stored procedures. This is not possible with migrations. In fact, this is a separate data layer.
If there are no stored procedures, it is better to have an abstract layer inside the application. Netflix, for example, also does this. They have a special library, with which they completely abstract data access through the data layer. Thus, they migrated from Oracle to Cassandra: they divide logic into business and data, and then replace business logic with another database. But changing the scheme in such a situation can be a nightmare.

NoSQL is a great thing, you can take this whole hierarchy along with all the orders and create one document. Nothing needs to be initialized, everything is written directly in JSON. Transactions are not needed: what is recorded, then recorded. There are implicit schemes. How to work with this when the structure of the document begins to change and where to push all this logic? This is scary. At the moment, unfortunately, there is not a single NoSQL database, except PostgreSQL, which is in ACID and does not lose data.
And, accordingly, in NoSQL there is no SQL. SQL is a very powerful language for analytic operations, converts data very quickly. To do all this, for example, in Java is also somehow scary.

What are the alternatives to ORM?
Direct SQL queries. You can pull aggregates from the database without using stored procedures. There are clear transaction boundaries - one SQL is started, no time is spent on processing data between transactions. A very good example: YeSQL on Clojure works, almost like a stored procedure. And Scala Slick - if you are involved in Scala and have not yet seen Slick, then you should definitely watch the source code, this is one of the most impressive pieces of code I've ever seen.

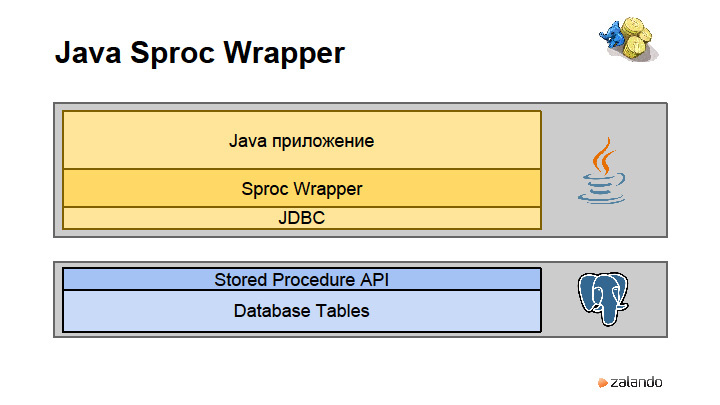
Stored procedures. Clear transaction boundaries. Abstraction from the data layer. This is a recipe for a classic application written in Java.
We have business logic, JDBC Driver and data tables. What have we done? We first implemented the stored procedure layer. Suppose we return a row, for example, getFullCustomerInformation , in which there is an array, its orders are serialized by Postgres, inside there is also an array with positions, inside which there is an array with bank data. It turns out very well typed hierarchical structure. If this is all written in Java, at some point we have 50 pages of members in the classes. This led to such terrible consequences that we decided to write our own library. They called it Sproc Wrapper, which works like an APC Layer in a database. It essentially makes the database an application server.




What does this look like?
The stored procedure is written, then such a small interface with annotations is written. The register_customer call is completely transparent to the application, the stored procedure in the database is called, as is the serialization / deserialization of all the terrible nested arrays, hash maps, etc. Including order address structures, which are maps as list of orders.

What problems?
Problems with stored procedures are that you need to write too much code. If you need to do a lot of CRUD operations (you write new Excel), I would not advise using stored procedures. If you have tables with 100 columns, you have to enter the change for each column as a separate stored procedure, then you can go crazy. We had people who wrote bootstrapper, generating these stored procedures. But then we said that it is better to use hibernate in this situation and edit these tables. We have, for example, in the procurement team, which drive in product information, there is a tool, it is written in hibernate. These tools are used by 500 people, and 15 million use our main site.
What is positive? Need to learn SQL. This is very helpful for developers. Developers who started to teach Closure and Scala now periodically come to me and say “Scala is almost like SQL, wow !!!”. I guess, yes. Data pipelines that flow upwards through functional filters are exactly what SQL has always done. Unfortunately, there is still no execution planner in Scala.

