Future API

I think we are not talking enough about the future of the API. I don’t remember a single good discussion about what the API is waiting for in the future. I don’t remember at all. But if we think about it well, then we will come to the conclusion that the API in the form in which we now understand is far from the end of the game. In this kind of API will not stay forever. Let's try to look into the future and answer the question of what will happen to the API in the future.
Turk
Our story begins in 1770 in the Hungarian Kingdom, which at that time was part of the Hapsburg Empire. Wolfgang von Kampelen develops a machine capable of playing chess. The idea was to play with the strongest players of the time.
Having completed the work on the machine, he impresses with her the yard of Maria Theresa of Austria. Campelen and his chess automaton are quickly becoming popular, winning chess players in demonstration games throughout Europe. Even such figures as Napoleon Bonaparte and Benjamin Franklin are among the eyewitnesses.
The car, which looked like a man dressed in Turkish robes, was actually a mechanical illusion. She was ruled by a living person sitting inside. The Turk was just an elaborate stunt. The myth, invented in order to make people think that they are competing with a real machine. The secret was fully revealed only in the 1850th year.
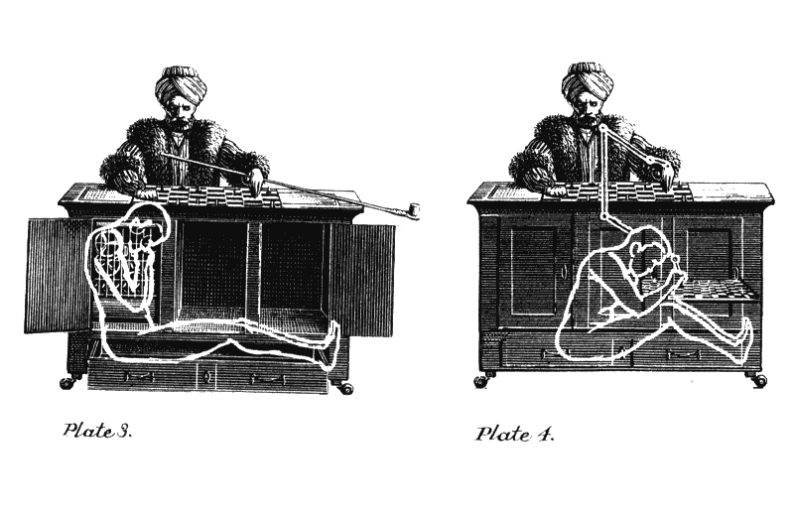
Since then, the term "Mechanical Turk" (Mechanical Turk) has been used for systems that look completely autonomous, but actually need a person to function.
Strangers
Fast forward to the year 1963, where American psychologist and scientist Joseph Liklider writes "Memorandum for Members and Allies of the Galactic Computer Network."
Liquidlider is one of the most important figures in the history of computers. It can be safely called a visionary. He foresaw the emergence of graphical interfaces and was involved in the creation of ARPANET and the Internet.
In the memorandum, Liklider asks:
"How will you begin communication between two wise beings who are not connected with each other?"
Imagine that there is a giant network connecting many galaxies and connecting intelligent beings that have never met before. The question is: How will they communicate when they meet?
Similar to the picture shown in the movie "Arrival" (2016), these creatures will have to explore each other, observe and record the reactions in order to first find a common lexicon. And only then will they be able to use this vocabulary to have a meaningful dialogue.
The end of the Turk era
We are transferred for 33 years forward, in 1996. Computer IBM Deep Blue wins the first game in a chess tournament with world champion Garry Kasparov. At the end of the tournament, Kasparov won the match of six games, losing only the first game.
IBM improves deep blue. A year later, the computer wins a rematch of 3½ – 2½, thus becoming the first car to win the reigning world champion.
227 years have passed between the original Turk of Kampelen and the real machine capable of defeating the best chess players of the planet.
The Second Coming of the Turks
Just 3 years after Deep Blue, in 2000, Roy Fielding publishes his thesis on Architectural Styles and Design of Software Network Architecture. This work will later become known as the architectural style of the REST API. It has become a template for the emergence of a whole generation of Web APIs using the HTTP protocol.
In the same year, Salesforce releases the first version of its Web API to automate sales. eBay joins a little later, and all other well-known Internet companies follow the trend.