Automate everything.
Everything that is done by hand is likely to be done poorly. It is very important to know how PostgreSQL works, how systems work so that nothing breaks.
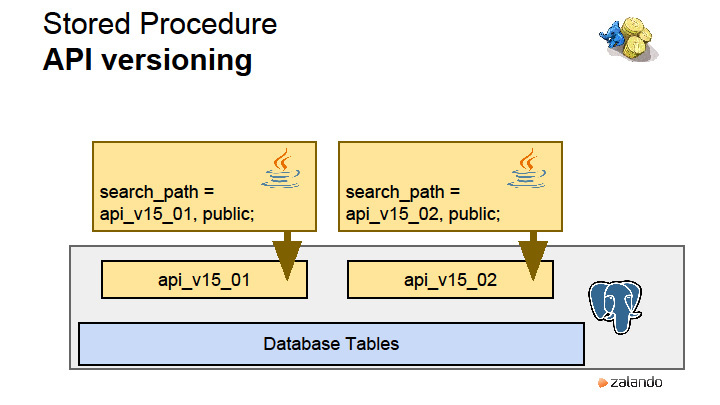
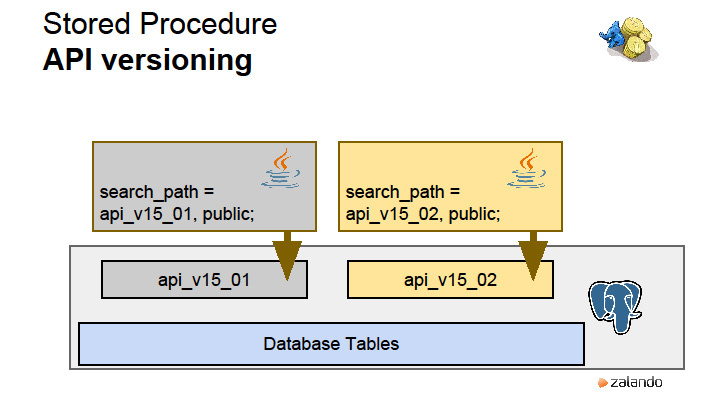
How do we version?
At first, when we first started using stored procedures, when we changed the procedure, the type of data that it returns was changed. You need to drop the old procedure, roll out a new one. All this in one transaction. If there are any dependencies between stored procedures, I had to look for them with pens. Drop completely and roll out again. When I was the only DBA in the company, all I did was to write these scary dbdiff updates to stored procedures. Then we somehow sat down and came up with the idea that you can use the amazing PostgreSQL search_path feature that controls the paths to search for objects in a session. If your application with version 15.01 opens and exposes search_path, then the objects it will find will be located in this scheme.
Our deployment tool while rolling out the application with this set of stored procedures creates a schema of the required version and loads everything there. Application then uses them. What happens when we roll out a new version? The Deployment tool rolls out a new scheme with the entire set of stored procedures that we have, and at the moment a new version rolls out, we actually have both versions, each with its own set of stored procedures. There is nothing related to the data. These are the so-called API schemes that provide the data access layer and nothing else. And all the migrations that happen, they happen here. Therefore, when migration occurs, it must be compatible with the previous version, which is still working.
Question from the audience : How long did you teach the developers to work on such a flow? How to ensure that everyone does exactly that and did not migrate, which are not compatible with previous versions? Do you somehow test additionally that the migration is indeed correct, that the new API correctly reads old data and does not fall at the same time?
Valentin : This is, of course, a question of how well test coverage works, and how well everything is tested. We have developers working on local databases, then we have integration staging, test staging, release staging and production.
Question from the audience : Who writes API, DBA or developers? How is the separation of access rights?
Valentine: They write the developers. The option when DBA does this is not scalable. I know a few small companies in which DBA write all APIs in general. When they called me, they also thought that I would write an API. But this is impossible. We first hired five people a month, now we hire 40 people a month. Therefore, it is easier to spend time for developers to learn how to work with the database. It is very simple in fact, if you explain how everything is physically stored and arranged.

Testing is very convenient, because the entire API layer is being tested, and no migration is required. Everything can be automated.


What are the positive points that we have one big base?
If I were asked if you can do everything in one big base, I would answer: stay in one big base as long as you can afford it. If you have all your business data in the database memory, do not do anything, stay in the same database, it is very beautiful. You can do analytics quickly, link data between objects, and strategies for accessing various data are trivial. It is enough to support one machine, and not a whole bunch of different nodes.



But the problem occurs when you have more data than RAM. Everything becomes slower: migrations, backups, maintenance, upgrades. The larger the base, the greater the headache. We share data: we take one large logical base and put it on many PostgreSQL instances.



What is so good about it?
Again, our bases are getting small. You can work with them quickly, but the problem, of course, is that it is already impossible to make joines. More tools are needed for analysts. To work with the data requires more tools. If you think that you can work with large amounts of data without investing in the development of an infrastructure that automates your processes, then you are mistaken. It is impossible to do. Need to write a lot of tools.

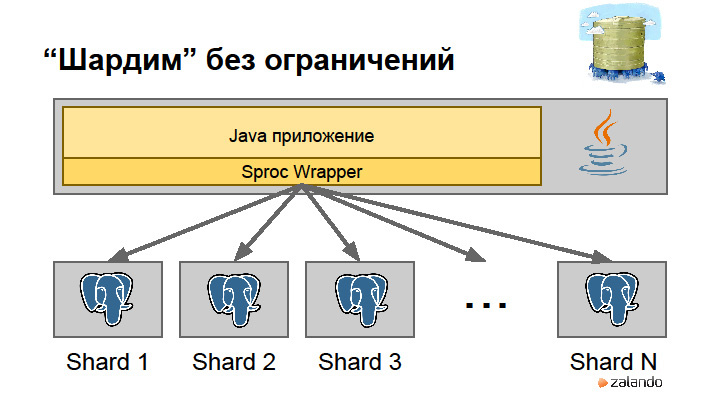


We had an advantage. We already had a Sproc Wrapper, which provides us with a data layer. We just taught him to access different databases.
What does this look like? We have a call to the findOrders function with the runOnAllShards parameter= true. He calls the stored procedure on all shards that he had registered. Or we have a CustomerNumber , and we say it is a shard key. In the configuration, you can specify which search strategy (Lookup Strategy) can be used: parallel search by shards, shard aware ID, and hashing is also, in my opinion, supported. The most widely used strategy for finding objects on shards is the so-called Virtual Shard ID .