But there is something strange about these web APIs. They seem to be protocols for communicating a computer with a computer. But in reality, this is not the case.
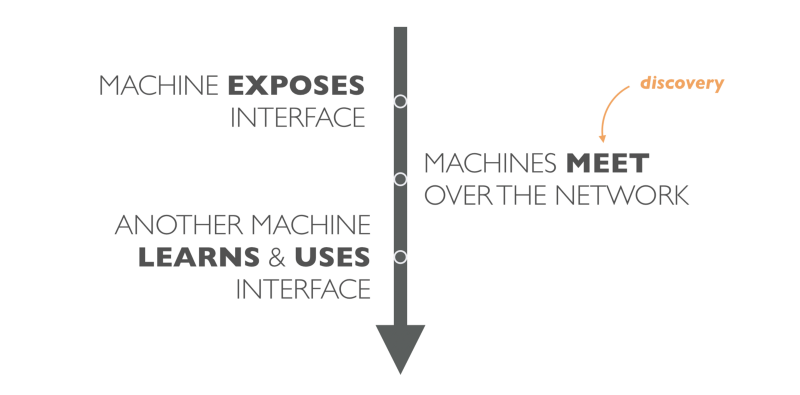
In reality, one service publishes an interface; then the person writes documentation to him and publishes it.
Another person should find this documentation and read it. Having obtained this knowledge, a person can program another machine to use this interface.

In fact, we have an intermediate layer in communicating a computer with a computer that includes us humans. As a result, what is meant by all as pure communication of a computer with a computer, in fact turns out to be a new Mechanical Turk.
Golden Era of the Turks
As in the case of the World Wide Web, companies around the world soon realized the importance of being in this segment of the Internet. The business levers launched the process, and we are witnessing the real boom of the Web API.

But as the API expands and the economy grows around them, new problems emerge. And, in most cases, these problems are directly related to the person hidden inside the API of the Turk.
Problem with API Turk
Each mature API must deal with the following tasks:
- synchronization
- versioning
- scaling
- detection
Synchronization
In the case of the Turk API, we create and distribute "Liklider dictionary" in advance. Ie, we write and publish API documentation before the two machines meet. And even if we forget that people may just misunderstand the documentation, we have an obvious problem when the API changes, but the documentation does not.
Keeping the API documentation in sync with the implementation is not an easy task. But supporting change in customers is even more difficult.
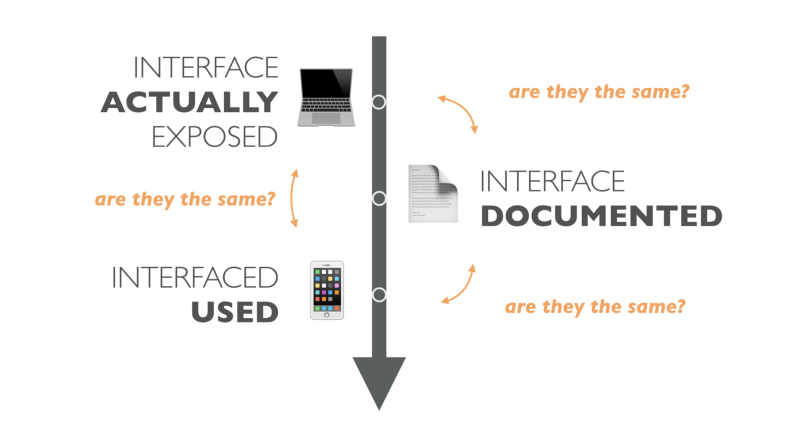
Versioning
Problems with synchronization lead us straight to the issue of versioning. Since most of the Turk APIs do not follow the REST principles described by Fielding, API clients are usually strongly associated with the interfaces used. Such strong connectivity creates very fragile systems. Changing the API can easily break the client. Moreover, human intervention is necessary to update an existing client for a new change in the API. But dependence on the person for such an action is expensive, slow, and, in most cases, inaccessible, since the client is already installed.