The idea is very simple indeed. We have a partitioning key - in the hierarchy that I showed, it will be CustomerNumber. A partitioning key is a key that defines for each object the boundaries of the connections between your objects.
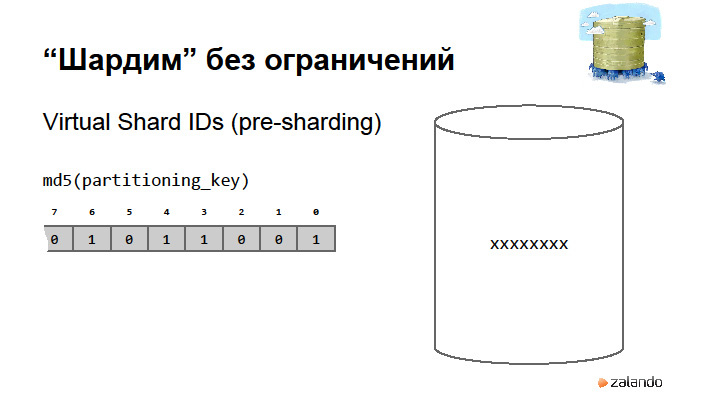
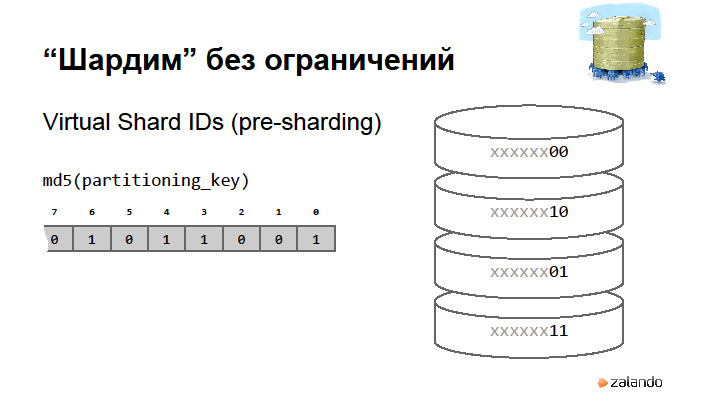
Key formation.
The main thing is to understand what partitioning key is. For example, we have users. The user has his orders, and many orders are attached to these orders. Partitioning key is a common key that selects a group of objects that belong to the same user. We will have a customer number, a unique user number. It must be dragged along with all objects of type Order, the underlying objects in the hierarchy, in order to understand where my Customer is located. I should always be able to find out where the parent lies for the objects in the hierarchy. I'm afraid to say Customer ID, because ID is a technical key. We are not talking about technical keys. We are talking about logical keys. Because technical keys will not be unique within a logical base.
It is quite normal to use the UUID for the Customer ID. We distinguish between Customer Number and Customer ID. One Customer ID exists eight times in our system, in eight databases. And the Customer Number is always one. We are hashing with MD5, but you can do better. The main thing is that the hashes are distributed evenly. This is done at the level of sharding strategy. In fact, the hash needs to be implemented wherever the application needs to quickly find the location of the hierarchy of objects. In our Sproc Wrapper situation, this will be just the Sharding Strategy for the Customer object.
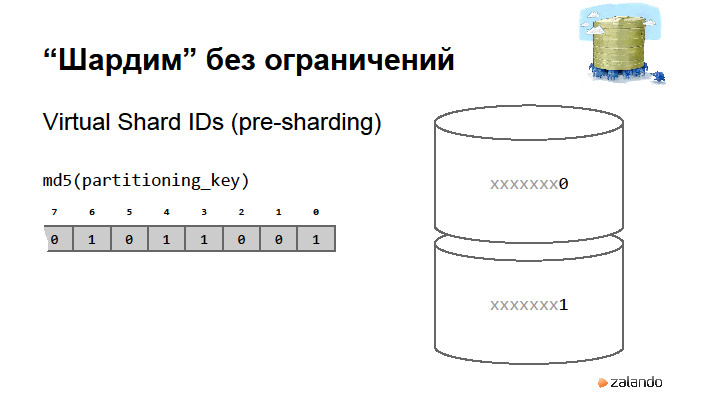
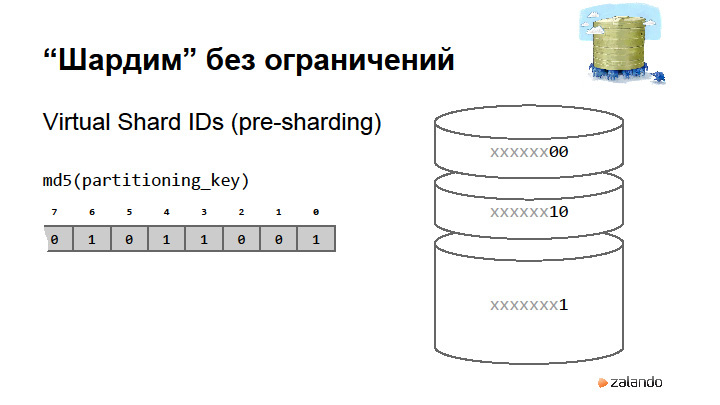
By the size of the hash of this key, we determine the number of virtual shards. What happens when we want to split the base? We just say that we share the base and start using the first bit in our hash. Thus, when the base is divided, we can indicate that it was a master, it became a slave, and at such a moment we will have a very short system shutdown. At the moment this is so. It could be fully automated to be transparent. We turn off the system, change the sharding strategy, and say that from now on we have access here and here, but we write data that has the first bit, one, to another database that already has data. The only thing we need to do after this is to erase all the objects that belong to one from this database, and on the other, to erase all the data that belong to zero. And so on.Even can be asymmetrically divided. Sharding strategy may know that if you start a hash from scratch, then there are still a couple of shards. So it is better not to do it, because you can go crazy. In principle, we have already shared it twice.

We are now experimenting with the amazing PostgreSQL feature - logical replication . This is a multi-master - the possibility of upgrades to the major version without having to stop the system, do everything slowly and painfully. Partial replication - you can pull out of the database only one table or part of the table. Make updates to caches.


We are working very hard to pull PostgreSQL into AWS with the great capabilities that RDS currently provides. Our AWS team has developed a system called STUPS. It allows you to roll out docker images in Spilo, traceable and monitorable way. Spilo with the help of three commands can roll out a PostgreSQL cluster on AWS, which will be high available, switch itself when one of the nodes is turned off, and choose a wizard. But this is a topic for another discussion.

At one of the past PG Day, Valentin Gogichashvili , who heads Data Engineering in Zalando, told how PostgreSQL is used in a company with a large staff of developers, highly dynamic processes, and how they came to this choice.
It's no secret that Zalando is a regular guest at PG Day. At PG Day'17 Russia we will present you three wonderful reports from German colleagues. Murat Kabilov and Alexey Klyukin will talk about the internal development of Zalando for the deployment of highly accessible PostgreSQL clusters . Alexander Kukushkin will tell about the practice of operating PostgreSQL in AWS . Dmitry Dolgov will help to understand the internals and performance of the JSONB data type in the context of using PostgreSQL as a document-oriented storage.
For the first time in my entire life I will present it in Russian. Do not judge if any translations and terms will be very funny for you. I'll start with myself. I am Valentine, head of Data Engineering in Zalando.
')
Zalando is a very famous in Europe online store selling shoes and everything related to clothing. That's how it looks about. Brand awareness of about 98% in Germany, our marketers did a very good job. Unfortunately, when marketers work well, it becomes very bad technology departments. At the time when I came to Zalando 4 years ago, our department consisted of 50 people, and we grew by 100% per month. And so it went on for a very long time. Now we are one of the biggest online stores. We have three warehouse centers, millions of users and 8 thousand employees.
Behind the interface screen, you have a great idea; terrible things are happening, including such warehouses: we have three such things. And this is only one small room, which is sorted. From a technological point of view, everything is much more beautiful, it is very good to draw diagrams. We have a wonderful person who can draw.
Postgres occupies one of the most important niches in our structure, because Postgres records everything related to user data. In fact, Postgres records everything except search data. We are looking at Solar's. Our technology office currently employs 700 people. We grow very fast and are constantly looking for people. Berlin has a large office. Smaller offices in Dortmund, Dublin and Helsinki. In Helsinki, opened literally last month, there is now going hiring.
What are we doing as a technology company?
We used to be Java and Postgres company: everything was written in Java and recorded in Postgres. In March 2015, we announced the concept of radical agility , which gives our teams endless autonomy with the choice of technology. Therefore, it is very important for us that Postgres is still the technology for our developers that they will choose themselves, and not I will come and say, “Well, let's write to Postgres”. Six terabytes occupies the base for “transactional” data. The largest database that is not included there is the event log, which we use to record our timeseries, business events (about 7 terabytes). It is interesting to work with this data. Many new things you learn about everything.
What problems do we have?
Constant growth, fast weekly development cycles: new features roll out every week. And downtime is not encouraged. Recently, we have a problem - autonomous development teams are dragging databases into their Amazon AWS accounts, and DBA-shniki do not have access to these databases.
I will tell about how we change the data scheme so that the production does not stand idle. How we work with data (access to databases in Zalando is carried out through a layer of stored procedures). I will explain very briefly why I think this is important. And as we shardim, as we break the database, also tell.
So, in Postgres, one of the most important abilities is the ability to change data schemes with virtually no locks . The problems that exist in Oracle, in MySQL and in many other systems, and which essentially led to the fact that NoSQL databases have risen as full members of our friendly family of databases, lies in the fact that other databases cannot so quickly and well change data schemas. In PostgreSQL no locks are needed to add a column or rename it, drop it or add default values, expand directories.
All that is needed is a barrier lock, which must ensure that no one else touches this table, and change the directory. Almost all operations do not require rewriting gigabytes of data. It's the most important. In particular, it is possible to create and delete indexes CONCURRENTLY (an index will be created without locking your table).
Problems after all exist with. Until now, it is not possible to add constraint NOT NULL to a large giant table without having to check that there are really no zero values in the table in the columns. This is correct because we trust constraints. But, unfortunately, there are a couple of exceptions that need to be applied in order for all this to work well, there are no scary locks that will stop the entire system.
How did we organize it? When I started in Zalando, I was the only DBA. I wrote all the scripts that change the database structure. Then we realized that it was terrible, because we need to do this on every staging environment. I started dumping directories in different environments and comparing them with diffs. There was an idea to automate the creation of dbdiffs. I realized that it’s not possible to waste time on such a tool, and it’s still easier to write with my hands the transition scripts from one version to another. But the name dbdiff remains.
With the growth that we had, it became impossible to write dbdiff by ourselves. So we had to teach developers to write SQL, train them and certify the basics of PostgreSQL, so that they understand how the database works, why there are locks, where regressions occur, etc. Therefore, we have introduced certification for "releasers". Only a person with such a certificate of our team receives administrative rights to the base and can stop the system. We, of course, come to the rescue and help, advise, do everything to ensure that the guys do not have problems.