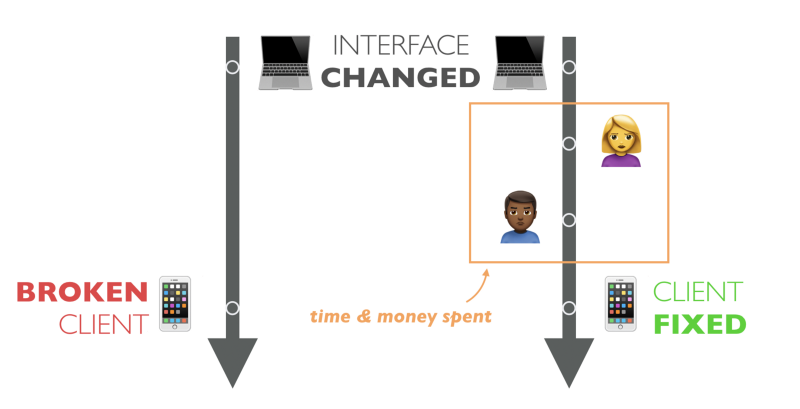
Because of these problems, we are afraid to make changes. We do not develop our API. Instead, we create new APIs on top of existing ones, polluting the code base. We increase the cost, technical debt and have endless discussions on how to solve versioning problems.
Scaling
Since there are people inside the API of the Turks, we have to hire more people to create more of the API of the Turks. And to make more mistakes. We are people - we make mistakes.
No matter how many people we hire - if we are talking about reading or writing documentation or correcting code for new changes in the API - we are limited in speed. Increasing the number of people somehow can help create more APIs, but it does not help at all to scale up the speed of response to changes.
Moreover, we often work with vague wording, which creates a lot of space for mistakes and misinterpretations. Where one person expects the title of the article, another will see the title.
What is it not the same thing?
Detection
And finally, there is still a problem with detectability. How do we know that there is a service that we want to use? Perhaps there is already a service that will give us the opportunity to build a breakthrough product, or simply save us valuable time.
API providers do not know where to offer themselves. It does not matter that this service for geolocation is better than the Google Places API - we simply have no way to even find out about it.
Word of mouth and Google is a so-called API detection solution. And, as with any other person-driven solution, this solution does not scale.
Possible exit
In the past decade, we have developed processes and tools to solve these problems. Together with the mass of the people, we have created a whole industry API. An economy that creates and maintains new Mechanical Turks.
The Workflow API, API Style Guide, API documentation best practices and other processes are running to maintain synchronization, prevent incompatible changes, and avoid human errors. We are creating even more tools to prop up these processes and support our API products.
We began to generate documentation and code automatically to achieve synchronization. We develop complex testing frameworks and hire more developers to support all of this. Now it’s quite common to have a whole team of developers on staff for documentation APIs only. Let me say it differently: We hire developers to create documentation for other developers so that they can understand the interface of one computer and program another computer to use it.
As one friend of mine says:
Programmers solve programming problems even more by programming.
If the API becomes popular, these providers become lucky enough to get money and spend it on marketing and various PR events. The rest are looking for good luck in the API directories or in the hope of being seen on Hacker News.
The role of man in communication between computers
So why do we need a person in the API Turk? What is the role of man in communication between computers?
People play a critical role in API detection and understanding. When we find any service, first of all we try to understand WHAT exactly we can do with it and HOW to do it.
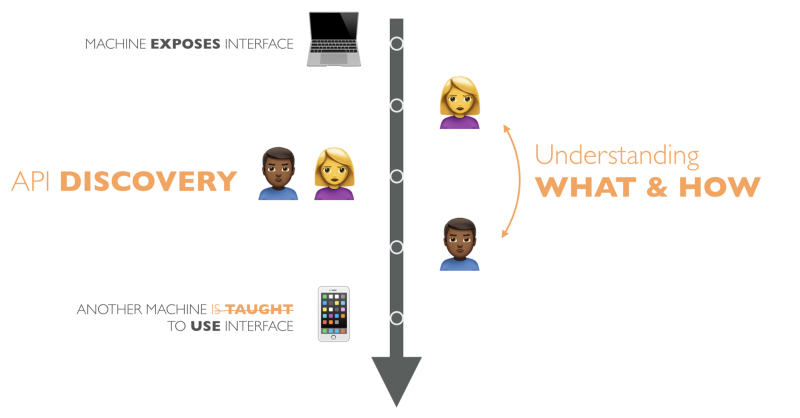
For example:
(API detection and WHAT): "Is there a service that will give me a weather forecast for Paris?"