Here is an example of what a very simple dbdiff looks like: the order_address and foreign key table is added. The problem is that if the table is changed during development, the source of this table must be changed each time. Since each object, each table lies in a separate file in git, you need to go in and change dbdiff every time, you can use the excellent opportunity pl / pgsql to load files from a directory.
Interestingly, the operation of adding a foreign key constraint is problematic because it requires locking the entire table, which can take a lot of time. In order to protect yourself, we recommend that you set statement_timeout to all - the number of seconds during which it is permissible for your system to keep locks. If the table fits in memory, 3 seconds is usually enough. If it does not fit, you will not scan it in 3 seconds.
What else helps us? We are helped by the tools we wrote. pg_view collects all the database information we need, including locks, the partition occupancy with xlog. It looks something like top. This tool collects information about how much disk space is left so that you can stop the migration in time if something goes wrong and shows locks that occur in the database.
nice_updater is a program that controls the database, looks at its load, the workload of the xlog-partitions, slowly, 10-100 thousand records, executes update statements, periodically starts a vacuum. So we are doing big migrations. If you need to add some table or write new values to additional columns, this is very easy to do with nice_updater. We rolled out some operation, due to which a few gigabytes of incorrect data was formed, they need to be rewritten - nice_updater helps us very well. In my opinion, it is already in open source. We try all of our tools “open source”: the quality of the code is very high, documentation appears.
The biggest advice I can give is to force programmers to write code that is equal to everything, is there a database or not. Our biggest mistake was that Postgres worked too well, the developers thought that the database is always like gravity. Therefore, any disconnection of the database for 2 seconds is regarded by our developers as a horror and a complete disaster. They do not write ROLLBACK, do not handle errors of this type, they do not have tests.
Having the ability to disable the base for 30 seconds in order to conduct an upgrade or do something else with the base is, in fact, the first thing to be. Today, Andres and I [ca. Ed .: Andres Freund ] said that in general you need to make a mode that will randomly disable connections, so that developers learn to write normal code. We have a script that kills everything that takes more than five minutes. Statement timeout is set to 30 seconds by default. If someone writes a procedure that takes more than 30 seconds, he needs to give good reasons.
What do stored procedures give us?
The biggest advantage is the ability to replace data on the fly: add a new empty column, reading data from the old column. Then turn on the record in both columns and do readings from the new one, implementing a fallback to the old one using coalesce. Then migrate the data to a new column. And then you can already throw out the old one. A couple of times we did normalization of the tables so that the application code did not know about it at all. This feature is important for keeping the system in working condition.
With good training and with good tools, we managed in principle to avoid downtime caused by migrations or changes in the data structure. In order to understand the scale of the number of changes: we have about 100 dbdiffs rolling out per database. And they basically change the tables. They regularly say that relational databases lack flexibility in changing data structures. It is not true.
We try to do dbdiff transactions, but, unfortunately, there are commands that are not transactional, for example, changing enum.
How do they usually refer to the data?
Here we have a classical structure - a hierarchy of objects: customer, it has a bank account. There are many different orders, orders are listed positions. What is good about this hierarchy? Objects that are tied to a customer are associated only with it. In most cases, we do not need to go beyond this hierarchy. We are not interested at all when placing an order with Customer A, which orders are available with Customer B, and vice versa. Everyone knows that there are a lot of advantages: you stay in your comfort zone, use the same language in which you write business logic.
But we had big problems with hibernate, to teach developers to write code that will work well with transactions. Developers are trying to load the entire table into memory, then do something with it and commit some parts in a couple of minutes. A long transaction remains, and the longer it is, the more difficult it is to make migrations in schemas. Tables must be constantly displayed in the code. We have no such thing as a database separate from the application. We call this data logic. In essence, these are constraints that are superimposed on the data, and it is convenient to keep them in stored procedures. This is not possible with migrations. In fact, this is a separate data layer.
If there are no stored procedures, it is better to have an abstract layer inside the application. Netflix, for example, also does this. They have a special library, with which they completely abstract data access through the data layer. Thus, they migrated from Oracle to Cassandra: they divide logic into business and data, and then replace business logic with another database. But changing the scheme in such a situation can be a nightmare.
NoSQL is a great thing, you can take this whole hierarchy along with all the orders and create one document. Nothing needs to be initialized, everything is written directly in JSON. Transactions are not needed: what is recorded, then recorded. There are implicit schemes. How to work with this when the structure of the document begins to change and where to push all this logic? This is scary. At the moment, unfortunately, there is not a single NoSQL database, except PostgreSQL, which is in ACID and does not lose data.
And, accordingly, in NoSQL there is no SQL. SQL is a very powerful language for analytic operations, converts data very quickly. To do all this, for example, in Java is also somehow scary.
What are the alternatives to ORM?
Direct SQL queries. You can pull aggregates from the database without using stored procedures. There are clear transaction boundaries - one SQL is started, no time is spent on processing data between transactions. A very good example: YeSQL on Clojure works, almost like a stored procedure. And Scala Slick - if you are involved in Scala and have not yet seen Slick, then you should definitely watch the source code, this is one of the most impressive pieces of code I've ever seen.
Stored procedures. Clear transaction boundaries. Abstraction from the data layer. This is a recipe for a classic application written in Java.
We have business logic, JDBC Driver and data tables. What have we done? We first implemented the stored procedure layer. Suppose we return a row, for example, getFullCustomerInformation , in which there is an array, its orders are serialized by Postgres, inside there is also an array with positions, inside which there is an array with bank data. It turns out very well typed hierarchical structure. If this is all written in Java, at some point we have 50 pages of members in the classes. This led to such terrible consequences that we decided to write our own library. They called it Sproc Wrapper, which works like an APC Layer in a database. It essentially makes the database an application server.
What does this look like?
The stored procedure is written, then such a small interface with annotations is written. The register_customer call is completely transparent to the application, the stored procedure in the database is called, as is the serialization / deserialization of all the terrible nested arrays, hash maps, etc. Including order address structures, which are maps as list of orders.
What problems?
Problems with stored procedures are that you need to write too much code. If you need to do a lot of CRUD operations (you write new Excel), I would not advise using stored procedures. If you have tables with 100 columns, you have to enter the change for each column as a separate stored procedure, then you can go crazy. We had people who wrote bootstrapper, generating these stored procedures. But then we said that it is better to use hibernate in this situation and edit these tables. We have, for example, in the procurement team, which drive in product information, there is a tool, it is written in hibernate. These tools are used by 500 people, and 15 million use our main site.
What is positive? Need to learn SQL. This is very helpful for developers. Developers who started to teach Closure and Scala now periodically come to me and say “Scala is almost like SQL, wow !!!”. I guess, yes. Data pipelines that flow upwards through functional filters are exactly what SQL has always done. Unfortunately, there is still no execution planner in Scala.
Automate everything.
Everything that is done by hand is likely to be done poorly. It is very important to know how PostgreSQL works, how systems work so that nothing breaks.
How do we version?
At first, when we first started using stored procedures, when we changed the procedure, the type of data that it returns was changed. You need to drop the old procedure, roll out a new one. All this in one transaction. If there are any dependencies between stored procedures, I had to look for them with pens. Drop completely and roll out again. When I was the only DBA in the company, all I did was to write these scary dbdiff updates to stored procedures. Then we somehow sat down and came up with the idea that you can use the amazing PostgreSQL search_path feature that controls the paths to search for objects in a session. If your application with version 15.01 opens and exposes search_path, then the objects it will find will be located in this scheme.
Our deployment tool while rolling out the application with this set of stored procedures creates a schema of the required version and loads everything there. Application then uses them. What happens when we roll out a new version? The Deployment tool rolls out a new scheme with the entire set of stored procedures that we have, and at the moment a new version rolls out, we actually have both versions, each with its own set of stored procedures. There is nothing related to the data. These are the so-called API schemes that provide the data access layer and nothing else. And all the migrations that happen, they happen here. Therefore, when migration occurs, it must be compatible with the previous version, which is still working.
Question from the audience : How long did you teach the developers to work on such a flow? How to ensure that everyone does exactly that and did not migrate, which are not compatible with previous versions? Do you somehow test additionally that the migration is indeed correct, that the new API correctly reads old data and does not fall at the same time?
Valentin : This is, of course, a question of how well test coverage works, and how well everything is tested. We have developers working on local databases, then we have integration staging, test staging, release staging and production.
Question from the audience : Who writes API, DBA or developers? How is the separation of access rights?