(HOW): "How can I use this service to get the weather forecast for Paris?"
When we get answers to these questions, we can write an API client. The client will be able to work further without our participation, until the API (or our requirements) changes. And, of course, we mean that the API documentation is always accurate and in sync with the implementation of the API.
Standalone APIs
But if human participation in the process is expensive, slow and error-prone, how can we get away from it? What will it cost to create a completely autonomous API?
First, we must find a way to develop and publish a common vocabulary. The next step is to start spreading the meaning of the meaning on the fly. Then the API detection system will be able to register new APIs along with its meaning dictionary.
The process of such an automated system without human intervention may look like this:
A computer publishes its interface along with a profile that describes the interface and its semantic dictionary. The service registers itself with an API detection system.
Later, another program polls the API discovery service using terms from the dictionary. If something is found, the API discovery service returns the found service to this program.
The program (which is now an API client) is already trained to work with a new dictionary. Now she can use the API for the actions she needs.
The client is programmed in a declarative way to perform a specific task, but is not strictly tied to a specific service.
For clarity, here is an example of a program that displays the temperature in Paris:
# Using a terms from schema.org dictionary, # find services that offers WeatherForecast. services = apiRegistry.find(WeatherForecast, { vocabulary: "http://schema.org"}) # Query a service for WeatherForecast at GeoCoordinates. forecast = service.retrieve(WeatherForecast, { GeoCoordinates: … }) # Display Temperature print forecast(Temperature) This approach not only allows you to create clients that are resistant to API changes, but also allows you to reuse code for many other APIs.
For example, you no longer need to create a weather forecast program for a particular service. On the contrary, you are writing a universal client who knows how to display the weather forecast. This application can use various services, such as AccuWeather, Weather Underground or any other country-specific weather forecasting service, if it supports (at least partially) the same glossary of meanings.
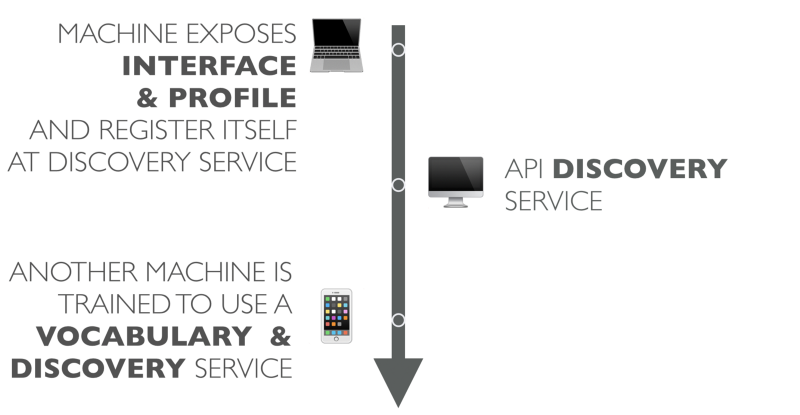
In summary, the building blocks of the Autonomous APIs are:
- register of dictionaries
- understanding of meaning on the fly
- API discovery service
- programming under the dictionary, but not under data structures
Arrival
So where are we with all this at the beginning of 2017? The good news is that we have these building blocks, and they gradually begin to attract attention.
We begin to learn to understand the meaning on the fly. HATEOAS use hypermedia formats for this. Using the JSON-LD format is gaining momentum in the industry APIs, and search providers like Google, Microsoft, Yahoo, and Yandex maintain the Schema.org dictionary.
Formats like ALPS give new life to semantic information for data. At the same time, GraphQL Schema can be studied on the fly to find out what is available using the GraphQL API.
And finally, there are special API directories, with HitchHQ and the Rapid API at the head.
Conclusion
In my version of the future API, we will get rid of human participation in documenting, discovering and using the API. We will begin to write our API clients in a declarative form and the information will be recognized on the fly.
This approach will reward us with lower costs, fewer mistakes and less time to market. With autonomous APIs, we can finally develop an API, re-use clients and scale the API indefinitely.
')
Source: https://habr.com/ru/post/326080/
All Articles