Valentine: They write the developers. The option when DBA does this is not scalable. I know a few small companies in which DBA write all APIs in general. When they called me, they also thought that I would write an API. But this is impossible. We first hired five people a month, now we hire 40 people a month. Therefore, it is easier to spend time for developers to learn how to work with the database. It is very simple in fact, if you explain how everything is physically stored and arranged.
Testing is very convenient, because the entire API layer is being tested, and no migration is required. Everything can be automated.
What are the positive points that we have one big base?
If I were asked if you can do everything in one big base, I would answer: stay in one big base as long as you can afford it. If you have all your business data in the database memory, do not do anything, stay in the same database, it is very beautiful. You can do analytics quickly, link data between objects, and strategies for accessing various data are trivial. It is enough to support one machine, and not a whole bunch of different nodes.
But the problem occurs when you have more data than RAM. Everything becomes slower: migrations, backups, maintenance, upgrades. The larger the base, the greater the headache. We share data: we take one large logical base and put it on many PostgreSQL instances.
What is so good about it?
Again, our bases are getting small. You can work with them quickly, but the problem, of course, is that it is already impossible to make joines. More tools are needed for analysts. To work with the data requires more tools. If you think that you can work with large amounts of data without investing in the development of an infrastructure that automates your processes, then you are mistaken. It is impossible to do. Need to write a lot of tools.
We had an advantage. We already had a Sproc Wrapper, which provides us with a data layer. We just taught him to access different databases.
What does this look like? We have a call to the findOrders function with the runOnAllShards parameter= true. He calls the stored procedure on all shards that he had registered. Or we have a CustomerNumber , and we say it is a shard key. In the configuration, you can specify which search strategy (Lookup Strategy) can be used: parallel search by shards, shard aware ID, and hashing is also, in my opinion, supported. The most widely used strategy for finding objects on shards is the so-called Virtual Shard ID .
The idea is very simple indeed. We have a partitioning key - in the hierarchy that I showed, it will be CustomerNumber. A partitioning key is a key that defines for each object the boundaries of the connections between your objects.
Key formation.
The main thing is to understand what partitioning key is. For example, we have users. The user has his orders, and many orders are attached to these orders. Partitioning key is a common key that selects a group of objects that belong to the same user. We will have a customer number, a unique user number. It must be dragged along with all objects of type Order, the underlying objects in the hierarchy, in order to understand where my Customer is located. I should always be able to find out where the parent lies for the objects in the hierarchy. I'm afraid to say Customer ID, because ID is a technical key. We are not talking about technical keys. We are talking about logical keys. Because technical keys will not be unique within a logical base.
It is quite normal to use the UUID for the Customer ID. We distinguish between Customer Number and Customer ID. One Customer ID exists eight times in our system, in eight databases. And the Customer Number is always one. We are hashing with MD5, but you can do better. The main thing is that the hashes are distributed evenly. This is done at the level of sharding strategy. In fact, the hash needs to be implemented wherever the application needs to quickly find the location of the hierarchy of objects. In our Sproc Wrapper situation, this will be just the Sharding Strategy for the Customer object.
By the size of the hash of this key, we determine the number of virtual shards. What happens when we want to split the base? We just say that we share the base and start using the first bit in our hash. Thus, when the base is divided, we can indicate that it was a master, it became a slave, and at such a moment we will have a very short system shutdown. At the moment this is so. It could be fully automated to be transparent. We turn off the system, change the sharding strategy, and say that from now on we have access here and here, but we write data that has the first bit, one, to another database that already has data. The only thing we need to do after this is to erase all the objects that belong to one from this database, and on the other, to erase all the data that belong to zero. And so on.Even can be asymmetrically divided. Sharding strategy may know that if you start a hash from scratch, then there are still a couple of shards. So it is better not to do it, because you can go crazy. In principle, we have already shared it twice.
We are now experimenting with the amazing PostgreSQL feature - logical replication . This is a multi-master - the possibility of upgrades to the major version without having to stop the system, do everything slowly and painfully. Partial replication - you can pull out of the database only one table or part of the table. Make updates to caches.
We are working very hard to pull PostgreSQL into AWS with the great capabilities that RDS currently provides. Our AWS team has developed a system called STUPS. It allows you to roll out docker images in Spilo, traceable and monitorable way. Spilo with the help of three commands can roll out a PostgreSQL cluster on AWS, which will be high available, switch itself when one of the nodes is turned off, and choose a wizard. But this is a topic for another discussion.
Source: https://habr.com/ru/post/326246/
All Articles